Kafka安装与基本的使用
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副 本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以 实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟 的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务 等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶 级开源 项目。
- 介绍
2-1 Kafka的特性:
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几 毫秒,每个topic可以分多个partition, consumer group 对partition进行 consume操作。
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
2-2 Kafka的使用场景:
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统 一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动, 如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka 的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载 到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的 数据,生产各种操作的集中反馈,比如报警和报告。
流式处理:比如spark streaming和storm
事件源
- 基本工作原理图

- 名词解释
Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker 可以组成一个Kafka集群。
- Topic:一类消息,消息存放的目录即主题,例如page view日志、click 日志等都可以以topic的形式存在,Kafka集群能够同时负责多 个topic的分发。
- Partition:topic物理上的分组,一个topic可以分为多个partition, 每个partition是一个有序的队列
- Segment:partition物理上由多个segment组成,每个Segment存 着message信息
- Producer : 生产message发送到topic
- Consumer : 订阅topic消费message, consumer作为一个线程来消费
- Consumer Group:一个Consumer Group包含多个consumer, 这个是预先在配置文件中配置好的。各个consumer(consumer 线程)可以组成一个组(Consumer group ),partition中的每个message只能被组(Consumer group ) 中的一个consumer(consumer 线程 )消费,如果一个message可以被多个consumer(consumer 线程 ) 消费的话,那么这些consumer必须在不同的组。Kafka不支持一个partition中的message由两个或两个以上的consumer thread来处理,即便是来自不同的consumer group的也不行。它不能像AMQ那样可以多个BET作为consumer去处理message,这是因为多个BET去消费一个Queue中的数据的时候,由于要保证不能多个线程拿同一条message,所以就需要行级别悲观所(for update),这就导致了consume的性能下降,吞吐量不够。而kafka为了保证吞吐量,只允许一个consumer线程去访问一个partition。如果觉得效率不高的时候,可以加partition的数量来横向扩展,那么再加新的consumer thread去消费。这样没有锁竞争,充分发挥了横向的扩展性,吞吐量极高。这也就形成了分布式消费的概念。
安装
1,将安装包上传到Linux上(安装Kafka前置条件需已安装zookeeper)
2,解压安装包
tar -zxf kafka_2.11-2.0.0.tgz3,移到指定目录下,并重命名
mv kafka_2.11-2.0.0 soft/kafka211
4,进入config文件夹 ,并修改server.properties文件
cd soft/kafka211/config/
vim server.properties
#更改以下内容
#,当前所在集群编号,如果是多台,每个千万不要设置为一样
broker.id=0
#取消注释,改为自己IP
listeners=PLAINTEXT://192.168.88.180:9092
zookeeper.connect=192.168.88.180:21815,配置环境变量
vim /etc/profile
添加如下内容
export KAFKA_HOME=/opt/soft/kafka211
export PATH=$PATH:$KAFKA_HOME/bin6,激活环境变量
source /etc/profile7,启动Kafka
kafka-server-start.sh /opt/soft/kafka211/config/server.properties 启动成功后,jps查看进程,会有一个Kafka进程
8,查看里面有那些消息,第一次刚建好,不会返回内容
kafka-topics.sh --list --zookeeper 192.168.88.180:2181使用
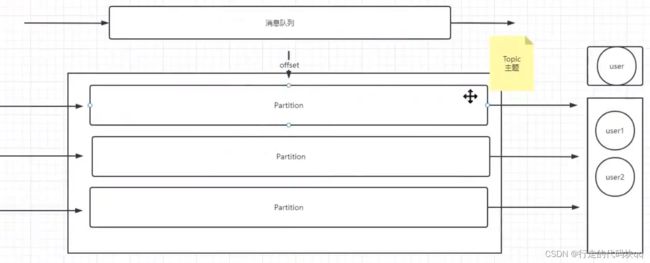
关于分组分区,user1,user2代表这个topic上一个组的两个消费者,user1未读取完时,user2会接着user1读取到的offset(游标)继续读,当一个组读完时,这个组就不能再次读取里面的数据了。如果此时换一个组读取分区里的数据,则它会有一个产生新的游标,从头开始读取,也就是说两个组的用户不会对消息产生任何冲突。
9,单分区操作 进入config文件夹,创建一个消息队列(一个主题可以有多个分区,默认按key hash进行分区)
#replication-factor 1表示副本数为1个 主题副本数量不大于brokers个数, partitions 1表示分区数为1个,topic mydemo表是消息队列名为mydemo
kafka-topics.sh --create --zookeeper 192.168.88.180:2181 --replication-factor 1 --partitions 1 --topic mydemo10,检查队列是否创建成功
kafka-topics.sh --list --zookeeper 192.168.88.180:218111,向你的消息队列中生产消息(回车停止在输入区)
