python爬虫基础小案例, scrapy框架,思路和经验你全都有。
目录
一、scrapy介绍
二、爬取步骤
三、代码
1、创建爬虫项目 scrapy startproject 项目名字 注意: 项目名字不能出现中文,也不能以数字开头。
2、创建爬虫文件
3.进入itmes.py
4.进入spiders
5.进入pipelines.py
四、运行scrapy 文件
一、scrapy介绍
简单介绍一下scrapy吧。
Scrapy 框架是一个基于Twisted的一个异步处理爬虫框架,应用范围非常的广泛,常用于数据采集、网络监测,以及自动化测试等。
Scrapy 框架主要由五大组件组成,它们分别是:
- 调度器(Scheduler) :它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- 下载器(Downloader) :负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
- 爬虫(Spider):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
- 实体管道(Item Pipeline):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Scrapy引擎(Scrapy Engine):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
这么说大家可能还是不太明白,直接上图(此图来自一位bilibili的up主):

步骤如下:
注:红色字体部分是给下一个步骤的数据
spiders url --》引擎(Scrapy Engine)url --》调度器 (Scheduler)请求 --》引擎(Scrapy Engine)请求 --》下载器(Downloader) 请求 --》互联网 数据 --》引擎(Scrapy Engine)数据 --》spiders 解析数据结果 --》引擎(Scrapy Engine)if(就交给管道下载数据) if(有 url 则重复上面步骤) 注意的一点是连个可以同时存在也可以单独存在
话不多说,直接开始干!!!!
二、爬取步骤
这次要爬取的是当当网中的电子书
点击此处,进入网址,可以看到很多的书。而我们需要的是数据:书的图片,书名,作者,价格
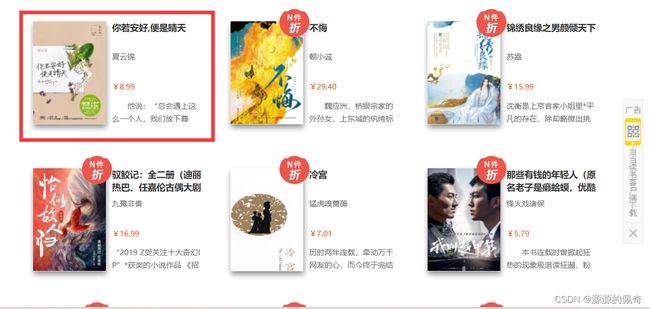
1.爬取思路
首先查看有多少页,会发现,这个网站没有页数,究其原因,是一个滚动条的 ajax 请求,当滚动条滑倒最底下的时候,就发出一条请求。说这么一堆可能听不懂,上图。
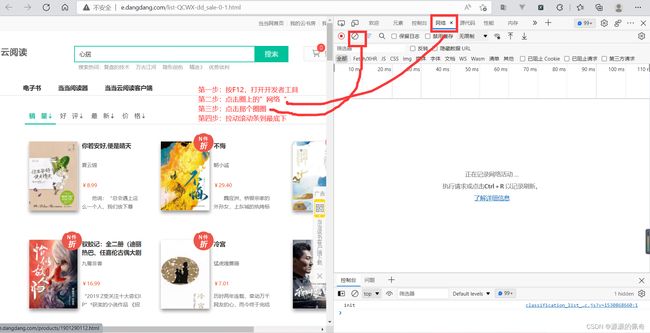
这时候你会发现里面多了很多条请求,我们直接看到最上面一条,因为是ajax的请求,肯定是一个json的一个嵌套格式,直接打开英文是”response“,中文是“响应”,我的是中文所以就点击响应,看看有没有我们所需要的数据。
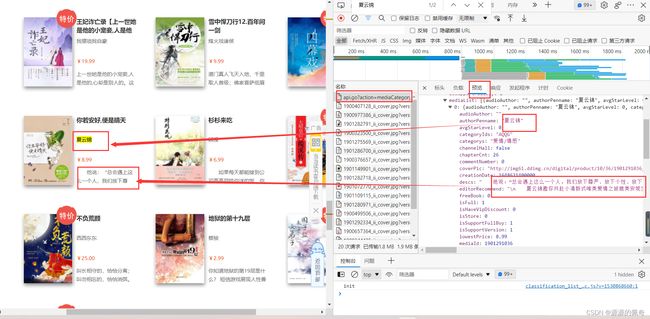
有数据吧,那就是他了。
http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerialNo=html5&macAddr=html5&channelType=html5&permanentId=20220424124301850188613824148624365&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=63&end=83&category=QCWX&dimension=dd_sale&order=0复制url 放到搜索栏里面在进行请求一次,检验一下是不是正确的。

