linux内核驱动学习--构造和运行模块
linux设备驱动–构造和运行模块
目录
- linux设备驱动–构造和运行模块
-
- Hello World模块
- 将模块链接到内核
- 用户空间和内核空间
- 当前进程
- 其他一些细节
- 装载和卸载模块
- 版本依赖
- 内核符号表
- 预备知识
- 初始化和关闭
- 清除函数
- 初始化过程中的错误处理
- 模块参数
Hello World模块
下面这段代码是完整的 "hello world"模块
#include 这个模块定义了两个函数,其中一个在模块被装载到内核时调用(hello_init),而另一 个则在模块被移除时调用(hello_exit)。 module _init和module_exit行使用了内核的特殊宏来表示上述两个函数所扮演的角色。另外一个特殊宏(MODULE_LICENSE)用来 告诉内核、该模块采用自由许可证,如果没有这样的声明,内核在装载该模块时会产生抱怨。
函数printk在Linux内核中定义,功能和标准C库中的函数print[类似。内核需要自己单独的打印输出函数,这是因为它在运行时不能依赖于C库。
注意:
优先级只是个字符串,诸如<1>.该字符串置于printk格式字符亭的前面.请注意, KERN_ALERT之后并不使用逗号,但添加逗号的打字错误却会经常发生,幸好编辑器能帮助我们捕获这个错误。
将模块链接到内核
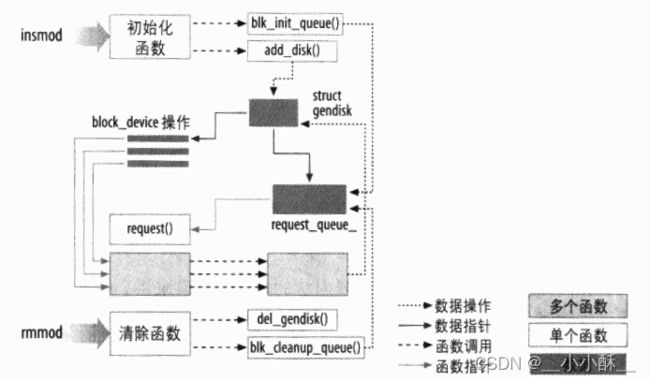
用户空间和内核空间
内核运行在最高级别(也称作超级用户态),在这个级别中可以进行所有的操作。而应用程序运行在最低级别(即所谓的用户态)、在这 个级别中,处理器控制着对硬件的直接访问以及对内存的非授权访问。
我们通常将运行模式称作内核空间和用户空间。这两个术语不仅说明两种模式具有不同的优先权等级,而且还说明每个模式都有自己的内存映射,也即自己的地址空间。
每当应用程序执行系统调用或者被硬件中断挂起时,Unix将执行模式从用户空间切换到内核空间。执行系统调用的内核代码运行在进程上下文中,它代表调用进程执行操作, 因此能够访问进程地址空间的所有数据。而处理硬件中断的内核代码和进程是异步的, 与任何一个特定进程无关。
当前进程
虽然内核模块不像应用程序那样顺序地执行,然而内核执行的大多数操作还是和某个特定的进程相关。内核代码可通过访问全局项current来获得当前进程。。current 在
实际上,与早期Linux内核版本不同.2.6中current不再是一个全局变量。为了支持
SMP(Symmetric multiprocessor, SMP)系统, 内核开发者设计了一种能找到运行在相关CPU上的当前进程的机制。这种机制必须是快速的, 因为对curr ent的引用会频繁发生。这样, 一种不依赖千特定架构的机制通常是,将指向task_struct结构的指针隐藏在内核栈中。这种实现的细节同样也对其他内核子系统隐藏、设备驱动程序只要包含
printk(KERN_INFO "The process is \"%s\" (pid %i) \n", current->comm, current->pid);
存储在current->comm成员中的命令名是当前进程所执行的程序文件的基本名称(basename), 如果必要, 会裁剪到l5个字符以内。
其他一些细节
-
应用程序在虚拟内存中布局,并具有一块很大的栈空间。当然,栈是用来保存函数调用历史以及当前活动函数中的自动变量的。而相反的是,内核具有非常小的栈,它可能只和一个4096字节大小的页那样小。我们自己的函数必须和整个内核空间调用链一同共享这个栈。因此,声明大的自动变最并不是一个好主意,如果我们需要大的结构,则应该在调用时动态分配该结构。
-
经常会在内核API中看到具有两个下划线前缀(__)的函数名称。具有这种名称的函数通常是接口的底层组件,应谨慎使用。实质上,双下划线告诉程序员:"谨慎调用, 否则后果自负。"
-
