Java【快速排序】算法, 凭什么以 “快速“ 冠名?
文章目录
- 前言
- 一、排序相关概念
-
- 1, 什么是排序
- 2, 什么是排序的稳定性
- 3, 七大排序分类
- 二、快速排序
-
- 1, 挖坑法 图文解析
- 2, 挖坑法 代码实现
- 3, Hoare法 图文解析
- 4, Hoare法 代码实现
- 三、性能分析
- 四、快速排序的优化
-
- 1, 优化选取基准
- 2, 优化小数组的排序方案
- 五、七大排序算法总体分析
前言
各位读者好, 我是小陈, 这是我的个人主页
小陈还在持续努力学习编程, 努力通过博客输出所学知识
如果本篇对你有帮助, 烦请点赞关注支持一波, 感激不尽
希望我的专栏能够帮助到你:
JavaSE基础: 从数据类型 到 类和对象, 封装继承多态, 接口, 综合小练习图书管理系统等
Java数据结构: 顺序表, 链表, 二叉树, 堆, 哈希表等 (正在持续更新)
JavaEE初阶: 多线程, 网络编程, html, css, js, severlet, http协议, linux等(正在持续更新)
本篇继续分享七大排序算法中的 希尔排序 , 其余六个算法也有介绍噢
想看哪个点哪个 : 直接插入排序, 选择排序, 希尔排序, 堆排序, 冒泡排序, 归并排序
提示:是正在努力进步的小菜鸟一只,如有大佬发现文章欠佳之处欢迎评论区指点~ 废话不多说,直接发车~
一、排序相关概念
1, 什么是排序
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作
以 int 类型数据从小到大排序为例:
排序前:4,1,3,6,8,7,2,5
排序后:1,2,3,4,5,6,7,8
2, 什么是排序的稳定性
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
以 int 类型数据从小到大排序为例:
排序前:4,1,3a,6,8,7,2,3b,5(3a 在 3b 之前)
排序后:1,2,3a,3b,4,5,6,7,8(3a 还在 3b 之前,稳定)
排序后:1,2,3b,3a,4,5,6,7,8(3a 不在 3b 之前,不稳定)
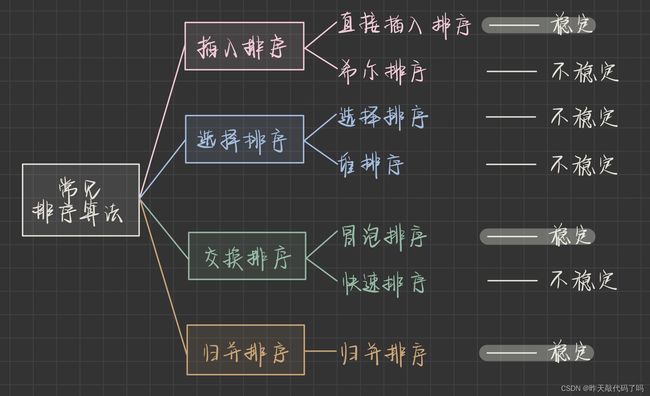
3, 七大排序分类
以下是常见的 7大排序 算法
二、快速排序
1, 挖坑法 图文解析
希尔排序 是对 直接插入排序 的优化, 同属于插入排序
堆排序 是 选择排序 的优化, 同属于选择排序
快速排序 是对 冒泡排序 的优化, 同属于交换排序
快速排序被称为20世纪十大算法之一,也是很多语言的源码中使用的排序算法
基本思想: 通过一趟排序, 找到基准(枢轴), 将待排序数组分割成独立的两部分, 基准(枢轴) 的一边的数据均比另一边的大 / 小, 再对两边的数据分别继续快速排序, 最终整个数组有序
有点晦涩难懂, 如图所示:
快速排序有几个不同的实现方式, 这里介绍 : 挖坑法 和Hoare法 效率上没有区别, 只是核心代码的实现方式有细微差异
挖坑法 :
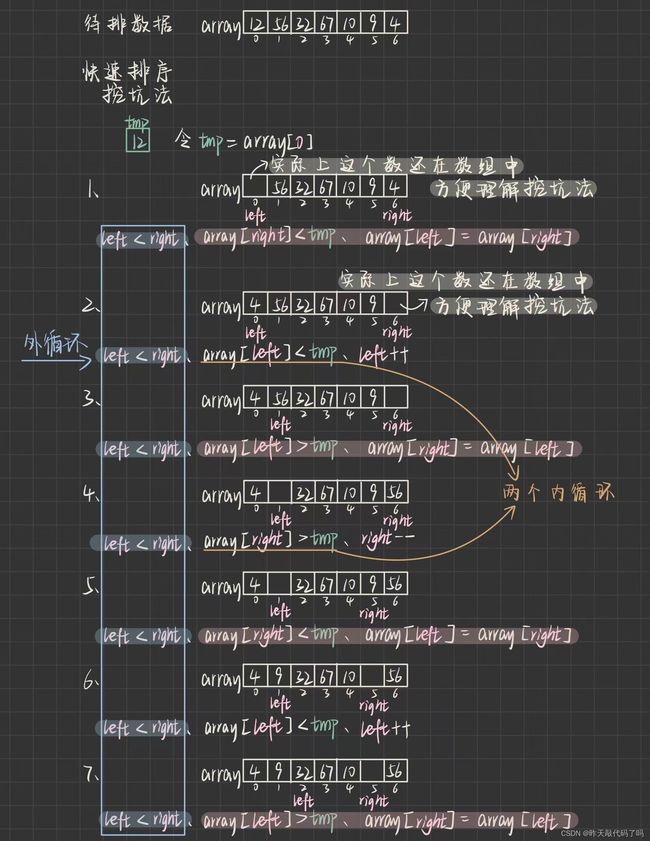

挖坑法可以理解为,数据每移动一次,就会在原地留下一个“坑”,实际上数组还在原处,只是覆盖到了目标位置上,可是这个数据已经走了,可以当它不在了,空出来一个“坑”
以上是找到快速排序算法中最核心的部分 :找到基准(枢轴)
