分布式散列表(DHT)及具体实现Kademlia(kad)/Chord
分布式散列列表也称为分布式哈希表,英文distributed hash table,简称 DHT。
分布式散列列表在概念上类似与传统的散列列表,差异在于传统的散列列表主要是⽤用于单机。
分布式散列列表主要是⽤用于分布式系统(此时,分布式系统的节点可以通俗理理解为散列列表中的 bucket),分布式散列列表主要是⽤用来存储⼤大量量的(甚⾄至是海海量量的)数据。在实际使⽤用场景中,直接对所存储的“每⼀一个业务数据”计算散列列值,然后用散列值作为 key,业务数据本身是 value。
分布式散列列表(DHT)的难点:
1、无中心导致的难点
DHT的诞生,是为了解决之前P2P技术的缺陷。其中一个缺陷是中央服务器导致的单点故障。
因此 DHT 就不能再依靠中央服务器。而没有了中央服务器,就需要提供一系列机制来实现节点之间的通讯。
2、海量数据导致的难点
DHT的很多使用场景是为了承载海量数据(PB 或更高级别)。
由于数据是海量的,每个节点只能存储(整个系统的)一小部分数据。需要把数据均匀分摊到每个节点。
3、节点动态变化导致的难点
很多DHT的使用场景是在公网(互联网)上,参与DHT的节点(主机)会出现频繁变化,每时每刻都有新的节点上线,也
会有旧的节点下线。在这种情况下,需要确保数据依然是均匀分摊到所有节点。
(特别强调一下:传统的散列表在这种情况下的困难)
因为传统散列表在针对 key 计算出散列值之后,需要用散列值和桶数进行某种运算(比如:取模运算),从而得到桶的编号。
如果桶的数量出现变化,就会影响到上述取模运算的结果,然后导致数据错乱。
4、高效查询导致的难点
对于节点数很多的分布式系统,如何快速定位节点,同时又不消耗太多网络资源,这也是一个挑战。
DHT 必须有更高效的查找机制。而且这种查找机制要能适应节点动态变化这个特点。
分布式散列表(DHT)解决上述难点
DHT 采用如下一些机制来解决上述问题,并满足分布式系统比较苛刻的需求。
1、散列算法的选择
前面提到: DHT 通常是直接拿业务数据的散列值作为 key,业务数据本身作为 value。
考虑到 DHT 需要承载的数据量通常比较大,散列函数产生的散列值范围(keyspace)要足够大,以防止太多的碰撞。更进一步,如果 keyspace大到一定程度,使得随机碰撞的概率小到忽略不计,就有助于简化 DHT 的系统设计。
通常的 DHT 都会采用大于等于128比特的散列值。
2、同构的node ID与data key
DHT属于分布式系统的一种。既然是分布式系统,意味着存在多个节点。在设计分布式系统的时候,一种常见的做法是:给每一个节点(node)分配唯一的ID。
很多 DHT 的设计会让node ID采用跟data key同构的散列值。这么搞的好处是:
2.1、当散列值空间足够大的时候,随机碰撞忽略不计,因此也就确保了node ID 的唯一性
2.2、可以简化系统设计——比如简化路由算法(下面会提及)
3、拓扑结构的设计
作为分布式系统, DHT 必然要定义某种拓扑结构;有了拓扑结构,自然就要设计某种路由算法。
如果某个DHT 采用前面所说的node ID与data key同构,那么很自然的就会引入Key-based routing。
当某个分布式系统具有自己的拓扑结构,它本身成为一个Overlay网络(Overlay Network)。所谓的Overlay网络,通俗地
说就是网络之上的网络。对于大部分 DHT 而言,它们是基于互联网之上的覆盖网络,它们的数据通讯是依赖下层的互联网来实现
的。