内核代码不能实现浮点数运算。如果打开了浮点支持,在某些架构上,需要在进人和退出内核空间时保存和恢复浮点处理器的状态。这种额外的开销没有任何价值,内核代码 中也不需要浮点运算。
装载和卸载模块
-
insmod工具:
构造模块之后,下一步就是将模块装人内核.如前所述,insmod为我们完成这项工作. insmod程序和Id有些类似,它将模块的代码和数据装入内核,然后使用内核的符号表解析模块中任何未解析的符号。然而,与链接器不同,内核不会修改模块的磁盘文件,而 仅仅修改内存中的副本.insmod可以接受一些命令行选项(参见它的手册页),并且可 以在模块链接到内核之前给模块中的整型和字符串型变址赋值。因此,一个良好设计的模块可以在装载时进行配置,这比编译时的配置为用户提供了更多的灵活性,但有些情况下仍然要使用编译时的配置。本章后面的“模块参数”一节中会介绍装载时的配置方法。
内核是如何支持insmod工作的:
实际上它依赖于定义在kernel/module.c中的一个系统调用。函数sys_init_module给模块分配内核内存以便装载模块,然后, 该系统调用将模块正文复制到内存区域,井通过内核符号表解析模块中的内核引用,最后调用模块的初始化函数。
如果仔细阅读内核源码,我们会发现有且只有系统调用的名字前带有 “sys_” 前缀,而其他任何函数都没有这个前缀。这种命名上的区别使我们在源码中grep系统调用时非常方便。 -
modprobe工具:
和insmod类似,modprobe也用来将模块装载到内核中。
它和insmod的区别在于:
它会考虑要装载的模块是否引用了一些当前内核不存在的符号。如果有这类引用,modprobe会在当前模块搜索路径中查找定义了这些符号的其他模块。如果modprobe找到了这些模块(即要装载的模块所依赖的模块),它会同时将这些模块装载到内核。如果在这种情况下使用insmod,则该命令会失败,并在系统日志文件中记录"unresolvedsymbols(未解析的符号)"消息。 -
rmmod工具:
我们可以使用rmmod工具从内核中移除模块。注意,如果内核认为模块仍然在使用状态(例如,某个程序正打开由该模块导出的设备文件),或者内核被配置为禁止移除模块,则无法移除该模块。配置内核井使得内核在模块忙的时候仍能“强制”移除模块也是可能的。 -
lsmod工具:
lsmod程序列出当前装载到内核中的所有模块,还提供了其他一些倌息,比如其他模块 是不是在使用某个特定模块等。lsmod通过读取/proc/modules虚拟文件来获得这些信 息。有关当前已装载模块的倌息也可以在sysfs虚拟文件系统的/sys/module下找到。
版本依赖
内核不会假定一个给定的模块是针对正确的内核版本构造的.我们在构造过程中,可以将自己的模块和当前内核树中的一个文件(即vermagic.o)链接;该目标文件包含了大虽有关内核的信息,包括目标内核版本、编译器版本以及一些重要配置变量的设置。在试图装载模块时,这些信息可用来检查模块和正在运行的内核的兼容性。如果有任何不匹配,就不会装载该模块,同时可以看到如下信息:
# insmod hello.Ko
Error inserting '/hello. ko': -1 Invalid module fonnat
查看系统日志文件(/var/log/messages或者系统配置使用的文件),将看到导致模块装载失败的具体原因。
内核符号表
在通常情况下, 模块只需实现自己的功能,而无需导出任何符号。但是,如果 其他模块需要从某个模块中获得好处时, 我们也可以导出符号。
Linux内核头文件提供了一个方便的方法来管理符号对换块外部的可见性,从而减少了 可能造成的名字空间污染(名字空间中的名称可能会和内核其他地方定义的名称发生冲突),并且适当隐藏信息。如果一个模块需要向其他模块导出符号,则应该使用下面的宏。
EXPORT_SYMBOL(name);
EXPORT_SYMBOL_GPL(name);
