cortex-M3/M4存储器系统
一、存储器系统特性简介
cortex-m 处理器可以对32位存储器进行寻址,因此存储器空间能够达到4GB。存储器空间是统一,这也意味着指令和数据共用相同的地址空间。根据架构定义,4GB的存储器空间被分为了多个区域。另外,cortex-M3和cortex-M4处理器的存储器系统支持多个特性:
①多个总线接口,指令和数据可以同时访问(哈佛总线架构)
②基于AMBA(高级微控制器总线架构)的总线接口设计,实际上也是一种片上总线标准:用于存储器和系统总线流水线操作的AHB(AMBA高性能总线)Lite协议,以及用于和调试部件通信的APB(高级外设总线)协议。
③同时支持小端和大端的存储器系统。
④支持非对齐数据传输
⑤支持排他传输(用于具有嵌入式OS或RTOS的系统的信号量操作)
⑥可位寻址的存储器空间(位段)
⑦不同存储器区域的存储器属性和访问权限
⑧可选的存储器保护单元(MPU)。若MPU存在,则可以在运行时设置存储器属性和访问权限配置。
二、存储器映射
在4GB可寻址的存储器空间中,有些部分被指定为处理器中的内部外设,如NVIC何调试部件等。这些内部部件的存储器位置是固定的,另外存储器空间在架构上被划分为如下图所示的多个存储器区域,这种处理使得:
处理器设计支持不同种类的存储器和设备
系统可以达到更优的性能
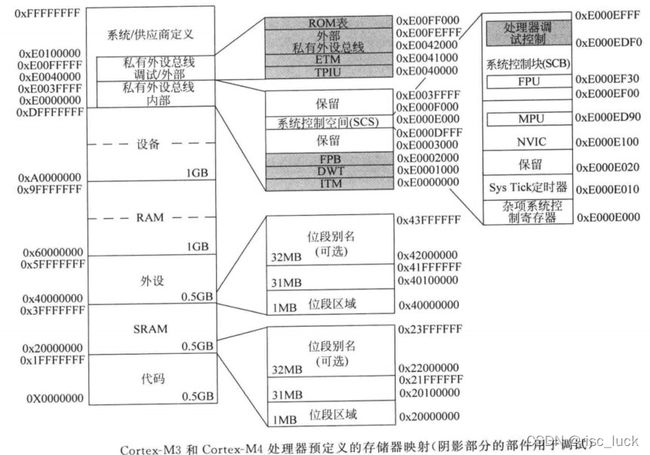
尽管预定义的存储器映射是固定的,架构仍然具有高度的灵活性,芯片设计者可以在他们的产品中加入具有差异化的不同存储器外设。
| 区域 | 地址范围 | 描述 |
|---|---|---|
| 代码 | 0x00000000 ---- 0x1FFF FFFF | 512MB的存储器空间,主要用于程序代码,包括作为程序存储器一部分的默认向量表,该区域也允许数据访问 |
| SRAM | 0X20000000 —0X3FFFFFFF | SRAM区域位于存储器空间中的下一个512MB,主要用于连接SRAM,其大都为片上SRAM,不过对存储器的类型没有什么限制。若支持可选的位段特性,则SRAM区域的第一个1M可位寻址,还可以在这个区域中执行程序代码。 |
| 外设 | 0x40000000 — 0x5FFFFFFF | 外设存储器区域的大小同样为512MB,而且多数用于片上外设。和SRAM区域类似,若支持可选的位段特性,则外设区域的第一个1MB是可位寻址的。 |
| RAM | 0x60000000 — 0x9FFFFFFF | RAM区域包括两个512MB存储器区域(总共1GB),用于片外存储器等其他RAM,且可存放程序代码和数据 |
| 设备 | 0xA0000000—0xDFFFFFFF | 设备区域包括两个512MB存储器空间(总共1GB),用于片外外设等其他存储器 |
