如何建设一个开源图形引擎的文档网站
如果你看过 Vue.js 的纪录片,就会发现一个开源产品的成功不仅仅是优质的代码,而且还需要:清晰的文档、不土的审美、持续的迭代、定期的布道、大佬的站台……今天来聊聊“文档”这件看似简单却需要精心雕琢的小事。

众所周知,写完代码和单测只是保证了功能的实现,而面向用户最重要的东西就是文档。文档在我们生活中是最司空见惯的东西,比如你买了一台吸尘器,一定会有一本说明书告诉你怎么操作,而不是跟你说:“想知道怎么操作吗?把吸尘器拆开自己看看工作原理吧!”。然而在软件领域,让用户看源码这种荒唐的事天天在发生。懂得文档重要性的程序员才是好的推销员。
言归正传,当开始运营团队里的开源图形引擎 Oasis Engine 的时候,我才发现做出一个简洁好用的文档比想象得难很多。
Oasis Engine:https://oasisengine.cn/
选型
在开源之前,我们把文档放在语雀上。语雀作为知识管理平台确实很不错,如果维护得当,积硅步可以至千里。但它也有两方面的缺点:
无法承载 API 文档、代码示例等复杂形态的需求;
无法满足个性化的设计。总而言之,一个开源产品如果连个独立的网站都没有,有点说不过去。

通过了解一些知名的开源作品的网站后,我发现他们大部分都选择把网站部署在 Github Pages 上。这很符合我们团队的想法,既然引擎都开源了,文档当然也应该开源,让全世界的开发者一起来维护。经过调研,我找到了一些能够把搭建 GIthub Pages 的静态网站框架:
- Jekyll:Github Pages 官方推荐的老牌框架,但是它依赖 Ruby,我觉得在 Mac OSX 下使用 Ruby 很麻烦,遂放弃。
- Vuepress:我的同事 ZS 开发的基于 Vue 的框架,虽然我对 Vue 很推崇并且敬佩 ZS 的实力,但是它的数据源限于 Markdown。
- Dumi:也是我厂另一位大神开发的基于 React 的框架,它为组件开发场景而生,其中的 dumi-theme-mobile 挺打动我的,但它的 Demo 预览能力和组件是耦合的,并不能满足图形引擎中非组件 Demo 的预览;另外它的默认样式有点粗糙。
- Docsify:一个非常小清晰的网站生成器(它的 logo 太可爱了),之所以没有提到 Gitbook,是因为 Docsify 不仅拥有 Gitbook 的功能,而且可以直接在运行时解析 Markdown 文件,不需要编译环节,使用起来非常简单。
开源在即,为了快速上线网站,我最终选择了 Docsify。事实证明,这是个仓促的选择。当时用了三套工程方案把三种完全不同的数据都编译成 HTML 后组合在一起:Docsify 解决了把文档编译成 HTML 的问题,Typedoc 解决了把 API 编译成 HTML 的问题,Demosify 解决了把示例编译成 HTML 的问题。
除了三个工程强扭在一起之后整个网站风格不统一之外,更要命的是我们还把 API(在引擎仓库)、教程文档、示例放在三个 Github 仓库(美其名曰“洁癖”),每次更新都需要从三个仓库拷贝内容到网站仓库,维护成本非常高。开源之后第一个里程碑迭代完,团队已经被文档折腾得筋疲力尽,完善文档的积极性也降低了。
初心
2021年四月,距离 Oasis 引擎开源已经过去两个月了,热潮消退,褒贬的声音已经淡去。期间有不少人反馈我们部署在 Github Pages 上的站点打开很慢,尤其是示例页面不根本打不开,我们没有认识到网站工程的臃肿导致了访问慢,还傻傻地以为 Github 就是慢,于是在 Gitee 上又部署了一个国内镜像来缓解这个问题。
看了行业里成功的图形/游戏引擎的网站:Unity、Unreal、Cocos、LayaAir、ThreeJS、BabylonJS,他们根据自己的定位、主打产品、发展阶段、商业策略展现出不同的信息架构和风格。而我们应该做成什么样呢?
