Day140-142.尚品汇:AOP+Redis缓存+redssion分布式锁、CompletableFuture异步编排、首页三级分类展示、Nginx静态代理
目录
Day08
一、获取商品详情 加入缓存
二、全局缓存:分布式锁与aop 整合
三、布隆过滤器
四、CompletableFuture 异步编排 jdk1.8
Day09
1. 将item 改为多线程并发 异步编排
2. 首页三级分类显示
3.页面静态化 -- Nginx静态代理
4. 商品的检索
4. 商品上架
Day08
hash 适合存储对象,在有修改的时候可以不反序列化其他字段;适合存储购物车
一、获取商品详情 加入缓存
商品详情页可能会出现并发,因此在获取数据时应该添加分布式锁保护数据库。
1. redisson方式
//获取商品详情 redisson 缓存方式
private SkuInfo getInfoRedissonCache(Long skuId) {
SkuInfo skuInfo = null;
try {
// 1.定义key,获取缓存,判断是否有数据
String skuKey = RedisConst.SKUKEY_PREFIX+ skuId +RedisConst.SKUKEY_SUFFIX;
skuInfo = (SkuInfo) redisTemplate.opsForValue().get(skuKey);
if(skuInfo == null){
// 2.定义LockKey,尝试获取锁
String locKey = RedisConst.SKUKEY_PREFIX + skuId + RedisConst.SKULOCK_SUFFIX;
RLock lock = redissonClient.getLock(locKey);
/*
第一种: lock.lock();
第二种: lock.lock(10,TimeUnit.SECONDS);
第三种: lock.tryLock(100,10,TimeUnit.SECONDS);
*/
// 3.尝试获取锁
boolean res = lock.tryLock(RedisConst.SKULOCK_EXPIRE_PX1, RedisConst.SKULOCK_EXPIRE_PX2, TimeUnit.SECONDS);
if(res){
try {
skuInfo = getSkuInfoDB(skuId);
// 4.存入空数据,防止缓存穿透
if(skuInfo==null){
SkuInfo skuInfoNull = new SkuInfo(); //对象的地址
redisTemplate.opsForValue().set(skuKey,skuInfoNull,RedisConst.SKUKEY_TEMPORARY_TIMEOUT,TimeUnit.SECONDS);
return skuInfoNull;
}
// 5.数据存入缓存
redisTemplate.opsForValue().set(skuKey,skuInfo,RedisConst.SKUKEY_TIMEOUT,TimeUnit.SECONDS);
return skuInfo;
} catch (Exception e){
e.printStackTrace();
}
finally {
// 6.解锁 加锁次数要与解锁次数一致
lock.unlock();
}
}else {
// 没获取到锁的线程等待;回旋
Thread.sleep(500);
return getSkuInfo(skuId);
}
}else {
// 缓存中有数据,直接返回
return skuInfo;
}
} catch (InterruptedException e) {
//redis宕机了!记录日志!发送短信方法!!
e.printStackTrace();
}
// 防止redis宕机,数据库兜底
return getSkuInfoDB(skuId);
}2. redis + lua 方式
lock,unlock 可能产生锁死,不需等待自旋机制;trylock可设定过期时间,需要等待自旋机制。
//获取商品详情 redis+lua 缓存方式
private SkuInfo getInfoRedisCache(Long skuId) {
SkuInfo skuInfo = null;
//1. 分析key是谁?
String skuKey = RedisConst.SKUKEY_PREFIX+ skuId +RedisConst.SKUKEY_SUFFIX;
//2. 分析使用那种数据类型? String Hash List set Zset
//模板自动进行序列化,可进行强转
skuInfo = (SkuInfo) redisTemplate.opsForValue().get(skuKey);
//3. 判断缓存中是否有这个数据,redis 非关系型数据库
if(skuInfo == null){
//4. 加锁,查询数据库放入缓存 redis +lua | redisson
String locKey = RedisConst.SKUKEY_PREFIX + skuId + RedisConst.SKULOCK_SUFFIX;
String uuid = UUID.randomUUID().toString();
//set key value ex timeout nx ==> 保证原子性,过期时间应大于业务执行时间
Boolean result = redisTemplate.opsForValue().setIfAbsent(locKey, uuid,
RedisConst.SKULOCK_EXPIRE_PX2, TimeUnit.SECONDS);
//5. 判断是否获取到锁
if(result){
// 6.从数据库获取数据,判断是否有此数据,防止缓存穿透
skuInfo = this.getSkuInfoDB(skuId);
if(skuInfo==null){
//存入空对象,时间要短一些
SkuInfo skuInfoNull = new SkuInfo();
redisTemplate.opsForValue().set(skuKey,skuInfoNull,
RedisConst.SKUKEY_TEMPORARY_TIMEOUT,TimeUnit.SECONDS);
//释放锁 省略...
