WSGI Server
1 WSGI
WSGI是 Web Server Gateway Interface 的缩写,它是 Python应用程序(application)或框架(如 Django)和 Web服务器之间的一种接口,已经被广泛接受。
它是一种协议,一种规范,其是在 PEP 333提出的,并在 PEP 3333 进行补充(主要是为了支持 Python3.x)。这个协议旨在解决众多 web 框架和web server软件的兼容问题。有了WSGI,你不用再因为你使用的web 框架而去选择特定的 web server软件。WSGI规定了服务器怎么把请求信息告诉给应用,应用怎么把执行情况回传给服务器,这样的话,服务器与应用都按一个标准办事,只要实现了这个标准,服务器与应用随意搭配就可以,灵活度大大提高。
相对正式的WSGI定义:
WSGI 接口有服务端和应用端两部分,服务端也可以叫网关端,应用端也叫框架端。服务端调用一个由应用端提供的可调用对象。如何提供这个对象,由服务端决定。例如某些服务器或者网关需要应用的部署者写一段脚本,以创建服务器或者网关的实例,并且为这个实例提供一个应用实例。另一些服务器或者网关则可能使用配置文件或其他方法以指定应用实例应该从哪里导入或获取。
WSGI 规范了些什么,下图能很直观的说明:

上图也可以看出一个HTTP请求的过程可以分为两个阶段,第一阶段是从客户端到WSGI Server,第二阶段是从WSGI Server 到WSGI Application。
常见的web应用框架有:Django,Flask,sanic等;
常用的web服务器软件有:uWSGI,Gunicorn,Gevent等。
web server要履行的任务:
- 接收HTTP请求;
- 解析HTTP请求;
- 准备 environ请求参数;
- 定义 start_response 函数;
- 组装响应头和相应体返回给客户端。
web application要履行的责任:
- 解析服务器发来的请求信息;
- 根据请求信息,进行业务处理;
- 返回所需要的数据。
WSGI 对于 application 对象有如下三点要求
- 必须是一个可调用的对象;
- 接收两个必选参数environ、start_response;
- 返回值必须是可迭代对象,用来表示http body。
2 python web服务一般部署方式
2.1 两级结构
两级结构即 wsgi server + wsgi application,在这种结构里,uWSGI/gevent/gunicorn作为服务器,它用到了HTTP协议以及wsgi协议,flask应用作为application,实现了wsgi协议。当有客户端发来请求,uWSGI接受请求,调用flask app得到相应,之后相应给客户端。
这里说一点,通常来说,Flask等web框架会自己附带一个wsgi服务器(这就是flask应用可以直接启动的原因),但是这只是在开发阶段用到的,在生产环境是不够用的,所以用到了uwsgi/gevent/gunicorn这些性能高的wsgi服务器。
2.2 三级结构
三级结构即nginx+wsgi server+wsgi application,这种结构里,wsgi server作为中间件,它用到了uwsgi协议(与nginx通信),wsgi协议(调用Flask app)。
当有客户端发来请求,nginx先做处理,判断是否访问的是静态资源,如果是静态资源,读取静态文件,返回静态文件给client;如果是访问的是动态资源,交给uwsgi服务器,wsgi server根据自身uwsgi和WSGI协议,找到对应的web application中的应用程序做逻辑处理,将返回值发送到wsgi server,然后wsgi server再返回给nginx,最后nginx将返回值返回给client进行渲染展示给用户。
多了一层反向代理有什么好处?
