Flink TaskSlot与并行度
文章目录
- 一、Flink的Task、SubTask
- 二、算子链
- 三、什么情况下算子可以组合为算子链?
- 四、算子链操作
- 五、并行度
- 六、TaskSlot与并行度的联系
- 七、槽位共享
- 八、并行度设置注意事项
- 九、并行度设置
- 十、并行度优先级
- 十一、并行度Parallelism与任务槽TaskSlot总结
- 十二、Local模式下注意事项
上文说到:TaskManager 是一个 JVM 进程,是实际负责执行计算的Worker,TaskManager中最小的资源调度单位是TaskSlots。TaskManger从 JobManager 接收需要执行的任务,然后申请Slot 资源(根据集群Slot使用情况以及并行度设置)并尝试启动Task开始执行作业,会以独立的线程来执行一个task或多个subtask。为了控制一个 TaskManager 能执行多少个 task,Flink 提出了 Task Slot 的概念…
一、Flink的Task、SubTask
Task可以理解为Flink作业计算时的算子 比如 map、keyBy等等
但是由于flink的taskmanager在运行task的时候是每个task采用一个单独的线程,这就会带来很多线程切换开销,进而影响吞吐量。为了减轻这种情况,flink进行了优化,也即对subtask进行链式操作,链式操作结束之后得到的task再作为一个调度执行单元,放到一个线程里执行。如下图的,source/map 两个算子进行了链式 合成了一个算子链(可理解为合并为一个算子);keyby/window/apply三个算子也进行了链式组合为了算子链(可理解为合并为一个算子),sink为单独的一个算子。
SubTask可以理解算子在运行时根据并行度设置而产生的运算算子实例
如下图所示:
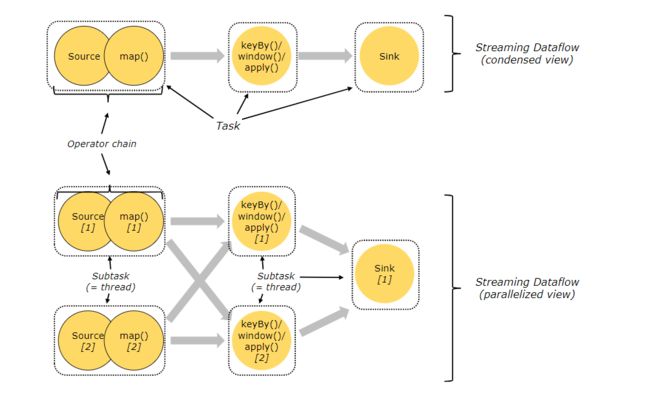
说明:图中假设是source/map的并行度都是2,keyby/window/apply的并行度也都是2,sink的并行度是1,则此Flink作业task有五个,则会由五个不同的线程执行。

