GDB定位coredump
前言:一句话如下使用
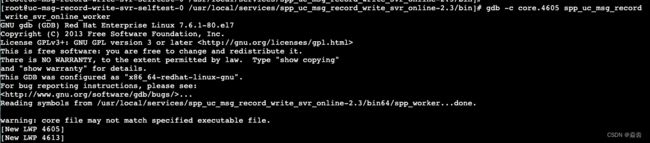
gdb [exec_file] [core_file]
#or
gdb -c [core_file] [exec_file] #-c指定转储的core文件
#进入后输入bt查看调用栈
bt #显示所有帧栈
bt 10 #显示前面10个帧栈(感觉没啥用)
bt -10 #显示后面10个帧栈(感觉没啥用)
bt full #显示帧栈以及局部变量
效果如下:
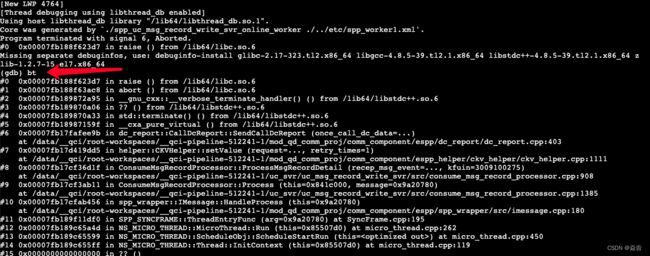
这篇文章主要讲GDB和coredump两个方面。
一、coredump
1、coredump简介
(1)、 core,又称coredump文件,准确来讲是Unix/Linux的记录机制产生的一种保存程序崩溃时现场状态的记录性文件。
(2)、为何需要这种记录机制?原因很简单,程序在在正常执行的时候当然是皆大欢喜,但是如果程序出现致命性错误难道不要保存一些现场信息已被分析使用吗!!Unix/Linux也是如此。Unix/Linux将程序工作的当前状况存储成一个文件,主要包括程序运行时候的内存状态、寄存器状态、堆栈指针、内存管理等现场信息,这就是coredump。可以说表示这种机制也可以表示该机制产生的文件。
(3)、在程序崩溃的一瞬间,内核会抛出当时该程序进程的内存详细情况,存储在core.xxx文件中(xxx为一个数字如core.699)。
(4)、如果硬要翻译的话。(core:内存/核心)、(dump:抛出/扔出)。coredump连起来可以直译为“吐核”。
2、coredump机制的优缺点分析
缺点:伴随着core进程的内存空间越大,生成core文件(将内存现场状态写入磁盘)的时间就越长。
优点:终止是内存、寄存器、各种函数堆栈信息的保留使得开发人员可以进行调试。
注:当然可以设定coredump产生的条件,指定当前回话可以生成的coredump文件大小(后续讲到)。
3、coredump文件的存储路径
之所以说这个问题是因为有时候执行程序出现提示Segmentation fault,但是当前目录下并没有coredump文件。
(1)查询core文件位置
执行如下指令:
cat /proc/sys/kernel/core_pattern默认值是core,表示当前目录。否则就是在指定目录下。
![]()
(2)更改coredump文件的存储位置
通过下面的命令可以更改coredump文件的存储位置,若你希望把core文件生成到/my/coredata目录下:
echo “/my/coredata”> /proc/sys/kernel/core_pattern
(3)指定内核生成的coredump文件的文件名
通过修改kernel的参数可以指定内核所生成的coredump文件的文件名。例如,使用下面的命令使kernel生成名字为core.filename.pid格式的core dump文件:
echo “/data/coredump/core.%e.%p” >/proc/sys/kernel/core_pattern
这样配置后,产生的core文件中将带有崩溃的程序名、以及它的进程ID。上面的%e和%p会被替换成程序文件名以及进程ID。
4、产生coredump文件的条件
ps:这个尤其值得注意。因为通常默认的core文件大小都是0.
(1)查询当前会话能生成的coredump文件的大小——ulimit -c
![]()
ps:通常段错误却不生成core文件的原因就是因为这个0.
