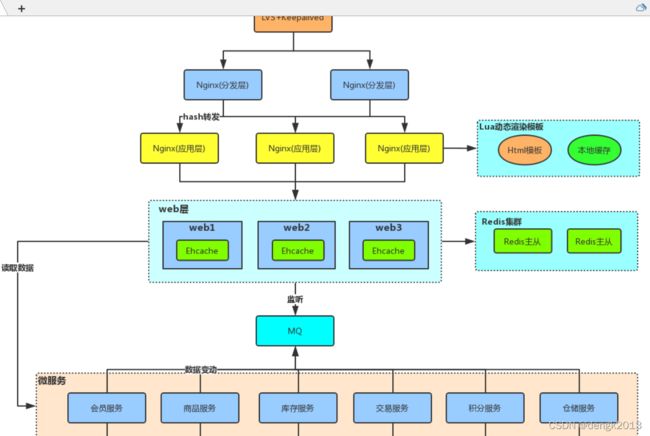
亿级流量多级缓存架构
1.缓存穿透:指查询一个根本不存在的数据, 缓存层和存储层都不会命中,
缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义
如何阻止缓存穿透?如果在数据层查不到数据,那么同样在redis set一个null,同时设置过期时间
String value = redis.get(key);
if(value ==null){
String mysqlvalue =mysql.get(key);
if(mysqlvalue==null){
redis.set(key,null);
redis.expire(key,30,SECOND);
return null;
}else{
redis.set(key,mysqlvalue);
redis.expire(key,300,SECOND);
return mysqlvalue
}
}else{
return value;
}
2.布隆过滤器解决缓存穿透问题:对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透
使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放
比如我去抢购一个商品,必须知道一个商品号,黑客就不停的攻击不存在的商品号,让服务接收大量无效的请求,所以此时我们必须把商品id放在布隆过滤器中,如果频繁收到无效的攻击,那么布隆过滤器直接拦截请求让其返回无效请求即可
//初始化布隆过滤器
RBloomFilter
bloomFilter.tryInit(100000000L,0.05);
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
3.缓存失效
比如电商平台秒杀场景中:10000个热点秒杀商品上线的时候同时设置了相同的缓存失效时间,在失效的一瞬间,大量的用户请求进来,直接打到数据库,导致数据库扛不住压力而崩溃,做法:
设置热点商品的缓存失效时间各不同,也就不存在某一时刻大量缓存失效的情况。
由于大批量缓存在同一时间失效可能导致大量请求同时穿透缓存直达数据库,可能会造成数据库瞬间压力过大甚至挂掉,对于这种情况我们在批量增加缓存时最好将这一批数据的缓存过期时间设置为一个时间段内的不同时间
//设置一个过期时间(300到1000之间的一个随机数)
int expireTime = new Random().nextInt(300) + 700;
if (storageValue == null) {
cache.expire(key, expireTime);
}
4.缓存雪崩
缓存雪崩指的是缓存层支撑不住或宕掉, 打向后端存储层。
redis崩溃导致mysql崩溃,造成了雪崩效应
预防和解决缓存雪崩问题, 可以从以下三个方面进行着手。
1) 保证缓存层服务高可用性,比如使用Redis Sentinel或Redis Cluster。
2) 后端限流熔断并降级。
3) 提前压力测试。 可能出现的问题, 在此基础上做一些预案
5.热点缓存key重建优化:比如疫情期间今日头条说连花清瘟胶囊对奥密克戎有效,全上海的人都去抢这个非热点商品,导致2000多万请求直接打到数据库中,导致数据库崩溃
伪代码解决思路:也就是说第一个线程通过互斥锁来新建来获取key,获取不到直接查数据库,然后set到redis中,最后删除互斥锁,第二个线程进来获取key的话,就可以直接获取了从而解决了非热点商品变成热点商品,缓存失效导致数据库崩溃的情况
String get(String key) {
// 从Redis中获取数据
String value = redis.get(key);
// 如果value为空, 则开始重构缓存
if (value == null) {
// 只允许一个线程重建缓存, 使用nx, 并设置过期时间ex
String mutexKey = "mutex:" + key;
if (redis.set(mutexKey, "1", "180", "nx")) {
// 从数据源获取数据
value = db.get(key);
// 回写Redis, 并设置过期时间
redis.setex(key, timeout, value);
// 删除key_mutex
redis.delete(mutexKey);
}// 其他线程休息1秒后重试
else {
Thread.sleep(1000);
get(key);
}
}
return value;
}
6.缓存与数据库双写不一致:也就是一个线程读数据库然后设置缓存这里有延迟,也就是设置缓存落后于第二个线程,另外一个线程进来读数据库,设置缓存,导致第一个线程的缓存读到第二个线程的缓存,导致双写数据库,导致缓存不一致,
处理方法:1.延迟双删 2.分布式锁单个处理。3.canal监控mysql binlog日志,有修改的话直接修改redis,因为binlog是有先后顺序的,所以redis就能保证有序性,绝对能解决双写不一致问题
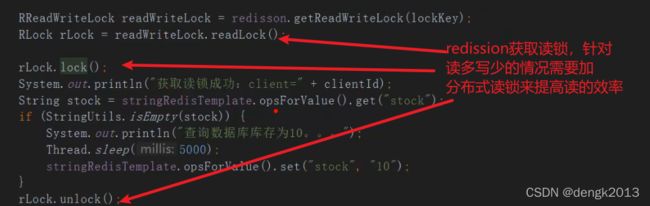
读锁:相当读操作不串行化
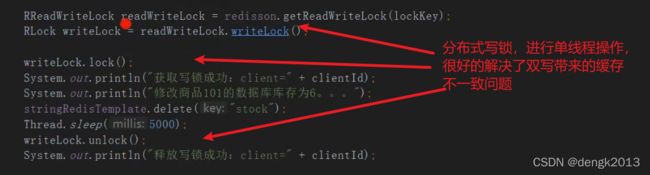
写锁:相当写操作要拿到锁才能执行,也就是串行化执行
读多写少的情况加入缓存提高性能,写多读多的情况又不能容忍缓存数据不一致,那
就没必要加缓存了,可以直接操作数据库。
7.bigkey的危害:
1.导致redis阻塞
2.网络拥塞,比如bigkey 为1M,对于1000M网卡,最多只能支持128个并发请求,大大降低了并发能力
3. 过期删除耗时很长,后台进程处理删除操作,我们最好遍历操作,而不是一次性删除,用sscan删除
8.bigkey产生
8.1 微博大v,存放粉丝,比如王思聪有上千万粉丝,如果用zset存放,必然产生bigkey,
8.2 网站统计日活用户,像京东这样的大型电商,每天统计日活用户,必然产生bigkey
解决方法:拆分思想:用分段锁的思想进行bigkey拆分,比如粉丝1-1000存放在vb:user:user1这个key中,1001-2000存放在vb:user:user2以此类推,然后通过粉丝的id进行hash来确定到底落在那个区间,这样就大大解决了bigkey的产生