前面提到的node ID,其解耦的作用就体现在分布式系统在设计拓扑结构和路由算法时,只需要考虑 node ID,而不用考虑其下层网络的属性(比如:协议类型、 IP 地址、端⼝口号)。
4、路由算法的权衡
由于DHT中的节点数可能非常多(比如:几十万、几百万),而且这些节点是动态变化的。因此就不可能让每一个节点都记录所有其它节点的信息。实际情况是:每个节点通常只知道少数一些节点的信息。
这时候就需要设计某种路由算法,尽可能利用已知的节点来转发数据。 路由算法很重要,直接决定了DHT 的速度和资源消耗。
在确定了路由算法之后,还需要做一个两难的权衡路由表的大小。路由表越大,可以实现越短(跳数越少)的路由;缺点是:(由于节点动态变化)路由表的维护成本也就越高。路由表数越小,其维护成本越小;缺点是:路由就会变长(跳数变多)。
5、距离算法
某些 DHT 系统还会定义一种距离算法,用来计算: 节点之间的距离、 数据之间的距离、 节点与数据的距离。
请注意:此处所说的距离属于逻辑层面,对应的是 DHT 自己的拓扑结构;它与地理位置无关,也与互联网的拓扑结构无关。
这里就能明白为什么前面要强调node ID与data key同构。当这两者同构,就可以用同一种距离算法;反之,如果这两者不同构,多半要引入几种不同的距离算法。
6、数据定位
对 DHT 而言,这是最关键的。DHT 与传统的散列表在功能上是类似的。说白了,他们最关键的功能只有两个保存数据和获取数据。
保存数据
(大致原理,具体的协议实现可能会有差异)
当某个节点得到了新加入的数据(K/V),它会先计算自己与新数据的 key 之间的距离;然后再计算它所知道的其它节点与这个key 的距离。
如果计算下来,自己与 key 的距离最小,那么这个数据就保持在自己这里。
否则的话,把这个数据转发给距离最小的节点。
收到数据的另一个节点,也采用上述过程进行处理(递归处理)。
获取数据
(大致原理,具体的协议实现可能会有差异)
当某个节点接收到查询数据的请求(key),它会先计算自己与 key 之间的距离;然后再计算它所知道的其它节点与这个 key 的距离。
如果计算下来,自己与 key 的距离最小,那么就在自己这里找有没有 key 对应的 value。有的话就返回 value,没有的话就报错。
否则的话,把这个数据转发给距离最小的节点。
收到数据的另一个节点,也采用上述过程进行处理(递归处理)。
Chord 协议
Chord 诞生于2001年。第一批 DHT 协议都是在那年涌现的,另外几个是: CAN、 Tapestry、 Pastry。
拓扑结构——环形
Chord 的拓扑,必然要提到Consistent Hashing(译作一致散列)。搞明白一致散列也就知道 Chord的拓扑设计了。
一致散列主要是为了解决节点动态变化这个难点。为了解决这个难点, 一致散列把散列值空间(keyspace)构成一个环。对于 m 比特的散列值,其范围是 [0, 2m-1]。你把这个区间头尾相接就变成一个环,其周长是 2m。然后对这个环规定了一个移动方向(比如顺时针)。
如果 node ID 和 data key 是同构的,那么这两者都可以映射到这个环上(对应于环上的某点)。

假设有某个节点A,距离它最近的是节点B(以顺时针方向衡量距离)。那么称 B 是 A 的继任(successor), A 是 B 的前任(predecessor)。
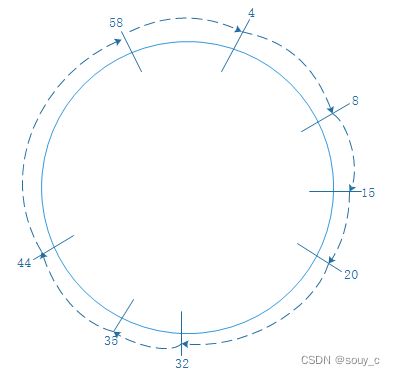
数据隶属于【距离最小】的节点。以 m=6 的环形空间为例:
数据区间 [5,8] 隶属于节点8
数据区间 [9,15] 隶属于节点15
......