| 系统 | 0xE0000000 — 0XFFFFFFFF | 系统区域可分为几个部分:①内部私有外设总线(PPB),0XE0000000 ----0XE003FFFF PPB用于访问NVIC 、SysTick、MPU等系统部件,以及Cortex-M3/M4内的调试部件。多数情况下,该存储器空间只能由运行在特权状态的程序代码访问。 ②外部私有外设总线(PPB)0XE0040000 ----0XE00FFFFF 另外一个PPB区域可用于其他的可选调试部件,芯片供应商也可以增加自己的调试或其他特定部件。该存储器空间只能由运行在特权状态的程序代码访问。需要注意的是,该总线上调试部件的基地址可能会被芯片设计者修改。③供应商定义区域 0xE0100000 — 0XFFFFFFFF 剩下的存储器空间用于供应商定义的部件,多数情况下是用不上的 |
尽管可以将程序存放在SRAM和RAM区域并执行,处理器设计在进行这种操作时效果并非最优的,在取每个指令时还需要一个额外的周期。因此,在通过系统总线执行程序代码时性能会稍微低一些。程序不允许在外设、设备和系统存储器区域中执行。
存储器映射中存在多个内置部件,其具体功能描述如下:
| 部件 | 描述 |
|---|---|
| NVIC | 嵌套向量中断控制器 异常(包括中断)处理的内置中断控制器 |
| MPU | 存储器保护单元 可选的可编程单元,用于设置各存储器区域的存储器访问权限和存储器访问属性(特性或行为),有些CORTEX-M3/M4微控制器中可能会没有MPU |
| SysTick | 系统节拍定时器 24位定时器,主要用于产生周期性的OS中断。若未使用OS,还可被应用程序代码使用 |
| SCB | 系统控制块 用于控制处理器行为的一组寄存器,并可提供状态信息 |
| FPU | 浮点单元 这里存在多个寄存器,用于控制浮点单元的行为,并可提供状态信息。FPU仅在cortex-m4中存在 |
| FPB | Flash 补丁和断点单元 用于调试操作,其中包括最多8个比较器,每个比较器都可被配置为产生硬件断点事件。例如,在执行断点地址处的指令时,它还可以替换原先的指令,因此可为固定的程序实现补丁机制 |
| DWT | 数据监视点和跟踪单元 用于调试和跟踪操作,其中包括最多4个比较器,每个比较器都可被配置为产生数据监视点时间,如在特定的存储器地址区域被软件访问时。它还可以产生数据跟踪包,供调试器使用以观察监控的存储器位置 |
| ITM | 指令跟踪宏单元 用于调试和跟踪的部件。软件可以利用它产生可被跟踪接口捕获的数据跟踪。它还可以在跟踪系统中生成时间戳包 |
| ETM | 嵌入式跟踪宏单元 产生调试软件可用的指令跟踪的部件 |
| TPIU | 跟踪端口接口单元 该部件可以将跟踪包从跟踪源转换到跟踪接口协议,这样可以用最少的引脚捕获跟踪的数据 |
| ROM表 | ROM表 调试工具用的简单查找表,表示调试和跟踪部件的地址,以便调试工具识别出系统中可用的调试部件。它还提供了用于系统识别的ID寄存器 |
三、连接处理器到存储器和外设
cortex-m 处理器提供了基于AMBA的通用总线接口。AMBA支持多种总线协议,对于Cortex-M3和Cortex-M4处理器,主要的总线接口使用AHB Lite协议,而APB协议则用作私有外设总线(PPB),它主要用于调试部件。基于APB的其他总线部分则可以利用其他的总线桥部件添加到系统总线上。为了提高性能,CODE存储器区域已经将总线接口从系统总线中独立出来,如下图所示,这样数据访问和取指可以并行执行。

这种分离的总线结构还会加快中断响应,这是因为在中断处理期间,栈访问和读取程序映像中的向量表可以同时执行。
