开源大数据可观测性方案实践 - 助力集群运维智能化、便捷化
前言
在过去的20年时间,大数据技术蓬勃发展,从最开始大公司内部的秘密武器,到现在广泛作用于几乎所有行业。通过使用大数据技术分析存量和实时的数据,能够更加全面清晰地洞察商业的本质。在商业节奏日益加快和发展越来越迅猛的今天,越来越多的企业意识到大数据分析的价值,并投入了大量的时间人力等资源。与此同时,从早期的简单报表,到搜广推(搜索广告推荐)的个性化需求,再到最近异常火爆的人机智能交互技术 ChatGPT,大数据应用对算力的要求呈指数级增长。如何以更低的成本、更加稳定地提供更高的算力,成为大数据行业需要探索和解决的核心问题。
另一方面,为了满足企业不断增长的大数据处理需求,从早期的 Hadoop、Hive,到 Spark、Presto、Flink,再到近几年火爆的数据湖、OLAP,涌现出了多种多样的大数据技术。虽然很多大数据技术都是开源的,可以通过网络获取到一些技术指南、最佳实践等,但是依旧缺乏从集群整体维度和数据处理全链路来分析和提升大数据栈“效能”的有效方法。
可观测性最早起源于应用服务,旨在随时了解整个应用栈中发生的情况。通过在网络、基础设施和应用程序中收集、关联、聚合和分析数据,以便深入了解系统的行为、性能和运行状况。可观测性可以用“观测-判断-优化-再观测”这一闭环来简单解释。可观测性是提升应用效率的基础和关键,但在大数据集群方面一直缺乏实践,这主要是由前述大数据技术的多样性和复杂性导致的。在本篇文章中,我们将介绍大数据集群领域所需的可观测性,实践大数据集群可观测所需要的条件和面临的挑战,以及阿里云EMR 产品如何通过 EMR Doctor 实现大数据可观测并向用户提供相关能力。
大数据可观测性介绍
当我们提及大数据的时候,脑中会浮现出各种技术,从 Kafka 到 HDFS、OSS,再到 YARN 和目前发展更好的 Kubernetes,还有上层的各种计算引擎如 Spark,Flink 和 Tez 等,甚至是深度学习和 OLAP 等业务相关技术。
尽管大数据技术纷繁复杂,我们可以把大数据各种技术自顶向下分为如下几层:计算引擎,资源调度层,存储等几个维度。由这些相互独立又互相关联的子系统一起构建了整体的大数据系统,为企业的大数据平台提供基础设施。
大数据的可观测性指的就是通过指标采集,元数据采集等技术获取到上述各个系统的洞察数据,而不是简单的指标罗列。大数据可观测的结果能够为企业带来如下价值:
- 通过资源分析与建议,辅助用户不断的优化,带来更合理的资源利用和更健康的集群使用
- 通过问题提示和异常提醒,减轻开发与运维人员的工作量,为企业大数据开发带来更高的效率
- 通过及时的规则分析、根因分析等,快速的定位大数据集群问题,减少集群因为故障带来的恢复时间

大数据可观测性场景分析
尽快前面提到,大数据可观测性可以为我们带来诸多好处,但现实情况是,很少有企业能够在大数据领域做好可观测性,甚至大部分企业还没有涉足这一领域。我们简单地分析一下大数据可观测性的使用场景。
我们先看一下企业中使用大数据应用的一个基本构成,通常企业中使用大数据的人群可以被分为如下几类:
- 数据分析师,数据科学家以及数据工程师,可以被统称为集群用户。
- 数据团队,包括运维团队等可以被统称为集群管理员。
- CIO/CTO/CEO 等可以被统称为管理层。
将集群中的角色细分后,我们其实可以看到,这三种不同的角色对大数据集群需求是不一样的,下面分别介绍一下这三种角色对于可观测性的不同要求。
大数据可观测性的用户画像
集群用户的需求
集群用户直接使用集群,提交各种任务到集群中,并产出数据,是为企业获取直接价值的群体。集群用户提交的任务多种多样,从批处理的 Hive on MR, SparkSQL 到流式的 Flink 任务以及 Ad-hoc 的 Presto 任务等。集群用户通过这些计算框架等直接构建上层的应用,如用户大盘,营销热点等。
对于集群用户来说,最关心的是任务的运行情况以及优化方法,集群用户常见的需求如下:
- 能否将我的任务更快的完成?