提高web server性能(wsgi server处理静态资源能力不如nginx;nginx会在收到一个完整的http请求后再转发给wsgi server);
nginx可以做负载均衡(前提是有多个服务器),保护了实际的web服务器(客户端是和nginx交互而不是wsgi server)。
2 WSGI Server
2.1 Gunicorn
官方地址
官方文档
Gunicorn“Green Unicorn”是一个用于UNIX的Python WSGI HTTP服务器。Gunicorn服务器与各种web框架广泛兼容,实现简单,服务器资源少,速度相当快。
2.1.1 安装
要求python版本号 ≥ \geq ≥ 3.5;
$ pip install gunicorn
如果需要以异步worker使用Gunicorn,还需要安装greenlet、eventlet和gevent。
$ pip install greenlet # Required for both
$ pip install eventlet # For eventlet workers
$ pip install gunicorn[eventlet] # Or, using extra
$ pip install gevent # For gevent workers
$ pip install gunicorn[gevent] # Or, using extra
gunicorn[eventlet] - Eventlet-based greenlets workers
gunicorn[gevent] - Gevent-based greenlets workers
gunicorn[gthread] - Threaded workers
gunicorn[tornado] - Tornado-based workers, not recommended
gunicorn[setproctitle] - Enables setting the process name,如果运行了多个Gunicorn实例,可以通过setproctitle给每个实例命名。
也可以通过pip install gunicorn[gevent,setproctitle]方式,同时安装多个包。
2.1.2 运行Gunicorn
Gunicorn可以通过命令行单独使用,也可以和web application框架联合使用。
安装Gunicorn之后,就可以在命令行中使用gunicorn命令了,基本用法是:
$ gunicorn [OPTIONS] [WSGI_APP]
[WSGI_APP]:
格式为$(MODULE_NAME):$(VARIABLE_NAME),MODULE_NAME是模块名,VARIABLE_NAME是模块中WSGI可调用对象。例如,定义test.py中的代码:
def app(environ, start_response):
"""Simplest possible application object"""
data = b'Hello, World!\n'
status = '200 OK'
response_headers = [
('Content-type', 'text/plain'),
('Content-Length', str(len(data)))
]
start_response(status, response_headers)
return iter([data])
可以在命令行中使用gunicorn --workers=2 test:app运行该服务。
VARIABLE_NAME也可以是一个普通函数,但函数的返回值一定要是一个application,那么就需要按照下述方式进行调用:
def create_app():
app = FrameworkApp()
...
return app
调用:
#注意必须加括号
$ gunicorn --workers=2 'test:create_app()'
可以给函数传递位置和关键字参数,但是建议通过环境变量指定配置文件来传递参数。
[OPTIONS]:
-c CONFIG,--config=CONFIG,指定配置文件,格式可以是$(PATH)、file:$(PATH)或python:$(MODULE_NAME),默认是从Gunicorn启动位置读取gunicorn.conf.py;-b BIND, --bind=BIND,指定绑定的socket,可以是$(HOST)、$(HOST):$(PORT)、fd://$(FD)或unix:$(PATH),IP符合$(HOST)格式;-w WORKERS, --workers=WORKERS,指定worker进程的数量,一般每个cpu核对应2 - 4个worker进程;-k WORKERCLASS, --worker-class=WORKERCLASS,指定worker进程的类型,可以是sync、eventlet、gevent、tornado和gthread,默认是sync;-n APP_NAME, --name=APP_NAME,如果安装了setproctitle,可以设置在进程表中显示的Gunicorn 进程的名称。