可以在处理器的总线接口中插入等待状态,因此,高速运行的cortex-M处理器可以访问速度较低的存储器或外设。总线接口还支持错误响应。例如,若产生了错误,当处理器访问未在合法存储器区域内的地址时,总线系统会对处理器返回错误响应,这样会触发错误异常,随后可由运行在处理器上的软件报告这一情况或对其进行处理。
在简单的微处理器设计中,程序存储器一般会被连接到I-CODE 和D-CODE总线,而SRAM和外设则会被连到系统总线。cortex-m3或cortex-m4的一种简单设计如下图所示:
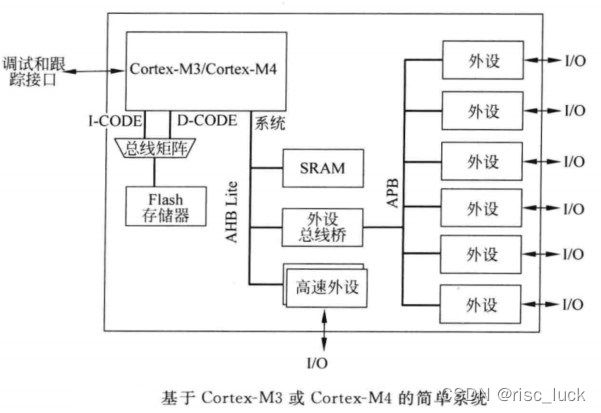
多数外设通常会被连接到独立的外设总线段,对于许多现有的cortex-m3 和cortex-m4产品,可以在设计中找到多个外设总线段。按照这种方式,每个总线都可以运行在不同的速度下以节省功耗。有些情况下,这样还可以带来更大的系统带宽(例如,外设系统有时需要支持以太网的DMA访问和高速USB)。
四、数据对齐和非对齐数据访问支持
由于存储器系统为32位的(至少从编程模型的角度来看是这样的),大小为32位或16位可以是对齐也可以是不对齐的。对齐传输的意思是地址值为大小(以字节为单位)的整数倍。如字大小的对齐传输可以执行的地址为0x00000000、0x00000004、…0x00001000等;半字大小的对齐传输可以执行的地址则为0x00000000、0x00000002、…0x00001000等。对齐和非对齐传输的实例如下图所示:
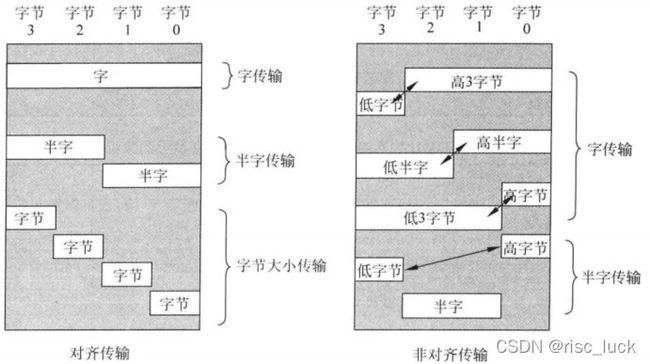
一般来说,多数经典ARM处理器(ARM7 ARM9 ARM10)都只允许对齐传输,这就意味着在访问存储器时,字传输地址的bit[1]和bit[0]为0,半字传输地址的bit[0]为0.cortex-m3、cortex-m4处理器都支持普通存储器访问(LDR LDRH STR以及STRH指令)的非对齐数据传输。另外还有一些限制:
①多加载/存储指令不支持非对齐传输
②栈操作指令(PUSH/POP)必须是对齐的。
③排他访问(如LDREX或STREX)必须是对齐的,否则就会触发错误异常(使用错误)。
④位段操作不支持非对齐传输,因为其结果是不可预测的。
当非对齐传输是由处理器发起时,它们实际上会被处理器的总线接口单元转换为多个对齐传输。这个转换是不可见的,因此应用程序开发人员无需考虑这个问题。不过当产生非对齐传输时,它会被拆分为几个对齐传输,因此本次数据访问会花费更多的时钟周期,可能对需要高性能的情形不利。若追求更高的性能,确保数据处于合适的对齐是有必要的。
多数情况下,C编译器不会产生非对齐传输,它只会在以下情况中出现:
① 直接操作指针
② 包含非对齐数据的数据结构增加 “_packed” 属性
③ 内联/嵌入式汇编代码
也可以对Cortex-m3 或cortex-m4处理器进行设置,使得非对齐传输出现时可以出发异常,这样就需要设置配置控制寄存器的UNALIGN_TRP(非对齐陷阱)位以及系统控制块SCB中CCR(地址0xE000ED14)。这样处理之后,Cortex-m3 或cortex-m4处理器就可以在出现非对齐传输时产生使用错误异常。这对于软件开发过程中测试程序是否会产生非对齐传输非常有用。