结果如下,密密麻麻的数据,有密集恐惧症的估计得没,而我们今天的任务就是从这些数据中提取出我们想要的数据。

要多页爬取,所以我们还要刚才一样在操作一次,下一条的请求URL,和这条url有什么区别。
这时候就有两条url
http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerialNo=html5&macAddr=html5&channelType=html5&permanentId=20220424124301850188613824148624365&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=63&end=83&category=QCWX&dimension=dd_sale&order=0
http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerialNo=html5&macAddr=html5&channelType=html5&permanentId=20220424124301850188613824148624365&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=84&end=104&category=QCWX&dimension=dd_sale&order=0
规律找到了,很简单。start(从第几本书开始) end(结束的那一本书)
思路有了,那就开始写代码
三、代码
在python 中的 Terminal 也就是终端中,创建scrapy框架
1、创建爬虫项目 scrapy startproject 项目名字
注意: 项目名字不能出现中文,也不能以数字开头。

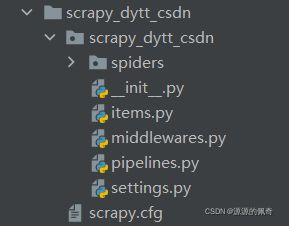
项目结构如下:玩过django的人应该都知道
2、创建爬虫文件
在spiders文件夹中创建爬虫文件 cd 项目的名字\项目的名字\spiders 进入spiders文件后创建爬虫文件: 创建爬虫文件 scrapy genspider 爬虫文件的名字 要爬取的网页
注:URL记得用 ” “包起来不然可能会报错
![]()
创建成功后会出现,也就是我们刚刚创建的文件夹
3.进入itmes.py
数据取到后接下里就是定义数据结构了
import scrapy
class ScrapyDyttCsdnItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#定义好数据结构
name = scrapy.Field() #书名
author = scrapy.Field() #作者
imgSrc = scrapy.Field() #图片
price = scrapy.Field() #价格
pass4.进入spiders
进入我们刚刚创建好的文件 spiders文件下的 dytt.py
进入该文件,会发现,看注释
import scrapy
class DyttSpider(scrapy.Spider):
name = 'dytt'
#链接范围,不在该范围内的url请求,都会报错,一般只写域名
allowed_domains = ['e.dangdang.com']
#执行文件请求的url,也就是我们创建文件的是给的url,
#但是又不懂是不是,这是因为框架内部的原因弄的,大家不用在意,把刚才的url重新复制在里面就可以了。
#改一下strat 和 end 这两个是前面提过的 strat=0 和 end=20
#意思也就是从索引0开始,一直到索引20,也就是21本书
start_urls = ['http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerialNo=html5&macAddr=html5&channelType=html5&permanentId=20220424124301850188613824148624365&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=0&end=20&category=QCWX&dimension=dd_sale&order=0']
def parse(self, response):
#页面返回来的数据全在response 中,response.text 看看数据有没有获取到
print(response.text)
3、运行爬虫代码
scrapy crawl 爬虫文件的名字
eg: scrapy crawl dytt
![]()
密密麻麻的数据已经获取到了,说明代码已经好了,接下来就是解析数据了,看到这些数据别说是我们了,就算哪些最牛逼的大神都头痛,有没有好的办法呢?当然是有的。

既然书是从strat开始 end结束,那能不能只获取一本书呢。
试试,改 strat=0 和 end=0 只获取一本书
在浏览器输入 根改后的链接
http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerialNo=html5&macAddr=html5&channelType=html5&permanentId=20220424124301850188613824148624365&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=0&end=0&category=QCWX&dimension=dd_sale&order=0结果如下,这样是不是就舒服多了,接下来就是了解 json 数据结构 ,找到我们需要数据的位置

结构已近给你们找好了,如果你们也想自己找的话可以试试,挺好玩的。
print(doc['data']["saleList"][0]['mediaList'][0]["authorPenname"]) #作者
print(doc['data']["saleList"][0]['mediaList'][0]["coverPic"]) #图片
print(doc['data']["saleList"][0]['mediaList'][0]["title"]) #书名字
print(doc['data']["saleList"][0]['mediaList'][0]["lowestPrice"]) #价格那接下来就是解析数据了
import scrapy
import json
class DyttSpider(scrapy.Spider):
name = 'dytt'
#链接范围,不在该范围内的url请求,都会报错,一般只写域名
allowed_domains = ['e.dangdang.com']
#执行文件请求的url,也就是我们创建文件的是给的url,
#但是又不懂是不是,这是因为框架内部的原因弄的,大家不用在意,把刚才的url重新复制在里面就可以了。
#改一下strat 和 end 这两个是前面提过的 strat=0 和 end=20
# 意思也就是从索引0开始,一直到索引20,也就是21本书
start_urls = ['http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerialNo=html5&macAddr=html5&channelType=html5&permanentId=20220424124301850188613824148624365&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=0&end=20&category=QCWX&dimension=dd_sale&order=0']
def parse(self, response):
json_list = json.loads(response.text)
# json_list['data']['saleList'] 获取每一本书的信息
for i in json_list['data']['saleList']: #遍历每一本书 获取其中需要的数据
author = i['mediaList'][0]["authorPenname"]
imgSrc = i['mediaList'][0]["coverPic"]
name = i['mediaList'][0]["title"]
price =i['mediaList'][0]["lowestPrice"]
print(author,name,imgSrc,price)
获取数据如下:
这样是不是就舒服多了

