毕业设计-基于深度学习的模糊文字识别方法
目录
前言
课题背景和意义
实现技术思路
一、相关理论基础
二、实验数据集准备
三、基于生成对抗网络的图像超分辨率重建
实现效果图样例
最后
前言
大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
毕业设计-基于深度学习的模糊文字识别方法
课题背景和意义
文字作为人类思想和情感的重要传播工具,在社会生活生产中扮演着重要角色。 在日常场景中,文字信息更是无处不在,如路标、广告牌、横幅等。这些场景文字图 像比起其他信息传播方式更直观更形象,通过对文字图片的分析,人们能更好了解图 片所传达的意义,从而思考和规划行为目的。因此,对自然场景中的文本文字进行分 析和识别具有重要的科学和社会意义。以当下来讲,随着科学方法和硬件设备的飞速 发展和迭代更替,越来越多的领域系统用到了文字图像识别技术。早期的光学字符识别(Optical Character Recognition,OCR)技术经过长时间的 沉淀,在识别文本文档图像上达到了较为理想的效果。但场景文字图像特有的复杂 性使得该类识别不能如以往的文字工作顺利进行。背景复杂程度、图像质量、文字 字型多样、文字排布多样的几类问题导致自然场景下文字识别的困难徒增。生产生活的需 要使得该类文字识别的研究加紧。因此对此开展研究并创新发明具有良好鲁棒性以 适应复杂多样的场景的算法模型成为了当前重要的课题。
实现技术思路
一、相关理论基础
神经网络基础知识
1、卷积神经网络原理
卷积神经网络是一类包含卷积计算且具有一定形状和层次结构的前反馈神经网 络。经典卷积神经网络LeNet5由卷积层、池化层和全连接层组成(如图所示)。 该网络所展现的层的设计思想成为现如今卷积神经网络结构选择的基础。

一系列的卷积运算在卷积层内展开,实际上这是一种简单的数学矩阵乘法和求和运算。如图所示,假定存在一个矩阵维度为3×3,卷积核大小为2×2,卷积核移动步长为1,从每行起向右侧依次滑动。将矩阵中像素值与对应卷积核中的权重值进行相乘,并将结果相加形成新的矩阵大小输出。

2、循环神经网络原理
在传统神经网络中,上一层与下一层能够得到充分地连接建立起关系网,但每层 各个节点之间缺少信息传递。在文字图片中,文字之间往往存在语义关系,所以设计 处理序列化关系的循环神经网络尤显重要。在一些常见检测(CTPN检测模块)和 识别(CRNN)算法中都引入了序列学习模型并获得了优异的表现。 循环神经网络通过使用带子反馈的神经元进行任意长度的序列处理。如图
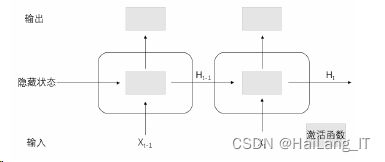
3、生成对抗网络原理
在机器学习中,生成模型可以建立起变量间的条件概率分布。生成对抗网络就是 在依靠生成模型上引入对抗博弈的思想。
假设有一个生成模型(Generator)负责生成一张比较真实的图像,同时还有一个 辨别模型(Discriminator),以判别图像是生成的还是真实图像。于是我们可以将该生 成和判断过程抽象为以下步骤:(1)生成模型生成虚假图像(2)辨别模型二分类学习 辨别真假图像。(3)生成模型根据辨别模型结果增强生成图像的能力,生成新的虚假 图像。(4)辨别模型继续学习辨别真假图像的能力。直到二者收敛,此时生成模型和 辨别模型达到预期目标。其逻辑过程如图:

实验基础模型介绍
1、VGG网络
VGGNet由牛津大学的几何视觉组(Visual Geometry Group)于2014年提出并 在当年ImageNet比赛上取得优异成绩。作为深度卷积神经网络的代表之一,VGG 系列网络证明了小卷积核的优秀特征提取能力和网络加深对性能一定程度提升的可 行性。如今仍以其优秀的实用性活跃在涉及神经网络的领域中。

