详解应对平台高并发的分布式调度框架TBSchedule
声明:本文为CSDN原创投稿文章,未经许可,禁止任何形式的转载。
作者:周立伟(ITeye博客:mycolababy.iteye.com),京东商城高级工程师,关注分布式、高并发和Java中间件的研究。
责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件[email protected],另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008申请入群,备注姓名+公司+职位。
【编者按】 TBSchedule是一款非常优秀的高性能分布式调度框架,本文是作者结合多年使用TBSchedule的经验,在研读三遍源码的基础上完成。期间作者也与阿里空玄有过不少技术交流,并非常感谢空玄给予的大力支持。另外,作者写这篇文章的目的一是出于对TBSchedule的一种热爱,二是现在是一个资源共享、技术共享的时代,希望把它展现给大家(送人玫瑰,手留余香),能给大家的工作带来帮助。
以下为文章正文:
一、TBSchedule初识
时下互联网和电商领域,各个平台都存在大数据、高并发的特点,对数据处理的要求越来越高,既要保证高效性,又要保证安全性、准确性。TBSchedule的使命就是将调度作业从业务系统中分离出来,降低或者是消除和业务系统的耦合度,进行高效异步任务处理。其实在互联网和电商领域TBSchedule的使用非常广泛,目前被应用于阿里巴巴、淘宝、支付宝、京东、聚美、汽车之家、国美等很多互联网企业的流程调度系统。
在深入了解TBSchedule之前我们先从内部和外部形态对它有个初步认识,如图1.1、图1.2。

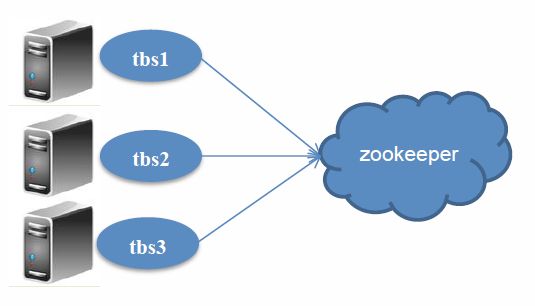
从TBSchedule的内部形态来说,与他有关的关键词包括批量任务、动态扩展、多主机、多线程、并发、分片……,这些词看起来非常的高大上,都是时下互联网技术比较流行的词汇。从TBSchedule的外部架构来看,一目了然,宿主在调度应用中与ZooKeeper进行通信。一个框架结构是否是优秀的,从美感的角度就可以看出来,一个好的架构一定是隐藏了内部复杂的原理,外部视觉上美好的,让用户使用起来简单易懂。
二、TBSchedule原理
为什么TBSchedule值得推广呢?
- 传统的调度框架spring task、quartz也是可以进行集群调度作业的,一个节点挂了可以将任务漂移给其他节点执行从而避免单点故障,但是不支持分布式作业,一旦达到单机处理极限也会存在问题。
- elastic-job支持分布式,是一个很好的调度框架,但是开源时间较短,还没有经历大范围市场考验。
- Beanstalkd基于C语言开发,使用范围较小,无法引入到php、java系统平台。
TBSchedule到底有多强大呢?我对TBSchedule的优势特点进行了如下总结:
- 支持集群、分布式
- 灵活的任务分片
- 动态的服务扩容和资源回收
- 任务监控支持
- 经历了多年市场考验,阿里强大技术团队支持
TBSchedule支持Cluster,可以宿主在多台服务器多个线程组并行进行任务调度,或者说可以将一个大的任务拆成多个小任务分配到不同的服务器。
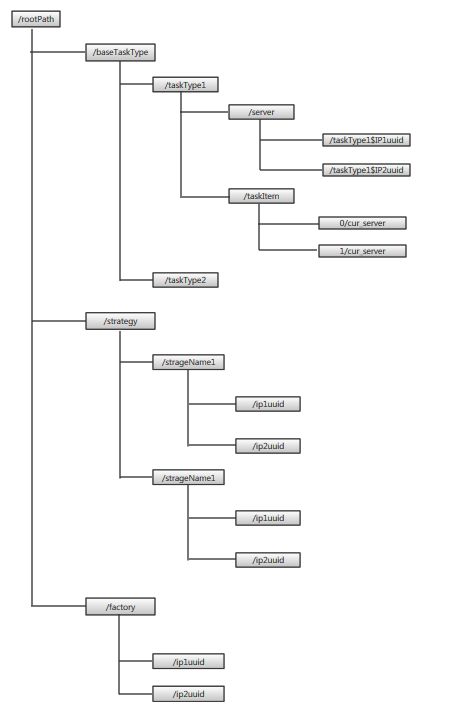