同时算法中加入了二叉树的思想,找到基准后,把基本当作 “根” ,利用 “左右子树” 递归遍历的思想完成整个数组的排序
所以我们把找到基准这个方法 pirtiton1() 独立封装出来
2, 挖坑法 代码实现
/**
* 快排
* 时间复杂度:最好情况:O(N^log₂N)
* 最坏情况:有序或逆序:O(N^N) 数据量大时有可能栈溢出异常
* 空间复杂度:最好情况:O(logN)
* 最坏情况:有序或逆序:O(N)
* 稳定性:不稳定
*/
public static void quickSort(int[] array) {
quick(array, 0, array.length - 1);
}
private static void quick(int[] array, int start, int end) {
// 取大于号,防止 start > end
if (start >= end) {
return;
}
int pivot = pirtiton2(array, start, end);
quick(array, start, pivot - 1);
quick(array, pivot + 1, end);
}
// 挖坑法
private static int pirtiton1(int[] array, int left, int right) {
int tmp = array[left];
while (left < right) {
// 为什么判断条件加等号,
// 用int[] arr = {5, 7, 3, 1, 4, 9, 6, 5}测试
while (left < right && array[right] >= tmp) {
right--;
}
array[left] = array[right];
while (left < right && array[left] <= tmp) {
left++;
}
array[right] = array[left];
}
array[left] = tmp;
return left;
}
以上是挖坑法的实现,下面图解 Hoare法 的实现方式
3, Hoare法 图文解析
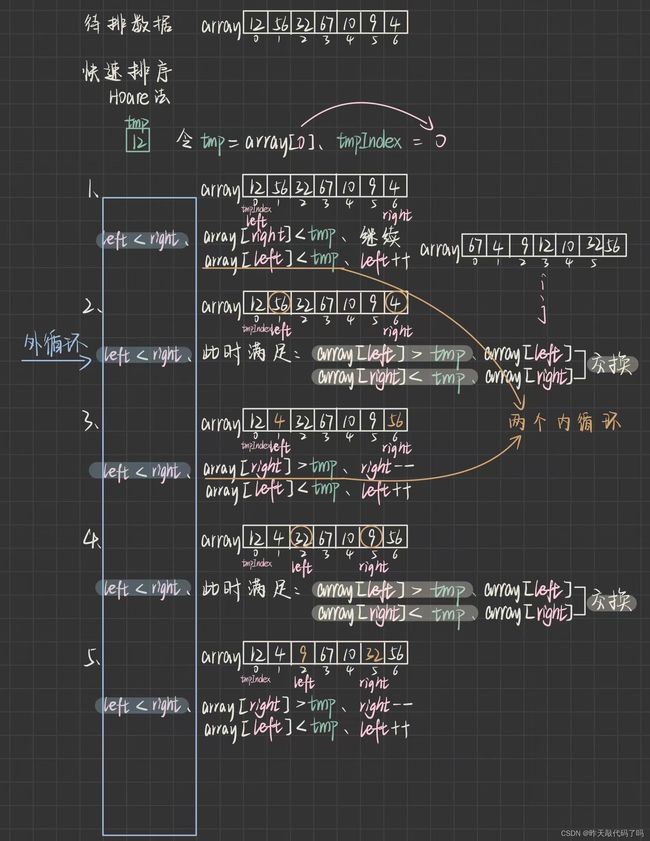

由于快速排序算法最早是由 Tony Hoare 设计出来的,所以 Hoare法算 是比挖坑法更原始正统的算法
挖坑法 和 Hoare 法的不同体现在找到基准的实现方式,二者效率上基本一致
理解了过程,来看代码如何实现:
4, Hoare法 代码实现
// Hoare法
private static int pirtiton2(int[] array, int left, int right) {
int tmp = array[left];
int tmpIndex = left;
while (left < right) {
while (left < right && array[right] >= tmp) {
right--;
}
while (left < right && array[left] <= tmp) {
left++;
}
swap(array, left, right);
}
swap(array, tmpIndex, left);
return left;
}
三、性能分析
时间复杂度 :
时间性能取决于递归的深度