2、门控记忆单元
GRU门控记忆单元是一种特殊的RNN网络,在获取长序列文字前后语义关系时 能有更好的表现。与普通版RNN相比,GRU内部对输入信息进行了筛选,满足了进 行长时间记忆和重点记忆的需求。其网络内部存在两个门来控制隐藏状态的计算:重 设门(Reset Gate)和更新门(Update Gate)。
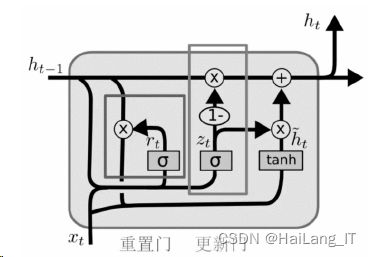
如图所示,GRU中的重设门和更新门的输入同普通版RNN一样都是当前输 入和上一时间状态ℎ−1,激活函数同为Sigmoid。
如图所示,将两个GRU在相反方向的隐藏层状态上搭建,将输入的序列信息 分别传入到相反的GRU中。在后续的输出上将两个GRU中所得到的序列信息进行拼 接操作。它们的输入相同,只是信息传递方向不同。

3、单图像超分辨率重构网络
GAN诞生后的几年变体网络层出不穷。在图像超分辨率研究中,学者也尝试将 GAN作为实现手段,于是就诞生了单图像超分辨率重构网络—SRGAN。以往基于卷 积的SR算法大都是计算重建图像和原图像间的均方误差(Mean-square Error,)最小值,这样往往在高频细节上没有很好把握。而SRGAN通过比较生成图片和高分 辨率图像经卷积后的特征差别进行的重建。

其模型如图所展示的,k为卷积核大小,n为卷积核数量,s为步长。图中上 半部分为生成网络。
图像插值方法
图像插值法是传统框架下进行图像超分辨率的重要方法。其核心思想就是通过人为设定的插值核或者通过插值函数对源图像各像素的值进行函数转化。
1、Bicubic插值
Bicubic插值算法是平面图像超分辨率中常用的插值算法,一般又被称为双立方 插值。其核心思想就是将图像坐标点的值与它最近4×4个像素点为采样点的值加权平均得到最终结果。这样做在考虑相邻4个像素进行采样的同时记录了较远处12个点 变化情况。
双三次插值图解 :

2、Lanczos插值
Lanczos插值算法在实现思想上与双三次插值类似,都是通过对最近的像素点计 算权重,加权取平均值得到最后的输出值。不同于双三次插值利用插值函数(公式)的方式,Lanczos插值采用正则化的函数作为插值核,而插值核则由下面的公式得到:
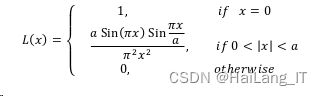
连接时序分类机制
在早期的语音识别研究中,传统语音声学模型进行训练前需要每一帧数据和标签 并需要提前手动做语音对齐的预处理,这容易出现纰漏且非常耗时。面对声音编解码 时的对齐问题,学者提出了连接时序分类(CTC)机制[39-40]作为答案。 在正式介绍CTC的使用之前我们先将目光放在音频标注问题上。序列化标注 (Sequence Labeling)是对来自输入固定字符集合的每一个元素进行标注。如图:

二、实验数据集准备
开源数据集介绍
在深度学习中,数据是科研创新的第一驱动力。数据集的质量会大概率地影响深度学习模型生成后的性能。因此对开源数据集的选择和开源数据集进行有效的预处理是不容忽视的重要环节。
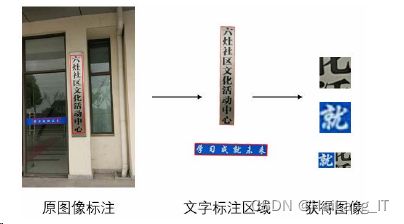
LVST数据集是首个提出弱标注数据的场景数据集,一共包含45万张图像,数据 量是ICDAR-2017、ICPR2018的14倍以上。这里主要将该数据集作为 超分辨率的研究实验原始数据集。该数据集的完整标注图像(图上半部分)和弱标注 图像(图下半部分)如图所示。数据集都是街景随拍所得的同时带有复杂的环境 影响和成像质量问题,这是选择作为研究内容的主要原因。