五 位段操作
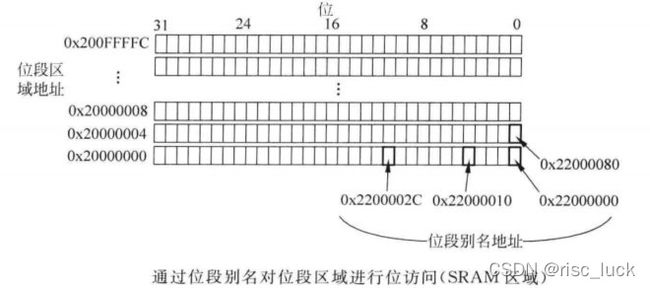
利用位段操作,一次加载/存储操作可以访问(读/写)一个位。对于Cortex-m3 或cortex-m4处理器,两个名为位段区域的预定义存储器区域支持这种操作,其中一个位于SRAM区域的第一个1MB,另一个则位于外设区域的第一个1MB。这两个区域可以同普通存储器一样访问,而且还可以通过名为位段别名的一块独立的存储器区域进行访问。当使用位段别名地址时,每个位都可以通过对应的字对齐地址的最低(LSB)单独访问,如下图所示:
例如,要设置地址0x20000000处字数据的第2位,除了使用三条指令读取数据、设置位,然后将结果写回之外,还可以使用一条单独的指令,如下图所示:

类似地,若需要读出某存储器位置中的一位,位段特性也可以简化应用程序代码。例如若需要确定地址0x20000000的第2位,可以采取下图所示的步骤:

在位段区域,每个字由位段别名地址区域32个字的LSB表示。实际情况是,当访问位段别名地址时,该地址就会被重映射到位段地址。对于读操作,字被读出且选定位的位置被移到读返回数据的LSB。对于写操作,待写的位数据被移到所需的位置,然后执行读–修改—写操作。
可以进行位段操作的存储器区域有两个:
0x20000000 ~ 0x200FFFFFF(SRAM ,1MB)
0x40000000 ~ 0x400FFFFFF(外设, 1MB)
对于SRAM存储器区域,位段别名的重映射,如下表所示
| 位段区域 | 别名等价 |
|---|---|
| 0x20000000 bit[0] | 0x22000000 bit[0] |
| 0x20000000 bit[1] | 0x22000004 bit[0] |
| 0x20000000 bit[2] | 0x22000008 bit[0] |
| … | … |
| 0x20000000 bit[31] | 0x2200007C bit[0] |
| 0x20000004 bit[0] | 0x22000080 bit[0] |
| … | … |
| 0x200FFFFC bit[31] | 0x23FFFFFC bit[0] |
类似地,外设存储器区域的位段可以通过位段别名地址访问,如下表所示
| 位段区域 | 别名等价 |
|---|---|
| 0x40000000 bit[0] | 0x42000000 bit[0] |
| 0x40000000 bit[1] | 0x42000004 bit[0] |
| 0x40000000 bit[2] | 0x42000008 bit[0] |
| … | … |
| 0x40000000 bit[31] | 0x4200007C bit[0] |
| 0x40000004 bit[0] | 0x42000080 bit[0] |
| … | … |
| 0x400FFFFC bit[31] | 0x43FFFFFC bit[0] |
在访问位段别名地址时,只会用到数据的LSB(bit[0])。另外,对位段别名区域的访问不应该是非对齐的。若非对齐访问在位段别名地址区域内支线,结果是不可预测的。
5.1 位段操作的优势
位段操作的优势有哪些呢?