return skuInfoNull;
}
// 7.将数据放入缓存
redisTemplate.opsForValue().set(skuKey,skuInfo,RedisConst.SKUKEY_TIMEOUT,TimeUnit.SECONDS);
// 8.释放锁; lua 脚本保证操作具有原子性
String scriptText = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
DefaultRedisScript redisScript = new DefaultRedisScript<>();
redisScript.setResultType(Long.class); //设置返回值类型
redisScript.setScriptText(scriptText);
redisTemplate.execute(redisScript, Arrays.asList(locKey),uuid);
return skuInfo;
}else {
// 9.没有获取到锁,等待;自旋
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getSkuInfo(skuId);
}
}else {
// 缓存中有数据直接放回
return skuInfo;
}
//数据库兜底 省略
}二、全局缓存:分布式锁与aop 整合
商品详情页面渲染数据都需要有分布式锁业务逻辑!
事务注解:底层就是使用aop 在不改变原有功能基础上,添加新的功能!
通知机制:前置、后置、环绕、异常
切点: 方法---注解;切面: 服务层
业务逻辑
1. 拼接缓存 key
2. 获取缓存数据,有则直接返回
3. 拼接锁 Lockey
4. 没有缓存数据,加锁,查询数据库
5. 判断是否存在数据,没有数据存入空对象防止缓存穿透
6. 将数据存入缓存,解锁
7. try cath,查询数据库兜底,防止redis 宕机
1. 自定义一个注解
@Target({ElementType.METHOD}) //注解的使用范围:方法上
@Retention(RetentionPolicy.RUNTIME) //表示注解的生命周期:运行时生效
public @interface GmallCache {
//在这里定义一个属性,组成缓存key的前缀
String prefix() default "cache";
}2. 自定义一个切面类
@Component
@Aspect
public class GmallCacheAspect {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private RedissonClient redissonClient;
//切面 AOP GmallCache注解
@SneakyThrows
@Around("@annotation(com.atguigu.gmall.common.cache.GmallCache)")
public Object cacheAroundAdvice(ProceedingJoinPoint joinPoint){
Object obj = new Object();
try {
//1.获取缓存key: 注解前缀+方法参数
//获取方法签名
MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();
//获取方法
Method method = methodSignature.getMethod();
//获取注解
GmallCache gmallCache = method.getAnnotation(GmallCache.class);
//获取注解参数
String prefix = gmallCache.prefix();
//组成key
Object[] args = joinPoint.getArgs();
String key = prefix + Arrays.asList(args).toString();
//2.通过key来获取缓存的数据;存在则返回 (封装为了方法)
obj = this.getRedisData(key,methodSignature);
if(obj==null){
//3.尝试获取锁
//通过方法签名 拼接锁的key
String locKey = key + ":lock";
RLock lock = this.redissonClient.getLock(locKey);
boolean res = lock.tryLock(RedisConst.SKULOCK_EXPIRE_PX1,
RedisConst.SKULOCK_EXPIRE_PX2,
TimeUnit.SECONDS);
if(res){
try {
//4.查询数据存入缓存,解锁
//执行方法体,查询数据库
obj = joinPoint.proceed(args);
//5.如果没有数据存入空值,防止缓存穿透
if(obj==null){
Object o = new Object();
//不能存入Object,转为JSON字符串
redisTemplate.opsForValue().set(key,JSON.toJSONString(o),
RedisConst.SKUKEY_TEMPORARY_TIMEOUT,TimeUnit.SECONDS);
return o;
}
//查到数据,存入缓存
this.redisTemplate.opsForValue().set(key,JSON.toJSONString(obj),
RedisConst.SKUKEY_TIMEOUT,TimeUnit.SECONDS);
return obj;
} finally {
// 解锁
lock.unlock();
}
}else {
//6.没有抢到锁,等待自旋
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
return cacheAroundAdvice(joinPoint);
}
}else {
//有缓存数据直接返回
return obj;
}
} catch (Throwable e) {
//redis宕机!发送消息、通知短信!
e.printStackTrace();
}
//7.查询数据库兜底:防止redis宕机
return joinPoint.proceed(joinPoint.getArgs());
}
private Object getRedisData(String key,MethodSignature methodSignature) {
//判断缓存数据是否存在,存在直接返回数据
String strJson = (String) redisTemplate.opsForValue().get(key);
if(!StringUtils.isEmpty(strJson)){
//将字符串转换为具体数据类型
Class returnType = methodSignature.getReturnType();
return JSON.parseObject(strJson,returnType);
}
return null;
}
}3. 需要缓存+锁的方法,加入自定义注解

4. 测试

如何防止二次调用?