这里记录一个bug:RuntimeError: Working outside of request context. with gunicorn
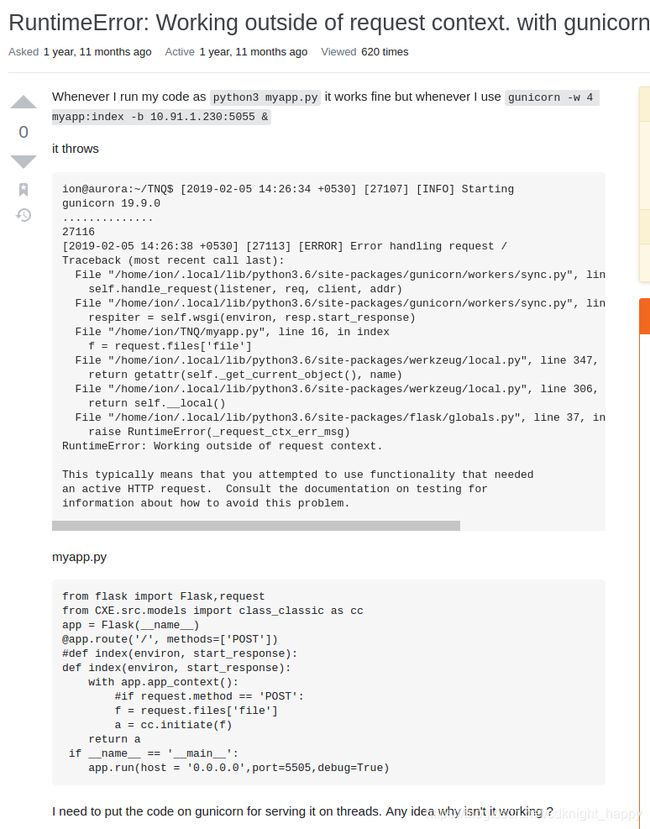 解决办法:
解决办法:

格式为$(MODULE_NAME):$(VARIABLE_NAME),MODULE_NAME是模块名,VARIABLE_NAME是模块中WSGI可调用对象,app(environ, start_response)是可调用对象,app是wsgi可调用对象,但index函数不是。
2.2.3 设计原理
2.2.3.1 server module
Gunicorn基于pre-fork worker module进行实现,这表示通过一个master进程管理一组worker进程。master进程无需了解客户端的任何信息,所有的请求和响应都是由worker进程处理的。
2.2.3.2 master
master进程接收不同的进程信号并予以响应来管理各worker进程,接收的信号包括TTIN、TTOU和CHLD。TTIN表示需要增加worker进程的数量,TTOU表示需要减少worker进程的数量,CHLD表示有一个child进程异常终止了,master进程需要自动重启该child进程。
2.2.3.3 sync worker
默认的worker类型是同步worker,一次只处理一个请求。这个模型是最容易解释的,因为任何错误最多只会影响一个请求。尽管正如我们在下面所描述的,一次只处理一个请求需要一些关于应用程序编程方式的假设。
sync worker不支持持续连接,即便在应用的头信息中添加了Keep-Alive,返回了响应信息一个连接就被关闭了。
2.2.3.4 Async worker
可用的异步worker基于greenlet(通过Eventlet和Gevent)。greenlet是Python协程库。一般来说,应用程序可以在不做任何更改的情况下使用这些worker类。
常用的Async worker是gevent;
2.2.3.5 tornado
tornado worker可以用来编写使用Tornado框架的应用程序。尽管Tornado workers能够为WSGI应用程序提供服务,但并不推荐。
2.2.3.6 AsyncIO worker
gthread worker是线程辅助worker。它接受主循环中的连接,接受的连接作为连接作业添加到线程池中。以keep alive模式工作时,连接被放回循环中等待event。如果直到keep alive超时都没有等到任何event触发,则关闭该连接。
还可以使用aiohttp的web.Application API和使用aiohttp.worker.GunicornWebWorker worker。
2.2.3.7 选择合适的worker类型
默认的同步worker假设应用程序在CPU和网络带宽方面是资源受限的。一般来说,这意味着您的应用程序不应该执行任何需要未定义时间的操作。对互联网的请求就是一个需要花费大量时间的例子。在某个时刻,外部网络可能会出现故障,请求将堆积在您的服务器上。因此,从这个意义上说,任何向api发出请求的web应用程序都将受益于异步worker。
这种资源受限的假设就是为什么我们需要在默认配置Gunicorn前面使用缓冲代理的原因。如果将同步worker暴露在internet上,那么DOS攻击只会创建一个向服务器传输数据的负载。
需要异步worker的例子:
- 需要长期阻塞的应用;
- 直接请求互联网;
- 流式请求和响应;
- 长轮询;
- web sockets;
- Comet。
2.2.3.8 worker数量
不要根据请求的数量设置worker的数量,对于每秒数百/千的请求量,Gunicorn只需要4 - 12个worker进程。Gunicorn处理请求时,依赖操作系统进行负载均衡,一般建议启动时建议使用(2 x $num_cores) + 1个worker,虽然不太科学,但这个公式是基于这样的假设:对于给定的内核,一个worker进程将从套接字读写,而另一个worker进程正在处理请求。显然,不同的硬件和应用程序将会对应不同的最佳worker数量。我们的建议是在应用程序加载时使用TTIN和TTOU信号从上述猜测开始进行自适应调整。
永远记住,worker太多是一个麻烦。某个点之后,worker进程将开始猛击系统资源,从而降低整个系统的吞吐量。
2.2.3.9 线程数量
自Gunicorn 19开始,threads选项可用于处理多个线程中的请求。使用线程假定使用gthread worker。线程的一个好处是,在通知主进程某个请求未冻结且不应终止时,请求的处理时间可能长于worker的超时时间。根据系统的不同,使用多个线程、多个worker进程或混合使用可能会产生最佳结果。例如,当使用线程时,CPython的性能可能不如Jython,因为每个线程的实现方式不同。使用线程而不是进程是减少Gunicorn内存占用的一个好方法,同时仍然允许使用重新加载信号进行应用程序升级,因为应用程序代码将在工作进程之间共享,但只在工作进程中加载(与使用预加载设置时不同,预加载设置在主进程中加载代码)。
2.2.4 可配置项