①可以利用其实现从通用目的输入/输出端口往串行设备的串行数据传输。由于串行数据和时钟信号的访问是分开的,因此应用程序代码实现起来也非常简单。
②位段操作可以简化跳转决断。例如,若跳转应该基于外设中某个状态寄存器的一位来执行,除了读取整个寄存器、屏蔽未使用的位、比较和跳转,还可以将操作简化为 通过位段名读取状态位(得到0或1)、比较和跳转。
③除了可以提高少数几个指令的位操作的速度外,M3/M4处理器的位段特性还可用于资源(如I/O端口的各引脚)被不止一个进程共用的情形。位段操作最重要的一个优势或特点在于它的原子性。利用位段特性,可以避免竞态现象,因为读–修改—写时在硬件等级执行的,是原子性的。
④位段特性可用于存储和处理SRAM区域中的Boolean数据。例如,多个boolean数据可被合并到同一个存储器位置中,以节省存储器空间。不过若通过位段别名地址区域执行操作,对每个位的访问仍然是独立的。
位段操作并不局限于字传输,字节传输或半字传输也可以执行。例如在用字节访问指令(LDRB/STRB)访问位段别名地址区域时,所产生的对位段区域的访问就是字节大小的。类似地,对位段别名的半字传输(LDRH/STRH)则会被重映射到对位段区域的半字大小的传输。
在位段别名地址上执行非字传输时,地址值仍然应该是字对齐的。
5.2 C程序实现的位段操作
C/C++语言本身不支持位段操作。例如,C编译器就不知道同一个存储器可以用两个不同的地址来寻址,而且也不了解对位段别名的访问只会操作存储器位置的LSB。要用C实现位段特性,最简单的方法就是分别声明存储器位置的地址和位段别名。例如:
#define DEVICE_REG0 *((volatile unsigned long *) (0x40000000))
#define DEVICE_REG0_BIT0 *((volatile unsigned long *) (0x42000000))
#define DEVICE_REG0_BIT1 *((volatile unsigned long *) (0x42000004))
......
DEVICE_REG0 = 0XAB; //使用普通地址访问硬件寄存器
...
DEVICE_REG0_BIT1 = 0x1;//利用位段特性通过位段别名地址设置第1位
也可以利用C语言的宏定义简化对位段别名的访问。例如,可以实现一个宏,将位段地址和位数转换为位段别名地址,并且用另外一个宏将地址作为一个指针来访问存储器地址。
//将位段地址和位编号转换为位段别名地址
#define BIT_BAND(addr, bitnum) ((addr&0xf0000000)+0x20000000 + ((addr&0xfffff)<<5)+(bitnum<<2))
//将地址转换为指针
#define MEM_ADDR(addr) *((volatile unsigned long*)) (addr)
上面的例子可以重写如下:
MEM_ADDR(DEVICE_REG0) = 0xAB; //利用普通地址访问硬件寄存器
MEM_ADDR(BIT_BAND(DEVICE_REG0,1)) = 0x1; //利用位段特性设置第1位
需要注意的是,在使用位段特性时,可能需要将访问的变量定义为volatile。C编译器不知道同一个数据会以两种不同的地址访问,因此需要利用volatile属性,以确保在每次访问变量时,操作的是存储器位置而不是处理器内的本地备份。
六、默认的存储器访问权限
cortex-m3、cortex-m4的处理器映射具有默认的存储器访问权限配置,用于程序(非特权)不允许访问NVIC等系统控制存储器空间。在没有MPU或MPU存在但未使能时会使用默认的存储器访问权限。
若MPU存在且使能,MPU设置所定义的其他访问权限也会决定是否允许用户访问其他的存储器区域。
默认的存储器访问权限如下表所示:
| 存储器区域 | 地址 | 用户程序的非特权访问 |