三、布隆过滤器
可以解决缓存穿透:uuid随机穿透
底层就是一个二进制数据 默认0,能够判断一个元素在集合中是否存在,
一个元素一定不存在 或者 可能存在,存在一定的误判率{可通过代码调节}
优点:
1. 保密性好:存储的数据是0或1
2. 空间效率和查询时间 O(M) M:数组长度,O(K) K:hash 函数个数
3. 占用空间小
缺点:
误判率、删除困难
原理
存储数据:
1. 通过k个kash 函数计算hash值,对应二进制数组下标
2. 将二进制数组中的 0 改为 1
获取数据:
1. 通过k个kash 函数计算hash值,对应二进制数组下标
2. 如果对应的下标都是1 说明可能存在,如果是0说明一定不存在
原因:可能发生 hash碰撞 (冲突)
误判率和什么有关:hash函数个数、数据长度、数据规模
如何使用:
1. redisson 整合好了布隆过滤器2. 设置一些参数,在redis 中
3. 初始化设置:
数据规模,误判率!4. 保存sku的时候,直接将skuId 添加到布隆过滤器!
5. 在获取数据时判断布隆过滤器中是否有该商品!

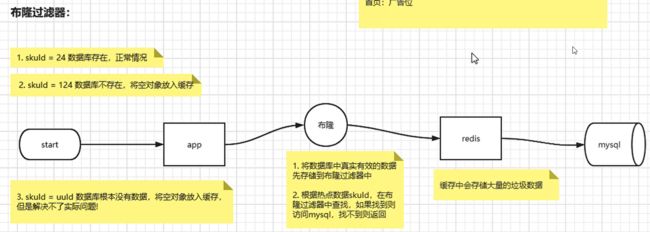
如何使用:
1. 初始化配置
@SpringBootApplication
@ComponentScan({"com.atguigu.gmall"})
@EnableDiscoveryClient
//CommandLineRunner:在启动时实现配置初始化
public class ServiceProductApplication implements CommandLineRunner {
@Autowired
private RedissonClient redissonClient;
public static void main(String[] args) {
SpringApplication.run(ServiceProductApplication.class, args);
}
//初始化方法
@Override
public void run(String... args) throws Exception {
//获取布隆过滤器
RBloomFilter2. 新增操作时添加布隆过滤器
//新增SkuInfo *
@Override
@Transactional(rollbackFor = Exception.class) //默认回滚运行时异常
public void saveSkuInfo(SkuInfo skuInfo) {
...
//添加布隆过滤器
RBloomFilter3. 获取数据时添加布隆过滤
//根据skuId 获取渲染数据
@Override
public Map getItem(Long skuId) {
HashMap map = new HashMap<>();
//添加布隆过滤,解决缓存穿透
RBloomFilter 四、CompletableFuture 异步编排 jdk1.8
在Java 8中, 新增加了一个包含50个方法左右的类: CompletableFuture,提供了非常强大的Future的扩展功能,可以帮助我们简化异步编程的复杂性,提供了函数式编程的能力,可以通过回调的方式处理计算结果,并且提供了转换和组合CompletableFuture的方法。
1.创建异步对象
runAsync(); -- 创建没有返回值的对象;
supplyAsync(); -- 创建一个有返回值的对象;
CompletableFuture runAsync = CompletableFuture.runAsync(()->{
System.out.println("runAsync:没有返回值");
});
CompletableFuture supplyAsync = CompletableFuture.supplyAsync(() -> {
System.out.println("supplyAsync:有返回值");
int i =1/0;
return "ok";
}); 2.计算完成时回调方法
whenComplete:能够获取到上一个结果和异常信息
whenCompleteAsync:异步执行
异步:有可能是本线程执行,也有可能是其他线程执行任务
exceptionally:单独处理异常,有返回值
CompletableFuture supplyAsync = CompletableFuture.supplyAsync(() -> {
System.out.println("supplyAsync:有返回值");
int i =1/0;
return 200;
}).whenComplete((t,e)->{
System.out.println("whenComplete可获取结果和异常信息");
System.out.println("t = " + t);
e.getMessage();
}).exceptionally(e->{
System.out.println("e = " + e);
return 404;
});
System.out.println("supplyAsync = " + supplyAsync.get()); 3.串行化并行化
带有Async默认是异步执行的。这里所谓的异步指的是不在当前线程内执行。
apply:应用
thenApply/thenApplyAsync 方法:当一个线程依赖另一个线程时,获取上一个任务返回的结果,有返回值。return ;
accept:接受
thenAccept/thenAcceptAsync 方法:消费处理结果。接收任务的处理结果,并消费处理,无返回值。void; 
thenRun 方法:只要上面的任务执行完成,就开始执行thenRun,只是处理完任务后,执行 thenRun的后续操作
// 并行:
CompletableFuture completableFutureA = CompletableFuture.supplyAsync(() -> {
return "hello";
});
// 创建B
CompletableFuture completableFutureB = completableFutureA.thenAcceptAsync((c) -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(c + ":\tB");
});
// 创建C
CompletableFuture completableFutureC = completableFutureA.thenAcceptAsync((c) -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(c + ":\tC");
});
System.out.println(completableFutureB.get());
System.out.println(completableFutureC.get()); 4.多任务组合方法
allOf:等待所有任务完成
anyOf:只要有一个任务完成
别忘了 .join();
Day09
1. 将item 改为多线程并发 异步编排
CompletableFuture,提高了10多ms!
