Python爬虫基础:scrapy 框架结构及scrapy.Spider
scrapy 框架结构
思考
- scrapy 为什么是框架而不是库?
- scrapy是如何工作的?
项目结构
在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:
注意:创建项目时,会在当前目录下新建爬虫项目的目录。
这些文件分别是:
- scrapy.cfg:项目的配置文件
- quotes/:该项目的python模块。之后您将在此加入代码
- quotes/items.py:项目中的item文件
- quotes/middlewares.py:爬虫中间件、下载中间件(处理请求体与响应体)
- quotes/pipelines.py:项目中的pipelines文件
- quotes/settings.py:项目的设置文件
- quotes/spiders/:放置spider代码的目录
Scrapy原理图
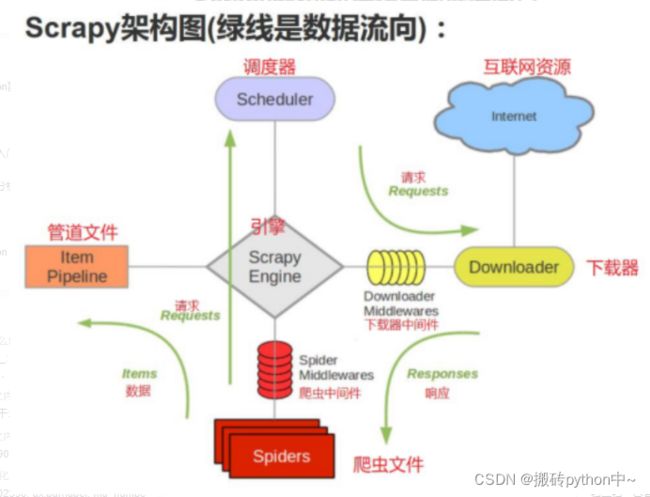
各个组件的介绍
Engine。引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
ltem。项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该ltem对象。
Scheduler。调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求的时候将请求提供给引擎。
Downloader。下载器,下载网页内容,并将网页内容返回给蜘蛛。
Spiders。蜘蛛,其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成提结果和新的请求。
Item Pipeline。项目管道,负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
Downloader Middlewares。下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求及响应。
Spider Middlewares。蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求。

数据的流动
Scrapy Engine(引擎):负责Spider、ltemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫)︰负责处理所有Responses,从中分析提取数据,获取ltem字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
ltem Pipeline(管道):负责处理Spider中获取到的ltem,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
scrapy.Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
对spider来说,爬取的循环类似下文:
- 以初始的URL初始化Request,并设置回调函数。当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。
spider中初始的request是通过调用start_requests()来获取的。start_requests()读取start_urls中的URL,并以parse为回调函数生成Request。 - 在回调函数内分析返回的(网页)内容,返回ltem对象或者Request或者一个包括二者的可迭代容器。返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。
- 在回调函数内,您可以使用选择器(Selectors)(您也可以使用BeautifulSoup,
Ixml或者您想用的任何解析器)来分析网页内容,并根据分析的数据生成item。 - 最后,由spider返回的item将被存到数据库(由某些ltem Pipeline处理)或使用Feed exports存入到文件中。
虽然该循环对任何类型的spider都(多少)适用,但Scrapy仍然为了不同的需求提供了多种默认spider。之后将讨论这些spider。
Spider
scrapy.spider.Spider是最简单的spider。每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及您自己编写的spider)。其仅仅请求给定的start_urls / start_requests,并根据返回的结果(resulting responses)调用spider的 parse方法。
name
定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化) spider,所以其必须是唯一的。不过您可以生成多个相同的spider实例(instance),这没有任何限制。name是spider最重要的属性,而且是必须的。
如果该spider爬取单个网站(single domain),一个常见的做法是以该网站(domain)(加或不加后缀)来命名spider。例如,如果spider爬取 mywebsite.com,该spider通常会被命名为mywebsite。
allowed_domains
可选。包含了spider允许爬取的域名(domain)列表(list)。当OffsiteMiddleware启用时,域名不在列表中的URL不会被跟进。
start_urls
URL列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。因此,第一个被获取到的页面的URL将是该列表之一。后续的URL将会从获取到的数据中提取。
start_requests()
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个Request。
当spider启动爬取并且未制定URL时,该方法被调用。当指定了URL时,make_requests_from_url()将被调用来创建Request对象。该方法仅仅会被Scrapy调用一次,因此您可以将其实现为生成器。
该方法的默认实现是使用start_urls的url生成Request。
如果您想要修改最初爬取某个网站的Request对象,您可以重写(override)该方法。例如,如果您需要在启动时以POST登录某个网站,你可以这么写:
def start_requests(self) :
return [scrapy.FormRequest("http : / /ww. example.com/login",
formdata={ 'user' : 'john', ' pass ' : 'secret'},
ca77back=se1f.1ogged_in)]
def logged_in(self,response) :
## here you would extract links to follow and return Requests for
## each of them,with another ca77back
pass
parse
当response没有指定回调函数时,该方法是Scrapy处理下载的response的默认方法。
parse负责处理response并返回处理的数据以及(/或)跟进的URL。Spider对其他的Request的回调函数也有相同的要求。
该方法及其他的Request回调函数必须返回一个包含Request 及(或) ltem的可迭代的对象。
参数: response-用于分析的response
学习更多知识或解答疑问、源码、教程请点击
启动方式
start_urls
start_urls是一个列表
start_requests
使用start_requests()重写start_ur1s,要使用Request()方法自己发送请求:
def start_requests(se7f):
"""重写start_urls 规则"""
yield scrapy.Request(ur1='http://quotes.toscrape.com/page/1/'cal1back=self.parse)
scrapy.Request
scrapy.Request是一个请求对象,创建时必须制定回调函数。
数据保存
可以使用-o将数据保存为常见的格式(根据后缀名保存)
支持的格式有下面几种:
- json
- jsonlines
- jl
- csv
- xml
- marshal
- pickle
使用方式:
scrapy crawl quotes2 -o a.json
案例: Spider样例
##一*- coding: utf-8 -*-
import scrapy
clTass Quotes2spider(scrapy.spider):
name = 'quotes2'
a7lowed_domains = [ 'toscrape.com ' ]
start_urls = [ ' http: //quotes.toscrape.com/ page/2/ ']
def parse(self,response):
quotes = response.css('.quote ' )
for quote in quotes:
text = quote.css( '.text: : text ' ).extract_first()
auth = quote.css( '.author : :text ').extract_first()
tages = quote.css('.tags a: :text' ).extract()
yield dict(text=text , auth=auth, tages=tages)