最好情况:二叉树几乎平衡时,也就是数组划分的比较均匀,递归的作用发挥到最大,递归次数最少,只需要 log₂N 次,时间复杂度是O(log₂N),递归过程中还要对 i,j 下标一起扫描数组,所以总体时间复杂度是O(N* log₂N)
最坏情况:二叉树极度不平衡时,也就是二叉树是一颗单分支的斜树(每次划分完基准后,基准总是当前数组中的最小/大值,导致左/右侧没有数据),这种情况下,递归就是一个“冤种”,递归的作用只有徒增时间空间的开销,要递归 N-1 次,并且加上 i,j 下标一起扫描数组,整体时间复杂度达到(N2)
空间复杂度:
空间性能取决于递归消耗的栈空间
最好情况:已经分析过,需要递归 log₂N 次,空间复杂度为O(log₂N )
最坏情况,已经分析过,需要递归 N-1 次,空间复杂度为O(N)
稳定性:
不稳定
四、快速排序的优化
上述的快速排序还有很多值得优化的地方,刚刚分析过时间复杂度最坏情况下 达到O(N2),是因为基准(枢轴)的位置太“刁钻”
那么第一步优化就是, 如何让基准的位置更合适一些,让他每次都尽量出现在数组的中间, 这样 “二叉树” 就会接近平衡
1, 优化选取基准
不能使用生成随机数,这也是看运气的,如果数据量很大,而刚好运气很差,随机值生成在极端,还是在做无用功,生成随机数本身也有时间上的开销
更合适的改进方法应该是 三数取中法,一般选取 left,right,mid 下标三个数
比如 left,right,mid 下标的值分别是,200,300,50,一眼就能看出中间大小的数是200,那么就选取 200 作为基准,200 和 300 交换即可
对于一组待排序数据来说, left,right,mid 下标的值都相对很小 / 大的概率是很低的,因此取 mid 的值作为中间值的可能性是相对比较高的
来看代码实现:
private static int getMid(int[] array, int left, int right) {
int mid = (left + right) >>> 1;
if (array[left] < array[right]) {
// 左比右小
if (array[mid] < array[left]) {
return left;
} else if (array[mid] > array[right]) {
return right;
}else {
return mid;
}
}else {
if (array[mid] < array[right]) {
return right;
} else if (array[mid] > array[left]) {
return left;
}else {
return mid;
}
}
}
对于数据非常大的情况下,三数取中还是不足以保证取到合适的中间值,所以可以再改进为九数取中法,感兴趣的可以自己了解一下
2, 优化小数组的排序方案
第一步改进之后,数组被划分的过程可以更近似于平衡二叉树
那么问题又来了 : 当结点个数越来越多,树深度最大的两层结点个数占了整棵树的很大一部分
而放在快速排序当中,这 “结点” 就是被 数组划分之后的子区间(并且子区间长度很小)
对于这些数组片段来说还是会继续使用递归,那么 深度最大的两层结点(子区间)递归开销就会变得非常大,极有可能会导致 栈溢出
基于这一点,就必须考虑如何才能减少递归次数, 答案是可以使用直接插入排序
好处:
无论什么排序,一定是越排越有序,总不能越排越无序,那得排到猴年马月天荒地老海枯石烂,而 直接插入排序有一个特点是数据集合越有序,效率越高!!!