@Service
public class ItemServiceImpl implements ItemService {
@Qualifier("com.atguigu.gmall.product.client.ProductFeignClient")
@Autowired
private ProductFeignClient productFeignClient;
@Autowired
private RedissonClient redissonClient;
@Autowired
private ThreadPoolExecutor threadPoolExecutor;
//根据skuId 获取渲染数据
@Override
public Map getItem(Long skuId) {
HashMap map = new HashMap<>();
//添加布隆过滤,解决缓存穿透
/*RBloomFilter @Configuration
public class ThreadPoolExecutorConfig {
// 7个核心参数;
@Bean
public ThreadPoolExecutor threadPoolExecutor(){
// 创建线程池:
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
5, // 核心线程数
100, // 最大线程数
3, // 空闲线程存活时间
TimeUnit.SECONDS, // 时间单位
new ArrayBlockingQueue<>(3), // 阻塞队列
Executors.defaultThreadFactory(), // 线程工厂
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略 抛出异常 ,由调用者机制,抛弃等待时间最久的任务,直接丢弃
);
return threadPoolExecutor;
}
}2. 首页三级分类显示

商品分类保存在base_category1、base_category2和base_category3表中,由于需要静态化页面,我们需要一次性加载所有数据,前面我们使用了一个视图base_category_view,所有我从视图里面获取数据,然后封装为父子层级
JSON数据格式如下:
[
{
"index": 1,
"categoryChild": [
{
"categoryChild": [
{
"categoryName": "电子书", # 三级分类的name
"categoryId": 1
},
{
"categoryName": "网络原创", # 三级分类的name
"categoryId": 2
},
...
],
"categoryName": "电子书刊", #二级分类的name
"categoryId": 1
},
...
],
"categoryName": "图书、音像、电子书刊", # 一级分类的name
"categoryId": 1
},
...
"index": 2,
"categoryChild": [
{
"categoryChild": [
{
"categoryName": "超薄电视", # 三级分类的name
"categoryId": 1
},
{
"categoryName": "全面屏电视", # 三级分类的name
"categoryId": 2
},
...
],
"categoryName": "电视", #二级分类的name
"categoryId": 1
},
...
],
"categoryName": "家用电器", # 一级分类的name
"categoryId": 2
}
]ManageServiceImpl 新增方法
public class JSONObject extends JSON implements Map
具有json 特性,同时具有map 方法!
//获取首页分类数据 难点:数据结构的组装
@Override
@GmallCache(prefix = "index:")
public List getBaseCategoryList() {
//存储一级分类数据集合
ArrayList list = new ArrayList<>();
//定义一个index
int index = 1;
//一、查询全部分类数据
List baseCategoryViewList = baseCategoryViewMapper.selectList(null);
//二、根据一级分类id进行分组,Long:一级id
Map> category1Map =
baseCategoryViewList.stream().