TBSchedule的分布式机制是通过灵活的Sharding方式实现的,比如可以按所有数据的ID按10取模分片(分片规则如图2.1)、按月份分片等等,根据不同的需求,不同的场景由客户端配置分片规则。然后就是TBSchedule的宿主服务器可以进行动态扩容和资源回收,这个特点主要是因为它后端依赖的ZooKeeper,这里的ZooKeeper对于TBSchedule来说是一个NoSQL,用于存储策略、任务、心跳信息数据,它的数据结构类似文件系统的目录结构,它的节点有临时节点、持久节点之分。调度引擎上线后,随着业务量数据量的增多,当前Cluster可能不能满足目前的处理需求,那么就需要增加服务器数量,一个新的服务器上线后会在ZooKeeper中创建一个代表当前服务器的一个唯一性路径(临时节点),并且新上线的服务器会和ZooKeeper保持长连接,当通信断开后,节点会自动摘除。
TBSchedule会定时扫描当前服务器的数量,重新进行任务分配。TBSchedule不仅提供了服务端的高性能调度服务,还提供了一个scheduleConsole war随着宿主应用的部署直接部署到服务器,可以通过web的方式对调度的任务、策略进行监控管理,以及实时更新调整。
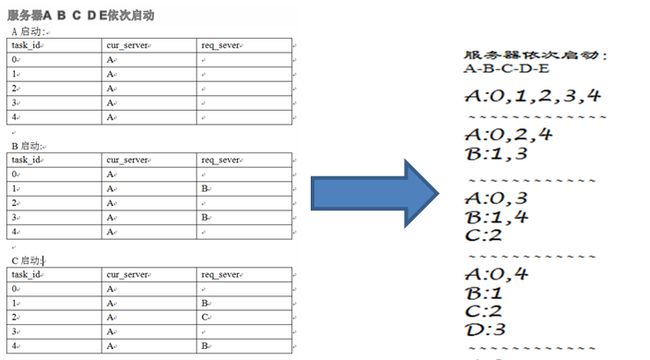
是不是已经对TBSchedule稍微了有些好感呢?我们接着往下看。
TBSchedule提供了两个核心组件ScheduleServer、TBScheduleManagerFactory和两类核心接口IScheduleTaskDeal、IScheduleTaskDealSingle、IScheduleTaskDealMuti,这两部分是客户端研发的关键部分,是使用TBSchedule必须要了解的。
ScheduleServer即任务处理器,的主要作用是任务和策略的管理、任务采集和执行,由一组工作线程组成,这组工作线程是基于队列实现的,进行任务抓取和任务处理(有两种处理模式,下面会讲)。每个任务处理器和ZooKeeper有一个心跳通信连接,用于检测Server的状态和进行任务动态分配。举个例子,比如3台服务器的worker集群执行出票消息生成任务,对于这个任务类型每台服务器可以配置一个ScheduleSever(即一个线程组),也可以配置两个线程组,那么就相当于6台服务器在并行执行此任务类型。当某台服务器宕机或者其他原因与ZooKeeper通信断开时,它的任务将被其他服务器接管。ScheduleServer参数定义如图2.2
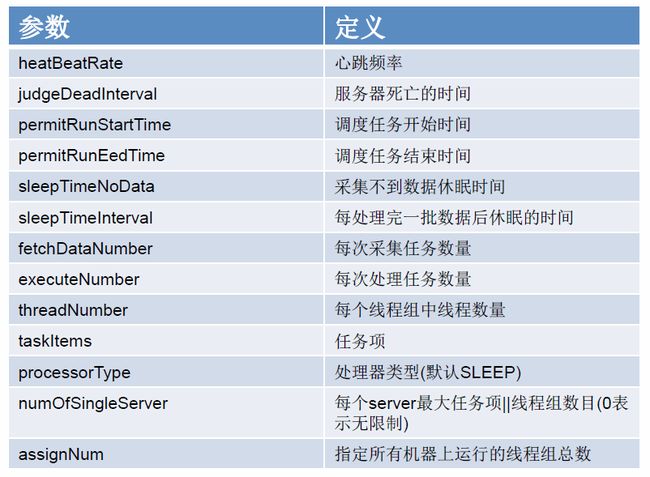
在这些参数中taskItems是一个非常重要的属性,是客户单可以自由发挥的地方,是任务分片的基础,比如我们处理一个任务可以根据ID按10取模,那么任务项就是0-9,3台服务器分别拿到4、 3、 3个任务项,服务器的上下线都会对任务项进行重新分配。任务项是进行任务分配的最小单位。一个任务项只能由一个ScheduleServer来进行处理,但一个Server可以处理任意数量的任务项。这就是刚才我们说的分片特性。
调度服务器TBScheduleManagerFactory的主要工作ZooKeeper连接参数配置和ZooKeeper的初始化、调度管理。
两类核心接口是需要被我们定义的目标任务实现的,根据自己的需要进行任务采集(重写selectTasks方法)和任务执行(重写execute方法),这两类接口也是客户端研发根据需求自由发挥的地方。
接下来我们深入了解下TBSchedule,看看它的内部是如何实现的。图2.3流程图是我花了很多心血通过一周时间画出来的,基本是清晰的展现了TBSchedule内部的执行流程以及每个步骤ZooKeeper节点路径和数据的变化。因为图中的注释已经描述的很详细了,每个节点右侧是ZooKeeper的信息(数据结构见图2.4),这里就不再做过多的文字描述了,有任何建议或者不明白的地方可以找我交流。
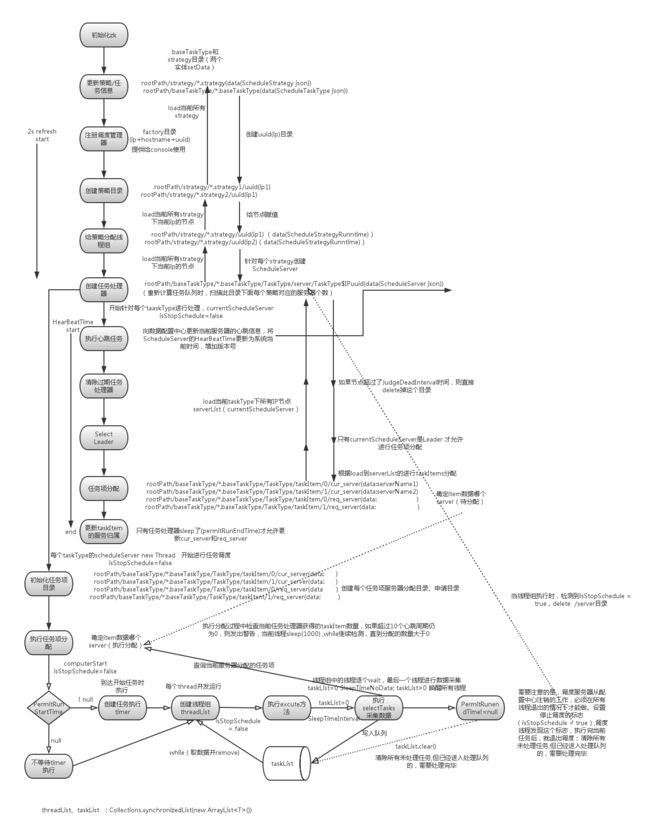
TBSchedule还有个强大之处是它提供了两种处理器模式模式:
1. SLEEP模式