完整配置官方文档
配置文件:
-
config:
命令行:-c CONFIGor--config CONFIG;
默认:'./gunicorn.conf.py';
格式:PATH,file:PATH, orpython:MODULE_NAME;
含义:设置配置文件;
注意点:从Gunicorn 19.4开始,从python module加载配置项需要python:前缀。 -
wsgi_app
WSGI应用路径,格式为$(MODULE_NAME):$(VARIABLE_NAME);
调试:
- reload
设置为True则在代码改变后重启worker,默认为False; - reload_engine
和reload搭配使用; - spew
按照一个调试函数,输出服务器执行的每一行,默认False;
日志:
-
accesslog
访问的日志文件; -
access_log_format
日志格式,默认'%(h)s %(l)s %(u)s %(t)s "%(r)s" %(s)s %(b)s "%(f)s" "%(a)s"',具体含义参考官方文档; -
errorlog
记录错误信息的日志文件; -
loglevel
日志级别,可用的有debug、info、warning、error和critical;
进程名:
- proc_name
进程名,默认是gunicorn;
SSL:
Security:
-
limit_request_line
HTTP请求的最大尺寸,单位是bytes,默认4094。此参数用于限制客户端HTTP请求行的允许大小。由于请求行由HTTP方法、URI和协议版本组成,因此该指令对服务器上请求所允许的请求URI的长度进行了限制。服务器需要此值足够大,以容纳其任何资源名称,包括GET请求的查询部分中可能传递的任何信息。值是从0(无限制)到8190的数字。 这个参数可用来抵御DDOS攻击。
-
limit_request_fields
限制请求中HTTP中header的数量,默认100。此参数用于限制请求中的header的数量,以防止DDOS攻击。与limit_request_line一起使用,可以提供更大的安全性。默认情况下,此值为100,不能大于32768。
-
limit_request_field_size
限制HTTP请求头字段的允许大小。
值是正数或0。将其设置为0将允许不受限制的头字段大小,默认8190。
Server Socket:
-
bind
设置绑定的socket,默认是127.0.0.1:8000,如果设置了PORT变量,默认是0.0.0.0:8000;
可以绑定多个地址,如:$ gunicorn -b 127.0.0.1:8000 -b [::1]:8000 test:app -
backlog
挂起的最大连接数,默认是2048;这是指可以等待服务响应的请求的数量。超过此数字将导致客户端在尝试连接时出错。只影响负载较大的服务器。必须是正整数。一般设置在64-2048范围内。
Worker Processes:
-
workers
处理请求的worker进程的数量,默认是1;通常设置为
(2 - 4) *$(NUM_CORES)的范围,需要根据自己的实际情况进行调整; -
worker_class
worker类别,使用命令行时的参数为-k,默认sync;
参考2.2.3.7节选择合适的worker类型; -
threads
使用gthread模式时,设置各worker的线程数,默认是1;
通常设置为(2 - 4) *$(NUM_CORES)的范围,需要根据自己的实际情况进行调整;
注意,如果使用的是sync模式且设置threads值大于1,那么会自动切换到gthread模式。 -
worker_connections
同时存在的客户端的最大数目,只影响eventlet和geventworker类型; -
max_requests
一个worker重启前能够处理的最多请求数量;默认为0,表示关闭自动重启,该方法用来限制内存溢出。 -
max_requests_jitter
在max_requests基础上添加的最大抖动量,即添加了一个随机抖动值,取值范围在randint(0, max_requests_jitter),目的是避免所有的worker同时重启。 -
timeout
超过该设置时间没有响应的worker会被重启,默认时间是30,单位是秒; -
graceful_timeout
重启超时时间,默认是30,单位是秒;在接收到重启信号后,worker有这么多时间来完成服务请求。超时后仍活着的worker(从收到重启信号开始)被强制杀死。
-
keepalive
在一个Keep-Alive连接中,灯带响应的秒数。默认是2;
对于直接连接到客户端的服务器(例如,当您没有单独的负载平衡器时),通常设置在1-5秒的范围内。当Gunicorn部署在负载平衡器后面时,将其设置为更高的值通常是有意义的。
syncworker不支持持久连接,会忽略掉该参数。
2.2.5 部署Gunicorn
本节原始地址
强烈建议在代理服务器之后使用Gunicorn;
Nginx配置:
虽然有多个HTTP代理服务器,但这里还是强烈建议使用Nginx。如果您选择其他的代理服务器,则需要确保在使用默认Gunicorn workers时,它会缓冲慢速客户端。没有这个缓冲区,Gunicorn很容易受到拒绝服务攻击。您可以使用Hey检查代理是否正常工作。
Nginx的示例配置如下面所示:
worker_processes 1;
user nobody nogroup;
# 'user nobody nobody;' for systems with 'nobody' as a group instead
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024; # increase if you have lots of clients
accept_mutex off; # set to 'on' if nginx worker_processes > 1
# 'use epoll;' to enable for Linux 2.6+
# 'use kqueue;' to enable for FreeBSD, OSX
}
http {
include mime.types;
# fallback in case we can't determine a type
default_type application/octet-stream;
access_log /var/log/nginx/access.log combined;
sendfile on;
upstream app_server {
# fail_timeout=0 means we always retry an upstream even if it failed
# to return a good HTTP response
# for UNIX domain socket setups
server unix:/tmp/gunicorn.sock fail_timeout=0;
# for a TCP configuration
# server 192.168.0.7:8000 fail_timeout=0;
}
server {
# if no Host match, close the connection to prevent host spoofing
listen 80 default_server;
return 444;
}
server {
# use 'listen 80 deferred;' for Linux
# use 'listen 80 accept_filter=httpready;' for FreeBSD
listen 80;
client_max_body_size 4G;
# set the correct host(s) for your site
server_name example.com www.example.com;
keepalive_timeout 5;
# path for static files
root /path/to/app/current/public;
location / {
# checks for static file, if not found proxy to app
try_files $uri @proxy_to_app;
}
location @proxy_to_app {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Host $http_host;
# we don't want nginx trying to do something clever with
# redirects, we set the Host: header above already.
proxy_redirect off;
proxy_pass http://app_server;
}
error_page 500 502 503 504 /500.html;
location = /500.html {
root /path/to/app/current/public;
}
}
}
如果您希望能够处理流式请求/响应或其他奇特的功能(如Comet、长轮询或websockets),则需要关闭代理缓冲。执行此操作时,必须使用一个异步worker类运行。
要关闭缓冲区,只需要在location中添加proxy_buffering off;即可,如下所示:
...
location @proxy_to_app {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_buffering off;
proxy_pass http://app_server;
}
...
建议将协议信息传递给Gunicorn。许多web框架使用这些信息来生成url。如果没有这些信息,应用程序可能会在“https”响应中错误地生成“http”url,从而导致混合内容警告或应用程序损坏。要将Nginx配置为传递适当的header,需要在location中添加proxy_set_header设置项:
...
proxy_set_header X-Forwarded-Proto $scheme;
...