回归初心吧,少年!Oasis 引擎想成为前端友好、高性能的移动端图形引擎,那么我们的网站必须给人简洁、可靠、极速的印象。四月快结束的时候,我猛然意识到:既然我们定位是面向前端的图形引擎,为啥不朝着前端框架的模式做呢?我重新梳理一下网站的需求:
1.一体化:把 API 文档(TypeDoc)、教程文档(Markdown)、示例(Typescript)等不同格式的数据源放到一个站点,并且支持全局内容搜索;
2.示例嵌入:支持在教程文档中嵌入功能示例,并且支持跳转到 Codepen 等流行在线开发环境中编辑;
3.多版本:不同引擎版本的文档同时存在,支持版本切换;
4.国际化:支持中英语言。
梳理完毕,我发现要做的其实是个类似 Ant Design 的站点。这里有个误解,前文中提到 Dumi 的 dumi-theme-mobile,我错误地以为 Ant Design Mobile 的网站是基于 Dumi 实现的(而且 Ant Design Mobile 的作者也推荐我用 Dumi),而 Dumi 已经是调研过后的放弃的方案,又由于 Ant Design Mobile 和 Ant Design 的网站风格相似,我仍以为 Ant Design 也是用 Dumi 做的,直到发现 Ant Design Pro 的网站源码,我才知道是基于 Gatsby 实现的。
开搞
接下去的内容虽然是这篇文章的主题,但可能比较无聊,事实上我完全可以省略上述心路历程,把文章的标题改成《如何用 Gatsby 实现一个文档网站》。然而,我想强调的是当一个人面对一个陌生的领域,势必会走弯路,当回头看的时候,这些弯路都是收获。
发现 Gatsby 的时候,我十分兴奋,以至于五一假期五天时间都在捣鼓这个工具;假期结束的时候,同事们惊讶地发现我已经把网站的功能基本写完了。那么,Gatsby 到底是个什么东西呢?它和上述选型中的其他方案有什么区别呢?
我认为最本质的区别是:Gatsby 有一个叫 GraphQL 的中间数据层。不管你的输入是什么格式,只要能转成 GraphQL 格式的数据,就能在 Gatsby 中通过查询语句获取数据,最后渲染成 React 组件。比如,Oasis 引擎的官网就希望把 TypeDoc、Markdown、Typescript 格式的文件数据转成 React 组件:
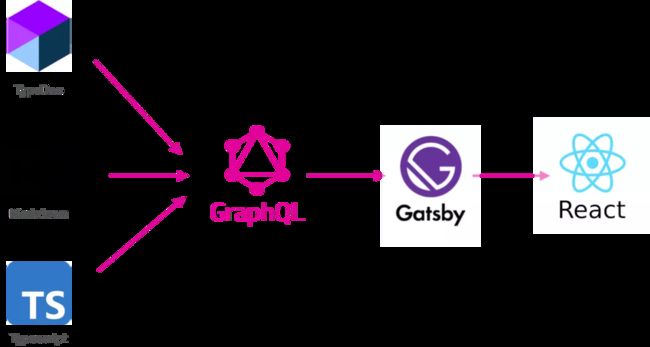
相当完美的流程!这意味着数据和样式解耦,原先各种格式都要通过不同的工具编译成 HTML,现在可以通过一个工具转成 React 组件,而 React 组件的样式可以统一管控。
处理 TypeDoc 数据
TypeScript(TS) 是近几年最流行的前端开发语言,出于代码质量和可维护性的考虑,Oasis 引擎也采用了 TypeScript 编写。TypeDoc 是社区中比较优秀的生成 TS API 文档的工具,它能够读取 Typscript 的声明数据并生成 HTML 网页,但似乎很少人知道它其实有 Node module——也就是说只用它的 Node API 读取数据,渲染交给其他工具。
至此,聪明的读者想必已经知道了:找一个 TypeDoc 转 GraphQL 的工具。幸运的是,我在 Gatsby 的社区就找到一个 gatsby-source-typedoc 插件(Gatsby 的插件生态很茂盛),顺藤摸瓜,又找了该插件作者写的文章。有趣的是,文章作者是一个叫 Excalibur.js 的游戏引擎的开发者,所谓同是引擎开发者,相逢何必曾相识,这就是猿粪啊。但是,我高兴得有点早,因为文章提供的信息非常有限。这个插件仅仅是帮你读取 TypeDoc 的数据转成 GraphQL,然后你自己 JSON.parse 数据,再然后 Please do something with that data by yourself…
export const pageQuery = graphql`
typedoc(typedocId: { eq: "default" }) {
internal {
content
}
}
`
export default function MyPage({ data: { typedoc } }) {
const typedocContent = JSON.parse(typedoc?.internal.content);
// do something with that data...