合成数据集
在实际生产和科研工作中,存在着许多类似以上靠人工拍摄并标注的数据集。这 些数据集很好地展现了真实情况下的文字分布形态,但自然场景中一些文字排版密布 且难以辨认,若仅靠人工注释标签往往存在难度大、速度慢、易出错的风险。再者中 文文字的特性又使得识别十分依赖大规模数据集。
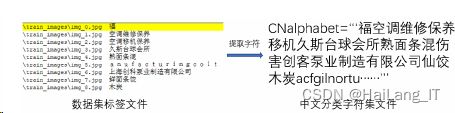
解压百度官方所提供的图片对应标签文件,提取每个出现的字符制作中文分类字符集(CNalphabet),如图所示:
现有的场景文字数据集绝大多数都是基于英文字符的,而中文文字无论是构造还是数量上都是英文文字无法比拟的。合成数据作为数据集扩充的手段之一,能一定程度上模拟真实情况。但仅仅以这种方式作为扩充是不充分和片面的,需要通过其他方法的配合进行扩充才能展现最后实验所用数据集的丰富多样。
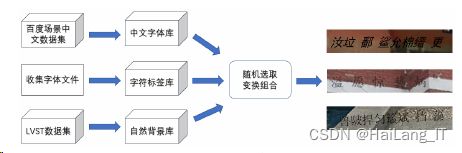
图像增广
除了数据生成之外,图像增广技术也是数据集扩充的重要手段。相较于数据生成,经增广后所展现的图片更贴合自然场景下图像文字所呈现的姿态。
实验数据集预处理
在研究中,图像超分辨率和文字识别的模型训练都需要用到数据集。其中图 像超分辨率模型实验的图片需求为96×96像素大小的高分辨率图片和相对应的24×24像素大小的低分辨率图片,文字识别模型实验也需要96×96像素的街景文字图片(为在后文体现超分辨率效果故将识别模型输入图片规定大小)。 根据具体的研究过程,需将上述所介绍的LVST数据集和中文场景文字识别创新 大赛数据集进行处理整合。
三、基于生成对抗网络的图像超分辨率重建
了解了图像超分辨率相关知识,得到了超 分辨率实验数据集。本章主要介绍单一图像的超分辨率重建网络实验,首先展示残差 密集网络以及残差密集块的结构特点、超分辨率常用评价指标,然后详述对SRGAN 基础网络进行重新设计,最后陈述实验过程、结果并与经典超分辨率模型相对比。
残差密集网络以及残差密集块
在基于深度学习的图像超分辨率方法中,除了基于生成对抗网络的方法外常见的 还有基于卷积神经网络设计的重构模型,残差密集网络(Residual Dense Block,RDN) [46]就是其中的经典代表之一。
如图所示,RDN网络主要由浅层卷积层、残差密集块组、密集特征融合层以 及上采样层构成。除了特征融合模块中所使用的为1×1的卷积核之外,其他所有用到的卷积核大小都为3×3,并在每一侧填充零以保证输出的大小不变。这样的设计方式不仅能方便融合时对齐,而且多尺度提取图像各局部层的信息表征,简便网络的表达 能力。
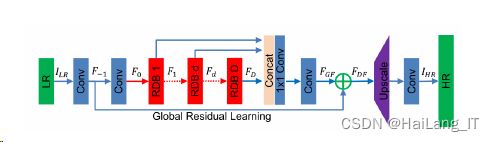
RDN网络在常见超分辨率基准数据集例如Set5、Set100和Urban100等上 均有着不错的表现,其中在放大因子为2时所得到的客观评价指标值相比最为优秀。 RDN网络有上述表现主要得益于RDB模块的设计理念,下面我们来重点介绍下RDB模块以及在本文设计中的使用。