当某一个线程任务处理完毕,从任务池中取不到任务的时候,检查其它线程是否处于活动状态。如果是,则自己休眠;如果其它线程都已经因为没有任务进入休眠,当前线程是最后一个活动线程的时候,就调用业务接口,获取需要处理的任务,放入任务池中,同时唤醒其它休眠线程开始工作。
2. NOTSLEEP模式
当一个线程任务处理完毕,从任务池中取不到任务的时候,立即调用业务接口获取需要处理的任务,放入任务池中。
SLEEP模式内部逻辑相对较简单,如果遇到大任务需要处理较长时间,可能会造成其他线程被动阻塞的情况。但其实生产环境一般都是小而快的任务,即使出现阻塞的情况ScheduleConsole也会及时的监控到。NOTSLEEP模式减少了线程休眠的时间,避免了因大任务造成阻塞的情况,但为了避免数据被重复处理,增加了CPU在数据比较上的开销。TBSchedule默认是SLEEP模式。
到目前为止我相信大家对TBSchedule有了一个深刻的了解,心中的疑雾逐渐散开了。理论是实践的基础,实践才是最终的目的,下一节我们将结合理论知识进行TBSchedule实战。
三、TBSchedule实战
在项目中使用TBSchedule需要依赖ZooKeeper、TBSchedule。
ZooKeeper依赖:
<dependency>
<groupId>org.apache.ZooKeepergroupId>
<artifactId>ZooKeeperartifactId>
<version>3.4.6version>
dependency>TBSchedule依赖:
<dependency>
<groupId>com.taobao.pamirs.schedulegroupId>
<artifactId>TBScheduleartifactId>
<version>3.3.3.2version>
dependency>TBSchedule有三种引入方式:
- 通过ScheduleConsole引入
TBSchedule随着宿主调度应用部署到服务器后,可以通过Web浏览器的方式访问其提供监控平台。
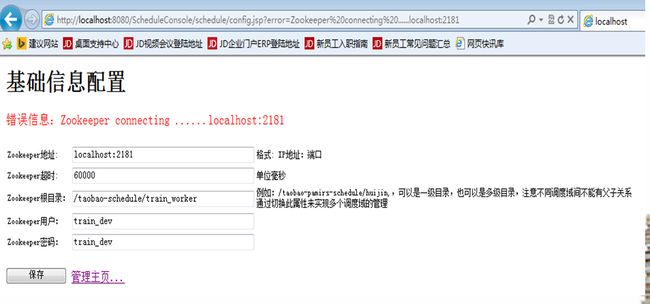
第一步,初始化ZooKeeper
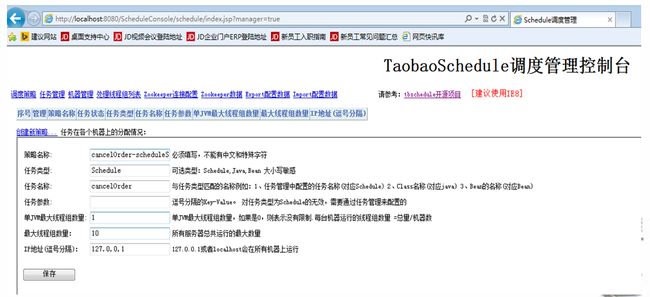
第二步,创建调度策略
第三步,创建调度任务

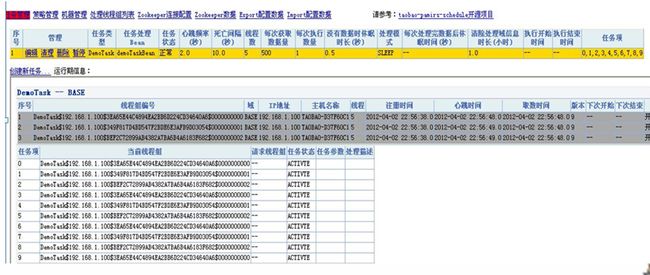
第四步,监控调度任务
2、通过原生Java引入
// 初始化Spring
ApplicationContext ctx = new FileSystemXmlApplicationContext(
"spring-config.xml");
// 初始化调度工厂
TBScheduleManagerFactory scheduleManagerFactory = new TBScheduleManagerFactory();
Properties p = new Properties();
p.put("zkConnectString", "127.0.0.1:2181");
p.put("rootPath", "/taobao-schedule/train_worker");
p.put("zkSessionTimeout", "60000");
p.put("userName", "train_dev");
p.put("password", " train_dev ");
p.put("isCheckParentPath", "true");
scheduleManagerFactory.setApplicationContext(ctx);
scheduleManagerFactory.init(p);
// 创建任务调度任务的基本信息