这两个宏均用于将给定的符号导出到模块外部._GPL版本使得要导出的模块只能被 GPL许可证下的模块使用.符号必须在模块文件的全局部分导出,不能在函数中导出, 这是因为上面这两个宏将被扩展为一个特殊变量的声明,而该变量必须是全局的.该变量将在模块可执行文件的特殊部分(即一个"ELF段")中保存,在装载时,内核通过这个段来寻找校块导出的变量(可以查阅
预备知识
大部分内核代码中都要包含相当数最的头文件,以便获得函数、数据类型和变址的定义。有几个头文件是专门用千模块的,因此必须出现在每个可装载的模块中。故而,所有的模块代码中都包含下面两行代码:
#include - module.h
含有可装载模块需要的大昼符号和函数的定义。 - init.h
指定初始化和清除函数 - 大部分模块还包括modu/eparam.h头文件
在装载模 块时向模块传递参数
初始化和关闭
桢块的初始化函数负责注册模块所提供的任何设施。这里的设施指的是一个可以被应用程序访问的新功能,它可能是一个完整的驱动程序或者仅仅是一个新的软件抽象。初始化由数的实际定义通常如下所示:
static int __init initialization_function(void)
{
/*这里是初始化代码*/
}
module_init(initialization_function);
初始化函数应该被声明为static,因为这种函数在特定文件之外没有其他意义。因为 --个模块函数如果要对内核其他部分可见,则必须被显式导出,因此这井不是什么强制性规则。上述定义中的__init标记看起来似乎有点陌生,它对内核来讲是一种暗示, 表明该函数仅在初始化期间使用。在模块被装载之后,模块装载器就会杅初始化函数扔棹、这样可将该函数占用的内存释放出来,以作他用。__init和__initdata的使 用是可选的,虽然有点繁琐,但是很值得使用。注意,不要在结束初始化之后仍要使用的函数(或者数据结构)上使用这两个标记。在内核源代码中可能还会遇到__devinit 和__devinitdata,只有在内核未被配置为支持热插拔设备的情况下,这两个标记才会被翻译为__init和__initdata。
module_init的使用是强制性的。这个宏会在模块的目标代码中增加一个特殊的段,用于说明内核初始化函数所在的位置,没有这个定义,初始化函数永远不会被调用。
清除函数
每个重要的模块都需要一个消除函数,该函数在模块被移除前注销接口并向系统中返回所有资源。该函数定义如下:
static void __exit cleanup_function(void)
{
/*这里是清除代码*/
}
module_exit(cleanup_function);
清除函数没有返回值,因此被声明为void。
__exit修饰词标记该代码仅用于模块卸载(编译器将把该函数放在特殊的ELF段中)。如果模块被直接内嵌到内核中,或者内核的配置不允许卸载模块,则被标记为__exit的函数将被简单地丢弃。出于以上原 因,被标记为__exit的函数只能在模块被卸载或者系统关闭时被调用,其他的任何用法都是错误的。和前面类似,module_exit声明对千帮助内核找到模块的清除函数是必需的。
如果一个模块未定义清除函数,则内核不允许卸载该模块。
初始化过程中的错误处理
当我们在内核中注册设施时,要时刻铭记注册可能会失败。因此模块代码必须始终检查返回值。
如果在注册设施时遇到任何错误,首先要判断模块是否可以继续初始化。通常,在某个注册失败后可以通过降低功能来继续运转。因此,只要可能,模块应该继续向前井尽可 能提供其功能。
如果在发生了某个特定类型的错误之后无法继续装载模块,则要将出错之前的任何注册 工作撤销掉。
错误恢复的处理有时使用goto语句比较有效。 通常情况下我们很少使用goto, 但在处理错误时(可能是唯一的情况)它却非常有用。 错误情况下的goto的仔细使用可避免大最复杂的、 高度缩进的 “结构化” 逻辑。 因此 , 内核经常使用goto来处理错误。
不管初始化过程在什么时刻失败,下面的例子(使用了虚构的注册和撤销注册函数)都能正确工作:
int __init my_init_function(void)