二、算子链
算子链,即多个算子组成一个链路,形成一个大的算子,比如source算子 map算子 组合为(source map)。
Flink 会使用算子链将尽可能多的上、下游算子链接到一起,链接到一起的上、下游算子会被捆绑到一起,作为一个线程执行。假如两个算子不进行链接,那么这两个算子间的数据通信存在序列化和反序列化,通信成本较高,所以说算子链可以在一定程度上提高资源利用率。
三、什么情况下算子可以组合为算子链?
-
上下游的并行度一致
-
上游算子将所有数据前向传播到下游算子上,数据不进行任何交换,那么这两个算子可以被链接到一起。比如,先进行filter(),再进行map).这两个算子可以被链接到一起。(Flink源码org.apache.flink.streaming.api.graph.StreamingJob-
raphGenerator中的 isChainable()方法定义了何种情况可以进行链接,感兴趣的读者可以阅读一下相关代码) -
下游节点的入并行度为1 (也就是说下游算子节点没有来自其他算子节点的输入)
-
上下游节点都在同一个 slot group 中
-
为了防止同一个slot包含太多的task,Flink提供了资源组(group)的概念。group就是对operator(算子)进行分组,同一group的不同operator task可以共享同一个slot。默认所有operator属于同一个组"default",也就是所有operator task可以共享一个slot。我们可以通过slotSharingGroup()为不同的operator设置不同的group。
dataStream.filter(e->e.getId()!=0).slotSharingGroup("groupName");
-
-
下游节点的 chain 策略为 ALWAYS(可以与上下游算子链接,map、flatmap、filter等默认是ALWAYS)
-
上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
-
两个节点间数据分区方式是 forward
-
用户没有禁用 chain
四、算子链操作
默认情况下,只要符合算子链生成规则,算子间便会自动组成算子链,当然,我们也可以根据需要来关闭算子链,或者对特定算子进行链接
执行环境层面关闭所有算子链链接
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.disableOperatorChaining();
在关闭算子链后,我们也可以调用startNewChain()方法,根据需求对特定算子进行链接
DataStream<T> source = input;
source.filter(new Myfilter1())
.map(new MyMap1())
.map(new MyMap2()).startNewChain()
.filter(new MyFilter2());
上面的例子中,Filter1和 Mapl被链接到了一起,Map2和 Filter2被链接到了一起。也可以使用disableChaining()方法,对当前算子禁用算子链。
DataStream<T> source = input;
source.filter(new Myfilter1())
.map(new MyMap1())
// 禁用算子链
.map(new MyMap2()).disableChaining();
上面的例子中,Filter1和 Map1被链接到了一起,Map2被分离出来。
五、并行度
一个Flink程序由多个任务(Task)组成(source、transformation和 sink)。 一个任务由多个并行的实例(线程)来执行(SubTask), 一个任务的并行实例(线程)数目就被称为该任务的并行度。
Flink中的程序本质上是并行的和分布式的。在执行期间,一个流具有一个或多个流分区,并且每个算子具有一个或多个算子子任务。算子子任务之间彼此独立,并可以在在不同的线程(甚至服务器)中执行,算子的并行度决定了算子子任务数量,同一程序的不同算子可设置不同的并行度。
六、TaskSlot与并行度的联系
既然Flink作业在执行的时候,是需要申请Slot资源(根据并行度),然后启动Task执行作业,那么TaskSlot与并行度到底什么关系呢?
我们以上图为例子 (source/map的并行度都是2,keyby/window/apply的并行度也都是2,sink的并行度是1)
假如,我们现在有两个TaskManger,且每个TaskManger都有三个TaskSlot,那么 如上示例subtask在Slot可能是这样分布的…
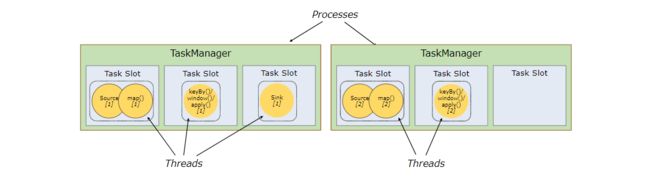
上边这幅图呢,表示了 source/map算子链 与 keyby/window/apply 算子链的两个subtask都进入了不同的Task Slot ,sink单独进入了一个TaskSlot,由于Taskmanger 会根据TaskSlot数量 对每个TaskSlot平分系统资源,但是呢,我们发现,上述情况,有一个TaskSlot为空闲状态并未使用,因为白白浪费了系统资源…
为什么会出现这种情况呢?因为并行度设置不合理导致的…由于上方 2+2+1 并行度,总共才会有2个subtask,就算每个subtask都进入了不同的TaskSlot,仍会有TaskSlot为空闲状态 (因为上图 TaskSlot有6个…)
这个时候呢,为了能充分利用slot资源,我们需要对我们的Flink作业并行度进行优化设置
比如,我们设置source/map、keyby/window/apply的算子链并行度为6(并行度为6,表示算子(Task)的并行数为6,即同时可有6个subTask执行),sink并行度保持为1
每一个 sourec/map keyBy/window/apply 算子链进入到不同TaskSlot 如下图所示

