在YOLOv5中添加Swin-Transformer模块
前段时间整理了一个可以添加SwinTransformer Block的YOLOv5代码仓库。不需要任何其他的库包,可以运行YOLOv5程序的环境即可以正常运行代码。
分别进行了SwinTransformer Block、Patch Merging、Patch Embed阶段的代码整理,以使得这些模块可以适配于u版YOLOv5的模型构建代码。
和YOLOv5一样,通过对模型yaml文件的修改,可以实现自定义模型结构设计。具体方法可以参考下方使用说明,以搭建符合自己需要的添加了SwinT相关模块的模型。
对于代码仓库有任何疑问或者改进优化,可以下方评论、提issue、或着邮箱联系[email protected]
YOLOv5
添加swin模块的代码基于ultralytics版本的YOLOv5代码实现,关于该YOLO代码库的详细情况,可以查看其源代码仓库。
Swin Transformer
Swin-Transformer论文下载
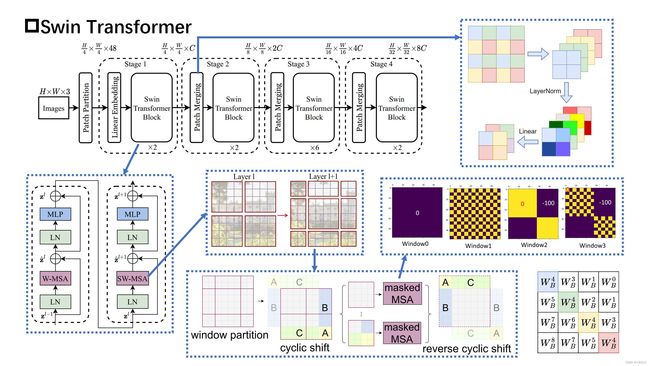
Swin-Transformer使用了层级式的骨干网络设计。从较小的Patch尺寸开始,每一阶段不断合并Patch,实现在不同阶段使用不同下采样率的特征图,从而可以输出多尺度的特征信息。
这种层级式获取多尺度特征的网络结构,使得对比ViT,SwinT更加适合于多种CV任务。借助于多尺度特征,网络能够更好地进行检测、分割等密集检测型的任务。
本代码仓库中所使用的SwinTransformer代码来自这个仓库。感谢B站霹雳吧啦Wz的SwinT讲解视频和代码讲解视频。该代码相比于原始的官方代码,具有详细的代码注释,同时增加了图像尺寸与窗口尺寸不匹配时候的填充,使得网络的设计限制更少。仓库中使用的代码在此基础上做了部分修改以适配于YOLOv5的模块构建。
想要了解更多关于SwinT的知识可以查看李沐老师和朱老师发布的Swin-Transformer论文精读。李沐老师的论文精读系列非常值得观看。
此外,关于Swin-Transformer应用于R-CNN系列的工作请关注此官方仓库。
使用说明
说明
数据准备、训练方法等与YOLOv5的完全一致,具体可以参考YOLOv5_Train-Custom-Data。
接下来主要针对模型构建进行说明
模块说明
Swin-Transformer相关的模块实现代码位于models文件夹下的swintransformer.py中,主要包含了SwinStage、Patch Merging和PatchEmbed的模块。
为了每个模块都能随时插入到原本的CNN结构中构成混合模型,在每个模块的前后,添加了对数据shape的变换。将Transformer Block中使用的[B, L, C]的数据形式变换成适用于CNN的[B, C, H, W]的形式。
PatchEmbed

该模块用于Backbone的最开始。在PatchEmbed部分,与ViT中的功能相同,用于将图像分成固定尺寸的Path,对每个Patch进行拉直与线性变换,得到后续输入向量。
在本模块的构建中,需要考虑的参数有:
-
in_c=3
输入图像的通道数。通常一个RGB彩色图像的通道数为3。每个模块的该参数在网络构建的过程中,默认将依据输入图像的尺寸自动选取;
-
embed_dim=96
Embed的向量长度。即论文中的 C C C参数,对应到混合模型中即该步骤最终生成特征图的通道数量。
SwinTransformer官方设置的模型参数如下:
Model Size C Swin-T tiny 96 Swin-S small 96 Swin-B base 128 Swin-L large 192 -
patch_size=4
划分每个Patch的大小。在SwinTransformer原始模型中,对原始图像的Patch划分为 4 × 4 4\times4 4×4,相对应的,模块输出的下采样率为4倍。即 224 × 224 224\times224 224×224的输入图像,将获得 56 × 56 56\times56 56×56的特征图输出;
-
norm_layer=None
对特征图是否进行Norm操作。默认为
None即不进行Norm操作。如有需要,请将其设置为nn中相对应的模块名称;
在运行该模块后,一个尺寸为[B, C, H, W]的输入图像的尺寸将进行如下变化:
| Data | Batch | Channel | Height | Width |
|---|---|---|---|---|
| Input | B | C | H | W |
| Output | B | embed_dim | H/patch_size | W/patch_size |
SwinStage

Swin-Transformer模型的主体部分,已经集合了串联多个Swin-Transformer Block的功能。
在本模块的构建中,需要考虑的参数有:
-
dim
输入特征图的通道数。该参数在模型构建过程中由上一层的输出自动确定;
-
c2
输出特征图的通道数。因为Transformer Block中的残差连接结构,该参数应当与第一个参数
dim一致,在模型构建中,该参数由手动输入,用于确认模型结构。 -
depth
串联Transformer Block的个数。即当前的Stage中包含了几个连续的Transformer Block,因为Swin-Transformer的移动窗口设计,通常是由一个使用窗口自注意力的Block和一个使用移动窗口自注意力的Block串联作为一组,因此该参数设计通常为偶数;
-
num_heads
多头自注意力使用的head数量。
-
window_size
给Patch划分窗口时候的窗口大小。在原论文中统一为7,在当前代码中暂未设置默认值;
-
mlp_ratio=4.
