大规模CTR框架的变革之夜

文 | 卖萌酱
大家好,我是卖萌酱。
这几年,有太多的领域吃到了深度学习和大模型的红利,而被大家称之为“现金牛”业务的搜广推,相比CV、NLP等领域却表现的有点“慢半拍”。
深度学习已经爆发有10年了。“点击率(CTR)预估”往往被认为是推荐和广告领域的一个核心问题,在这方面,业内如今依然有不少团队连深度学习都没有用到。
究其原因,卖萌酱认为有二:
CTR问题依赖的特征规模非常大而稀疏,仅仅是横向的将这些特征好好建模一下,都会有比较高的收益天花板,即使这时模型层面仅仅是个线性的LR(逻辑回归)
传统的深度学习框架对大规模稀疏特征的处理不友好,而传统的基于CPU参数服务器的CTR框架又训不动大型神经网络。换言之,基建限制了想象力。
关于原因一,可以用一张图来描绘一个典型的CTR模型的参数分布和模型特点:
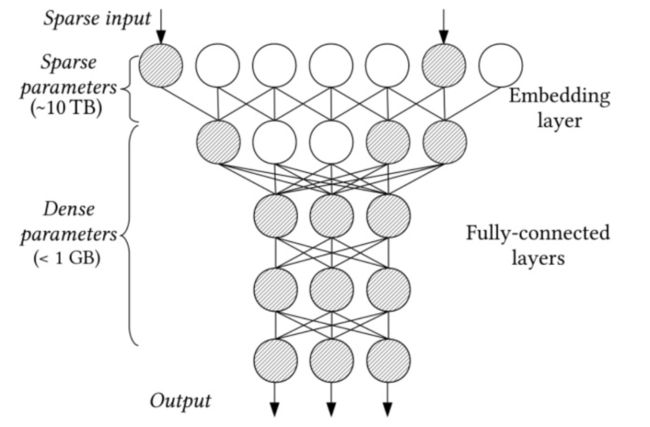
从上图可以看出,特征embedding化的部分非常“宽”,特征维度常常高达百亿、千亿级,导致embedding table参数大小常常在TB数量级;而后续的dense计算的参数大小却往往不到1GB,这是推荐CTR模型与CV、NLP模型相比非常大的区别。这也是为什么传统的CTR训练框架大都是基于CPU+参数服务器的方式:

即模型参数保存在少数几个server机器中,梯度计算的任务则交给几百上千个worker机器来完成。
虽然embedding table比较大,但由于内存容量大且相对廉价,单台worker机器的内存也能存储一部分embedding table了,因此embedding table经过切片(即模型并行)丢给多个worker去分别计算也就解决了embedding存储规模过大的问题。
不过,显然这种基于CPU参数服务器的CTR计算架构,会带来诸多问题:
首先,成本高。组建一个CPU参数服务器集群常常需要购置数百上千台CPU机器,是一笔不小的开销;而且网卡是一种相对容易发生故障的硬件设备,而网络里又有大量的网卡级联,时常发生的节点故障既影响计算的稳定性,又会导致居高不下的后期维护成本。
其次,速度慢,难以支持大型神经网络。网卡通信的速度显然要远远慢于单机内的内存访问速度,因此网络通信的延迟常常成为CTR模型计算速度的瓶颈;此外,CPU的算力难以应对Transformer这种有大量并行计算的大型神经网络模型,因此这种传统架构往往制约了CTR模型的模型结构层面的复杂度,进而制约CTR模型的效果提升。
此外,由于网络通信有天然的“长尾效应”,因此模型参数往往采用“异步更新”的机制来提升训练效率,无法做到同步更新模型参数,这就会偶尔引发训练不稳定的问题或影响训练效果。而先进的推荐系统常常需要做到模型参数的热部署,支持在线学习,因此框架的这些不足可能会拖慢策略迭代速度,甚至影响线上的推荐效果。
尽管这种架构槽点很多,但在业务迭代的初步阶段时也凑合能用。
不过,毕竟这么多年卷过去了,特征层面的收益已经被大厂算法工程师们挖的七七八八了,再想向上突破就得啃硬骨头,于是大家纷纷将目光投向了模型层面。
前有wide&deep模型筑基(2016,谷歌),后有MMoE模型(2018,谷歌)、DIN模型(2018,阿里巴巴)、DLRM模型(2019,Facebook)等将模型推向更高的复杂度。
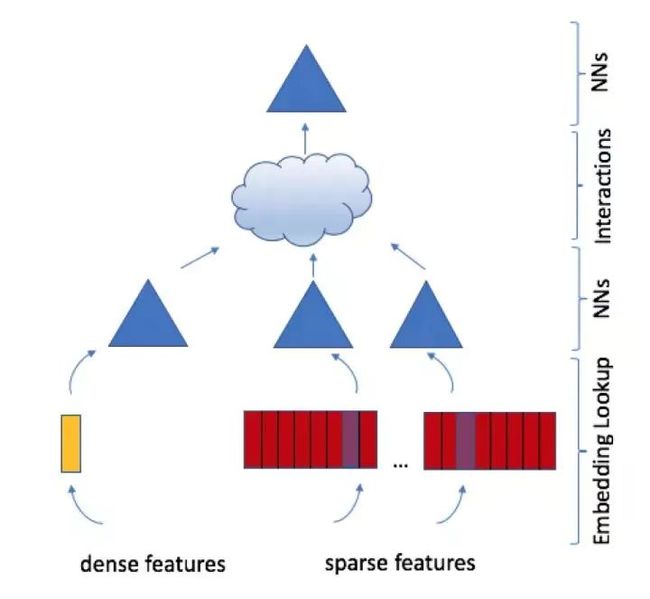