{
int err;
/* 使用指针和名称注册 */
err = register_this(ptrl, "skull") ;
if (err) goto fail_this;
err = register_that(ptr2, "skull");
if (err) goto fail_that;
err = register_those(ptr3, "skull");
if (err) goto fail_those;
return 0; /* 成功 */
fail_those: unregister_that(ptr2, "skull");
fail_that: unregister_this(ptr2, "skull");
fail_this: return err; /* 返回错误 */
}
my_init_module的返回值err是一个错误编码。 在Linux内核中, 错误编码是定义在
模块的清除函数需要撤销初始化函数所注册的所有设施,并且习惯上(但不是必须的)以相反千注册的顺序撤销设施:
void __exit my_cleanup_function (void)
{
unregister_those(ptr3, "skull");
unregister_that(ptr2, "skull") ;
unregister_this(ptrl, "skull"};
return;
}
模块参数
我们添加了两个参数:一个是整数值,其名称为 howmany;另一个是字符串,名称为whom。在装载这个增强的模块时,将向whom问候 howmany次。这样,我们可用下面的命令行来装载该模块:
insmod hellop howmany=lO whom="Mom"
上面这条命令的效果会让hel/op打印10次"hello.Mom"。
当然可在insmod改变模块参数之前,模块必须让这些参数对insmod命令可见。参数必 须使用module_param宏来声明,这个宏在moduleparam.h中定义.module_param需要三个参数.变扯的名称、类型以及用于sysfs人口项的访问许可掩码。这个宏必须放 在任何函数之外,通常是在源文件的头部。这样,hellop通过下面的代码来声明它的参数并使之对insmod可见;
static char *whom ="world";
static int howmany = l;
module_param(howmany, int, S_IRUGO);
module_param(whom, charp, S_IRUGO);
内核支持的模块参数类型如下:
- bool
- invbool
布尔值(取,true或false),关联的变量应该是int型。invbool类型反转其值, 也就是说,true值变成false,而false变成true。 - charp
字符指针值。内核会为用户提供的字符串分配内存,井相应设置指针。 - int
- long
- short
- uint
- ulong
- ushort
具有不同长度的基本整数值。以u开头的类型用千无符号值。
模块装载器也支持数组参数,在提供数组值时用逗号划分各数组成员。要声明数组参数, 需要使用下面的宏:
module__pararm_array(narne, type, num, perm);
其中,name是数组的名称(也就是参数的名称),type是数组元素的类型.num是一 个整数变量,而perm是常见的访问许可值。如果在装载时设置数组参数,则num会被设置为用户提供的值的个数。模块装载器会拒绝接受超过数组大小的值。
如果我们需要的类型不在上面所列出的清单中,模块代码中的钩子可让我们来定义这些 类型。具体的细节请参阅moduleparam.h文件。所有的模块参数都应该给定一个默认值;insmod只会在用户明确设置了参数的值的情况下才会改变参数的值,模块可以根据默认值来判断是否是一个显式指定的参数。
module_param中的最后一个成员是访问许可值,我们应使用