MLP模块隐藏层的单元个数比例。在一个Transformer Block中,进行Attention以后的数据还要通过一个MLP层进行信息的提取。MLP的输入和输出维度一致,一共包含一个隐藏层,如果mlp_ratio=4,则对于输入维度为 d i m dim dim的数据,隐藏层单元个数为 d i m × 4 dim\times4 dim×4;
-
qkv_bias=True
在计算数据的Q、K、V的linear层中是否使用偏置;
-
drop=0.
多头自注意力完成映射融合以后的Dropout比例;
-
attn_drop=0.
多头自注意力拼接完成,还未进行映射融合时,Dropout的比例;
-
drop_path=0.
整个Attention完成(已经完成残差连接),后的DropPath的比例;
-
norm_layer=nn.LayerNorm
在Transformer Block中使用的Norm方式。参数使用nn中的可用方法;
-
use_checkpoint=False
训练中是否使用checkpoint。是一种在训练中使用时间换空间的策略,可以使用更少的显存、花费更长的训练时间完成训练。
在运行该模块后,一个尺寸为[B, C, H, W]的输入图像的尺寸将进行如下变化:
| Data | Batch | Channel | Height | Width |
|---|---|---|---|---|
| Input | B | C | H | W |
| Output | B | C | H | W |
PatchMerging

Swin-Transformer模型各个Stage之间的部分,其实现类似于CNN中下采样的效果,特征图的宽高缩小一半,而通道数增加一倍。
在本模块的构建中,需要考虑的参数有:
-
dim
输入特征图的通道数。该参数在模型构建过程中由上一层的输出自动确定;
-
c2
输出特征图的通道数。根据PatchMerging的设计,该参数应当为第一个参数
dim的2倍,在模型构建中,该参数由手动输入,并用于确认模型结构。 -
norm_layer=nn.LayerNorm
在Transformer Block中使用的Norm方式。参数使用nn中的可用方法;
在运行该模块后,一个尺寸为[B, C, H, W]的输入图像的尺寸将进行如下变化:
| Data | Batch | Channel | Height | Width |
|---|---|---|---|---|
| Input | B | C | H | W |
| Output | B | C*2 | H/2 | W/2 |
搭建模型
准备工作
在仓库代码中关于Swin Transformer的相关准备工作已经完成,在此处进行简单描述,依据以下步骤,可以自行对模型进行模块的增删。
模块的代码
在models/common.py中、或者自己创建的*.py文件中编写自己的模块对应的代码。(本代码在models/common.py中增加了CBAM注意力机制的代码,在models/swintransformer.py中编写了Swin-Transformer模块的代码)
关于模块的编写,需要遵守以下例子的格式:
class CBAM(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
out = self.channel_attention(x) * x
# c*h*w
# c*h*w * 1*h*w
out = self.spatial_attention(out) * out
return out
如上,在模块的__init__方法中,参数的第一个除了self外,应当为in_channel,即模块输入的通道数(示例中为c1),该参数会在构建模型过程中自动根据输入层的输出产生并添加在args的开头。在构建模型的过程中,需要设置的参数是从输入通道参数以后开始的第二个及以后的参数。
导入自己的模块
在models/yolo.py中先导入自己的模块,本代码中的Swin-Transformer模块相应代码位于models/swintransformer.py中,则在models/yolo.py中需要加入下述语句导入以上模块:
from models.swintransformer import SwinStage, PatchMerging, PatchEmbed
而如果是加在models/common.py中的模块,原代码中已经一并导入。
编辑自己模型的yaml
编辑yaml文件表示你要使用的模型结构。
Swin-Transformer-Tiny的模型搭建
以使用Swin-Tiny的backbone、YOLOv5l的head为例,搭建的模型如下:
# Parameters
nc: 80 # number of classes
#ch: 3 # no. input channel
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# Swin-Transformer-Tiny backbone
backbone:
# [from, number, module, args]
# input [b, 1, 640, 640]
[[-1, 1, PatchEmbed, [96, 4]], # 0 [b, 96, 160, 160]
[-1, 1, SwinStage, [96, 2, 3, 7]], # 1 [b, 96, 160, 160]
[-1, 1, PatchMerging, [192]], # 2 [b, 192, 80, 80]
[-1, 1, SwinStage, [192, 2, 6, 7]], # 3 --F0-- [b, 192, 80, 80]
[ -1, 1, PatchMerging, [384]], # 4 [b, 384, 40, 40]
[ -1, 1, SwinStage, [384, 6, 12, 7]], # 5 --F1-- [b, 384, 40, 40]
[ -1, 1, PatchMerging, [768]], # 6 [b, 768, 20, 20]
[ -1, 1, SwinStage, [768, 2, 24, 7]], # 7 --F2-- [b, 768, 20, 20]
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 11
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 15 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 12], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 18 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 8], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 21 (P5/32-large)
[[15, 18, 21], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
在表示模型每一层的列表中,分别表示[from, number, module, args],即:
- from - 模型的输入来自哪一层,来自上一层即
-1,也可以用0开始的顺序编号表示层数,当模型的输入来自多个层的输出时(如Concat),该参数也可以是一个列表; - number - 该层的重复次数,特别的,当模块为
C3等模块时,表示模块中卷积层的次数,具体的信息可以参考models/yolo.py中parse_model函数部分; - module - 该层使用的模块;
- args - 该模块的参数;
参照以下示例:
Conv模块示例
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
以上是Conv模块的代码,在其初始化中可以看到包含8个参数,对于模型yaml中的一层
[-1, 1, Conv, [256, 3, 2]],
表示模块的输入来自上一层的输出,Conv模块重复1次,参数[256, 3, 2]则依次对应模块初始化参数中,位于输入通道数之后的参数c2, k, s,即表示输出通道数为256,卷积核大小为1*1,卷积步长为1,其余参数使用默认参数。
相当于如下语句构建的模块
conv = nn.Conv2d(c1, 256, 1, 1, autopad(k, p, d), groups=1, dilation=1, bias=False)
SwinStage模块示例
SwinStage模块的初始化函数的参数如下:
def __init__(self, dim, c2, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, use_checkpoint=False):
对于模型yaml文件示例中的一层
[-1, 1, SwinStage, [96, 2, 3, 7]],
表示模块的输入来自上一层的输出,SwinStage重复1次,参数[96, 2, 3, 7]则分别对应输入通道数dim之后的c2, depth, num_heads, window_size,即就是,96的输出通道数,SwinTransformer-Block的个数为2,多头自注意力的head个数为3,window的大小为7,其余参数使用默认参数。
相当于如下语句构建的模块
conv = SwinStage(c1, 96, 2, 3, 7)
验证自己的模型
在models/yolo.py的最后,可以验证自己的模型。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='yolov5l.yaml', help='model.yaml')
parser.add_argument('--batch-size', type=int, default=1, help='total batch size for all GPUs')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--profile', action='store_true', help='profile model speed')
parser.add_argument('--line-profile', action='store_true', help='profile model speed layer by layer')
parser.add_argument('--test', action='store_true', help='test all yolo*.yaml')
opt = parser.parse_args()
opt.cfg = check_yaml(opt.cfg) # check YAML
print_args(vars(opt))
device = select_device(opt.device)
# Create model
im = torch.rand(opt.batch_size, 3, 640, 640).to(device)
model = Model(opt.cfg).to(device)
# Options
if opt.line_profile: # profile layer by layer
model(im, profile=True)
elif opt.profile: # profile forward-backward
results = profile(input=im, ops=[model], n=3)
elif opt.test: # test all models
for cfg in Path(ROOT / 'models').rglob('yolo*.yaml'):
try:
_ = Model(cfg)
except Exception as e:
print(f'Error in {cfg}: {e}')
else: # report fused model summary
model.fuse()
在文件末尾,将--cfg指向自己的模型文件,修改im = torch.rand(opt.batch_size, 3, 640, 640).to(device)中的参数设置为自己模型预期的输入大小,然后运行yolo.py文件。
如果模型搭建没有错误,代码将成功运行,并且输出模型的参数量和计算量。
models\yolo: cfg=D:\Projects\SwinT-YOLOv5\models\yolov5l.yaml, batch_size=1, device=cpu, profile=False, line_profile=False, test=False
YOLOv5 da91a2e Python-3.8.12 torch-1.10.0+cu113 CPU
18 -1 1 590336 models.common.Conv [256, 256, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 3 2495488 models.common.C3 [512, 512, 3, False]
21 -1 1 2360320 models.common.Conv [512, 512, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 3 9971712 models.common.C3 [1024, 1024, 3, False]
24 [17, 20, 23] 1 457725 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [256, 512, 1024]]
YOLOv5l summary: 368 layers, 46563709 parameters, 46563709 gradients, 109.3 GFLOPs
Fusing layers...
YOLOv5l summary: 267 layers, 46533693 parameters, 46533693 gradients, 109.1 GFLOPs
训练自己的模型
与YOLOv5代码原版的训练方法一致,只需要在使用train.py使用时,将--cfg指向自己设计模型的yaml文件。
注意:Swin的结构设计时,window的大小对于计算量的提升非常大,改动一点窗口大小就会使得模型计算量和训练时候的显存需求提升不少。pytorch提供了checkpoint这种以时间换空间的策略,可以按需要调整。