ADDS-DepthNet:基于域分离的全天图像自监督单目深度估计
完整项目已在AI Studio开源,点击链接即可运行:
https://aistudio.baidu.com/aistudio/projectdetail/5387023
01 简介
无人驾驶车辆在路上行驶时,通常需要配置激光雷达获得高精度点云数据,从点云数据中获取主车与周围各个障碍物的距离。但是,激光雷达的成本高,因此,很多学者尝试用相机来估计主车与周围各个障碍物的距离,从而尽可能地降低成本。
用专业术语来说,深度估计就是通过图像采集装置采集物体的图像,利用物体的图像估计物体各点到图像采集装置的成像平面的垂直距离,该垂直距离即为该物体上对应点的深度信息。
目前有很多深度估计方法,如果按照使用的传感器来分,可以分为基于TOF相机、基于双目摄像头和基于单目摄像头的深度估计。本文讨论的是基于单目摄像头的深度估计。
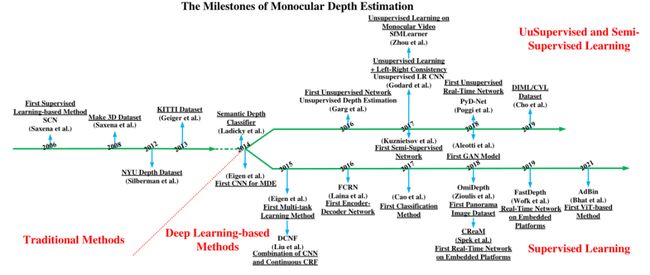
图1 单目深度估计算法发展史[1]
02 算法背景
近年来,自监督深度估计得到了广泛的研究,Monodepth和SFMLearner是第一个采用训练深度网络和独立位姿网络的自监督单目深度估计方法。一些方法在户外场景进行了改进,并在KITTI数据集和Cityscape数据集上进行了充分的测试,但因为夜间的低能见度和不均匀光照,所以在夜间的效果并不是特别好。因此,有学者开发了夜间场景的深度估计方法。但是,夜间深度估计比白天要难,多光谱迁移网络MTN就使用额外的传感器来估计夜间深度估计,采用热成像相机传感器来减少夜间能见度低的影响,还通过一定方式增加了激光传感器以提高额外信息。同时,也有一些方法采用生成式对抗网络来进行夜间深度估计。
虽然夜间单目深度估计已经取得了显著的进展,但由于白天图像和夜间图像之间存在较大的差异,因此这些方法的性能有限。
为了缓解光照变化导致的性能降低问题,ADDS-DepthNet算法采用了一种域分离的网络,将昼夜图像对的信息划分为两个互补的子空间:私有域和不变域。私有域包含昼夜图像的唯一信息(光照等),不变域包含必要的共享信息(纹理等)。同时,为了保证白天和夜晚图像包含相同的信息,域分离网络将白天图像和对应的夜间图像(使用GAN方法生成)作为输入,通过正交性和相似损失学习私有域和不变域的特征提取,从而减小域差距,获得更好的深度图。最后,利用重建和光度损失对互补信息和深度图进行有效地深度估计。
这里多说一句,所谓私有域,可以理解为特征的“个性”;而不变域就类似于特征的“共性”。
03 ADDS算法架构
ADDS算法提出了一种域分离框架来消除干扰的影响,该框架用GAN的思路产生的白天图像和相应的夜间图像作为网络为输入。
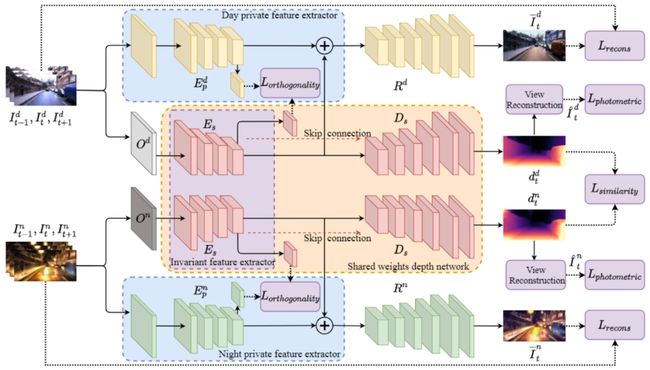
图2 ADDS-Net算法架构[2]
ADDS算法架构包括三个部分:共享权重的深度网络(中间橙色区域粉色结构)、白天私有网络(上方蓝色区域黄色结构)和夜间私有网络(下方蓝色区域绿色结构)。
深度网络的输入是共享权重的白天和夜间图像。该网络首先提取不变特征,然后估计相应的深度图。同时,白天私有特征提取器和夜间私有特征提取器(蓝色区域)分别提取白天和夜晚的特征,这些私有特征受到正交性损失的约束,以获得互补特征,并添加私有和不变特征来重建具有重建损失的原始输入图像。
Part-1 模型输入
对于相同场景里白天和夜间图像,尽管这些图像对的照明非常不同,但其深度信息应该是一致的。这意味着场景对应的白天图像和夜晚图像的基本信息应该是相似的。ADDS算法分别将白天和夜间图像的信息分成两部分:白天和夜晚图像的不变信息(如街道近大远小的规律等),白天和夜间图像的私有信息(如照明等)。
场景的照明随着时间的推移而不同,而场景的深度是恒定的,因此场景的照明分量在自监督深度估计中发挥的作用较少。
此外,很难保证场景的真实世界白天和夜间图像包含除了私有信息(照明等)之外的相同信息不变,因为在室外场景中总是有移动的对象,这将误导网络获取图像的私有和不变信息。因此,ADDS算法使用CycleGAN将白天图像转换为夜间图像,这样白天图像和相应生成的夜间图像被视为输入图像对,它确保了不变信息是一致的,并且所有对象都位于相同的位置,从而减少了在分离私有信息的过程中重要信息的丢失。注意,这里也可以使用其他GAN算法。
Part-2 特征提取器
域分离框架将图像分离为特征层中的两个互补子空间,并且将不变分量用于深度估计。
ADDS算法使用两个网络分支分别在特征级别提取图像的私有和不变信息。给定输入的白天图像序列和相应生成的夜晚图像序列,对于输入的白天图像序列,用白天专用特征提取器提取图像的私有和不变信息;同理,对于输入的夜晚图像序列,也有一个专用的特征提取器用来提取图像的私有和不变信息。由于输入的白天和夜间图像包含相同的基本信息,因此两个特征提取器中提取不变信息那部分是权重共享的。
Part-3 深度图的生成及图像的重建
基于上一步得到的特征重建白天和夜间图像的相应深度图。其中,红色解码器表示共享权重的深度网络的深度恢复模块,黄色解码器和绿色解码器表示白天、夜间图像的重建分支。
Part-4 自监督信号