数据区间 [59,4] 隶属于节点4(注: 6比特的环形空间, 63之后是0)
路由机制
接下来简单说⼀一下路由的玩法。
基本路由(简单遍历)
当收到请求(key),先看 key 是否在自己这里。如果在自己这里,就直接返回信息;否则就把 key 转发给自己的继任者。以此类推。
这种玩法的时间复杂度是 O(N)。对于一个节点数很多的 DHT 网络,这种做法显然非常低效。
高级路由(Finger Table)
由于基本路由非常低效,自然就引入更高级的玩法——基于“Finger Table”的路由。
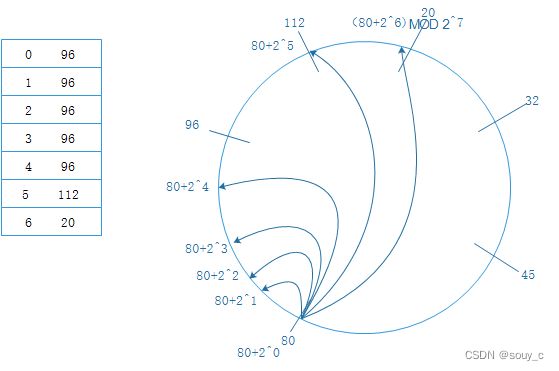
Finger Table是一个列表,最多包含 m 项(m 就是散列值的比特数),每一项都是节点 ID。
假设当前节点的 ID 是 n,那么表中第 i 项的值是: successor( (n + 2i) mod 2m )
当收到请求(key),就到Finger Table中找到最大的且不超过 key的那一项,然后把 key 转发给这一项对应的节点。有了Finger Table之后,时间复杂度可以优化为 O(log N)。
节点的加入
1任何一个新来的节点(假设叫 A),需要先跟 DHT 中已有的任一节点(假设叫 B)建立连接。
2 A 随机生成一个散列值作为自己的 ID(对于足够大的散列值空间, ID 相同的概率忽略不计)
3 A 通过跟 B 进行查询,找到自己这个 ID 在环上的接头人。也就是——找到自己这个 ID 对应的“继任”(假设叫 C)与“前任”(假设叫 D)
4 接下来, A 需要跟 C 和 D 进行一系列互动,使得自己成为 C 的前任,以及 D 的继任。
这个互动过程,大致类似于在双向链表当中插入元素。
节点的正常退出
如果某个节点想要主动离开这个 DHT 网络,按照约定需要作一些善后的处理工作。比如说,通知自己的前任去更新其继任者......
这些善后处理,大致类似于在双向链表中删除元素。
节点的异常退出
作为一个分布式系统,任何节点都有可能意外下线(也就是说,来不及进行善后就挂掉了)
假设 节点A 的继任者异常下线了,那么 节点A 就抓瞎了。
为了保险起见, Chord 引入了一个继任者候选列表”的概念。每个节点都用这个列表来包含:距离自己最近的 N 个节点的信息,顺序是由近到远。一旦自己的继任者下线了,就在列表中找到一个距离最近且在线的节点,作为新的继任者。然后 节点A 更新该列表,确保依然有 N 个候选。更新完继任者候选列表后,节点A 也会通知自己的前任,那么 A 的前任也就能更新自己的继任者候选列表。
Kademlia(Kad)协议
Kad 的原理比Chord 稍微晦涩一些。之所以选 Kad 来介绍,是因为实际应用的 DHT大部分都采用 Kad 及其变种。
拓扑结构二叉树
Kad 也采用了node ID 与 data key同构的设计思路。然后 Kad 采用某种算法把 key 映射到一个二叉树,每一个 key 都是这个二叉树的叶子。
在映射之前,先做一下预处理。
1. 先把 key 以二进制形式表示。
2. 把每一个 key 缩短为它的最短唯一前缀。
为什么要搞“最短唯一前缀”?