}
当时的想法是,反正 TypeDoc 的默认样式也不好看,我就重写一个渲染器吧…万万没想到,这一重写就是五一三天假期。主要原因是 TypeDoc 的数据类型挺复杂的,比如类型就有这么多(可能还没列全,终于能够理解为啥 TypeDoc 官方的渲染器每次升级都有不小的变化):
export enum Kinds {
MODULE = 1,
ENUM = 4,
CLASS = 128,
INTERFACE = 256,
TYPE_ALIAS = 4194304,
FUNCTION = 64,
PROPERTY = 1024,
CONSTRUCTOR = 512,
ACCESSOR = 262144,
METHOD = 2048,
GET_SIGNATURE = 524288,
SET_SIGNATURE = 1048576,
PARAMETER = 32768,
TYPE_PARAMETER = 131072,
}
这里说一下具体的步骤:
1.从 Oasis 引擎仓库获取数据源,就是入口级别的 index.ts 文件。由于 Oasis Engine 是一个 monorepo 仓库,要获取每个子仓库的 index.ts 的路径,最后写入到一个临时文件 tsfiles.js 里:
const glob = require('glob');
const fs = require('fs');
glob(`${EngineRepoPath}/packages/**/src/index.ts`, {realpath: true}, function(er, files) {
var re = new RegExp(/([^test]+).ts/);
var tsFiles = [];
for (let i = 0; i < files.length; i++) {
const file = files[i];
var res = re.exec(file);
console.log('[Typedoc entry file]:', file);
if (!res) continue;
tsFiles.push(`"${file}"`);
}
fs.writeFile('./scripts/typedoc/tsfiles.js', `module.exports = [${tsFiles.join(',')}];`, function(err) {});
});
2.在 gatsby-config.js 中配置插件:
const DTS = require('./scripts/typedoc/tsfiles');
module.exports = {
plugins: [
{
resolve: "gatsby-source-typedoc",
options: {
src: DTS,
typedoc: {
tsconfig: `${typedocSource}/tsconfig.json`
}
}
}
]
}
3.打开 http://localhost:8000/___graphql 如果看到左侧面板中有 typedoc 说明数据读取已经成功,勾选一下 internal> content 执行查询,可以到详细的数据:
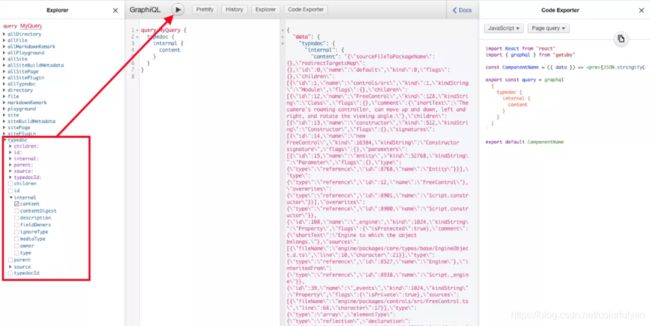
4.接下去就是使用 gatsby 创建页面,gatsby 提供了 createPages.js 入口编写创建页面的代码,以下就是插件作者在文章中省略的 do something with that data… 部分的代码:
async function createAPI(graphql, actions) {
const { createPage } = actions;
const apiTemplate = resolve(__dirname, '../src/templates/api.tsx');
const typedocquery = await graphql(
`
{
typedoc {
internal {
content
}
}
}
`,
);
let apis = JSON.parse(typedocquery.data.typedoc.internal.content);
// do something with that data...