String baseTaskTypeName = "DemoTask";
ScheduleTaskType baseTaskType = new ScheduleTaskType();
baseTaskType.setBaseTaskType(baseTaskTypeName);
baseTaskType.setDealBeanName("demoTaskBean");
baseTaskType.setHeartBeatRate(10000);
baseTaskType.setJudgeDeadInterval(100000);
baseTaskType.setTaskParameter("AREA=BJ,YEAR>30");
baseTaskType.setTaskItems(ScheduleTaskType.splitTaskItem(
"0:{TYPE=A,KIND=1},1:{TYPE=A,KIND=2},2:{TYPE=A,KIND=3},3:{TYPE=A,KIND=4}," +
"4:{TYPE=A,KIND=5},5:{TYPE=A,KIND=6},6:{TYPE=A,KIND=7},7:{TYPE=A,KIND=8}," +
"8:{TYPE=A,KIND=9},9:{TYPE=A,KIND=10}"));
baseTaskType.setFetchDataNumber(500);
baseTaskType.setThreadNumber(5);
this.scheduleManagerFactory.getScheduleDataManager()
.createBaseTaskType(baseTaskType);
log.info("创建调度任务成功:" + baseTaskType.toString());
// 创建任务的调度策略
String taskName = baseTaskTypeName;
String strategyName =taskName +"-Strategy";
try {
this.scheduleManagerFactory.getScheduleStrategyManager()
.deleteMachineStrategy(strategyName,true);
} catch (Exception e) {
e.printStackTrace();
}
ScheduleStrategy strategy = new ScheduleStrategy();
strategy.setStrategyName(strategyName);
strategy.setKind(ScheduleStrategy.Kind.Schedule);
strategy.setTaskName(taskName);
strategy.setTaskParameter("china");
strategy.setNumOfSingleServer(1);
strategy.setAssignNum(10);
strategy.setIPList("127.0.0.1".split(","));
this.scheduleManagerFactory.getScheduleStrategyManager()
.createScheduleStrategy(strategy);
log.info("创建调度策略成功:" + strategy.toString());3、通过Spring容器引入
<bean id="scheduleManagerFactory"
class="xx.xx.TBScheduleManagerFactory">
<property name="zkConfig">
<map>
<entry key="zkConnectString" value="127.0.0.1:2181" />