为了以自监督学习的方式获得全天图像的私有和不变特征并很好地估计深度信息,ADDS算法利用了不同的损失,包括重建损失(Reconstruction Loss)、相似性损失(Similarity Loss)、正交性损失(Orthogonality Loss)和光度损失(Photometric Loss)。
网络的总训练损失为:
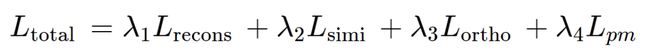
其中,λ1, λ2, λ3, λ4是权重参数。在ADDS算法中,作者根据经验设置为λ1=0.1, λ2=λ3=λ4=1。
04 基于PaddleVideo快速体验ADDS-DepthNet
PaddleVideo是飞桨官方出品的视频模型开发套件,旨在帮助开发者更好地进行视频领域的学术研究和产业实践。下面将简要介绍快速体验步骤。
安装PaddleVideo
# 下载PaddleVideo源码
%cd /home/aistudio/
!git clone https://gitee.com/PaddlePaddle/PaddleVideo.git
# 安装依赖库
!python -m pip install --upgrade pip
!pip install --upgrade -r requirements.txt
下载训练好的ADDS模型
PaddleVideo提供了在Oxford RobotCar dataset数据集上训练好的ADDS模型,为了快速体验模型效果的开发者可以直接下载。
# 下载在Oxford RobotCar dataset数据集上训练好的模型参数
!wget https://videotag.bj.bcebos.com/PaddleVideo-release2.2/ADDS_car.pdparams
# 导出推理模型
%cd /home/aistudio/PaddleVideo
!python tools/export_model.py -c configs/estimation/adds/adds.yaml \
-p ADDS_car.pdparams \
-o inference/ADDS
导出的推理模型保存在
/PaddleVideo/inference
└── ADDS
├── ADDS.pdiparams
├── ADDS.pdiparams.info
└── ADDS.pdmodel
模型推理
使用PaddleVideo/tools/predict.py加载模型参数,并输入一张图片,其推理结果会默认以伪彩的方式保存下模型估计出的深度图。这里提供了两张测试图片,分别是白天和夜间拍摄的照片,拍摄设备是大疆Osmo Action灵眸运动相机。 以下是测试图片和对应的预测深度图:

从测试结果来看,我个人觉得深度图的表现效果在白天相对更好,在晚上则会弱一些,不过也有可能是晚上拍出来的图像质量较差,且环境较暗。但毕竟是基于自监督学习所作,所以结果还不错。
05 总结
论文最后展示了比较有意思的量化结果,这里给大家展示一下:

图3 模型卷积层特征图可视化[2]
这张图展示的是卷积层的特征图可视化。从上到下分别是:(a)白天私有特征;(b)夜间私有特征;(c)白天共有特征;(d)夜间共有特征。第一列显示了相应的输入图像,从左到右的其余列是包含更多信息的前10个特征图。首先看输入,这里展示的图像,不管是白天还是夜间拍摄的图像,都是比较亮的。也就是说,在做深度估计时,图片一定要清晰,上方演示测试的不完美结果可能就是图片不清晰导致的。另外,可视化特征图后,可以在一定程度上看出模型的各个部分是怎么“分工”的。可视化结果里部分的黑色区域说明了有效信息的缺失。有意思的是,对于白天私有特征和夜间私有特征,其浅层特征是比较清晰的,越深越模糊,并且他们对道路两边的物体比较敏感(比如停在道路两边的车辆或是从旁边经过的车辆);而对于白天共有特征和夜间共有特征,可以发现它们的可行驶边缘的两条线比较亮,而道路两边的区域相对来说比较暗。这也反映了私有特征和共有特征确实是互补的。
以上就是基于域分离的全天图像自监督单目深度估计的论文初步解读,欢迎大家来我的AI Studio页面互关交流
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/147378
此外,想探索更多关于自动驾驶相关单目双目深度算法、3D单目感知算法、3D点云感知算法和BEV感知算法的问题,可以前往:
-
Paddle3D
https://github.com/PaddlePaddle/Paddle3D -
PaddleDepth
https://github.com/PaddlePaddle/PaddleDepth
参考文献
[1] Xingshuai Dong, Matthew A. Garratt, Sreenatha G. Anavatti, & Hussein A. Abbass (2023). Towards Real-Time Monocular Depth Estimation for Robotics: A Survey**
[2] Lina Liu, Xibin Song, Mengmeng Wang, Yong Liu, & Liangjun Zhang (2021). Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation… international conference on computer vision.