const packages = apis.children.map((p) => {
return {
id: p.id,
kind: p.kind,
name: p.name.replace('/src', '')
};
});
if (apis) {
apis.children.forEach((node, i) => {
const name = node.name.replace('/src', '');
// 索引页
createPage({
path: `${version}/api/${name}/index`,
component: apiTemplate,
context: { node, type: 'package', packages }
});
// 详情页
if (node.children) {
node.children.forEach((child) => {
createPage({
path: `${version}/api/${name}/${child.name}`,
component: apiTemplate,
context: { node: child, type: 'module', packages, packageIndex: i }
});
})
}
});
}
}
最终的结果,可以访问 https://oasisengine.cn/0.3/api/core/index。样式是不是比 TypeDoc 默认的好看一点?可能有人会问:Typdoc 也可以直接转成 Markdown,你为什么大费周折呢?因为一个图形引擎的复杂度相当高,API 有成千上万个,如果用 Markdown 展示是非常难看的,所以 TypeDoc 的存在是有意义的。
在 Markdown 中嵌入 Demo
这是一个很朴素的需求,就是希望能在文档中嵌入 Demo, 方便开发者理解文档中描述的功能,增强文档和示例的关联性。这也是我们做面向前端的引擎必须具备的优势,市面上大部分引擎网站都是文档和示例分离的,更别说一些 Native 引擎想在网页里渲染都很难呢。比如材质文档中讲到 PBRMaterial,总得展示一下 PBR 材质的样子吧。我们是搞图形学的,又不是搞服务端的,只是文字描述多么干涩啊。
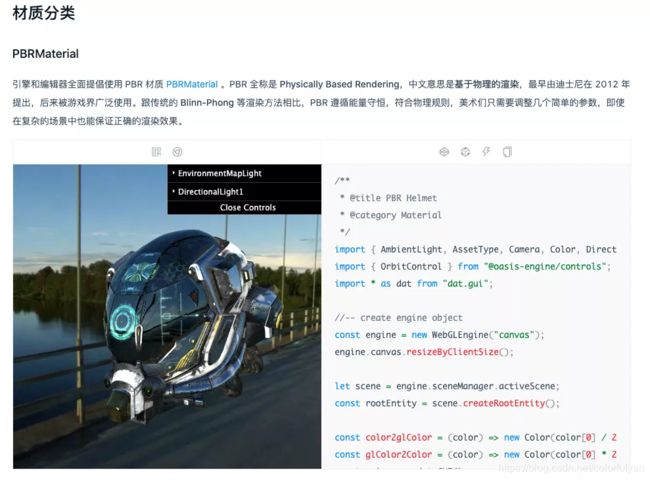
可以负责任地告诉大家,我的五一假期剩余两天就是被这个功能消耗掉的。接下来说一下具体的实现思路。
首先,我想让维护文档的同学轻松一点,在 Markdown 文件中嵌入一个 Demo 应该是一行代码的事情,比如:
多么简单优雅!可是问题来了:怎么从 Markdown 中“提取”出这行代码并最终渲染成想要的样子呢?不要忘了 Markdown 本来就是 gatsby 的一项数据源,gatsby 正是通过 gatsby-transformer-remark 插件解析数据的,而数据的解析从原理上绕不过抽象语法树,看了一下 graphiQL 果然有 AST 数据:
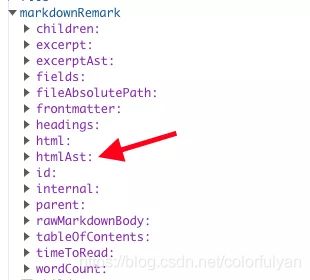
1.第一步,在语法树中找到 标签替换成我想要的数据。于是,我就开始了人生的第一个 gatsby 插件 gatsby-remark-oasis 的编写:
// `gatsby-remark-oasis` plugin:
// Extract from markdown AST and replace the content
const visit = require('unist-util-visit');
const fs = require('fs');
const Prism = require('prismjs');
module.exports = ({ markdownAST }, { api, playground, docs }) => {
visit(markdownAST, 'html', (node) => {
if (node.value.includes('${Prism.highlight(code, Prism.languages.javascript, 'javascript')} `;
}
}
});
return markdownAST;
};
这里有人可能会觉得奇怪,既然已经把源码塞入到 (为了省去转义的工作)中,为何引入一个 Prsimjs 再把代码解析成 HTML 片段呢?