- 任务失败了,究竟是什么导致的?
- 我的任务今天跑不出来,但是之前都能跑,是什么导致的?
- 今天的日报比昨天晚出了2个小时,是哪个流程造成的?
集群管理员的需求
集群管理员负责维护大数据集群的稳定性,包含大数据集群软件设施,甚至包括底层的 IaaS 资源的稳定运行。在企业中虽然集群管理员不直接产出具体产品,但是通过对集群的稳定性提升以及整体的效率提升,会直接的提升整个集群的使用效率,从而提升企业的竞争力。
对于集群管理员来说,他需要了解集群整体的运行状态,集群潜在的风险以及对于风险能够找到对应的负责方进行处理。集群管理员常见的需求如下:
- HDFS中产生了大量的小文件,能否找到对应的使用方进行清理?
- 昨天集群中占用最多计算资源的使用方是哪些,这些是否合理,能够进行多大程度的优化?
- 哪些任务运行了最长的时间,占用最多的资源?
- 集群现在感觉有问题,到底是什么原因导致的?是由于任务导致的,还是 HDFS 出现瓶颈?
管理层的需求
管理层不太关注大数据使用的具体技术,更关注大数据能够给企业带来的价值以及整体的投资回报比,对于成本也有着较强的需求,包括资源优化,成本分摊等。常见的管理层的需求如下:
- 现有的集群在扩容前是否已经运行在较高的水位,是否还有优化空间?
- 集群从哪个方面能够进行资源优化,优化的效果如何?
- 现在集群的花费中,不同业务的占比如何,是否与产出成正比?
分析完三种角色对于大数据可观测性的不同需求,我们可以总结出,不同的角色对于大数据可观测性都有非常强的需求。但是现阶段,大数据可观测并不是大数据集群的标配,无法满足各个角色的需求。而造成这一现象的原因由于首先大数据软件栈太过繁杂,能够全部了解各个框架的人才屈指可数,而这些知识是大数据可观测性的一个前提条件。另一个原因是成本考虑,构建一整套大数据可观测系统需要多种技术,较长的链路以及复杂的技术,这对于一般的企业来说负担较重且很难量化产出。
大数据可观测性技术初探
大数据可观测性发展历程
在实践大数据可观测的过程中,需要经历四个阶段,每一个阶段的都是下一个阶段的必要组成,并为用户提供越来越多的业务价值。
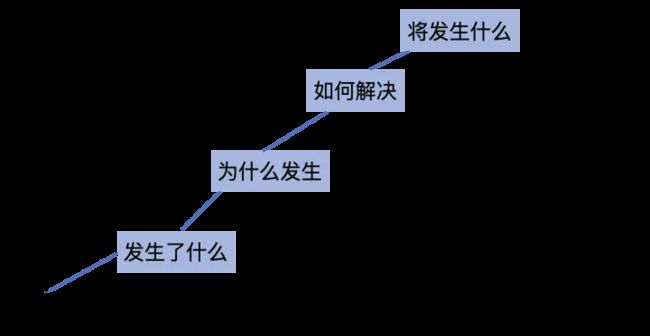
- 第一阶段,主要根据各个大数据组件提供的接口采集各个组建的 metrics 信息等,在这一阶段需要有大数据平台经验的人才来对这些 metrics 进行分析,能够得到基础的组件健康状态、组件压力状态等信息,在出现问题的时候需要分析历史的 metrics 信息进行推断,得到潜在可能的问题。
- 第二阶段,除了采集各个组件的基础 metrics 外,还对集群中的任务,cpu 资源,调度的队列信息等进行全面的采集,除了采集外,还需要对这些信息进行关联,获取到出现问题的根本原因。在这一阶段,除了采集更多的信息外,更重要的是对采集的信息进行关联,得到问题的本质原因。
- 第三阶段,在第二阶段的基础上,根据规则等把相应的处理方案反馈给用户,用户根据提示进行自运维操作,甚至发展到更高级的阶段,在底层的自愈系统能够自动化的对问题进行处理,减少股长时间。