接下来把解析好的数据 给 items.py 中的类,让items.py 给数据进行封装 dict 字典格式
import scrapy
import json
class DyttSpider(scrapy.Spider):
name = 'dytt'
#链接范围,不在该范围内的url请求,都会报错,一般只写域名
allowed_domains = ['e.dangdang.com']
#执行文件请求的url,也就是我们创建文件的是给的url,
#但是又不懂是不是,这是因为框架内部的原因弄的,大家不用在意,把刚才的url重新复制在里面就可以了。
#改一下strat 和 end 这两个是前面提过的 strat=0 和 end=20
# 意思也就是从索引0开始,一直到索引20,也就是21本书
start_urls = ['http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerialNo=html5&macAddr=html5&channelType=html5&permanentId=20220424124301850188613824148624365&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=0&end=20&category=QCWX&dimension=dd_sale&order=0']
def parse(self, response):
json_list = json.loads(response.text)
# json_list['data']['saleList'] 获取每一本书的信息
for i in json_list['data']['saleList']: #遍历每一本书 获取其中需要的数据
author = i['mediaList'][0]["authorPenname"]
imgSrc = i['mediaList'][0]["coverPic"]
name = i['mediaList'][0]["title"]
price =i['mediaList'][0]["lowestPrice"]
#导入items.py 中的类 也就是我们刚刚定义好的数据结构 会定义成一个字典格式的数据结构
from scrapy_dytt_csdn.items import ScrapyDyttCsdnItem
book = ScrapyDyttCsdnItem(author=author,imgSrc=imgSrc,name=name,price=price)最后就是下载数据,需要交给管道,pipelines.py 文件
import scrapy
import json
class DyttSpider(scrapy.Spider):
name = 'dytt'
#链接范围,不在该范围内的url请求,都会报错,一般只写域名
allowed_domains = ['e.dangdang.com']
#执行文件请求的url,也就是我们创建文件的是给的url,
#但是又不懂是不是,这是因为框架内部的原因弄的,大家不用在意,把刚才的url重新复制在里面就可以了。
#改一下strat 和 end 这两个是前面提过的 strat=0 和 end=20
# 意思也就是从索引0开始,一直到索引20,也就是21本书
start_urls = ['http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerialNo=html5&macAddr=html5&channelType=html5&permanentId=20220424124301850188613824148624365&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=0&end=20&category=QCWX&dimension=dd_sale&order=0']
def parse(self, response):
json_list = json.loads(response.text)
# json_list['data']['saleList'] 获取每一本书的信息
for i in json_list['data']['saleList']: #遍历每一本书 获取其中需要的数据
author = i['mediaList'][0]["authorPenname"]
imgSrc = i['mediaList'][0]["coverPic"]
name = i['mediaList'][0]["title"]
price =i['mediaList'][0]["lowestPrice"]
#导入items.py 中的类 也就是我们刚刚定义好的数据结构 会定义成一个字典格式的数据结构
from scrapy_dytt_csdn.items import ScrapyDyttCsdnItem
book = ScrapyDyttCsdnItem(author=author,imgSrc=imgSrc,name=name,price=price)
#把数据交给管道 piplines.py 进行数据的下载
yield book
5.进入pipelines.py
进行数据的下载
class ScrapyDyttCsdnPipeline:
#程序执行前第一个开始此方法,该方法是框架内置方法,方法名一定不能修改,否则会报错
def open_spider(self):
#打开文件
self.fp = open("book.json",'w',encoding='utf-8')
def process_item(self, item, spider):
#item 中就是 dytt.py 文件中 yield book 中返回的数据
#注意 item 要转化成字符串类型,否则会报错
self.fp.write(str(item))
return item
def closer_spider(self):
#关闭文件
self.fp.close()让后在settings.py 文件中把这一行的注释解开,也就是打开管道,管道不带开,数据怎么进去呢,更别提下载数据了。
为了方便大家寻找 进入settings 文件后 按住 crat+f 进行搜索这个 ITEM_PIPELINES,就能找到了

四、运行scrapy 文件
在终端 输入
scrapy crawl 爬虫文件的名字
scrapy crawl dytt
![]()
输入之后进行按下回车 就可以了
最后文件book.json 文件会在 spiders文件夹下

总共105条,一本书5条数据
105/5=21(本)
所有数据都在这里了,一点都没漏,Perfect!!!
还有不懂的地方可以评论,看到了会及时回复的,谢谢大家的支持。