SPARKSQL3.0-DataFrameAPI与spark.sql()区别源码分析
一、前言:
阅读本节需要先掌握spark-sql内部执行的基本知识:
SessionState
Unresolved阶段
Analyzer阶段中queryExecution的介绍
二、区别
spark.sql的执行顺序为: sql字符串 -> antlr4解析成AST语法树 -> unreolved解析成logicalPlan -> Analyzer解析 -> Optimizer优化 -> 后续物理执行计划
DataFrame执行顺序: 根据api直接构建logicalPlan -> 根据调用不同的api嵌套成新的logicalPlan【部分函数包含Analyzer解析】 -> action算子触发Optimizer优化 -> 后续物理执行计划
可以看出dataFrameAPI 和 spark.sql 的【Optimizer优化 -> 后续物理执行计划】完全一致;
而dataFrameAPI的Analyzer阶段是在调用select等函数时直接触发Analyzer阶段,下面有详细过程
两者唯一的区别是dataFrame省略了【antlr4解析成AST语法树 -> unreolved解析成logicalPlan】步骤
三、示例:
val value = spark
.range(2)
.select('id as "_id")
.filter('_id === 0)
value.explain(true)
结果: 看起来和spark.sql的explan一样
== Parsed Logical Plan ==
'Filter ('_id = 0)
+- Project [id#0L AS _id#2L]
+- Range (0, 2, step=1, splits=Some(2))
== Analyzed Logical Plan ==
_id: bigint
Filter (_id#2L = cast(0 as bigint))
+- Project [id#0L AS _id#2L]
+- Range (0, 2, step=1, splits=Some(2))
== Optimized Logical Plan ==
Project [id#0L AS _id#2L]
+- Filter (id#0L = 0)
+- Range (0, 2, step=1, splits=Some(2))
== Physical Plan ==
*(1) Project [id#0L AS _id#2L]
+- *(1) Filter (id#0L = 0)
+- *(1) Range (0, 2, step=1, splits=2)
四、源码:
关于spark.sql的执行过程前面已经详细讲过,这里主要介绍dataFrameAPI的执行过程
先来看spark.range(2):可以看到最终是构建了一个Dataset[long]返回,但dateSet的构建需要logicalPlan入参,也就是Range
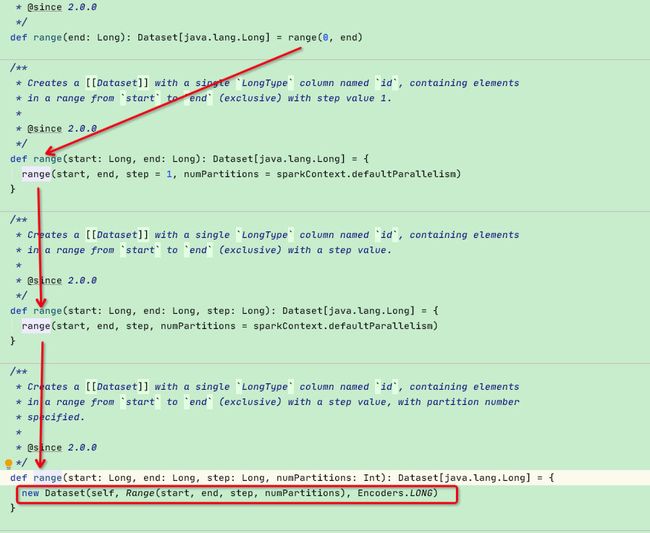
logicalPlan入参,如下图:

可以看出dataSet的logicalPlan入参就是range函数中的Range,来看一下Range的构建,看出是构建了一个Range类,而range类正是logicalPlan的子类
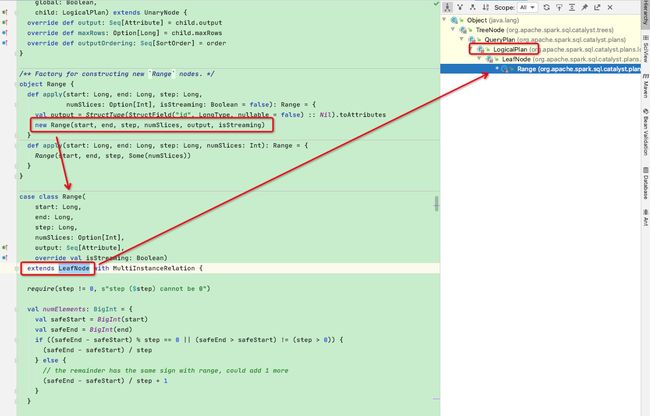
然后回到构建DateSet-this函数那里:参数logicalPlan = Range
def this(sparkSession: SparkSession, logicalPlan: LogicalPlan, encoder: Encoder[T]) = { // 参数logicalPlan = Range
this(sparkSession.sessionState.executePlan(logicalPlan), encoder) // 通过executePlan函数构建QueryExecution
}
......
class Dataset[T] private[sql](
// Dataset的构建第一个参数需要是QueryExecution,所以上面的this构造函数需要先构建QueryExecution
@DeveloperApi @Unstable @transient val queryExecution: QueryExecution,
@DeveloperApi @Unstable @transient val encoder: Encoder[T])
......
def executePlan(plan: LogicalPlan): QueryExecution = createQueryExecution(plan) // 调用createQueryExecution函数
......
// 实际上就是构建一个新的QueryExecution
protected def createQueryExecution: LogicalPlan => QueryExecution = { plan =>
new QueryExecution(session, plan)
}
此时QueryExecution已经构建完成,主函数中.range(2)函数的返回值是DateSet,DateSet中的logicalPlan为:Range
Range (0, 2, step=1, splits=Some(2))
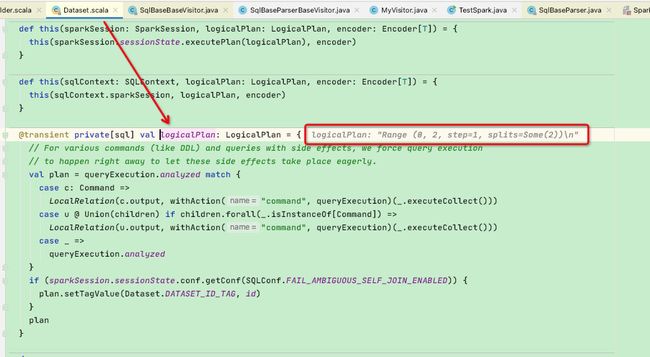
再看DateSet.select('id as “_id”), 这里贴一下源码:需要主要两个函数: withPlan{}、logicalPlan变量
def select(cols: Column*): DataFrame = withPlan { // 这里的withPlan函数很重要,下面会有介绍
// untypedCols函数主要是将用户传输的column字段检查
val untypedCols = cols.map {
......
}
Project(untypedCols.map(_.named), logicalPlan) // 可以看到这里是根据range函数创建的【range】logicalPlan又构建了一个新的Porject【logicalPlan】
}
再看withPlan函数:调用了Dataset.ofRows函数,参数是上面创建的Project logicalPlan

