组提交_并行复制
1. 组提交
1.1 两阶段提交
在MYSQL的InnoDB存储引擎中,如果开启了binlog情况下,MYSQL会同时维护binlog和InnoDB中的redo log,为了保证这两个日志的一致性问题,它使用了内部XA事务(当然也有外部XA事务)解决。内部XA事务是由binlog作为协调者,redo log 作为参与者。MySQL 内部开启一个 XA 事务,分两阶段来完成 XA 事务的提交,如下图:
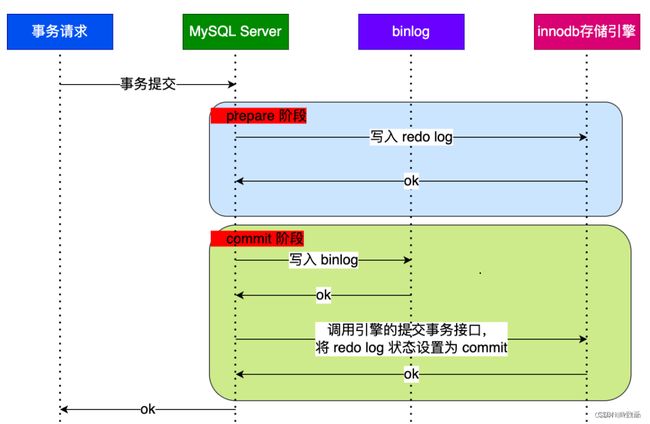
1.1 两阶段提交过程
从两个阶段提交定义和上图可以知道,我们是把redo log 拆分为两个步骤:prepare 和 commit,而在这中间加入binlog的写入,具体如下:
-
prepare 阶段:将 XID(内部 XA 事务的 ID) 写入到 redo log,同时将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘
-
commit 阶段:把 XID 写入到 binlog,然后将 binlog 刷新到磁盘,接着调用引擎的提交事务接口,将 redo log 状态设置为 commit
1.2 异常处理
如果在两个阶段出现异常怎么处理?
两个阶段出现异常情况如下图:
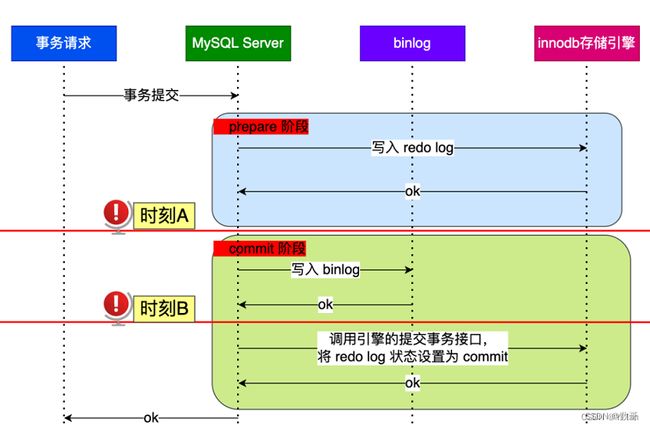
两个阶段出现异常情况
上图解释说明:
-
时刻A: redo log 写入,binlog没有写入;时刻A: redo log 和binlog都写入,但没有提交commit标识;
-
不管在时刻A,还是时刻B, redo log 都是处于 prepare 阶段
如果在MYSQL重启之后会按照顺序读取redo log 文件,当碰到处于 prepare阶段的redo log 文件,就会拿着redo log 的XID去binlog中寻找,看是否有该XID:
-
如果binlog中没有该XID,那么就说明redo log 刷盘完成,但binlog还没有,则回滚事务,即时刻A阶段异常
-
如果binlog中有该XID,那么就说明redo log 和binlog都刷盘完成,但commit标识还没有提交,则提交事务,即时刻B阶段异常
所以从上面可以看出,对于处于 prepare 阶段的 redo log,即可以提交事务,也可以回滚事务,这取决于是否能在 binlog 中查找到与 redo log 相同的 XID,如果有就提交事务,如果没有就回滚事务。这样就可以保证 redo log 和 binlog 这两份日志的一致性了。
总结:两阶段提交是以 binlog 写成功为事务提交成功的标识,因为 binlog 写成功了,就意味着能在 binlog 中查找到与 redo log 相同的 XID。
问题1:如果事务还没有提交,redo log会持久化吗?