如果你分析一下上文中 Demo 的构成,会发现有两部分构成:左边是一个预览,右边是代码片段,这个代码片段就是通过 Prsimjs 美化生成的。如果我们在运行时使用 Prsimjs 也是可以的,但我们在插件里完成解析就相当于在编译期完成这项工作,可以避免运行时引入一个 Prsimjs 的包增加网页体积。
2.完成上一步之后,数据终于到了 React 中,但 React 也不认识 这个组件。于是,我们就需要另一个插件 gatsby-remark-component-parent2div 来把 声明成 React 组件:
{
resolve: 'gatsby-transformer-remark',
options: {
plugins: [
// Extract from html markdwon AST and replace the content
{
resolve: 'gatsby-remark-oasis',
options: {
api: `/${version}/api/`,
playground: `/${version}/playground/`,
docs: `/${version}/docs/`,
}
},
// convert to React Componennt
{
resolve: "gatsby-remark-component-parent2div",
options: {
components: ["Playground"],
verbose: true
}
},
],
},
},
注意这两个插件使用的是 gatsby-transformer-remark 插件生成的数据,所以插件配置要嵌套在 gatsby-transformer-remark 的 plugins 里,这是一条数据处理管线。
3.最后一步,我们在 React 代码中把 替换成真正的 React 组件,这一步通过使用 rehype-react 来实现:
import RehypeReact from "rehype-react";
import Playground from "../Playground";
const renderAst = new RehypeReact({
createElement: React.createElement,
components: { "playground": Playground }
}).Compiler;
export default class Article extends React.PureComponent {
render () {
return renderAst(this.props.content.htmlAst);
}
}
至于 组件本身的编写就相对简单了。值得提一下的是这里的左侧 Demo 预览其实是一个 iframe 嵌入的 html 页面,为此我也通过 gatsby 的 createPages API 创建了很多 Demo 页面。为了把 Typescript 示例文件编译成 React 页面,我写了第二个 gatsby 插件(实际更复杂,这里只展示最重要的 babel transform 部分,感兴趣的可以看一下插件源码):
// gatsby-node.js
const babel = require("@babel/core");
exports.onCreateNode = module.exports.onCreateNode = async function onCreateNode(
{ node, loadNodeContent, actions, createNodeId, reporter, createContentDigest }
) {
const { createNode } = actions
const content = await loadNodeContent(node)
// 省略了 babel 配置
const result = babel.transformSync(content, {...});
const playgroundNode = {
internal: {
