使用Python学会jsonpath+re正则
前言:在开发测试中,遇到一些数据提取是经常的事情,如果我们没有特定的工具或者不知道怎么做数据提取,那jsonpath+Re是你必须会的。包括我们的接口测试的接口提取都需要用到喔,下面就一起来学习学习吧
1、了解Jsonpath
一、Jsonpath是什么?
a)与xpath从xml中提取元素的方式类似,jsonpath就是,从json串中提取内容的表达式
二、使用jsonpath的基本用法
特殊字符特殊含义:
————————————————
$: 根元素
.[]: 子元素
..: 递归搜索
*: 通配
[]: 子元素操作符,索引取值,切片,字段名称取值(多个字段用逗号隔开)
?(): 过滤表达式 "$..python.[?(@.age<20)]"注意 .$就是从根目录开始找,第一个字母永远都是.$开始
遇到字典就用.来取:.number
遇到列表就用索引的方式来取$.phoneNumbers[0]三、如何练习jsonpath?
JSONPath Online Evaluator练习网址如下:JSONPath Online Evaluator
例子:取这个JSON串里面 “city”对应的值
答案:$..city --$..就是全局去找这个city找到就返回出来

四、jsonpath实战例子:
import pprint
from jsonpath import jsonpath
teacher_info = {"lemon":
{"python": [
{"name": "海励",
"sex": "男",
"age": 30,
"height": 175,
"info":"python自动化老师"
},
{"name": "木森",
"sex": "男",
"age": 28,
"height": 185,
"info":"python测开老师"
},
{"name": "小简",
"sex": "女",
"age": 18,
"height": 170,
"info":"python自动化老师"
},
{"name": "心蓝",
"sex": "男",
"age": 28,
"height": 185,
"info":"python测开老师"
},
{"name": "雨泽",
"sex": "男",
"age": 28,
"height": 190,
"info":"python自动化老师"
}
],
"java": {
"name": "三宝",
"sex": "男",
"age": 30,
"height": 185.5,
"info":"java测开老师"
}
}
}
#?(@.name in ['小简','木森'])
res = jsonpath(teacher_info,"$..python.[?(@.name in ['小简','木森'])].[name,age]") #
res = jsonpath(teacher_info,"$..python.[?(@.age>29 || @.height>175)]") #多条件匹配,或运算 || or
res = jsonpath(teacher_info,"$..python.[?(@.age<30 && @.height>175)]") #多条件匹配,与运算 && and
res = jsonpath(teacher_info,"$..python.[?(@.age==18)]") #单个条件 等于
res = jsonpath(teacher_info,"$..python.[?(@.age<20)]") #单个条件 小于
res = jsonpath(teacher_info,"$..python.[name,age,height]") #获取指定的字段
res = jsonpath(teacher_info,"$..python.[0:3]") #切片
res = jsonpath(teacher_info,"$..python.[0,1]") #索引取值
res = jsonpath(teacher_info,"$.lemon.*") #通配符
res = jsonpath(teacher_info,"$..name") # 递归查找 【掌握】
res = jsonpath(teacher_info,"$.lemon.python") #子元素
res = jsonpath(teacher_info,"$.lemon[python]")#子元素
res = jsonpath(teacher_info,"$[lemon][python]")#子元素
pprint.pprint(res)2、了解正则表达式RE
一、什么是正则表达式:
a)正则表达式: 操作对象-字符串,从字符串当中,提取匹配的内容
正则表达式: 操作对象-字符串
1、从字符串当中,提取匹配的内容
re模块
re.findall -- 返回的是列表,列表里是匹配的所有字符。
1、匹配1个字符
. 除换行符以外的所有字符 \n
\d 只匹配数字0-9
\D 匹配非数字
\w 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”, 支持中文
\W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”
[a-z] 匹配小写字母
[A-Z] 匹配大写字母
[0-9] 匹配数字
[abcd] 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”
[a|b] 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”
2、数量匹配
* 匹配前一个字符,0次或者多次
+ 匹配前一个字符,1次或者多次
? 匹配前一个字符,0次或1次
{n} 匹配前一个字符n次
{n,m} 匹配前一个字符最少是n次,最多是m次
{n,} 匹配前一个字符最少是n次,没有下限。
贪婪模式: 尽可能的匹配更多更长 对人民币贪婪,越多越好。
非贪婪模式: 尽可能的匹配更少 在数量表达后面加上? 对无偿加班时间,越少越好。
边界匹配:
^ 匹配输入字符串的开始位置
$ 匹配输入字符串的结束位置
匹配分组:()
"""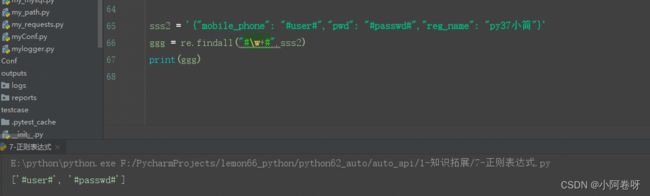
b)非贪婪模式:
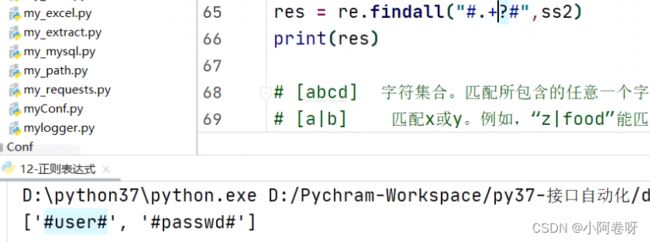
c)贪婪模式:

regular表达式学习手册:
https://www.cnblogs.com/Simple-Small/p/9150947.html
https://tool.oschina.net/uploads/apidocs/jquery/regexp.html
https://gitee.com/thinkyoung/learn_regex