Kad 使用 160 比特的散列算法(比如 SHA1),完整的 key 用二进制表示有 160 个数位。
首先,实际运行的 Kad 网络,即使有几百万个节点,相比 keyspace(2160)也只是很小的一个子集。
其次,由于散列函数的特点, key 的分布是高度随机的。因此也是高度离散的——任何两个 key 都不会非常临近。
所以,使用最短唯一前缀来处理 key 的二进制形式,得到的结果就会很短(远远小于 160 个数位)。
散列值的映射
完成上述的预处理后,接下来的映射规则是:
1. 先把 key 以二进制形式表示,然后从高位到低位依次处理。
2. 二进制的第 n 个数位就对应了二叉树的第 n 层
3. 如果该位是1,进入左子树,是0则进入右子树(这只是人为约定,反过来处理也可以)
4. 全部数位都处理完后,这个 key 就对应了二叉树上的某个叶子
距离算法——异或(XOR)
接下来要聊的是 Kad 最精妙之处——采用 XOR(按比特异或操作)算法计算 key 之间的距离。
这种搞法使得它具备了类似于几何距离的某些特性(下面用 ⊕ 表示 XOR)
路由机制
二叉树的拆分
对每一个节点,都可以按照自己的视角对整个二叉树进行拆分。
拆分的规则是:先从根节点开始,把不包含自己的那个子树拆分出来;然后在剩下的子树再拆分不包含自己的下一层子树;以此类推,直到最后只剩下自己。
Kad 默认的散列值空间是 m=160(散列值有 160 比特),因此拆分出来的子树最多有 160 个(考虑到实际的节点数远远小于2160,子树的个数会明显小于160)。
对于每一个节点而言,当它以自己的视角完成子树拆分后,会得到 n 个子树;对于每个子树,如果它都能知道里面的一个节点,那么它就可以利用这 n个节点进行递归路由,从而到达整个二叉树的任何一个节点(考虑到篇幅,具体的数学证明就不贴出来了)
K-桶(K-bucket)
前面说了,每个节点在完成子树拆分后,只需要知道每个子树里面的一个节点,就足以实现全遍历。但是考虑到健壮性(分布式系统的节点是动态变化的),光知道一个是不够滴,需要知道多个才比较保险。
所以 Kad 论⽂文中给出了一个K-桶(K-bucket)的概念。也就是说:每个节点在完成子树拆分后,要记录每个子树里面的 K 个节点。这里所说的 K 值是一个系统级的常量。由使用 Kad 的软件系统自己设定(比如 BT 下载使用的 Kad 网络, K 设定为 8)。
K 桶其实就是路由表。对于某个节点而言,如果以它为视角拆分了n 个子树,那么它就需要维护 n 个路由表,并且每个路由表的上限是 K。
说 K 只是一个上限,是因为有两种情况使得 K 桶的尺寸会小于 K。
1. 距离越近的子树就越小。如果整个子树可能存在的节点数小于 K,那么该子树的 K 桶尺寸永远也不可能达到 K。
2. 有些子树虽然实际上线的节点数超过 K,但是因为种种原因,没有收集到该子树足够多的节点,这也会使得该子树的 K 桶尺寸小于K。
应用实例
1、文件的存储及查找
原来收藏在图书馆里,按索引号码得整整齐齐的书,以一种什么样的方式分发到同学们手里呢?大致的原则,包括:1)书本能够比较均衡地分布在同学们的手里,不会出现部分同学手里书特别多、而大部分同学连一本书都没有的情况;2)同学想找一本特定的书的时候,能够一种相对简单的索引方式找到这本书。
Kademlia作了下面这种安排:
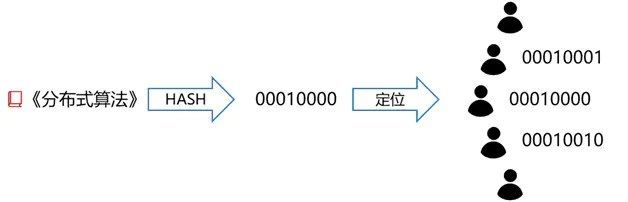
假设《分布式算法》这本书的书名的hash值是 00010000,那么这本书就会被要求存在学号为00010000的同学手上。(这要求hash算法的值域与node ID的值域一致。Kademlia的Node ID是160位2进制。这里的示例对Node ID进行了简略)
但还得考虑到会有同学缺勤。万一00010000今天没来上学(节点没有上线或彻底退出网络),那《分布式算法》这本书岂不是谁都拿不到了?那算法要求这本书不能只存在一个同学手上,而是被要求同时存储在学号最接近00010000的k位同学手上,即00010001、00010010、00010011…等同学手上都会有这本书。
同样地,当你需要找《分布式算法》这本书时,将书名hash一下,得到 00010000,这个便是索书号,你就知道该找哪(几)位同学了。剩下的问题,就是找到这(几)位同学的手机号。
2、节点的异或距离
由于你手上只有一部分同学的通讯录,你很可能并没有00010000的手机号(IP地址)。那如何联系上目标同学呢?
一个可行的思路就是在你的通讯录里找到一位拥有目标同学的联系方式的同学。前面提到,每位同学手上的通讯录都是按距离分层的。算法的设计是,如果一个同学离你越近,你手上的通讯录里存有ta的手机号码的概率越大。而算法的核心的思路就可以是:当你知道目标同学Z与你之间的距离,你可以在你的通讯录上先找到一个你认为与同学Z最相近的同学B,请同学B再进一步去查找同学Z的手机号。
上文提到的距离,是学号(Node ID)之间的异或距离(XOR distance)。异或是针对yes/no或者二进制的运算.