答案:会持久化。因为事务执行过程中redo log 会直接写到 redo log buffer中,这些在 redo log buffer里的redo log 会每隔一秒就被持久化到磁盘中(根据持久化策略决定)。所以事务没有提交,redo log可能会持久化到磁盘的。
问题2: 如果在事务还没有提交,而redo log 已经被持久化磁盘了。这时MYSQL崩溃了,怎么办?
答案:在MYSQL重启时,事务会进行回滚操作。因为事务没提交的时候,binlog 是还没持久化到磁盘的。
1.3 性能影响
两阶段提交解决两个日志一致性,那它会不会带来新的问题呢?
虽然两阶段提交是解决了两个日志数据一致性问题,但是它也带来了一定性能问题:
-
磁盘 I/O 次数高:对于“双1”配置(sync_binlog 和 innodb_flush_log_at_trx_commit 都配置为 1),每个事务提交都会进行两次 fsync(刷盘),一次是 redo log 刷盘,另一次是 binlog 刷盘
-
锁竞争激烈:两阶段提交虽然能够保证「单事务」两个日志的内容一致,但在「多事务」的情况下,却不能保证两者的提交顺序一致,因此,在两阶段提交的流程基础上,还需要加一个锁来保证提交的原子性,从而保证多事务的情况下,两个日志的提交顺序一致。
磁盘 I/O 次数高
因为redo log 和binlog 都是存在对应的缓存里,即redo log缓存在redo log buffer,binlog缓存在 binlog cache中,而持久化它们是各自通过参数来控制的。一般为了数据不会丢失,都会设置这两个参数为1:
-
当 sync_binlog = 1 的时候,表示每次提交事务都会将 binlog cache 里的 binlog 直接持久到磁
-
当 innodb_flush_log_at_trx_commit = 1 时,表示每次事务提交时,都将缓存在 redo log buffer 里的 redo log 直接持久化到磁盘
-
这两个参数都设置为1,就是“双1”配置。那么当有事务提交的时候,至少就是刷两个磁盘(分别是 redo log 刷盘和binlog 刷盘),所以就导致了性能问题。
1.2 组提交
1.2.1 组提交说明
为了解决两阶段提交性能问题,MYSQL引入了binlog 组提交机制,就是当有多个事务提交时,会将多个binlog 刷盘操作合并成一个,从而减少磁盘 I/O 的次数。
其实binlog组提交机制就把之前的 commit 阶段,拆分为三个过程:
- flush 阶段:多个事务按进入的顺序将 binlog 从 cache 写入文件(不刷盘);
- sync 阶段:对 binlog 文件做 fsync 操作(多个事务的 binlog 合并一次刷盘);
- commit 阶段:各个事务按顺序做 InnoDB commit 操作;
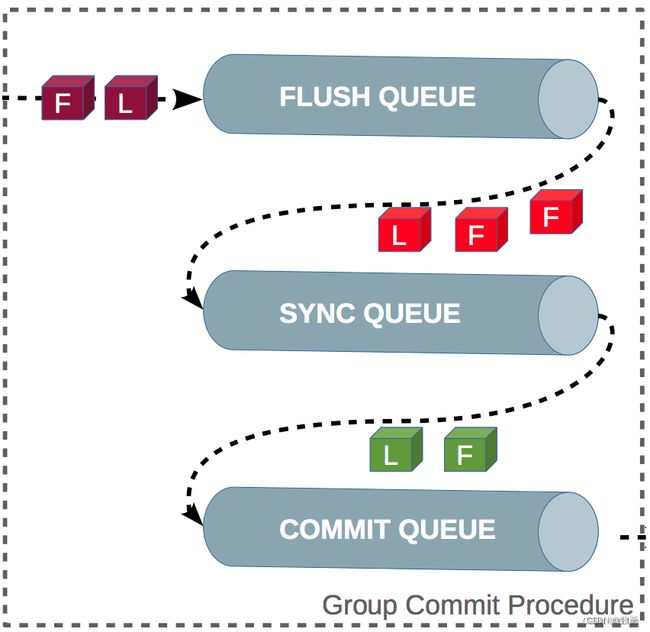
其实上面这三个阶段中每个阶段都有一个队列来完成,而每个队列有锁来保护,从而保证了事务写入的顺序,第一个进入队列的事务会成为 leader,leader领导所在队列的所有事务,全权负责整队的操作,完成后通知队内其他事务操作结束。
-
每个阶段都有一个队列
对每个阶段引入了队列后,锁就只针对每个队列进行保护,不再锁住提交事务的整个过程,可以看的出来,锁粒度减小了,这样就使得多个阶段可以并发执行,从而提升效率。 -
有 binlog 组提交,那有 redo log 组提交吗?