collect(Collectors.groupingBy(BaseCategoryView::getCategory1Id));
//遍历Map集合,封装数据 迭代器:JavaSE,遍历Map集合需要先转化为set
Set>> category1Set = category1Map.entrySet();
Iterator>> iterator = category1Set.iterator();
while (iterator.hasNext()){
//2.1 存储一级分类数据对象,获取当前元素进行封装
JSONObject category1 = new JSONObject();
//2.2 获取当前元素
Map.Entry> entry = iterator.next();
//2.3 获取一级分类id 以及对应的集合数据
Long category1Id = entry.getKey();
List baseCategoryViewList1 = entry.getValue();
//去重:取其中一条的name即可
String category1Name = baseCategoryViewList1.get(0).getCategory1Name();
//2.4 封装数据
category1.put("index",index);
category1.put("categoryId",category1Id);
category1.put("categoryName",category1Name);
//2.4声明一个集合存储二级分类数据
List categoryChild2List = new ArrayList<>();
//index 迭代
index++;
//三、获取二级分类数据:根据getCategory2Id分组,遍历
Map> category2Map = baseCategoryViewList1.stream()
.collect(Collectors.groupingBy(BaseCategoryView::getCategory2Id));
Iterator>> iterator1 = category2Map.entrySet().iterator();
while (iterator1.hasNext()){
//3.1 存储二级分类数据对象
JSONObject category2 = new JSONObject();
//3.2 获取二级分类数据
Map.Entry> entry1 = iterator1.next();
Long category2Id = entry1.getKey();
List baseCategoryViewList2 = entry1.getValue();
String category2Name = baseCategoryViewList2.get(0).getCategory2Name();
//3.2 封装二级分类数据
category2.put("categoryId",category2Id);
category2.put("categoryName",category2Name);
//3.3 存入二级分类集合
categoryChild2List.add(category2);
//声明一个集合存储二级分类数据
List categoryChild3List = new ArrayList<>();
//四、获取三级分类数据
baseCategoryViewList2.forEach(baseCategoryView -> {
//获取三级分类数据,封装,存入三级分类集合
JSONObject category3 = new JSONObject();
category3.put("categoryId",baseCategoryView.getCategory3Id());
category3.put("categoryName",baseCategoryView.getCategory3Name());
categoryChild3List.add(category3);
});
//将三级分类集合添加到二级分类
category2.put("categoryChild",categoryChild3List);
}
//将二级分类集合添加到一级分类
category1.put("categoryChild",categoryChild2List);
//将一级分类集合添加到总集合
list.add(category1);
}
return list;
} web-all远程调用
@Controller
public class IndexController {
@Qualifier("com.atguigu.gmall.product.client.ProductFeignClient")
@Autowired
private ProductFeignClient productFeignClient;
@Autowired
private TemplateEngine templateEngine;
//访问首页控制器
// www.gamll.com/ www.gmall.com/index.html
//String[] s = {"1m","m2"};
@GetMapping({"index.html","/"})
public String index(Model model){
Result result = productFeignClient.getBaseCategoryList();
model.addAttribute("list",result.getData());
return "index/index";
}
}3.页面静态化 -- Nginx静态代理
先创建一个静态化页面
indexController
// 创建静态化页面
@GetMapping("createIndex")
@ResponseBody
public Result createIndex(){
//获取数据
Result result = productFeignClient.getBaseCategoryList();
//设置页面显示的内容
Context context = new Context();
context.setVariable("list",result.getData());
//定义输出对象
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter("E:\\index.html");
} catch (IOException e) {
e.printStackTrace();
}
// 调用process();方法创建模板
templateEngine.process("index/index.html",context,fileWriter);
return Result.ok();
}使用 nginx 静态化处理,将静态化页面与静态资源放入nginx 的文件夹
如果项目中的数据变化很小,可以使用静态化形式渲染
nginx.conf:
server {
listen 8787;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
}
直接启动nginx 访问即可
4. 商品的检索
mysql 数据达到500W 或 2GB 提倡分库分表
ES为什么快?倒排索引:通过value 找 id,value 通过中文分词器 分词之后的数据!
全文检有两个入口:分类检索,全文检索
展示的内容:品牌、平台属性-属性值、sku、分页、分类Id、商品的名称、商品的默认图片
、商品的价格等数据
用来过滤:品牌Id ,平台属性值Id,分类Id、商品的名称 -- 分词,高亮
全文检索数据直接来自于 es,es 数据来自于数据库
nested是一种特殊的对象object数据类型(specialised version of the object datatype ),允许对象数组彼此独立地进行索引和查询。
创建索引库方式
第一种:直接使用PUT 命令创建第二种:使用注解 @Document 创建
es 6.8.1 需要自己访问控制器才能生成
es 7.8.0 不需要访问控制器,只需要启动项目就会自动创建

搭建service - list 模块

4. 商品上架
本质:把数据库的数据弄到ES里;查询数据之后将数据传递给Goods实体类,ES保存这个实体类。