如果Nginx和Gunicorn运行在不同的机器上,那么就需要告诉Gunicorn信任由Nginx发送来的X-Forwarded-*头信息。默认情况下,为了防止恶意欺骗,Gunicorn只信任来自于本机的连接。如下面所示,设置多个信任IP:
$ gunicorn -w 3 --forwarded-allow-ips="10.170.3.217,10.170.3.220" test:app
当Gunicorn主机与外部网络完全防火墙连接,使得所有连接都来自受信任的代理(例如Heroku)时,此值可以设置为’*’。如果到Gunicorn的连接可能来自不受信任的代理或直接来自客户端,则使用此值可能是危险的,因为应用程序可能会被欺骗,通过不安全的连接提供仅限SSL的内容。
Gunicorn 19引入了一个关于如何处理远程地址的突破性变化。在Gunicorn 19之前,它被设置为X-Forwarded-For的值(如果从受信任的代理接收)。但是,这不符合RFC3875,这就是为什么远程地址现在是代理的IP地址而不是实际用户。
要使访问日志指示代理时的实际用户IP,请将访问日志格式设置为包含X-Forwarded-For的格式。例如,此格式使用X-Forwarded-For代替远程地址:
%({x-forwarded-for}i)s %(l)s %(u)s %(t)s "%(r)s" %(s)s %(b)s "%(f)s" "%(a)s"
如果将Gunicorn绑定到一个UNIX Socket而不是一个TCP的host:port元组,那么REMOTE_ADDR将为空。
服务监视器:
请注意:如果使用了下面所列的服务监视器,请不要将Gunicorn设置为守护进程模式。这些服务监视器希望自己所监视的进程需要被监视(如果监视的是守护进程,进程从系统启动就开启,直到系统停止才停止,监视这样的进程没有意义)。
如果需要将不同的进程的代码对应到不同的显卡,需要使用server hook配合本地日志文件进行实现,在配置文件中可以采用:
import pickle
base_path = './datasets/logs/Gunicorn.logs'
def on_starting(server):
DeviceFile = base_path+os.sep+'DeviceAllocate.log'
DeviceAllocate = {}
ProcessAllocate = {}
if not os.path.exists(DeviceFile):
nDevice = 8#pynvml.nvmlDeviceGetCount()
for index in range(nDevice):
DeviceAllocate[str(index)] = 0
file = open(DeviceFile,'wb')
pickle.dump([DeviceAllocate,ProcessAllocate],file)
file.close()
print("启动master进程")
else:
os.remove(DeviceFile)
def post_fork(server,worker):
import pynvml,fcntl
from fcntl import LOCK_EX,LOCK_UN
pynvml.nvmlInit()
DeviceFile = base_path+os.sep+'DeviceAllocate.log'
file = open(DeviceFile,'rb')
# fcntl.flock(file.fileno( ),LOCK_EX)
info = pickle.load(file)
DeviceAllocate = info[0]
ProcessAllocate = info[1]
key = min(DeviceAllocate,key=lambda x: DeviceAllocate[x])
os.environ["CUDA_VISIBLE_DEVICES"]=key
DeviceAllocate[key] += 1
ProcessAllocate[worker.pid] = key
# print('新建进程:%s ,对应显卡 %s' %(worker.pid,key))
# print([DeviceAllocate,ProcessAllocate])
file = open(DeviceFile,'wb')
pickle.dump([DeviceAllocate,ProcessAllocate],file)
# fcntl.flock(file.fileno( ),LOCK_UN)
file.close()
def child_exit(server,worker):
import fcntl
from fcntl import LOCK_EX,LOCK_UN
DeviceFile = base_path+os.sep+'DeviceAllocate.log'
file = open(DeviceFile,'rb')
# print('acquire lock')
# fcntl.flock(file.fileno( ),LOCK_EX)
info = pickle.load(file)
DeviceAllocate = info[0]
ProcessAllocate = info[1]
file.close()
# print([DeviceAllocate,ProcessAllocate])
device = ProcessAllocate[worker.pid]
DeviceAllocate[device] -= 1
del ProcessAllocate[worker.pid]
# print('退出对应于显卡%s的进程:%s' %(device,worker.pid))
file = open(DeviceFile,'wb')
pickle.dump([DeviceAllocate,ProcessAllocate],file)
# fcntl.flock(file.fileno( ),LOCK_UN)
# print('release lock')
file.close()
def on_exit(server):
if os.path.exists(base_path+os.sep+'DeviceAllocate.log'):
os.remove(base_path+os.sep+'DeviceAllocate.log')
