美团前端面试(一面)面试题总结
1、介绍二叉树的深度遍历和广度遍历;
假设页面上的dom结构如下:
-
![]()
-
-
让我们来把这个dom结构转化成树的样子:
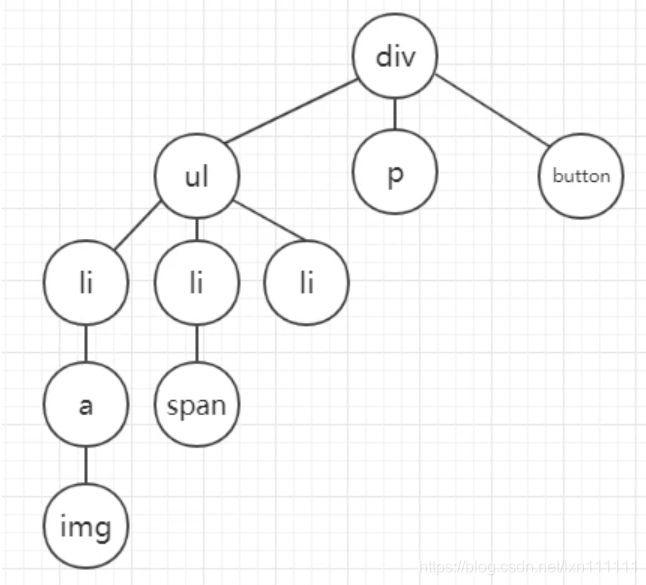
深度遍历:
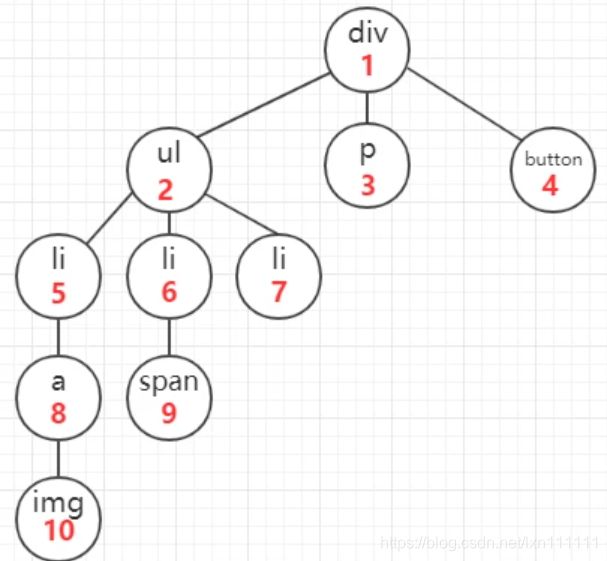
该方法是以纵向的维度对dom树进行遍历,从一个dom节点开始,一直遍历其子节点,直到它的所有子节点都被遍历完毕之后在遍历它的兄弟节点。即如图所示(遍历顺序为红字锁标):

js实现该算法代码(递归版本):
function deepFirstSearch(node,nodeList) {
if (node) {
nodeList.push(node);
var children = node.children;
for (var i = 0; i < children.length; i++)
//每次递归的时候将 需要遍历的节点 和 节点所存储的数组传下去
deepFirstSearch(children[i],nodeList);
}
return nodeList;
} deepFirstSearch接受两个参数,第一个参数是需要遍历的节点,第二个是节点所存储的数组,并且返回遍历完之后的数组,该数组的元素顺序就是遍历顺序,调用方法:
let root = document.getElementById('root')
deepFirstSearch(root,nodeList=[])控制台输出结果:

广度遍历:
该方法是以横向的维度对dom树进行遍历,从该节点的第一个子节点开始,遍历其所有的兄弟节点,再遍历第一个节点的子节点,完成该遍历之后,暂时不深入,开始遍历其兄弟节点的子节点。即如图所示(遍历顺序为红字锁标):
由于递归版本会导致栈溢出,所以我们这里只写非递归版本:
function breadthFirstSearch(node) {
var nodes = [];
if (node != null) {
var queue = [];
queue.unshift(node);
while (queue.length != 0) {
var item = queue.shift();
nodes.push(item);
var children = item.children;
for (var i = 0; i < children.length; i++)
queue.push(children[i]);
}
}
return nodes;
}
控制台输出结果:

2、队列、链表、数组的存储方式;
链表:
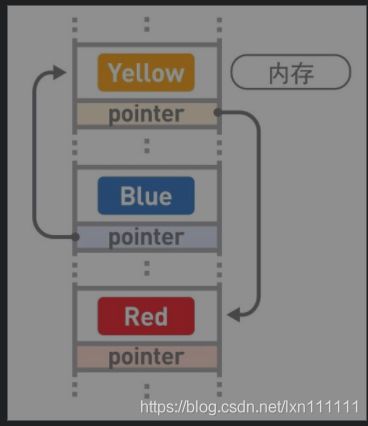
在链表中,数据一般都是分散存储于内存中的,无须存储在连续空间内。

因为数据都是分散存储的,所以如果想要访问数据,只能从第1个数据开始,顺着指针的指向一一往下访问(这便是顺序访问)。比如,想要找到Red这一数据,就得从Blue开始访问。数据的添加和删除都是通过改变指针指向来实现的。
数组:

数据按顺序存储在内存的连续空间内。

由于数据是存储在连续空间内的,所以每个数据的内存地址(在内存上的位置)都可以通过数组下标算出,我们也就可以借此直接访问目标数据(这叫作“随机访问”)。如果想在任意位置上添加或者删除数据,数组的操作就要比链表复杂多了。这里我们尝试将Green添加到第2个位置上。首先,在数组的末尾确保需要增加的存储空间。 为了给新数据腾出位置,要把已有数据一个个移开。首先把Red往后移,然后把Yellow往后移,最后在空出来的位置上写入Green。
在链表和数组中,数据都是线性地排成一列。在链表中访问数据较为复杂,添加和删除数据较为简单;而在数组中访问数据比较简单,添加和删除数据却比较复杂。

队列:

就和“队列”这个名字一样,把它想象成排成一队的人更容易理解。在队列中,处理总是从第一名开始往后进行,而新来的人只能排在队尾。
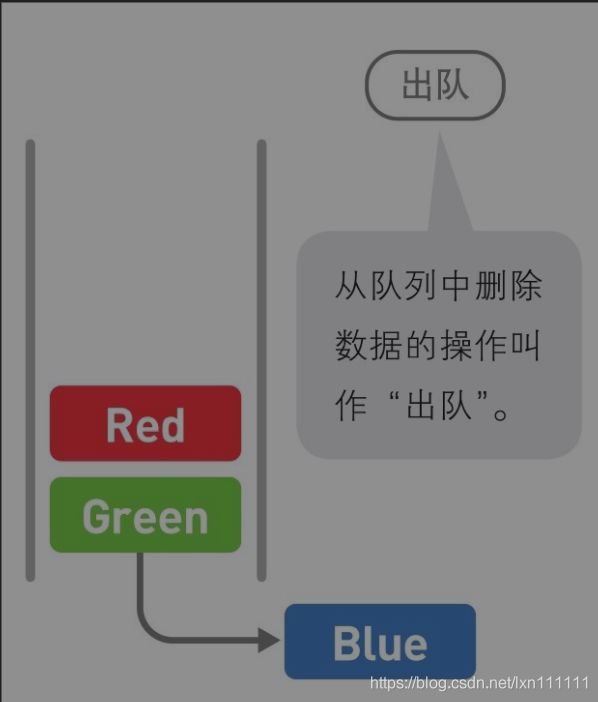
从队列中取出(删除)数据时,是从最下面,也就是最早入队的数据开始的。这里取出的是Blue。如果再进行一次出队操作,取出的就是Green了。 “先来的数据先处理”是一种很常见的思路,所以队列的应用范围非常广泛。
3、手写深拷贝

4、闭包的优缺点以及如何解决缺点;
优点:一个是可以读取函数内部的变量,避免全局变量的污染;另一个就是让这些变量的值始终保持在内存中。
缺点:
1)由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除。
2)闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
5、Object.keys( )与 for in 区别
for in 一般用于对象的遍历:
let obj = {
a:1,
b:2,
}
for(let key in obj){
console.log(key)
}
// a
// bObject.keys() 方法会返回一个由一个给定对象的自身可枚举属性组成的数组,数组中属性名的排列顺序和使用 for...in 循环遍历该对象时返回的顺序一致 。
let obj = {
a:1,
b:2,
}
console.log(Object.keys(obj))
// ["a", "b"]两者之间最主要的区别就是Object.keys( )不会走原型链,而for in 会走原型链;
Object.prototype.test = ‘test';
var obj= {
a:1,
b:2,
}
//Object.keys不会输出原型链中的数据;
console.log(Object.keys(obj))
// ["a", "b"]
for(var key in obj){
console.log(key)
}
// a
// b
// test //for in 会把原型链中test 输出除了上面的问题,还问了基本数据类型,引用数据类型的存储方式和区别,垂直居中布局,vue中为什么需要key,以及diff算法。