|---|---|---|
| 供应商定义 | 0xE0100000 ~ 0xFFFFFFFF | 全访问 |
| ROM表 | 0xE00FF000 ~ 0xE00FFFFF | 禁止,非特权访问导致总线错误 |
| 外部PPB | 0XE0042000 ~ 0XE00FEFFF | 禁止,非特权访问导致总线错误 |
| ETM | 0XE0041000 ~ 0XE0041FFF | 禁止,非特权访问导致总线错误 |
| TPIU | 0XE0040000 ~ 0XE0040FFF | 禁止,非特权访问导致总线错误 |
| 内部PPB | 0XE000F000 ~ 0XE003FFFF | 禁止,非特权访问导致总线错误 |
| NVIC | 0XE000E000 ~ 0XE000EFFF | 禁止,非特权访问导致总线错误 |
| FPB | 0XE0002000 ~ 0XE0003FFF | 禁止,非特权访问导致总线错误 |
| DWT | 0XE0001000 ~ 0XE0001FFF | 禁止,非特权访问导致总线错误 |
| ITM | 0XE0000000 ~ 0XE0000FFF | 读允许,写忽略,除非是非特权访问激励端口(实时可配置) |
| 外部设备 | 0XA0000000 ~ 0XDFFFFFFF | 全访问 |
| 外部RAM | 0X60000000 ~ 0X9FFFFFFF | 全访问 |
| 外设 | 0X40000000 ~ 0X5FFFFFFF | 全访问 |
| SRAM | 0X20000000 ~ 0X3FFFFFFF | 全访问 |
| 代码 | 0X00000000 ~ 0X1FFFFFFF | 全访问 |
当非特权访问被阻止时,错误异常就会立即产生。根据总线错误异常是否使能以及优先级配置,它可以是硬件错误或总线错误异常。
七、存储器访问属性
存储器映射描述了每个存储器区域所包含的部分,除了解析被访问的存储器块或设备外,存储器映射还定义了访问的存储器属性。Cortex-M3和cortex-M4处理器中存在的存储器属性包括以下几种:
①可缓冲。当处理器继续执行下一条指令时,对存储器的写操作可由写缓冲执行。
②可缓存。读存储器所得到的数据可被复制到存储器缓存,以便下次再访问时可以从缓存中取出这个数值,这样可以加快程序执行。
③可执行。处理器可以从本存储器区域取出并执行程序代码
④可共享。这种存储器区域的数据可被多个总线主设备共用。存储器系统需要确保可共享存储器区域中不同总线主设备间数据的一致性。
在每次指令和数据传输时,处理器总线接口都会将存储器访问属性信息输出到存储器系统。若MPU存在且MPU区域配置和默认的不同,则默认的存储器属性设置会被覆盖。对于现有的多数cortex-m3和cortex-m4微控制器,只有可执行和可缓冲属性会影响到应用程序的执行。可缓存和可共享属性则一般由缓存控制器使用,用以确定存储器类型和缓存设计。如下表所示:
| 可缓冲 | 可缓存 | 存储器类型 |
|---|---|---|
| 0 | 0 | 强序,cortex-m3和cortex-m4处理器会在继续下一个操作前等待总线接口上的传输完成。从架构上来说,处理器可以继续执行下一个操作,不过无法启动另一个对类型为强序或设备的存储器的访问。 |
| 1 | 0 | 设备。若下一条指令也是存储器访问,则cortex-m3和cortex-m4设备可以在使用写缓冲处理传输的同时,继续执行下一条指令。从架构上来说,处理器可以继续执行下一个操作,不过无法启动另一个对类型为强序或设备的存储器的访问 |
| 0 | 1 | 具有写通(WT)缓存的普通存储器 |
| 1 | 1 | 具有写回(WB)缓存的普通存储器 |
若系统中存在多个处理器以及具有缓存相关性控制的缓存单元就需要用到可共享属性。当数据访问显示为可共享时,缓存控制器需要确保该数值同其他缓存单元是一致的,这是因为它可能被另外一个处理器缓存并修改。