(2)设置当前回话允许生成的coredump文件大小
1)ulimit -c unlimited
2)ulimit -c [size]
注:(1)这里的size单位是block,1block=512byte。
(2)以上设置都只是对当前会话有效,若想系统均有效,需进行如下设置。
3)在etc/profile中加入一下一行:
ulimit -c unlimited
ps:这个特性可以用于避免过大core文件生成的作用。
5、coredump产生的原因
造成程序coredump的原因有很多,这里总结一些常见情况:
(1)内存访问越界
a) 由于使用错误的下标,导致数组访问越界。
b) 搜索字符串时,依靠字符串结束符来判断字符串是否结束,但是字符串没有正常的使用结束符。
c) 使用strcpy, strcat, sprintf, strcmp,strcasecmp等字符串操作函数,将目标字符串读/写爆。应该使用strncpy, strlcpy, strncat, strlcat, snprintf, strncmp, strncasecmp等函数防止读写越界。
(2)多线程程序使用了线程不安全的函数。
应该使用下面这些可重入的函数,它们很容易被用错:
asctime_r(3c) gethostbyname_r(3n) getservbyname_r(3n)ctermid_r(3s) gethostent_r(3n) getservbyport_r(3n) ctime_r(3c) getlogin_r(3c)getservent_r(3n) fgetgrent_r(3c) getnetbyaddr_r(3n) getspent_r(3c)fgetpwent_r(3c) getnetbyname_r(3n) getspnam_r(3c) fgetspent_r(3c)getnetent_r(3n) gmtime_r(3c) gamma_r(3m) getnetgrent_r(3n) lgamma_r(3m) getauclassent_r(3)getprotobyname_r(3n) localtime_r(3c) getauclassnam_r(3) etprotobynumber_r(3n)nis_sperror_r(3n) getauevent_r(3) getprotoent_r(3n) rand_r(3c) getauevnam_r(3)getpwent_r(3c) readdir_r(3c) getauevnum_r(3) getpwnam_r(3c) strtok_r(3c) getgrent_r(3c)getpwuid_r(3c) tmpnam_r(3s) getgrgid_r(3c) getrpcbyname_r(3n) ttyname_r(3c)getgrnam_r(3c) getrpcbynumber_r(3n) gethostbyaddr_r(3n) getrpcent_r(3n)
(3)多线程读写的数据未加锁保护。
对于会被多个线程同时访问的全局数据,应该注意加锁保护,否则很容易造成coredump
(4)非法指针
a) 使用空指针
b) 随意使用指针转换。一个指向一段内存的指针,除非确定这段内存原先就分配为某种结构或类型,或者这种结构或类型的数 组,否则不要将它转换为这种结构或类型的指针,而应该将这段内存拷贝到一个这种结构或类型中,再访问这个结构或类型。这是因为如果这段内存的开始地址不是按照这种结构或类型对齐的,那么访问它时就很容易因为bus error而core dump。
(5)堆栈溢出
不要使用大的局部变量(因为局部变量都分配在栈上),这样容易造成堆栈溢出,破坏系统的栈和堆结构,导致出现莫名其妙的错误。
6、如何判断一个文件是core文件
readelf -h 读取coredump文件头。如下图所示:

二、GDB+coredump
1、使用GDB,需要先从执行文件中读取符号表信息,然后再读取core文件。即
gdb test core.2919
原因:core文件中没有符号表信息,无法进行调试。验证如下:objdump -x core.2919 | tail
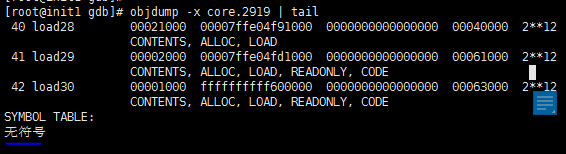
2、调试过程如下(和使用gdb调试其他程序几乎一样):
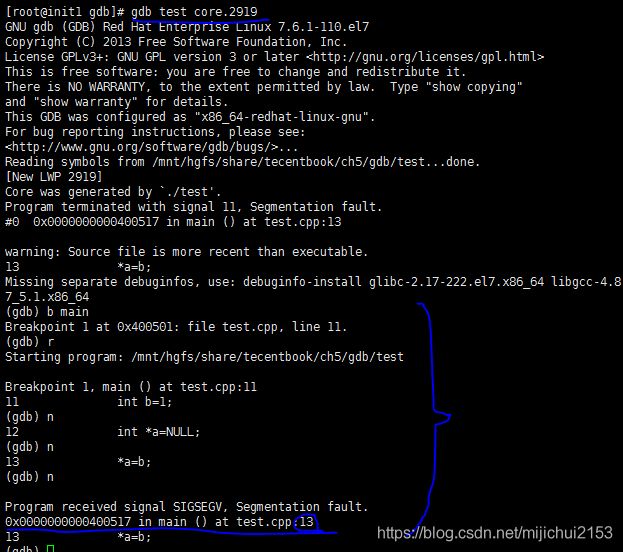
从上面可以看出出问题的是第十三行。
当然进入GDB之后也可以直接执行where可以立马找出出错的位置。如下所示:
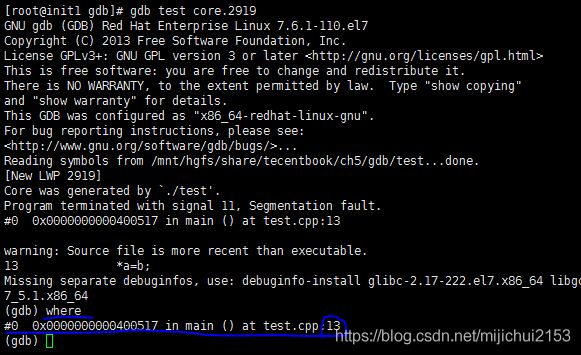
测试程序如下:
/*************************************************************************
> File Name: test.cpp
> Author: ma6174
> Mail: [email protected]
> Created Time: 2018年12月24日 星期一 19时10分39秒
************************************************************************/
#include
int main(){
int b=1;
int *a=NULL;
*a=b;
return 0;
}
三、演示gdb调试coredump
(1)源程序如下
#include
void do_it();
int main(){
do_it();
return 0;
}
void do_it(){
//定义一个字符指针变量a,指向地址1.这个地址肯定不是自己可以访问的,但是这行不会产生段错误。
char* p=1;
//视图更改地址1出的值,内核会终止该进程,并把core文件dump出来。
*p='a';
}
(2)必要的准备
1)确定core文件的生成位置,免得待会儿找不到。(此处采用默认的当前位置)
2)设置产生条件 ulimit -c unlimited ,免得一直段错误,就是不吐核。
3)记住编译时要加-g选项,gcc -g -o test1 test1.c
(3)运行test1程序 如下
![]()
说明core已经被dump了,查看对于的core文件是core.3177。
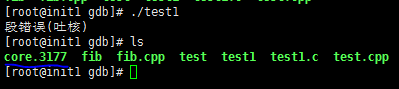
注:每一次执行./test1都会生成一个core.xxx文件,他们的记录的信息应该都是一样的。
(4)开始调试
调试过程非常简单:gdb test1 core.3177。进入后运行where即可列出出错的位置了。