超分辨率网络改进方案
1、构造RDGAN网络
超分辨率网络模型是在第二章所介绍的SRGAN网络进行了改进,减少了原网络中影响网络稳定因素,提高了模型的特征提取能力,使性能发挥上得到了提升。 在生成器网络方面,如图所示:
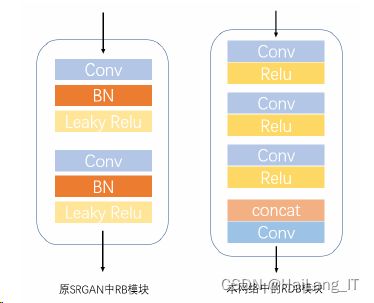
在SRGAN的基础上进行改变并将以上的特征提取模块以合适的方式搭建,可以得到如图所示本文的生成器网络。
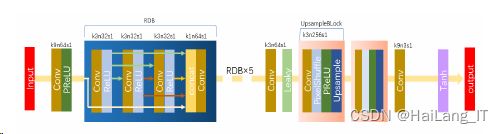
从功能方面来讲,该网络可分为三个基本结构:浅层特征层、RDB模块组、上采 样模块组。输入图片通过第一个Conv+PReLU浅层特征层先进行全局特征提取,由 RDB模块组将全局特征信息反复利用融合特征,最后通过上采样模组的反卷积操作 对结果进行扩充处理。
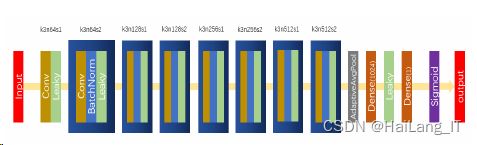
此外,将原网络中所带的BN层也进行了移除并用Leaky函数 进行通道数目的统一,这样做可以减少因BN层归一化操作数据,破坏原图像对比度 导致输出的差异变大。从而减少计算复杂度,保留图像还原信息。 而辨别器网络的结构如图4-5所示,其本质上是一个解决二分类问题的分类器。 先以8个Conv-Leaky_ReLU的组合层形式,除第一个组合层不带BN层外,其余后续 均在中间层添加BN层,其中卷积核大小均为3×3,步长为2,补边为1,卷积通道数以64-128-256-512的形式进行叠加。
2、Loss改进
在本文的Loss设计之初,采用的Loss方案如公式4-1所示,类似于超分辨率损失函数设计方案,总损失函数由内容损失和对抗损失两部分组成,并以权重进行相加求和得到。
其中对于的损失是通过将伪图像与真实标签的值进行S计算得到,则采用预训练的VGG19中第个池化层之前的第个卷积层所输出的特征图(公式)与真实图片进行S的计算。

但若仅仅采取以上所表示的损失函数,则在实际实验操作过程中所生成的超分辨 率图像出现了严重的棋盘效应如图所示。图中上半部分为原高分辨率图像,下半 部分生成的超分辨率图像中出现了较细的类似交叉直线格子的伪影。这种伪影是上采 样过程中转置卷积重叠不均导致颜色分布不均所产生的。

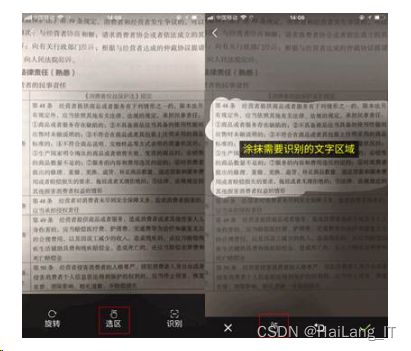
实现效果图样例
模糊文字识别方法:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!