显然,如前所述,这种复杂的神经网络是CPU难以招架的,而若能引入GPU训动这种复杂的神经网络,不仅可以缩短训练时间、节省设备成本,且类似Transformer的复杂网络经验上往往能带来几个千分点的业务收益,带来巨大的商业回报。
因此,推荐系统的计算正在逐渐由GPU接管,由此直接引发了一场CTR底层框架的变革——业界需要以GPU为核心驱动的CTR计算框架!
在这个大势之下,各互联网大厂开始自研大规模稀疏计算友好的GPU驱动的深度学习框架,典型代表如百度自研的PaddleBox(前身是AIBOX(2019)、Abacus(2013))、阿里巴巴XDL框架、腾讯的无量框架、NVIDIA的HugeCTR框架等。
这里给大家推荐一个近期NVIDIA Merlin HugeCTR框架的官方介绍视频,可以非常清晰了解一个先进的GPU加速的推荐CTR框架是如何设计的:
 GPU计算引发的巨大挑战
GPU计算引发的巨大挑战
有人说,不就是基于GPU的深度学习嘛,这个我熟!那我就给每个worker结点挂载上GPU行不行?
N多年前还真有人这样做了。但毫无疑问,CPU参数服务器往往机器节点数量庞大(少说几百台),在降本增效的今天,你跟老板提“我要买几百台GPU机器替换掉廉价的CPU机器”,估计老板能气吐血。
 ▲一张梗图
▲一张梗图
即使你买够了GPU机器,但考虑下前面提过的——CTR模型的embedding table大小常常在TB量级,GPU那几十G的显存在embedding table面前完全没眼看。若你暴力的将embedding table切片塞内存,或干脆丢进SSD里,仅让GPU去计算DNN的部分,embedding的查询和更新所带来的内存到GPU显存的通信开销、SSD到内存的通信开销就足以把GPU计算DNN带来的加速给淹没掉了。这样一来,引入GPU带来的加速优势就非常有限了。
正是这一系列的问题,让CTR计算框架的变革之夜有了初始的攻坚目标。
 GPU驱动的CTR计算
GPU驱动的CTR计算
2019年,百度研究院在信息检索顶会CIKM上发表了题为 "AIBox: CTR Prediction Model Training on a Single Node" 的论文,通过三级流水线的机制设计,巧妙的SSD、内存、GPU显存之间的通信开销进行了较大程度的隐藏,实现了在单台GPU机器上训练CTR模型。
在这篇工作中,TB级别的embedding table是存放在SSD中的,而内存则是充当了cache的角色来减少SSD的通信开销。但毕竟embedding的查询、更新等全程由CPU完成,当神经网络的结构不够复杂时,CPU驱动的embedding操作的时间开销就难以被流水线隐藏,进而拖慢CTR模型的计算和训练更新。
NVIDIA Merlin HugeCTR框架则在近期首创了带GPU缓存的推理端分级参数服务器(HPS),巧妙利用各存储介质的特性,极大地提升了大模型的推理速度,实现了推荐系统端到端全链路的推理加速, 直接上视频:
HPS 进行了许多专门针对高效利用 GPU 的优化,包括分布式参数服务器分片,以实现 GPU/CPU 中许多庞大 Embedding Table 的并行推理,以及 GPU 友好的缓存、临时数据移动内存、内存管理机制等。
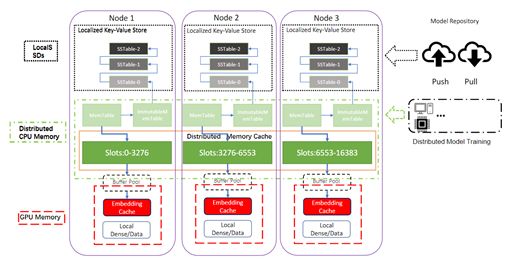
以embedding操作为例,HugeCTR团队注意到了一个关键的观察——在现实世界的推荐数据集中,一些特征类别通常比其他特征类别出现得更频繁。例如 在用于 MLPerf 的一个使用广泛的 1 TB 点击日志基准数据集中,有 305K 个特征仅占总特征数的0.16%,但却被 95.9% 的样本使用到了。