- 第四阶段,基于前面个阶段的积累,根据多种问题产生的规律总结,或者基于规则,或者基于火热的 AI 技术,能够在故障处理之前能够及时预警,及早的排除隐患,将故障消灭在发生前。
从这四个阶段说明来看,每一个阶段都是在前一个阶段完成的基础上再进行数据在加工,产生更高质量的服务,当然了,随着要求的提升,技术难度和广度也愈加复杂。
大数据可观测性的技术要求
前面提到大数据可观测性在整体技术上要求很高,普通用户对于构建这一流程存在难度,这里仔细探讨一下这方面的原因。
首先在实践大数据可观测性的过程中,需要对多种组件、引擎、调度系统都要了解。比如对于 Hive on Tez 需要了解 Tez 的状态机转换,在不同的阶段需要获取不同的 metrics 和 events;对于 Spark 需要了解各个 stage 阶段采集不同的数据;对于 HDFS 需要了解元数据 Image 解析流程;对于 ResourceManager 需要了解不同的队列在各个优先级不同的情况下的调度策略。
如果想做好全链路的大数据可观测系统,需要对整个集群中使用的各个组件,各个引擎等有着比较深入的了解,并且不像 web 应用监测形成标准化,各个大数据组件和引擎采集等互不相同,没有一个统一的标准能够进行采集,但是彼此之间却相互关联,比如一个 Hive 的任务有一个 session id,在 YARN上 是一个 ApplicationID,相互之间需要做映射处理。
其次,除了采集以为,整个的大数据可观测系统还有一个复杂的链路,如下图:
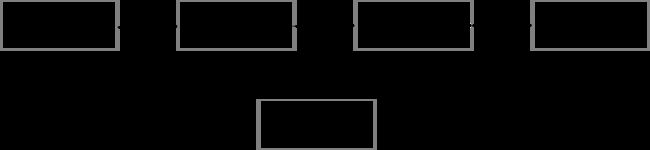
在采集系统,需要有足够的经验能够获取所需要的必要数据。
- 入仓阶段,需要对采集的数据进行统一收集管理,方便后面的分析。
- 分析阶段,根据收集方式的不同,可以采用实时分析或者批处理分析等。
- 展示阶段,将分析的结果全面有效的反馈给客户,并且能够快速的迭代。
在这几个阶段中,都需要一个全链路的监控系统,保证了整个系统的稳定性和有效性。
在这个链路过程中,涉及到了大数据各个组建的内核分析,jvm 使用分析,采集链路,收集链路、流式处理分析,批处理分析,前后端技术等等,可以说相当复杂。这也是为什么大数据可观测性没有广泛的成为业界标准的原因。
阿里云EMR 在大数据可观测性的实践
自2016年阿里云推出 EMR 以来,阿里云EMR 团队一直致力于为客户提供高附加值产品,解决大数据集群的痛点,如提升性能,降低资源成本,提升运维效率等能力。发展至今,我们已经为大量客户提供了完善的半托管服务,依托于社区专家的人才积累,场景的丰富多样,我们在大数据可观测性以及大数据管理方面积累了大量的经验,为我们的大数据可观测性实践提供了坚实的基础。
在2022年12月,阿里云EMR正式发布了云原生开源大数据平台EMR 2.0,升级后的开源大数据平台在成本持平的情况下,扩缩容性能最高可提升6倍。EMR 2.0为客户提供了完善的大数据可观测性能力,通过集群监控,我们提供了完备的监控指标以及巡检项,及时的提醒用户集群中目前出现的问题。通过 EMR Doctor 健康检查,我们为客户提供全面的大数据可观测能力,提供了从存储、计算的多方面,集群维度的健康评估,为客户提供开箱即用的大数据可观测平台,辅助提升客户整体的集群使用效率,解决潜在的问题。