在MYSQL5.7版本之前是没有的,从该版本就开始有了。即在 prepare 阶段不再让事务各自执行 redo log 刷盘操作,而是推迟到组提交的 flush 阶段,也就是说 prepare 阶段融合在了flush 阶段。
这个改进是将 redo log 的刷盘延迟到了 flush 阶段之中,sync 阶段之前。通过延迟写 redo log 的方式,为 redolog 做了一次组写入,这样 binlog 和 redo log 都进行了优化。
1.2.2 组提交图解
下面,在“双 1” 配置中介绍每个阶段的过程。
flush 阶段
第一个事务会成为 flush 阶段的 Leader,此时后面到来的事务都是 Follower :
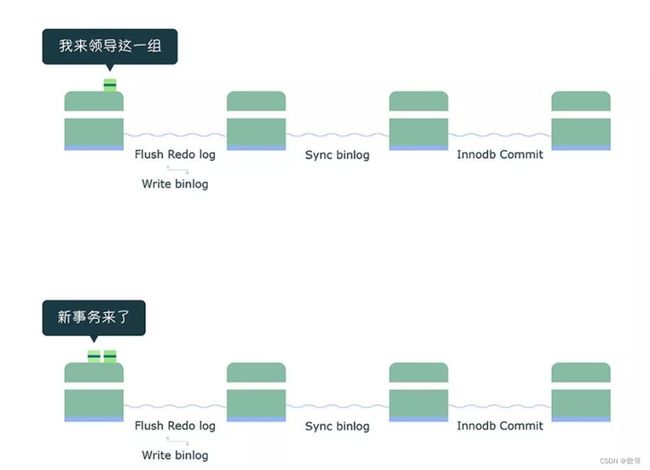
接着,获取队列中的事务组,由绿色事务组的 Leader 对 rodo log 做一次 write + fsync,即一次将同组事务的 redolog 刷盘:
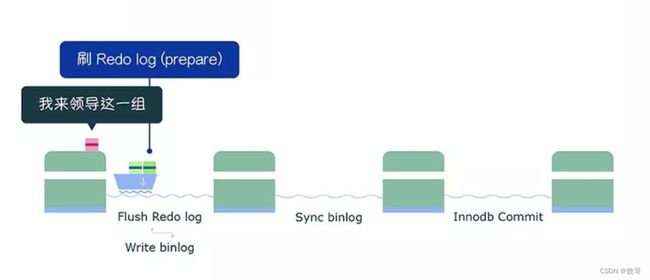
完成了 prepare 阶段后,将绿色这一组事务执行过程中产生的 binlog 写入 binlog 文件(调用 write,不会调用 fsync,所以不会刷盘,binlog 缓存在操作系统的文件系统中)。
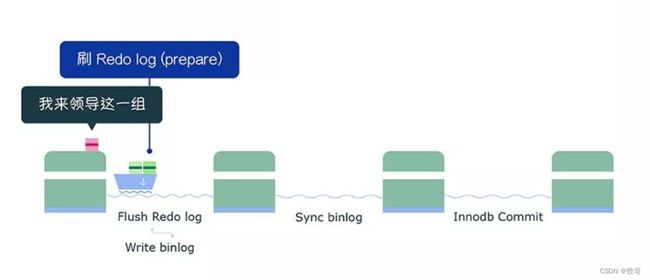
从上面这个过程,可以知道 flush 阶段队列的作用是用于支撑 redo log 的组提交。
如果在这一步完成后数据库崩溃,由于 binlog 中没有该组事务的记录,所以 MySQL 会在重启后回滚该组事务。
sync 阶段
绿色这一组事务的 binlog 写入到 binlog 文件后,并不会马上执行刷盘的操作,而是会等待一段时间,这个等待的时长由 Binlog_group_commit_sync_delay 参数控制,目的是为了组合更多事务的 binlog,然后再一起刷盘,如下过程:
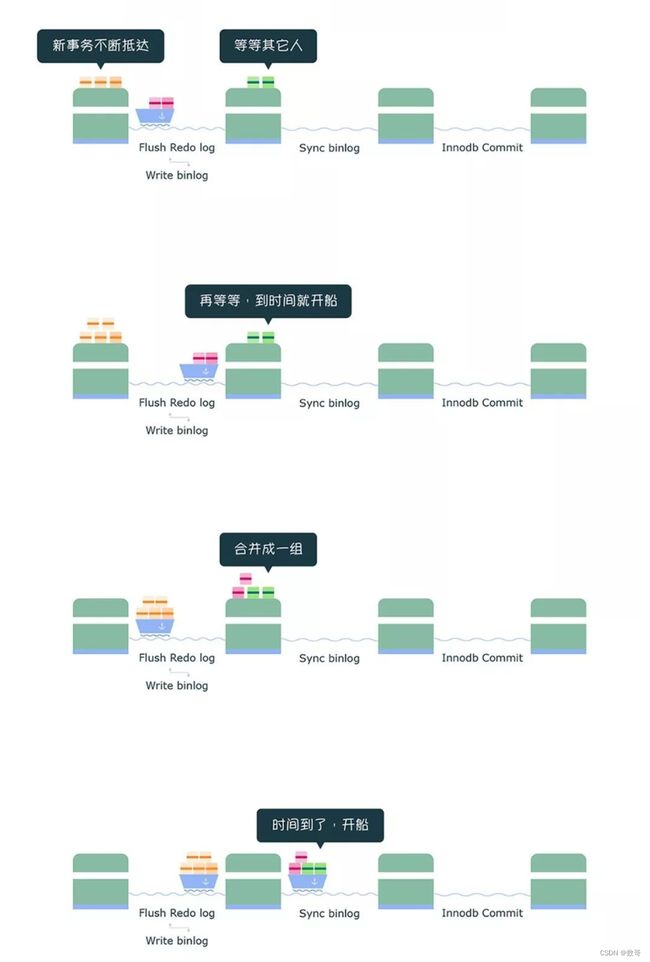
不过,在等待的过程中,如果事务的数量提前达到了 Binlog_group_commit_sync_no_delay_count 参数设置的值,就不用继续等待了,就马上将 binlog 刷盘,如下图:
从上面的过程,可以知道 sync 阶段队列的作用是用于支持 binlog 的组提交。

如果想提升 binlog 组提交的效果,可以通过设置下面这两个参数来实现:
binlog_group_commit_sync_delay= N,表示在等待 N 微妙后,直接调用 fsync,将处于文件系统中 page cache 中的 binlog 刷盘,也就是将「 binlog 文件」持久化到磁盘。
binlog_group_commit_sync_no_delay_count = N,表示如果队列中的事务数达到 N 个,就忽视binlog_group_commit_sync_delay 的设置,直接调用 fsync,将处于文件系统中 page cache 中的 binlog 刷盘。
如果在这一步完成后数据库崩溃,由于 binlog 中已经有了事务记录,MySQL会在重启后通过 redo log 刷盘的数据继续进行事务的提交。
commit 阶段
最后进入 commit 阶段,调用引擎的提交事务接口,将 redo log 状态设置为 commit。
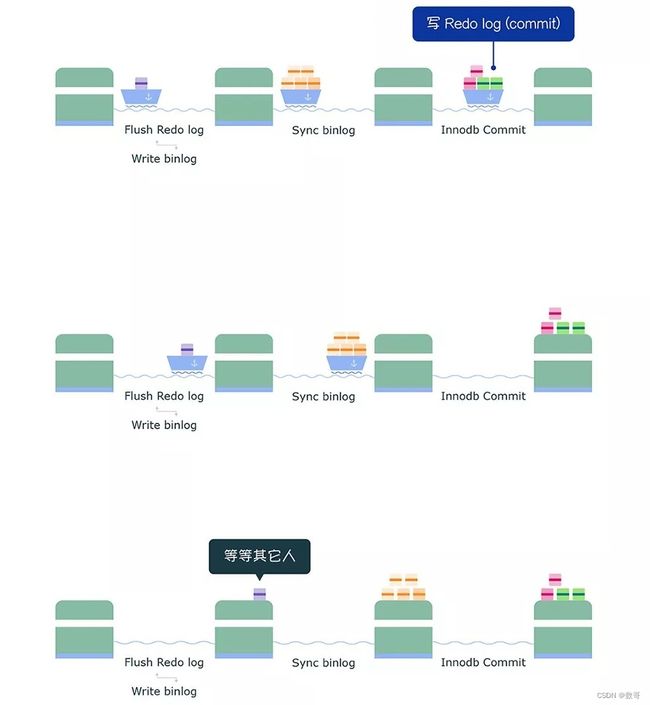
commit 阶段队列的作用是承接 sync 阶段的事务,完成最后的引擎提交,使得 sync 可以尽早的处理下一组事务,最大化组提交的效率。
1.2.3 组提交相关参数
“延迟” binlog 和 redo log 刷盘的时机,从而降低磁盘 I/O 的频率:
设置组提交的两个参数:binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 参数,延迟 binlog 刷盘的时机,从而减少 binlog 的刷盘次数。这个方法是基于“额外的故意等待”来实现的,因此可能会增加语句的响应时间。
binlog_group_commit_sync_delay表示事务延迟提交多少时间来加大整个组提交的事务数量,从而减少进行磁盘刷盘sync的次数,单位为1/1000000秒,最大值1000000也就是1秒;
binlog_group_commit_sync_no_delay_count表示组提交的事务数量凑齐多少此值时就跳出等待,然后提交事务,而无需等待binlog_group_commit_sync_delay的延迟时间;但是binlog_group_commit_sync_no_delay_count也不会超过binlog_group_commit_sync_delay设置。