<entry key="rootPath" value="/taobao-schedule/train_worker" />
<entry key="zkSessionTimeout" value="60000" />
<entry key="userName" value="train_dev" />
<entry key="password" value="train_dev" />
<entry key="isCheckParentPath" value="true" />
map>
property>
bean>
<bean id="abstractDemoScheduleTask" class="com.xx.core.TBSchedule.InitScheduleTask" abstract="true">
<property name="scheduleTaskType.heartBeatRate" value="10000" />
<property name="scheduleTaskType.judgeDeadInterval" value="100000" />
<property name="scheduleTaskType.permitRunStartTime" value="0 0 1 * * ?"/>
<property name="scheduleTaskType.permitRunEndTime" value="0 0 3 * * ?"/>
<property name="scheduleTaskType.taskParameter" value="AREA=BJ,YEAR>30" />
<property name="scheduleTaskType.sleepTimeNoData" value="60000"/>
<property name="scheduleTaskType.sleepTimeInterval" value="60000"/>
<property name="scheduleTaskType.fetchDataNumber" value="500" />
<property name="scheduleTaskType.executeNumber" value="1" />
<property name="scheduleTaskType.threadNumber" value="5" />
<property name="scheduleTaskType.taskItems">
<list>
<value>0:{TYPE=A,KIND=1}value>
<value>1:{TYPE=A,KIND=2}value>
<value>2:{TYPE=A,KIND=3}value>
<value>3:{TYPE=A,KIND=4}value>
<value>4:{TYPE=A,KIND=5}value>
<value>5:{TYPE=A,KIND=6}value>
<value>6:{TYPE=A,KIND=7}value>
<value>7:{TYPE=A,KIND=8}value>
<value>8:{TYPE=A,KIND=9}value>
<value>9:{TYPE=A,KIND=10}value>
list>
property>
<property name="scheduleStrategy.kind" value="Schedule" />
<property name="scheduleStrategy.numOfSingleServer" value="1" />
<property name="scheduleStrategy.assignNum" value="10" />