print('关闭所有进程')
Gaffer:
官方地址
示例:
[process:gunicorn]
cmd = gunicorn -w 3 test:app
cwd = /path/to/project
Runit:
官方地址
示例:
#!/bin/sh
GUNICORN=/usr/local/bin/gunicorn
ROOT=/path/to/project
PID=/var/run/gunicorn.pid
APP=main:application
if [ -f $PID ]; then rm $PID; fi
cd $ROOT
exec $GUNICORN -c $ROOT/gunicorn.conf.py --pid=$PID $APP
Supervisor:
官方地址
示例:
[program:gunicorn]
command=/path/to/gunicorn main:application -c /path/to/gunicorn.conf.py
directory=/path/to/project
user=nobody
autostart=true
autorestart=true
redirect_stderr=true
Upstart:
参考博客
配置“myapp”应用示例:
/etc/init/myapp.conf:
description "myapp"
start on (filesystem)
stop on runlevel [016]
respawn
setuid nobody
setgid nogroup
chdir /path/to/app/directory
exec /path/to/virtualenv/bin/gunicorn myapp:app
Systemd:
官方地址
在linux系统上开始流行的一个工具是Systemd。它是一个系统服务管理器,允许严格的进程管理、资源和权限控制。
下面是使用systemd为传入的Gunicorn请求创建unix套接字的配置文件和说明。Systemd将监听这个套接字并自动启动gunicorn以响应通信量。本节后面将介绍如何配置Nginx以将web流量转发到新创建的unix套接字:
/etc/systemd/system/gunicorn.service:
[Unit]
Description=gunicorn daemon
Requires=gunicorn.socket
After=network.target
[Service]
Type=notify
# the specific user that our service will run as
User=someuser
Group=someuser
# another option for an even more restricted service is
# DynamicUser=yes
# see http://0pointer.net/blog/dynamic-users-with-systemd.html
RuntimeDirectory=gunicorn
WorkingDirectory=/home/someuser/applicationroot
ExecStart=/usr/bin/gunicorn applicationname.wsgi
ExecReload=/bin/kill -s HUP $MAINPID
KillMode=mixed
TimeoutStopSec=5
PrivateTmp=true
[Install]
WantedBy=multi-user.target
/etc/systemd/system/gunicorn.socket:
[Unit]
Description=gunicorn socket
[Socket]
ListenStream=/run/gunicorn.sock
# Our service won't need permissions for the socket, since it
# inherits the file descriptor by socket activation
# only the nginx daemon will need access to the socket
SocketUser=www-data
# Optionally restrict the socket permissions even more.
# SocketMode=600
[Install]
WantedBy=sockets.target
2.2 Gevent
官方地址
Gevent是一个基于协程的python网络库,在libev或libuv事件循环的基础上使用greenlet提供高层同步API。支持协程的并发式操作,也可以对外当成wsgi server使用。
下面的代码展示了如何以并行的方式运行多个任务:
>>> import gevent
>>> from gevent import socket
>>> urls = ['www.google.com', 'www.example.com', 'www.python.org']
>>> jobs = [gevent.spawn(socket.gethostbyname, url) for url in urls]
>>> _ = gevent.joinall(jobs, timeout=2)
>>> [job.value for job in jobs]
['74.125.79.106', '208.77.188.166', '82.94.164.162']
在设置了所有的任务之后,gevent在等待所有的任务完成,最长等待时间为2秒。通过jobs的value属性来收集返回值。gevent.socket.gethostbyname()和标准的socket.gethostbyname()接口含义一致,但能够以不阻塞解释器的方式并行运行多个任务。
Monky Patch:
上面的代码中使用gevent.socket进行套接字操作,如果使用的是标准的socket包,因为需要序列化处理DNS请求,总的处理时间会是上面并行方式的三倍。在greenlet中使用标准socket模块使gevent变得毫无意义,那么构建在socket之上的现有模块和包(包括urllib之类的标准库模块)自然也就无法并行处理了。