这也就是说,如果我们可以把这305K个超高频特征的embedding(称为热embedding)缓存到GPU中,那显然可以大大加快CTR模型的计算效率。
这正是HPS在GPU优化方面的一个设计亮点,HPS实现了将上述“热embedding”保留在GPU缓存中,从而大大减少了CPU-GPU的通信消耗。 HPS对embedding的处理可以说做到了新的极致。
除了设计理念先进外,借助NVIDIA在GPU方面的深厚技术积淀,HPS还把kernel、显存等优化到了极致,在业界公认权威的AI性能测试基准——MLPerf上,NVIDIA更是实现了常年霸榜。
 与深度学习框架深度融合
与深度学习框架深度融合
HugeCTR框架在解决了GPU驱动的高效CTR计算后,还做了一个重要的事情,那就是将框架功能与业界主流的深度学习框架TensorFlow进行深度融合,来减少用户的学习成本。
实现这个功能的插件包叫做sparse-operation-kit(简称SOK),下面是SOK的官方介绍视频:
原理方面,SOK 以数据并行的方式接收输入数据,然后在内部做模型转换,最后将计算结果以数据并行的方式传递给初始 GPU。这种方式使得用户给仅需要修改几行代码即可享受HugeCTR带来的性能加速。
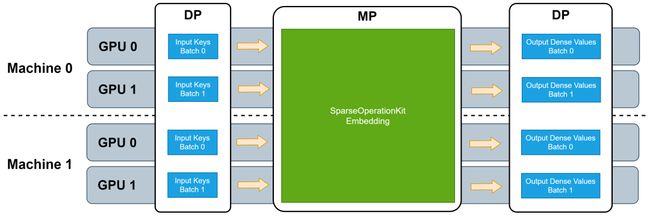
此外,SOK 不仅仅是加速了 TensorFlow 中的算子,还提供了一系列新的解决方案(比如 GPU HashTable)。SOK 深度兼容了 TensorFlow 1.15 和 TensorFlow 2.x,既可以使用 TensorFlow 自带的通信工具,也可以使用 Horovod 等第三方插件来作为 embedding parameters 的通信工具。
下面是SOK在AI性能测试基准MLPerf(基于标准模型DLRM)上的表现:

可以看到HugeCTR带来的加速效果非常显著。SOK的出现很大程度上打破了GPU驱动的CTR框架各大厂“各玩各的”的壁垒,使得框架研发能力弱的中小厂也能低成本的使用GPU来训练CTR模型了。
 展望
展望
先进的GPU驱动的CTR计算框架出现,使得许多以前被掣肘的策略idea有了实现的空间,也解决了很多大规模CPU参数服务器时代的遗留问题。
幸运的是,我们就正处在新老框架交接的变革之夜。可能多年前,我们很难想象CTR模型竟然可以在一台GPU机器上训练,想不到一台A100 GPU机器能比200台CPU机器更能打。由此,基础设施的搭建成本和维护成本得到了大大的降低。
与此同时,受益于强大的GPU并行计算的算力,以及砍掉的若干低速设备的通信成本,CTR模型的复杂度不仅可以被提升到新的高度,模型的训练时间也大大缩短了,这对算法同学来说,也意味着可以进行更加精细的模型调优,甚至拿到上线复杂模型带来的效果收益。
而NVIDIA Merlin HugeCTR框架不仅充分发挥了GPU的优势,并对性能做了极致优化,还通过SOK接入TensorFlow,使得GPU驱动的CTR计算框架的使用门槛得到了极大的降低。
在新一代的CTR计算框架下,将会诞生怎样的CTR模型?推荐系统的智能程度会因此迎来新一波的起飞吗?
我们拭目以待!
*注:与 NVIDIA 产品相关的图片或视频(完整或部分)的版权均归 NVIDIA Corporation 所有
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群