kafka-console-producer.sh --topic mydemo --broker-list 192.168.88.180:909212,为了能看到消费端消息,新开xshell界面,写一个消费端
kafka-console-consumer.sh --topic mydemo --bootstrap-server 192.168.88.180:9092

此时生产端输入东西,消费端就可以看到你输入的消息
13,查看分区上的数据(分区上的数据默认保留7天,所以刚开始即使数据都读完,但是也不会在内存上消失)
kafka-run-class.sh kafka.tools.GetOffsetShell --topic mydemo --time -1 --broker-list 192.168.88.180:9092
#也可以查看某一个分区
kafka-run-class.sh kafka.tools.GetOffsetShell --topic mydemo --time -1 --broker-list 192.168.88.180:9092 --partitions 0前面0代表是哪一个分区,2是表示这个分区有两个数据

14,多分区操作(这里建了3个分区)
kafka-topics.sh --create --zookeeper 192.168.88.180:2181 --topic mydemo01 --replication-factor 1 --partitions 3如果需要删除消息队列,则需要先把kafka先关闭运行,然后在conf/server.propertities 配置文件中添加此句,然后重新启动kafka
delete.topic.enable=true然后用此命令删除
kafka-topics.sh --delete --zookeeper 192.168.88.180:2181 --topic mydemo0115,查看
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.88.180:9092 --time -1 --topic mydemo01
16,Java操作kafka
1,导入依赖
org.springframework.kafka
spring-kafka
2,yml配置
spring:
application:
name: mykafka
kafka:
bootstrap-servers: 192.168.88.180:9092
# producer 生产者
producer:
retries: 1 # 重试次数
acks: 1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # consumer消费者
group-id: qjc01 消费组ID
enable-auto-commit: false # 无论是否自动提交offset,这里都写为false
auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset)
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
consumer-thred-num: 3
server:
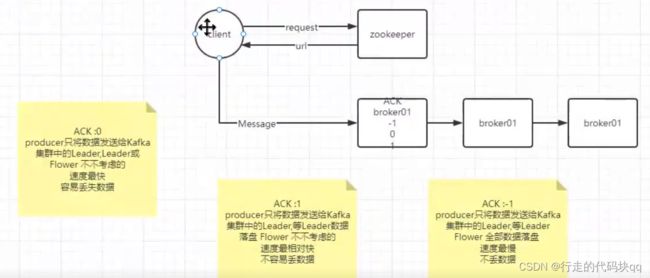
port: 9090kafka中的应答机制:
ack作用是确认收到消息,一条是producer发送消息到leader收到消息之后发送ack
另一条是leader和follower之间同步完成数据会发送ack
对于一些不太重要的数据,对数据的可靠性要求不是特别高的情况下,能够容忍少量的数据丢失,因此没有必要等待ISR中所有follower全部要接收成功
所以Kafka为用户提供了三种可靠级别设置,可以根据不同需求来修改选择:
ack有三个参数配置:参数是0,1和-1
参数为0意思是:
producer不等待broker的ack,这一种操作提供了最低的延迟,broker一接受到还没有写入到磁盘就已经返回了,当broker故障的时候 丢失数据(相当于异步发送)
参数为1时:
producer等待broker的ack,partition的leader落盘成功后返回ack,如果follower同步数据之前leader故障,此时会丢失数据。
此时follower需要同步leader中的数据,但是leader宕机了,挂了之后kafka集群会重新选举leader,选举出leader之后,并没有同步到原有的数据,就会造成数据的丢失
参数为-1时:
producer等待broker的ackpartition的leader和follower全部落盘成功后,才会返回ack,但是如果follower同步完成之后,在broker发送ack之前,leader发生故障,那么会出现数据的重复,但不会造成数据丢失
3,生产controller层进行测试
package com.example.mykafka.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ProducerCtrl {
@Autowired
private KafkaTemplate template;
@RequestMapping("/sendmsg/{pno}/{msg}")
public String sendMsg(@PathVariable("pno") String pno,@PathVariable("msg") String msg){
//方法1 只传消息内容,不给key
// ListenableFuture res = template.send("mydemo01",msg);
//
// res.addCallback(o-> System.out.println("消息发送成功"),throwable -> System.out.println("消息发送失败"));
//方法2 带key传消息
// template.send("mydemo01",key,msg);
//方法3 即带分区号也带key传消息
template.send("mydemo01",Integer.parseInt(pno),"key",msg);
return "success";
}
}consumer消费层(监听器)读取分区消息,前面输一个,这里就可以读取到一个(这里没有限定去读取那个分区,所以都会读出来)
package com.example.mykafka.services;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Optional;
@Service
public class KafkaConsumerServer {
@KafkaListener(topics = "mydemo01")
public void consumerData(ConsumerRecord record){
Optional value = Optional.ofNullable(record.value());
//isPresent判断是否value是否是null 如果null则返回false
if (value.isPresent()){
System.out.println(value.get());