举2个例子:
01010000与01010010距离(即是2个ID的异或值)为00000010(换算为十进制即为2);
01000000与00000001距离为01000001(换算为十进制即为26+1,即65);
如此类推。
那通讯录是如何按距离分层呢?下面的示例会告诉你,按异或距离分层,基本上可以理解为按位数分层。设想以下情景:
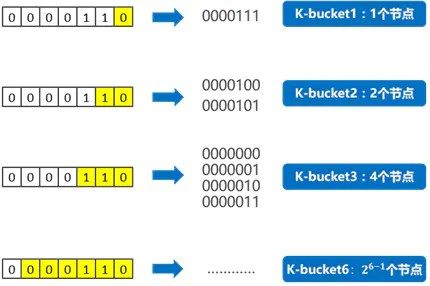
以0000110为基础节点,如果一个节点的ID,前面所有位数都与它相同,只有最后1位不同,这样的节点只有1个——0000111,与基础节点的异或值为0000001,即距离为1;对于0000110而言,这样的节点归为“k-bucket 1”;
如果一个节点的ID,前面所有位数相同,从倒数第2位开始不同,这样的节点只有2个:0000101、0000100,与基础节点的异或值为0000011和0000010,即距离范围为3和2;对于0000110而言,这样的节点归为“k-bucket 2”;
……
如果一个节点的ID,前面所有位数相同,从倒数第n位开始不同,这样的节点只有2(i-1)个,与基础节点的距离范围为[2(i-1), 2i);对于0000110而言,这样的节点归为“k-bucket i”;
按位数区分k-bucket
对上面描述的另一种理解方式:如果将整个网络的节点梳理为一个按节点ID排列的二叉树,树最末端的每个叶子便是一个节点,则下图就比较直观的展现出,节点之间的距离的关系。
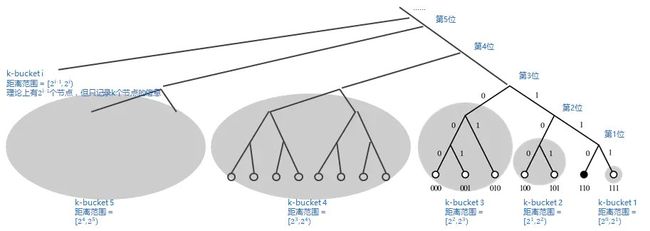
k-bucket示意图:右下角的黑色实心圆,为基础节点(按wiki百科的配图修改)
回到我们的类比。每个同学只维护一部分的通讯录,这个通讯录按照距离分层(可以理解为按学号与自己的学号从第几位开始不同而分层),即k-bucket1, k-bucket 2, k-bucket 3…虽然每个k-bucket中实际存在的同学人数逐渐增多,但每个同学在它自己的每个k-bucket中只记录k位同学的手机号(k个节点的地址与端口,这里的k是一个可调节的常量参数)。
由于学号(节点的ID)有160位,所以每个同学的通讯录中共分160层(节点共有160个k-bucket)。整个网络最多可以容纳2^160个同学(节点),但是每个同学(节点)最多只维护160 * k 行通讯录(其他节点的地址与端口)。
3、节点定位
我们现在来阐述一个完整的索书流程。
A同学(学号00000110)想找《分布式算法》,A首先需要计算书名的哈希值,hash(《分布式算法》) = 00010000。那么A就知道ta需要找到00010000号同学(命名为Z同学)或学号与Z邻近的同学。
Z的学号00010000与自己的异或距离为 00010110,距离范围在[24, 25),所以这个Z同学可能在k-bucket 5中(或者说,Z同学的学号与A同学的学号从第5位开始不同,所以Z同学可能在k-bucket 5中)。
然后A同学看看自己的k-bucket 5有没有Z同学:
- 如果有,那就直接联系Z同学要书;
- 如果没有,在k-bucket 5里随便找一个B同学(注意任意B同学,它的学号第5位肯定与Z相同,即它与Z同学的距离会小于24,相当于比Z、A之间的距离缩短了一半以上),请求B同学在它自己的通讯录里按同样的查找方式找一下Z同学:
-- 如果B知道Z同学,那就把Z同学的手机号(IP Address)告诉A;