不仅是原始待排序数组很大时需要避免栈溢出,当 给定的原始数组很小 的时候也不太适合用递归,因为数据量太小了,再使用递归实际上是"大材小用" “杀鸡用牛刀” “大炮打蚊子”,所以更加适合简单的排序算法
解决方案 就是 : 每次递归前判断此时子区间的长度,可以给定一个界限,看心情,这里给定 10
在原本的直接插入排序代码上稍作修改即可
private static void insertSort2(int[] array, int left, int right) {
// 从小到大排序
if (array == null) {
return;
}
int tmp = 0;
for (int i = left+1; i <= right; i++) {
tmp = array[i];
for (int j = i - 1; j >= left; j--) {
// j往后走
if (array[j] > tmp) {
array[j + 1] = array[j];
array[j] = tmp;
} else {
break;
}
}
}
}
优化后的 quick()方法:
private static void quick(int[] array, int start, int end) {
// 取大于号,防止 start > end
if (start >= end) {
return;
}
// 优化1,三数取中法,让start位置尽量靠近中间
int mid = getMid(array, start, end);
swap(array, start, mid);
// 优化2,最后小区间使用插入排序,减少递归次数
if(end-start+1 <= 10) {
insertSort2(array, start, end);
return;
}
int pivot = pirtiton2(array, start, end);
quick(array, start, pivot - 1);
quick(array, pivot + 1, end);
}
五、七大排序算法总体分析
建议对七大算法都有认识之后, 再对比分析~~
想看哪个点哪个 : 直接插入排序, 选择排序, 希尔排序, 堆排序, 冒泡排序, 归并排序
没有完美的排序算法,任何一种算法都是有优点和缺陷的,即便是大名鼎鼎的快速排序,也只是整体上效率比较高,性能相对更优越
现在就整体分析一下各种排序的优缺点

早期的排序算法平均时间复杂度都是O(N2); 因为原理比较简单, 但性能较差, 所以 一般把直接插入排序,选择排序,冒泡排序归为简单排序一类, 另外四种排序都归于 改进排序
从平均情况看:
改进过的排序: 希尔排序, 堆排序, 归并排序, 快速排序要胜过简单排序的性能, 而四个改进算法中, 希尔排序的性能最差
时间复杂度:
直接插入排序和冒泡排序最快
从最好情况看从最坏情况看:
堆排序和归并排序的性能更胜过快排和其他简单排序
综合来看:
堆排序和归并排序比较稳定和强大, 情况最坏时好用
直接插入排序和冒泡排序, 最好情况时最好用,
而快速排序比较极端, 最好最坏情况都有缺陷 但是 快速排序能够称之为快速排序, 是因为它的综合性能最强,一般情况下是最快的
从稳定性来看:
改进排序中只有归并排序
从数据个数上看:
数据量越少, 越适合用简单排序, 因为堆排, 快速排序, 归并排序, 都用到了递归, 对于少量数据排序有点"炮弹打蚊子"
只要是交换时, 两数据相邻就是稳定的算法,只要是跳跃式的交换就是不稳定, 当然别忘了, 稳定的算法也可以修改代码更改成不稳定的
如果本篇对你有帮助,请点赞收藏支持一下,小手一抖就是对作者莫大的鼓励啦~
上山总比下山辛苦
下篇文章见