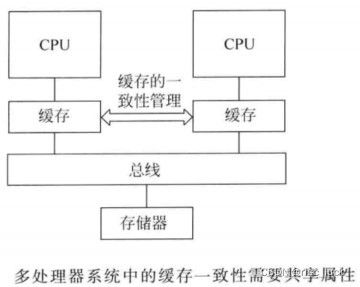
尽管cortex-m3和cortex-m4处理器中并不存在缓存存储器或微控制器,微控制器中仍然可以加上缓存单元,它可以利用存储器属性信息定义存储器访问行为。另外,根据芯片生产商所使用的存储器控制器,缓存属性可能还会影响到片上和片外存储器控制器的操作。可缓冲属性用于处理器内部。为了提供更优的性能,cortex-m3和cortex-m4处理器支持总线接口上的单入口写缓冲。即使总线接口上的实际传输需要多个时钟周期才能完成,对可缓冲存储器区域的写操作可在单个时钟周期内执行,接下来会继续执行下一条指令。
每个存储器区域的默认访问属性如下表所示,其中,XN表示永不执行,这也意味着本区域内不允许程序执行。
| 区域 | 存储器/设备类型 | XN | 缓存 | 备注 |
|---|---|---|---|---|
| CODE存储器区域(0X00000000 ~ 0X1FFFFFFF) | 普通 | — | WT | 内部写缓冲使能,输出的存储器属性始终为可缓存以及不可缓冲 |
| SRAM存储器区域(0X20000000 ~ 0X3FFFFFFF) | 普通 | — | WB-WA | 写回,写分配 |
| 外设区域(0X40000000 ~ 0X5FFFFFFF) | 设备 | Y | — | 可缓冲,不可缓存 |
| RAM区域(0X60000000 ~ 0X7FFFFFFF) | 普通 | — | WB–WA | 写回,写分配 |
| RAM区域(0X80000000 ~ 0X9FFFFFFF) | 普通 | — | WT | 写通 |
| 设备(0XA0000000 ~ 0XBFFFFFFF) | 设备 | Y | – | 写缓冲,不可缓存 |
| 设备(0XC0000000 ~ 0XDFFFFFFF) | 设备 | Y | – | 写缓冲,不可缓存 |
| 系统-PPB(0XE0000000 ~ 0XE00FFFFF) | 强序 | Y | – | 不可缓冲,不可缓存 |
| 系统–供应商定义(0XE0100000 ~ 0XFFFFFFFF) | 设备 | Y | – | 可缓冲,不可缓存 |
注意,对于从版本1开始的cortex-M3和所有发布版的cortex-M4处理器,处理器的I-CODE和D-CODE总线接口上的CODE区域存储器属性信号被硬件连接表示为可缓存和不可缓冲。MPU配置不能将其覆盖,只会影响到处理器外的缓存存储器系统(如2级缓存和某些具有缓存特性的存储器控制器)。在处理器内,内部写缓冲仍可用作访问CODE区域的写缓冲。
八、排他访问
cortex-m3和cortex-m4处理器不支持SWP指令(交换)。该指令一般用于ARM7TDMI等传统ARM处理器的信号量操作,目前它已被排他访问操作替代。
信号量常用于给应用分配共享资源。当某个共享资源只能满足一个客户端或应用处理器时,还可将其称为互斥体(MUTEX)。在这种情况下,若某个资源被一个进程占用,它就会被锁定到这个进程,在锁定解除前无法用于其他进程。要创建MUTEX信号量,需要将某个存储器地址定义为锁定状态,以表示共享资源是否已被一个进程锁定。当进程或应用要使用资源时,它需要首先检查资源是否已被锁定,若未被使用,则可以设置锁定状态,表示本资源目前已被锁定。对于传统的ARM处理器,对锁定状态的访问由SWP指令执行,它可以确保读写锁定状态操作的原子性,避免资源被两个进程同时锁定。
对于较新的ARM处理器,读/写访问可由独立的总线执行。这样,由于锁定传输流程中的读写必须要位于同一个总线,因此SWP指令无法保证存储器访问的原子性,锁定传输也就被排他访问取代了。排他访问操作的理念相当简单,不过和SWP不同。有了排他访问,信号量的存储器位置被另一个总线主控设备或同一个处理器上运行的另一个进程访问也就有了可能性,如下图所示。