-- 如果B也不知道Z同学,那B按同样的搜索方法,可以在自己的通讯录里找到一个离Z更近的C同学(Z、C之间距离小于23),把C同学推荐给A;A同学请求C同学进行下一步查找。
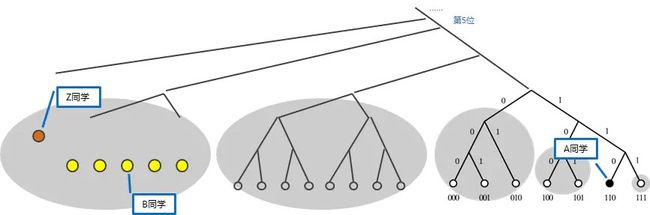
查询方式示意
Kademlia的这种查询机制,有点像是将一张纸不断地对折来收缩搜索范围,保证对于任意n个学生,最多只需要查询log2(n)次,即可找到获得目标同学的联系方式(即在对于任意一个有[2(n?1), 2n)个节点的网络,最多只需要n步搜索即可找到目标节点)。
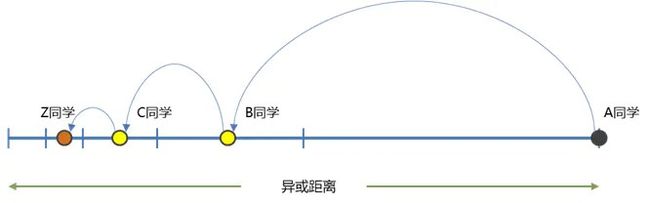
每次搜索都将距离至少收缩一半
以上便是Kademlia算法的基本原理。以下再简要介绍协议中的技术细节。
4、算法的三个参数:keyspace,k和α
keyspace
-- 即ID有多少位
-- 决定每个节点的通讯录有几层
k
-- 每个一层k-bucket里装k个node的信息,即
-- 每次查找node时,返回k个node的信息
-- 对于某个特定的data,离其key最近的k个节点被会要求存储这个data
α
-- 每次向其他node请求查找某个node时,会向α个node发出请求
5、节点的指令
Kademlia算法中,每个节点只有4个指令
PING
-- 测试一个节点是否在线
STORE
-- 要求一个节点存储一份数据
FIND_NODE
-- 根据节点ID查找一个节点
FIND_VALUE
-- 根据KEY查找一个数据,实则上跟FIND_NODE非常类似
6、k-bucket的维护及更新机制
刷新机制大致有如下几种:
1. 主动收集节点
任何节点都可以主动发起“查询节点”的请求(对应于协议类型 FIND_NODE),从而刷新 K 桶中的节点信息(下面聊“节点的加入”时,会提及这种)
2. 被动收集节点
如果收到其它节点发来的请求(协议类型 FIND_NODE 或 FIND_VALUE),会把对方的 ID 加入自己的某个 K 桶中。
3. 探测失效节点
Kad 还是支持一种探测机制(协议类型 PING),可以判断某个 ID 的节点是否在线。因此就可以定期探测路由表中的每一个节点,然后把下线的节点从路由表中干掉。
7、节点的加入
7.1
任何一个新来的节点(假设叫 A),需要先跟 DHT 中已有的任一节点(假设叫 B)建立连接。
7.2
A 随机生成一个散列值作为自己的 ID(对于足够大的散列值空间, ID 相同的概率忽略不计)
7.3
A 向 B 发起一个查询请求(协议类型 FIND_NODE),请求的 ID 是自己(通俗地说,就是查询自己)
7.4
B 收到该请求之后,(如前面所说)会先把 A 的 ID 加入自己的某个 K 桶中。
然后,根据 FIND_NODE 协议的约定, B 会找到K个最接近 A 的节点,并返回给 A。
(B 怎么知道哪些节点接近 A 捏?这时候,用 XOR 表示距离的算法就发挥作用啦)
7.5
A 收到这 K 个节点的 ID 之后,(仅仅根据这批 ID 的值)就可以开始初始化自己的 K 桶。
7.6
然后 A 会继续向刚刚拿到的这批节点发送查询请求(协议类型 FIND_NODE),如此往复(递归),直至 A 建立了足够详细的路由表。
8、节点的退出
与 Chord 不同, Kad 对于节点退出没有额外的要求(没有“主动退出”的说法)。
所以, Kad 的节点想离开 DHT 网络不需要作任何操作
总结:
Kad 成为 DHT 的主流实现⽅方式,这已经是很明显的事实。