那么,此时,我们的TaskSlot都被利用到了,就能充分利用slot资源,同时保证每个TaskManager能平均分配到重的subtasks,比如keyby/window/apply操作就会均分到申请的所有slot里,也保证了slot的负载均衡
如果看到这里,您还不太清楚,我再上一张官网示例图:
说明:当前Flink集群一共有三个TaskManger,每个TaskManger有三个TaskSlot (那么Flink集群总可用TaskSlot为 3*3=9个)

1、我们设置作业并行度为1,将占用1个Slot

那么,Flink程序的所有Task 与SubTask 均会在一个TaskSlot中, 就如同上图,现在在TaskManger1 中 第一个Slot,此时Flink程序使用着Flink集群中1/9的资源执行作业,余下的8/9皆为空闲状态
2、我们设置作业并行度为2后,将占用2个Slot

此时,我们的Flink程序的所有Task 与SubTask 会在两个TaskSlot中, 就如同上图,现在在TaskManger1 中 第一个Slot,与TaskManger2中第一个Slot,此时Flink程序使用着Flink集群中2/9的资源执行作业,余下的7/9皆为空闲状态
3、我们设置作业并行度为9后,将占用9个Slot

我们所有的Source、Reduce、SInk 算子子任务 分配到了每个Slot,此时Flink程序使用着Flink集群中9/9的资源执行作业,TaskSlot利用率为100%
4、我们设置作业算子Source、Reduce并行度为9 Sink并行度为1

此时,我们所有的Source、Reduce算子子任务分配到了每个Slot,但是由于Sink并行度为1,则只会进入其中一个Slot中,此时Flink程序使用着Flink集群中9/9的资源执行作业,TaskSlot利用率为100%,与示例(3)不同的是 我们输出并行度为1,无论哪一组Source、Reduce subTask执行完毕后,都只会交由一个且仅有一个sink的subTask执行数据输出
七、槽位共享
Flink默认开启了槽位共享,从 Source到 Sink的所有算子子任务可以共享一个Slot,共享计算资源。或者说,从Source到 Sink的所有算子子任务组成的Pipeline共享一个Slot.
ex:我们现在有一个TaskManger,且设置了四个Slot
注意,我的source 实现了ParallelSourceFunction ,因此也是支持多并行度的
那么我这个代码,作业执行图会是如下

过多的计算任务集中在一个 Slot,有可能导致该Slot的负载过大。每个算子都有一个槽位共享组(Slot Sharing Group )。默认情况下,算子都会被分到default组中,也就意味着在最终的物理执行图中,从 Source到Sink上下游的算子子任务可以共享一个 Slot。我们可以用slotSharingGroup()方法将某个算子分到特定的组中。例如,将我们的上边代码中的source算子 分到source资源组中,将我们的window-apply-sink算子链分到 sink资源组



此时呢,我们上述代码的作业执行图应该是如下

这是为什么呢?
未自定义算子链与资源槽位,如果一个作业的并行度为parallelism,该作业至少需要个数为parallelism 的Slot。
自定义算子链和槽位共享会打断算子子任务之间的共享,当然也会使该作业所需要的Slot数量大于 parallelism。(这一点需要各位注意,避免因可用Slot数量不足提交Job时资源申请不下来导致作业执行失败)
八、并行度设置注意事项
注意点:并行度改变会影响任务划分,与subtask数量,如果taskslots数量不满足要求,会导致任务没有足够的资源分配,但flink会尝试申请资源(5分钟)然后才会关闭计算程序

九、并行度设置
-
算子
DataStream<String> result = windowedStream.apply(new SpeedAlarmWindow()).setParallelism(1); -
环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(12); -
客户端

-
系统
flink-config.yaml文件中设置

十、并行度优先级
算子级别>环境>客户端>全局系统
十一、并行度Parallelism与任务槽TaskSlot总结
-
TaskSlot是静态的概念,代表着Taskmanager具有的并发执行能力
-
parallelism是动态的概念,是指程序运行时实际使用的并发能力
-
设置合适的parallelism能提高运算效率 不可太多也不可太少(多了导致无法申请可用资源 程序无法正常执行,少了资源浪费,并发执行力度浪费)
十二、Local模式下注意事项
在Local模式下、代码开发中,默认并行度为Cpu核心数数量