<property name="scheduleStrategy.iPList">
<list>
<value>127.0.0.1value>
list>
property>
bean>
<bean id="demoTask" class="com.xx.worker.task.DemoTask" parent="abstractDemoScheduleTask">
<property name="scheduleTaskType.baseTaskType" value="demoTask" />
<property name="scheduleTaskType.dealBeanName" value="demoTaskBean" />
<property name="scheduleStrategy.strategyName" value="demoTaskBean-Strategy" />
<property name="scheduleStrategy.taskName" value="demoTaskBean" />
bean>
调度任务具体实现 DemoTask.java
/**
* DemoTask任务类
*/
public class DemoTask mplements
IScheduleTaskDealSingle,TScheduleTaskDeal {
/**
* 数据采集
* @param taskItemNum--分配的任务项 taskItemList--总任务项
* eachFetchDataNum--采集任务数量
*/
@Override
public List<DemoTask> selectTasks(String taskParameter,
String ownSign, int taskItemNum, List<TaskItemDefine> taskItemList,
int eachFetchDataNum) throws Exception {
List<DemoTask> taskList = new LinkedList<DemoTask>();
//客户端根据条件进行数据采集start
//客户端根据条件进行数据采集end
return rt;
}
/**
* 数据处理
*/
@Override
public boolean execute(DemoTask task, String ownSign)
throws Exception {
//客户端pop任务进行处理start
//客户端pop任务进行处理end
return true;
}
}其实我们看对于TBSchedule客户端的使用非常简单,初始化ZooKeeper、配置调度策略、配置调度任务,对调度任务进行具体实现,就这几个步骤。现在可以庆祝下了,你又掌握了一个优秀开源框架的设计思想和使用方式。
四、TBSchedule挑战
任何事物都是没有最好只有更好,TBSchedule也一样,虽然它现在已经很完美了,我们不能放弃对更完美的追求。阿里团队可以在下面几个方面进行优化。
- 目前ScheduleConsole监控页面过于简单,需完善UI设计,提高用户体验。
- 支持Zookeeper集群自动切换,避免ZooKeeper服务的集群单点故障。
- 原生ZooKeeper操作替换为Curator,Curator对ZooKeeper进行了一次包装,对原生ZooKeeper的操作做了大量优化,Client和Server之间的连接可能出现的问题处理等等,可以进一步提高TBSchedule的高可用。
- TBSchedule的帮助文档较少,网上的资料基本是千篇一律,希望有更多的爱好者加入进来。
至此,我们已经完成了对TBSchedule的全部介绍,尽快使用起来吧!
TBSchedule技术交流QQ群:89558542。