将 sync_binlog 设置为大于 1 的值(比较常见是 100~1000),表示每次提交事务都 write,但累积 N 个事务后才 fsync,相当于延迟了 binlog 刷盘的时机。但是这样做的风险是,主机掉电时会丢 N 个事务的 binlog 日志。
将 innodb_flush_log_at_trx_commit 设置为 2。表示每次事务提交时,都只是缓存在 redo log buffer 里的 redo log 写到 redo log操作系统文件缓存。 1是只写同步到文件中。
1.2.4 性能影响
# MTS
binlog_group_commit_sync_delay=100000000
binlog_group_commit_sync_no_delay_count=2000
生产环境不要开启组提交,之前0.02sec,现在要1.02秒
mysql> insert into t9 values(15,'xx');
Query OK, 1 row affected (1.02 sec)
2. 并行复制
2.1 延迟的原因
MySQL复制包括两部分,IO线程 和 SQL线程,IO和SQL线程都是单线程的,然后master却是多线程的,所以难免会有延迟,为了解决这个问题,多线程应运而生了,并行复制功能,目的就是为了改善复制延迟问题,并行复制称为enhanced multi-threaded slave(简称MTS)(IO Thread多线程意义不大,主要指的是SQL Thread多线程)。
主从复制架构下主库与从库出现延迟的原因:
- 主库的master线程多个处理,而回放的时候sql_thread回放线程只有一个;
- 主从所在的主机硬件性能有差异;
- 主库有大事务;
2.2 组提交方式
-
组提交说明
简单来说就是在双1的设置下,事务提交后即刷盘的操作改为多个事务合并成一组事务再进行统一刷盘,这样处理就降低了磁盘IO的压力。
通过对事务进行分组,优化减少了生成二进制日志所需的操作数。一个组提交(group commit)的事务可以并行回放。 -
如何判断事务在一个组内呢?