在ofRows函数中,参数logicalPlan = Project,再调用sparkSession.sessionState.executePlan函数构建新的QueryExecution
再经过assertAnalyzed解析后构建新的DateSet返回,保持和RDD一样的不可变性
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame =
sparkSession.withActive {
val qe = sparkSession.sessionState.executePlan(logicalPlan) // 这里调用executePlan函数来构建一个新的queryExection
qe.assertAnalyzed() // 执行解析,可以看出这一步直接执行Analyzer阶段
new Dataset[Row](qe, RowEncoder(qe.analyzed.schema)) // 构建新的DateSet返回,和RDD的不可变特性保持一致
}
......
def executePlan(plan: LogicalPlan): QueryExecution = createQueryExecution(plan)
......
// 实际上就是构建一个新的QueryExecution
protected def createQueryExecution: LogicalPlan => QueryExecution = { plan =>
new QueryExecution(session, plan)
}
此时主函数.select函数返回的DataSet中的logicalPlan为:
Project [id#0L AS _id#2L]
+- Range (0, 2, step=1, splits=Some(2))
再来看filter函数:根据上一次的Project - logicalPlan 构建一个新的Filter父节点,然后执行withTypedPlan函数,withTypedPlan函数中调用了DataSet的apply函数
def filter(condition: Column): Dataset[T] = withTypedPlan {
Filter(condition.expr, logicalPlan) // 根据上一次的Project - logicalPlan 构建一个新的Filter父节点
}
@inline private def withTypedPlan[U : Encoder](logicalPlan: LogicalPlan): Dataset[U] = {
Dataset(sparkSession, logicalPlan) // 调用DataSet的apply函数
}
DataSet的apply函数:可以看到此处是新构建了一个DateSet,并将Filter-logicalPlan传入,并返回
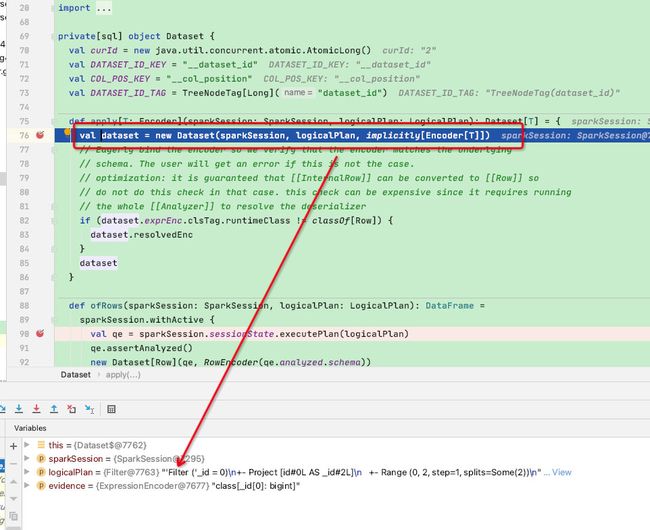
这里我们看一下返回的DateSet:可以看到其内部的QueryExecution的logicalPlan包含了各个节点的语法树,此处已和spark.sql的logicalPlan完全相同
后续的【Analyzer解析 -> Optimizer优化 -> 后续物理执行计划】将保持一致

至此DataFrameAPI与spark.sql(“”)执行区别结束,再来回顾一下两者的异同:
spark.sql的执行顺序为: sql字符串 -> antlr4解析成AST语法树 -> unreolved解析成logicalPlan -> Analyzer解析 -> Optimizer优化 -> 后续物理执行计划
DataFrame执行顺序: 根据api直接构建logicalPlan -> 根据调用不同的api嵌套成新的logicalPlan【部分函数包含Analyzer解析】 -> action算子触发Optimizer优化 -> 后续物理执行计划