}
}
} 浏览器上根据不同情况自行给值传参,用命令15查看结果可以看出:1,方式一,虽然没有给key值,但是kafka也会自己在消息前列创建一个key值进行分区,而且基本均匀分布。2,方式二,会根据你给的key,转为hash进行分区,此时的key一样就会进入同一个区。3,方式三:它会按照你给的分区号进行分区,忽略key。 即kafka的分区原则为:
-
)指明partition的情况下,使用指定的partition;
-
)没有指明partition,但是有key的情况下,将key的hash值与topic的partition数进行取余得到partition值;
-
)既没有指定partition,也没有key的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition数取余得到partition值,也就是常说的round-robin算法。
4,多分区多消费者多线程事件处理
配置类,
package com.example.mykafka.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.listener.ContainerProperties;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServer;
@Value("${spring.kafka.consumer.group-id}")
private String groupid;
@Value("${spring.kafka.consumer.enable-auto-commit}")
private String autoCommit;
@Value("${spring.kafka.consumer.key-deserializer}")
private String keyDeserializer;
@Value("${spring.kafka.consumer.value-deserializer}")
private String valueDeserializer;
@Value("${spring.kafka.consumer.auto-offset-reset}")
private String offsetReset;
@Value("${spring.kafka.consumer.consumer-thred-num}")
private Integer consumerThreadNum;
private Map getProperties(){
Map map = new HashMap();
map.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,kafkaServer);
map.put(ConsumerConfig.GROUP_ID_CONFIG,groupid);
map.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,autoCommit);
map.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,keyDeserializer);
map.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,valueDeserializer);
map.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,offsetReset);
return map;
}
private ConsumerFactory consumerFactory(){
Map prop = getProperties();
prop.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG,100); //每100毫秒 从kafka中拉取一批数据
return new DefaultKafkaConsumerFactory<>(prop);
}
//多线程工厂
@Bean(name = "kafkaThreadFactory")
public KafkaListenerContainerFactory> customFactory(){
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(consumerThreadNum); //连接池中消费者数量
factory.setBatchListener(true); //是否并发
factory.getContainerProperties().setPollTimeout(4000); //拉去topic的超时时间
//批量自动提交
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.BATCH);
//批量手动提交,关闭自动提交
//factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
} service层(这里如果为手动提交,把上面内容中,自动提交注释,取消手动提交的注释,并且在下面方法参数中添加Acknowledgment ack,手动提交代码注释取消。如果要自动提交则只需把上面代码中自动提交代码取消注释即可)
package com.example.mykafka.services;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Optional;
@Service
public class KafkaConsumerServer {
@KafkaListener(topics = "mydemo01",containerFactory = "kafkaThreadFactory")
public void batchConsumer(List> records){
System.out.println("当前线程:"+Thread.currentThread().getName()+"====>本次消费数量:"+records.size());
records.forEach(record -> System.out.println("topic名称:"+record.topic()+"分区号:"+record.partition()
+"消息:"+record.value()));
//ack手动提交
// ack.acknowledge();
// , Acknowledgment ack
}
} 自动提交与手动提交的区别:
自动提交:可能会丢失数据 ,poll之前就已经移动了offset
手动提交:不会丢失数据,执行客户端业务后,用户自己提交,但是会有重复数据问题
如果一个组还想重读某topic可用下面这个命令重置游标
kafka-consumer-groups.sh --bootstrap-server 192.168.88.180:9092 --group 组名--reset-offsets --all-topics --to-earliest --execute