一组事务同时提交也就意味着组内事务不存在冲突,故组内的事务在从节点上就可以并发执行,问题在于如何区分事务是否在同一组中的,于是在binlog中出现了两个新的参数信息last_committed 和 sequence_number,其中last_committed存在重复的情况。
sequence_number # 这个值指的是事务提交的序号,单调递增。
last_committed # 这个值有两层含义,1.相同值代表这些事务是在同一个组内,2.该值同时又是代表上一组事务的最大编号。
[root@sdns ~]# grep -i 'last_commit' x
#230330 5:36:14 server id 1116 end_log_pos 219 CRC32 0x1b2edf56 GTID last_committed=0 sequence_number=1 rbr_only=yes
#230330 5:36:18 server id 1116 end_log_pos 480 CRC32 0x64a87f22 GTID last_committed=1 sequence_number=2 rbr_only=yes
#230330 5:36:22 server id 1116 end_log_pos 741 CRC32 0x51309f0c GTID last_committed=1 sequence_number=3 rbr_only=yes
#230330 5:36:31 server id 1116 end_log_pos 1002 CRC32 0x5f72af28 GTID last_committed=1 sequence_number=4 rbr_only=yes
备库配置
slave-parallel-type=LOGICAL_CLOCK # 启用组提交复制
方案不足点
基于LOGICAL_CLOCK的同步有个不足点,就是当主节点的事务繁忙度较低的时候,导致时间段内组提交fsync刷盘的事务量较少,于是导致从库回放的并行度并不高,甚至可能一组里面只有一个事务,这样从节点的多线程就基本用不到,可以通过设置下面两个参数,让主节点延迟提交。
-
binlog_group_commit_sync_delay # 等待延迟提交的时间,binlog提交后等待一段时间再 fsync。让每个 group 的事务更多,人为提高并行度。
-
binlog_group_commit_sync_no_delay_count # 待提交的最大事务数,如果等待时间没到,而事务数达到了,就立即 fsync。达到期望的并行度后立即提交,尽量缩小等待延迟。
为了兼容MySQL 5.6基于库的并行复制,5.7引入了新的变量slave-parallel-type,其可以配置的值有:
DATABASE(默认值,基于库的并行复制方式)
LOGICAL_CLOCK(基于组提交的并行复制方式)
2.3 MySQL 5.6并行复制原理
MySQL 5.6版本也支持并行复制,但是其并行只是基于库的。如果用户的MySQL数据库中是多个库,对于从库复制的速度的确可以有帮助。
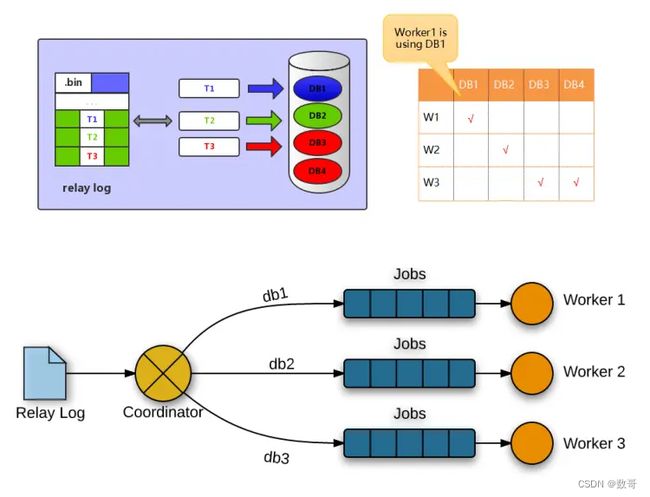
基于库的并行复制,实现相对简单,使用也相对简单些。基于库的并行复制遇到单库多表使用场景就发挥不出优势了,另外对事务并行处理的执行顺序也是个大问题。
2.4 MySQL 5.7并行复制原理
MySQL 5.7是基于组提交的并行复制,这其中最为主要的原因就是slave服务器的回放与master服务器是一致的,即master服务器上是怎么并行执行的slave上就怎样进行并行回放。不再有库的并行复制限制。
组提交的并行复制如何实现?
那么如何知道事务是否在同一组中,生成的Binlog内容如何告诉Slave哪些事务是可以并行复制的?