EMR Doctor 为阿里云EMR 客户提供较为完备的大数据可观测产品,我们提供实时和日报两种方式,为集群用户提供不同角度的可观测方案。EMR Doctor 提供的功能包括如下:
- EMR Doctor 提供集群的日报功能,并提供量化打分、智能建议,用户可以清晰到获取到集群的健康状态以及改进建议
- EMR Doctor 提供集群的实时检测功能,实时的对集群任务进行分析,异常检测,对组件状态进行检查分析,找到潜在的问题和改进建议
- EMR Doctor 对多数据源进行采集、融合分析,并根据智能算法进行智能诊断分析,减少大数据平台繁重和重复的劳动
EMR Doctor 功能介绍
EMR Doctor 提供日报和实时检测两种形态的功能,从两个维度辅助客户在大数据可观测性上进行实践。
日报功能
在日报中,我们会保存30天的集群日报分析,以分数的形式定量的给客户集群打分,在日报具体报告中,我们会给客户客户具体的分析,分析到客户不同组件,不同维度的一些实际问题。
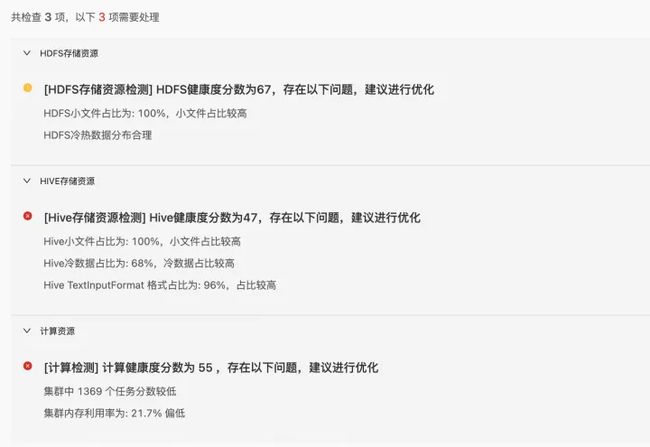
除了打分之外,我们在每个模块还提供用户对现有问题可操作的解决方案,如下图计算资源分析中,我们列举出内存利用率低的问题,并建议用户根据我们提供的作业数据进行优化。

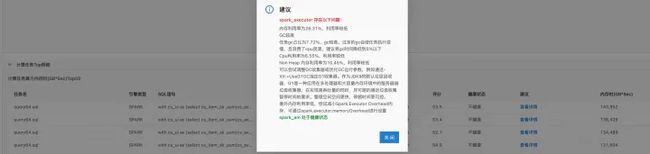
EMR Doctor 不仅在集群维度进行打分、分析,对 metrics 数据,元数据进行分析,对于具体的细节数据,比如任务运行等,也给出了分析数据,满足使用方的需求。比如对于计算任务,我们会给出Top 50算力使用的详细说明,如 appid,sql 语句,引擎类型,算力使用,配置信息以及评分和健康状态,并根据问题进行建议。

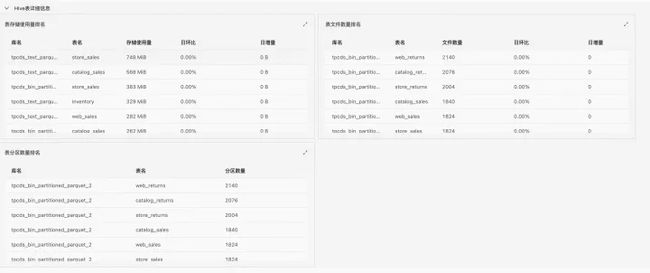
此外,我们根据不同组大数据组件的需求,提供多种的看板,如在 hive 中我们可以对库、表问题进行分析,Hive表的一些详细信息分析如下图。
实时功能
在实时功能中,EMR Doctor 为用户提供最近5分钟粒度的集群分析,着重于集群的问题排查,尤其是多种因素引起的问题汇总,获得潜在的根因。目前,实时分析之前多种计算引擎和YARN的分析。
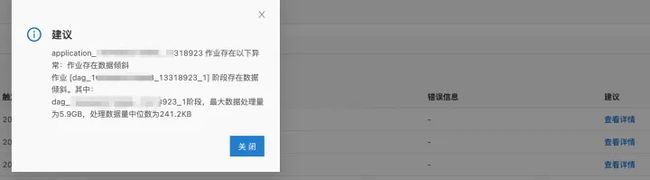
如下图,通过对5分钟数据的汇总,能够获得用户的一些任务问题,如数据倾斜、长尾,资源不足风险等,并且给出建议。

总结
整体产品上,EMR Doctor 为大数据客户提供一个集群维度的健康状态,让大数据集群可观测、可量化,为管理层,集群管理员以及用户提供不同的视角去了解现有集群的健康情况,满足各方的需求,从而推动大数据集群更健康的发展。此外,EMR 平台在不断的发展演进,对于大数据可观测性的实践会越发深入,更多的组件,更多的细化分析都会随着产品迭代不断加入,期望带给 EMR 客户更好的高附加值体验。
作者:燕回@阿里云
原文链接
本文为阿里云原创内容,未经允许不得转载。