这就是mokey patch的作用了,gevent.monky会将标准socket中的函数和类替换为协程版本,这样,即使不知道gevent的模块也可以从多greenlet环境中获益。
例如:
>>> from gevent import monkey; monkey.patch_socket()
>>> import requests # it's usable from multiple greenlets now
当然,标准库还有其他几个部分可以阻止整个解释器并导致序列化处理行为。gevent也提供了其中许多的合作版本。它们可以通过单个函数独立地进行修补,但是大多数使用monkey修补的程序都希望使用gevent.monkey.patch()函数一次性修复全部的功能,如下代码所示:
>>> from gevent import monkey; monkey.patch_all()
>>> import subprocess # it's usable from multiple greenlets now
提示:打猴子补丁时,建议在生命周期内尽早打。如果可能的话,猴子补丁应该在第一行执行。如果猴子补丁打晚了,特别是如果本机线程已经创建,atexit或信号处理程序已经安装,或套接字已经创建,可能会导致不可预知的结果,包括意外的LoopExit错误。
事件循环:
gevent不会阻塞和等待socket操作完成(一种称为轮询的技术),而是安排操作系统传递一个事件,例如让它知道何时从socket中读取的数据已经到达。这样,gevent就可以继续运行另一个greenlet了,也许它本身已经为它准备好了一个事件。注册事件并在事件到达时对其作出反应的重复过程就是事件循环。
与其他网络库不同,尽管gevent的方式与eventlet类似,但它在一个专用的greenlet中隐式地启动事件循环,没有必要显式调用run()或dispatch()函数。当gevent的API中的函数想要阻塞时,它会获得gevent.hub.Hub实例(运行事件循环的特殊greenlet)并切换到它(据说greenlet将控制权让给了中心)。如果还没有Hub实例,则会自动创建一个。
每一个线程都有自己的Hub,这就允许多个线程使用gevent阻塞式API。
协作式多任务:
所有的greenlet都在同一个OS线程中运行,并且是协同调度的。这意味着,除非某个特定的greenlet放弃控制(通过调用将切换到Hub的阻塞函数),否则其他greenlet将没有机会运行。对于绑定I/O的应用程序来说,这通常不是问题,但是在执行CPU密集型操作时,或者在调用绕过事件循环的阻塞I/O函数时,应该注意到这一点。甚至一些表面上协作的函数,比如gevent.sleep(),在某些情况下都可以暂时优先于等待的I/O操作。
在大多数情况下,greenlet中共享的对象的访问不必要进行同步的(因为访问控制通常是显式的),因此像gevent.lock.BoundedSemaphore, gevent.lock.RLock文件以及gevent.lock.Semaphore文件类虽然存在,但并不经常使用。线程和多进程的其他抽象在协作世界中仍然有用:
- Event允许唤醒一组通过调用wait函数处于等待状态的greenlet;
- AsyncResult和Event功能想死,但是允许给等待的greenlet传递值或异常信息;
- 也提供了Queue和JoinableQueue对象。
轻量级伪线程:
通过创建一个新的greenlet对象并且调用其start函数创建一个协程。一旦已创建的greenlet对象不占用cpu之后,就可以通过新创建的greenlet的start函数启动其执行。
Greenlet对象中有用的关键函数:
- join – 等待greenlet执行完成;
- kill – 中断greenlet的执行;
- get – 获取greenlet的返回值或重新抛出关闭协程的异常。
>>> from gevent import Greenlet
>>> g = Greenlet(gevent.sleep, 4)
>>> g.start()
>>> g.kill()
>>> g.dead
True
WSGI Server:
gevent提供了两种WSGI server,分别是:
- gevent.wsgi.WSGIServer
- gevent.pywsgi.WSGIServer
使用举例:
gevent + flask
from gevent import monkey
monkey.patch_all()
from gevent import pywsgi
app = flask(__name__)
if __name__ == "__main__":
server = pywsgi.WSGIServer(('0.0.0.0',5000),app)
server.serve_forever()
gevent启动多进程WSGI:
多进程模式:
from gevent import monkey
monkey.patch_all()
from gevent.pywsgi import WSGIServer
from multiprocessing import cpu_count, Process
from bottle import Bottle
app = Bottle()
@app.get("/")
def index():
return {"hello": "world"}
server = WSGIServer(('', 8000), app, log=None)
server.start()
def serve_forever():
server.start_accepting()
server._stop_event.wait()
if __name__ == "__main__":
# server.serve_forever()
# 启动的进程数为cpu个数
for i in range(cpu_count()):
p = Process(target=serve_forever)
p.start()
单进程模式:
- 屏蔽 server.start();
- 打开 server.serve_forever();
- 屏蔽 最后三行
2.3 uWSGI
官方地址
参考文档
参考:
花了两个星期,我终于把 WSGI 整明白了
WSGI协议的作用和实现原理详解
说说我对 WSGI 的理解
什么是 web 框架?
gevent启动多进程WSGI