在MySQL 5.7版本中,其设计方式是将组提交的信息存放在GTID中。
通过mysqlbinlog工具分析binlog日志,就可以发现组提交的内部信息。
[root@sdns ~]# mysqlbinlog -vv --base64-output=decode-rows /data/mysql/my3306/logs/mysql-bin.000001 > x
[root@sdns ~]# grep -i 'last_committed' x
#230329 9:14:43 server id 1116 end_log_pos 219 CRC32 0x6b404fd0 GTID last_committed=0 sequence_number=1 rbr_only=no
#230329 9:14:58 server id 1116 end_log_pos 412 CRC32 0xa640e2ec GTID last_committed=1 sequence_number=2 rbr_only=yes
#230329 9:15:04 server id 1116 end_log_pos 673 CRC32 0x9c75ec1c GTID last_committed=1 sequence_number=3 rbr_only=yes
#230329 9:25:15 server id 1116 end_log_pos 934 CRC32 0xc8f50d71 GTID last_committed=1 sequence_number=4 rbr_only=yes
#230329 9:25:20 server id 1116 end_log_pos 1195 CRC32 0xe60d5ee3 GTID last_committed=1 sequence_number=5 rbr_only=yes
#230329 9:25:32 server id 1116 end_log_pos 1456 CRC32 0x893b6bf1 GTID last_committed=5 sequence_number=6 rbr_only=yes
#230329 9:25:34 server id 1116 end_log_pos 1711 CRC32 0x62d4efb5 GTID last_committed=6 sequence_number=7 rbr_only=yes
可以发现二进制日志当中较last_committed和sequence_number,last_committed表示事务提交的时候,上次提交的事务编号,如果事务具有相同last_committed,则表示这些事务都在一组内,可以进行并行的回放,last_committed和sequence_number生成算法比较复杂,暂时不讲。
binlog_transaction_dependency_tracking=writeset 这个参数binlog_transaction_dependency_tracking于降低order_commit生成的last commit,以提高从库的并行。 简而言之就是让一个组可以有更多的事务。它是基于行级的并行复制。
3.2 并行复制设置
- 主库:
需要开启组提交
group commit:
binlog_group_commit_sync_delay=100 //等待多长时间再一起提交
binlog_group_commit_sync_no_delay_count=20 //等待多少个条目再一起提交
transaction_write_set_extraction=1
binlog_transaction_dependency_tracking=writeset # 当主库的binlog_transaction_dependency_tracking参数设置为writeset或者writeset_session的时候,用于降低order_commit生成的last commit,以提高从库的并发。
// 满足任一条件
- 从库:
# MTS
slave_parallel_type=logical_clock #启用组提交的并行复制
slave_parallel_workers=4 #开启并发的线程数
transaction_write_set_extraction=1 # transaction_write_set_extraction
该模式支持三种算法,默认采用XXHASH64,当从节点配置writeset复制的时候,该配置不能配置为OFF。writeset 是一个HASH类型的数组,里面记录着事务的更新信息,通过transaction_write_set_extraction判断当前事务更新的记录与历史事务更新的记录是否存在冲突,判断过后再采取对应处理方法
binlog_transaction_dependency_tracking=writeset # 行级并行复制
slave_preserve_commit_order=1 # 开启并行复制
log_bin=/data/mysql/my3306/logs/mysql-bin # 需要开启binlog
log_slave_updates=1 # 主库的事务记录到备库的binlog
mysql> start slave; # 需要启动binlog 和 log_slave_updates 否则并行复制无法开启
ERROR 3031 (HY000): slave_preserve_commit_order is not supported unless both log_bin and log_slave_updates are enabled.
3.3 查看并行复制
mysql> select * from performance_schema.replication_applier_status_by_worker \G;
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 1
THREAD_ID: 28
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 2. row ***************************
CHANNEL_NAME:
WORKER_ID: 2
THREAD_ID: 30
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 3. row ***************************
CHANNEL_NAME:
WORKER_ID: 3
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
*************************** 4. row ***************************
CHANNEL_NAME:
WORKER_ID: 4
THREAD_ID: 32
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION:
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
4 rows in set (0.00 sec)
ERROR:
No query specified