content: result.code,
type: `Playground`,
},
}
playgroundNode.internal.contentDigest = createContentDigest(playgroundNode)
createNode(playgroundNode)
return playgroundNode
}
主体的功能完成之后,又加了一些小功能,比如在二维码预览、新页面打开,以及 CodePen、CodeSandBox、Stackblitz 的跳转编辑。这些小功能非常实用,既可以验证功能的可靠性,又可以增强开发者的互动。
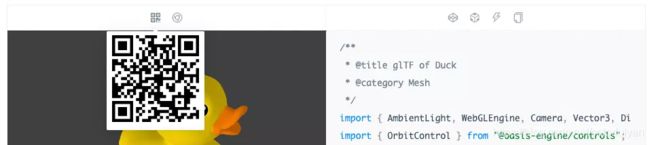
全局搜索
前面说了图形引擎的功能和 API 是非常多,特别对于深度使用引擎的开发者来说,如果没有搜索真的很痛苦。一开始我觉得这是个小功能,后来我发现确实也只是个小功能:)不过这个功能让我苦苦等了 20 天。
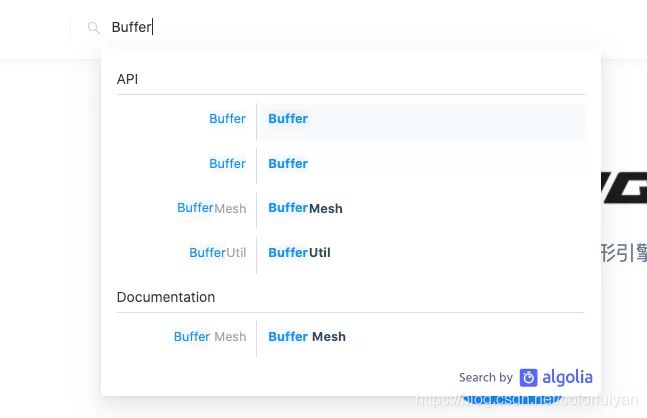
这里用到了 Algolia Docsearch。Algolia 是一家提供云搜索服务的公司,简单来说,Docsearch 的服务器会每隔 24 小时爬取网站的数据,然后网站引入 Docsearch 的前端 SDK 访问爬取的数据。实现这样的搜索需要两步:
1.去官网申请后,会收到一份邮件询问你是否是网站管理员,是否能够引入 Docsearch 的 前端SDK:
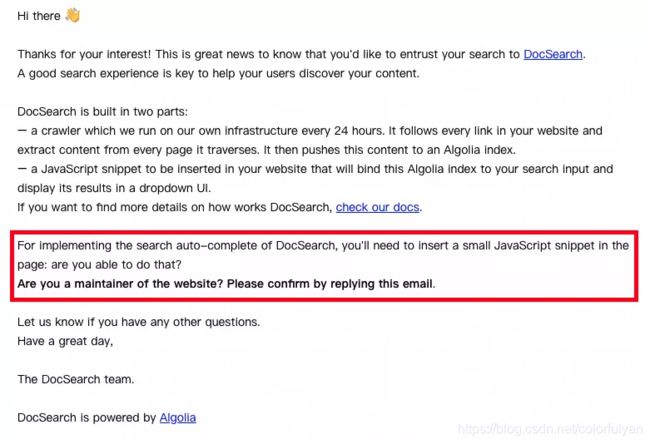
我自信地回复邮件“Yes, I can…”,然而从此以后杳无音信。过了半个月,此时我已经回复了三封邮件,依然没有收到回复。于是我换了个邮箱申请,过了几天终于收到了确认邮件,里面包含了分配给 oasisengine.cn 的 apiKey。
2.收到 apiKey 后,我第一时间去验证功能,发现搜索结果并不是我期望的。和早期 SEO 优化一样,想让搜索结果满意,要么网站根据爬虫的默认规则修改网站内容,要么修改爬虫的爬取规则。Docsearch 为开发者提供了后者的选项,只要提供一个配置文件到这个 docsearch-configs 仓库就可以。这里展示一下比较关键的字段:
{
// 要爬取的页面 url 匹配规则
"start_urls": [
{
"url": "https://oasisengine.cn/(?P.*?)/docs/.+?-cn",
"variables": {
"version": [
"0.3"
]
},
"tags": [
"cn"
]
},
],
// 爬取页面中哪些 HTML 标签的数据
"selectors": {
// 一级类目,这个很关键,搜索的结果分类就可以根据这个实现的
"lvl0": {
"selector": ".docsearch-lvl0",
"global": true,
"default_value": "Documentation"
},
"lvl1": "article h1",
"lvl2": "article h2",
"lvl3": "article h3",
"lvl4": "article h4",
"lvl5": "article h5",
"text": "article p, article li"
}
}
负责 docsearch-configs 仓库的 PR 合并的是个法国帅哥,服务太好了,我前一分钟发PR,他后一分钟就回复了,堪比在线答疑。相比之下,负责邮件回复的部门效率真的太低了。
小结
以上就是建站过程中遇到主要几个问题以及解法,走弯路的过程比真正写代码的过程长得多。这几年一直在沉浸于互动图形开发方向,趁着这次建站的机会也更新了一些前端技术栈,受益匪浅,比如第一次使用 GraphQL,感觉非常强大,预感以后还有用武之地。
Oasis 引擎的文档发展才刚刚开始,我们深知这是一份需要逐年累月打磨的工作。希望这点小小的工作,能帮助团队更好地迭代文档,帮助开发者更快地找到所需的
在此如果大家有需要的话,可以领取阿里云代金券,免费领取,以防后事之需
阿里云代金券
腾讯云代金券