若出现了下面的条件之一,排他写(如STREX)可能会失败:
①执行了CLREX指令
②产生了上下文切换(如中断)
③前面没有执行过LDREX
④外部硬件通过总线接口上的边带信号向处理器返回排他失败状态
若排他存储得到一个失败状态,则存储器中不会进行实际的写操作,因为它可能已经被处理器内核或外部硬件阻止。
要使排他传输能在多处理器环境中正常工作,需要额外增加一个名为排他传输监控的硬件。该监控会检查到共享地址的传输,并告知处理器排他访问是否成功。处理器总线接口还向本监控提供了额外的控制信号,以表明本次传输是否为排他访问。
若存储器设备已被领一个总线主设备访问,且处于排他读和排他写之间,在处理器试图进行排他写时,排他访问监控会通过总线系统产生一个排他失败状态。这样会将排他写的返回状态置1,对于排他写失败的情形,排他访问监控会阻止写缓冲操作排他访问地址。
cortex-m3和cortex-m4处理器中的排他访问指令包括LDREX(字)、LDREXB(字节)、LDREXH(半字)、STREX(字)、STREXB(字节)以及STREXH(半字)。简单语法实例如下所示:
LDREX <Rxf>, [Rn, #offset]
STREX <Rd>, <Rxf>, [Rn, #offset]
其中,Rd为排他写的返回状态(0为成功, 1位失败)。
当使用排他访问时,即便MPU将区域定义为了可缓冲的,也不会使用处理器总线接口上的写缓冲。这样可以确保物理存储器中的信号量信息总是最新的,并保持各总线主设备间的一致性。利用cortex-M3或cortex-M4进行多处理器SOC设计的人员应该确保在出现排他传输时,存储器系统中数据的一致性。
九、微控制器中的存储器系统
对于许多微控制器设备,设计中还集成了其他的存储器系统特性,例如:bootloader、存储器重映射、存储器别名。这些特性在处理器中不存在,不同供应商的微控制器的实现方式会有所差异,使用全部这些特性可以提高存储器映射处理的灵活性。
许多情况下,除了可以存放程序代码的程序存储器外(如FLASH),微控制器可能还会有一个单独的ROM,它可以是FLASH也可以是不能修改的掩膜ROM。这些单独的程序存储器一般会包含一个BootLoader,这也是在自己的应用程序开始前执行的程序。
芯片设计人员将BootLoader放入系统中的原因是多方面的。例如:
①提供FLASH编程功能,这样就可以利用一个简单的UART接口来编程FLASH,或者当程序运行时,在自己的应用程序中编程Flash存储器的某些部分。
②提供通信协议栈等额外的固件,可被软件开发人员通过API调用。
③提供芯片内置的自检功能(BIST)。
对于具有BootLoader ROM的芯片,当系统开始时执行BootLoader,因此当系统在上电启动时它必须要位于地址0处。不过,等系统下次启动时,可能还需要再次执行BootLoader并在Flash中直接运行应用程序,因此需要修改存储器映射。
为了达到这个目的,地址解析器需要为可编程的,可以使用硬件寄存器(如系统控制单元中的外设寄存器)。

切换存储器映射的操作被称作“存储器重映射”,该操作由BootLoader实现。不过,无法再切换存储器映射的同时跳转到BootLoader的新位置,因此,采用了一种被称作别名的方法。通过存储器地址别名,存放BootLoader的ROM可以从两个不同的存储器区域访问。一般来说,BootLoader可从地址0利用存储器地址别名进行访问,而且该别名可被关闭。可能的存储器配置有很多种,下图是其中的一种可能。对于一些微控制器,由于BootLoader位于地址0,每次系统启动时都会执行,因此无须进行存储器重映射。向量表可以利用处理器提供的向量表重定位特性进行重定位,因此在处理取向量时也无须进行重映射。
(如系统控制单元中的外设寄存器)。

备注:参考ARM Cortex-M3与Cortex-M4权威指南