基础知识-推荐系统
https://blog.csdn.net/baishuiniyaonulia/article/details/111030265?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162855755016780366569177%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162855755016780366569177&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-111030265.pc_search_result_control_group&utm_term=%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F&spm=1018.2226.3001.4187
1. 推荐系统
1.1. 什么是推荐系统
(1)推荐系统的定义
推荐系统(Recommendation System, RS)是一种自动联系用户和物品的工具,它能够帮助用户在信息过载的环境中发现令他们感兴趣的信息。它通常由前台的展示页面、后台的日志系统、推荐算法系统三个部分组成。
(2)为什么需要推荐系统
随着互联网上的数据越来越多,各大应用及平台坐拥海量信息,但用户却难以找到真正对自己有用的信息,用户面对庞大的数据变得毫无头绪。
目前有三大方法可以解决信息超载的问题:分类目录、搜索引擎和推荐系统:
分类目录
分类目录是将信息分门别类,从而方便用户根据类别进行查找。例如:优设导航 、百度更多 等门户网站。但分类目录只适合用在内容少而精的网站上,大多数分类目录网站只能涵盖少数热门信息,应用场景有限。
搜索引擎
用户通过在搜索引擎上输入关键字,查找自己需要的信息。例如:搜狗、Bing 等搜索引擎。但是,用户必须主动提供准确的关键词,才可能找到需要的信息。
推荐系统
推荐系统通过分析用户的历史行为,对用户的兴趣进行建模,从而主动给用户推荐可能满足他们需求的信息,该方法能够很好的发掘长尾信息。
我们可以看到,推荐系统相对于分类目录和搜索引擎,在某些方面有着不可替代的优势。通常认为,当一个系统满足以下两个条件时,就可以考虑应用推荐系统:
(1)存在信息过载(用户难以找到想要的内容);
(2)用户大多数时候没有明确的需求。
1.2. 推荐系统评测
1.2.1. 实验方法
一般来说,一个新的推荐算法最终上线,需要通过3个实验。
首先,通过离线实验证明它在很多离线指标上优于现有的算法;
其次,通过用户调查确定用户满意度不低于现有的算法;
最后,通过在线AB测试确定它在特定的指标上优于现有的算法;
(1)离线实验 Offline Experiment
离线实验的方法的步骤如下:
(1)通过日志系统获得用户行为数据,并生成一个标准数据集;
(2)将数据集分成训练集和测试集;
(3)在训练集上训练用户兴趣模型,在测试集上进行预测;
(4)通过事先定义的离线指标,评测算法在测试集上的预测结果。
(5)从以上步骤看出,离线实验的都是在标准数据集上完成的。这意味着,它不需要一个实际的系统作为支撑,只需要有一个模拟环境即可。
离线实验的优缺点: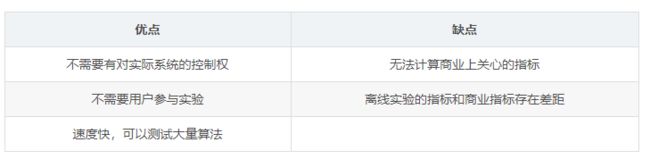
(2)用户调查 User Study
用户调查由真实的用户在需要测试的推荐系统上完成某些任务。在他们完成这些任务时,观察和记录他们的行为,并让他们回答一些问题。最后通过分析他们的行为和答案,了解推荐系统的性能。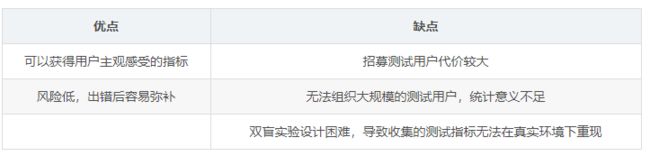
(3)在线实验 Online Experiment
在线实验是指将系统上线做AB测试,把它和旧算法进行比较。AB测试通过一定的规则将用户随机分成几组,对不同组的用户采用不同的算法,然后通过统计不同组的评测指标,比较不同算法的好坏。
AB测试的优缺点:
大型网站做AB测试,可能会因为不同团队同时进行各种测试对结果造成干扰,所以切分流量是AB测试中的关键。不同的测试层以及控制这些层的团队,需要从一个统一的流量入口获得自己AB测试的流量,而不同层之间的流量应该是正交的。关于分层实验和流量正交的知识可以参考这篇博客:黄一能:什么是科学的AB测试?谈谈分层实验和流量正交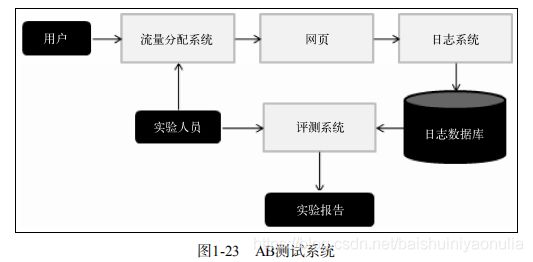
1.2.2. 评测指标
评测指标用于评测推荐系统的性能,有些可以定量计算,如预测准确度、覆盖率、多样性、实时性;有些只能定性描述,如用户满意度、新颖性、惊喜度、信任度、健壮性和商业目标。
有了这些指标,就可以根据需要对推荐系统进行优化,通常的优化目标是在给定覆盖率、多样性、新颖性等限制条件下,尽量提高预测准确度。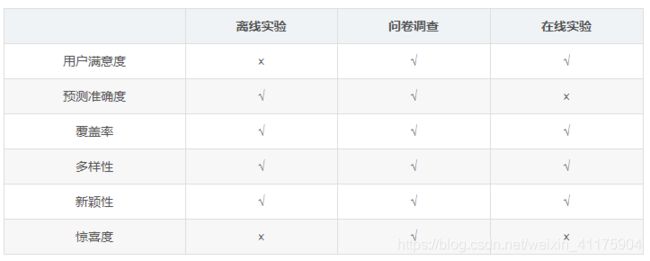
(1) 用户满意度
用户满意度是评测推荐系统的重要指标,无法离线计算,只能通过用户调查或者在线实验获得。
调查问卷的设计需要考虑周全,用户才能针对特定问题给出准确的回答;
在线系统中用户的满意度通过统计用户行为得到。一般情况,可以用用户点击率、停留时间、转化率等指标度量用户的满意度。
(2) 预测准确度
预测准确度是度量一个推荐系统或其中推荐算法预测用户行为的能力。 是推荐系统最重要的离线评测指标。大致可从“评分预测”和“Top-N推荐”两个方面进行评测。
评分预测
预测评分的准确度,衡量的是算法预测的评分与用户的实际评分的贴近程度,一般通过以下指标度量:

Top-N推荐
如果推荐服务会给用户提供个性化的推荐列表,那么这种推荐就叫做Top-N推荐。Top-N推荐的预测准确率,一般通过2个指标度量:
Top-N推荐由于其个性化特性突出,因此相对于评分预测更符合实际的应用需求
(3) 覆盖率
覆盖率(Coverage)是描述一个推荐系统对物品长尾的发掘能力。覆盖率最简单的定义是:推荐系统能够推荐出来的物品占总物品集合的比例
覆盖率是内容提供者关心的指标,覆盖率为100%的推荐系统可以将每个物品都至少推荐给一个用户。
除了利用推荐物品的占比来定义覆盖率,还可以通过研究物品在推荐列表中出现的次数分布来描述推荐系统的挖掘长尾的能力。如果分布比较平,说明推荐系统的覆盖率很高;如果分布陡峭,说明分布系统的覆盖率较低。
信息论和经济学中有两个著名指标,可以定义覆盖率:
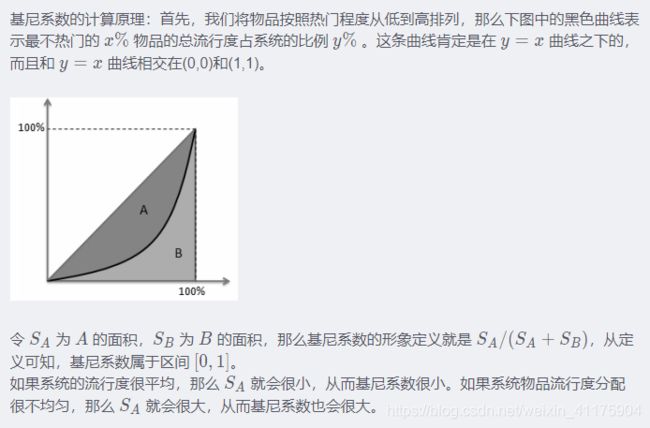
(4) 多样性
为了满足用户广泛的兴趣,推荐列表需要能够覆盖用户不同的兴趣领域,即需要具有多样性。
(5) 新颖性
新颖性也是影响用户体验的重要指标之一。它指的是向用户推荐非热门非流行物品的能力。评测新颖度最简单的方法是利用推荐结果的平均流行度,因为越不热门的物品,越可能让用户觉得新颖。
但是这种计算方法比较粗糙,因为不同用户不知道的东西是不同的,需要配合用户调查准确统计新颖度。
(6) 惊喜度
惊喜度与新颖度相关,它是指推荐结果和用户的历史兴趣不相似,但却让用户满意的程度。
(7) 信任度
信任度用于衡量用户对推荐系统的信任程度,这个指标的意义在于,如果用户信任推荐系统就会增多用户和推荐系统的交互。信任度目前只能通过问卷调查的方式来度量。
提高信任度的方式主要有两种:
增加系统透明度
即提供推荐解释,让用户了解推荐系统的运行机制。
利用社交网络信息
即利用用户的好友给用户做推荐。
(8) 实时性
许多物品具有很强的时效性,例如新闻、微博等,需要在时效期内推荐给用户,否则物品的价值就可能大打折扣。推荐系统的实时性包括两方面:
实时更新推荐列表满足用户新的行为变化;
将新加入系统的物品推荐给用户;
前者可以通过推荐列表的更新速率来控制和测评,后者可以通过计算推荐列表中有多大比例的物品是新加入物品来测评。
(9) 健壮性
任何能带来利益的算法系统都会被攻击,最典型的案例就是搜索引擎的作弊与反作弊斗争。推荐系统也不例外,健壮性衡量了推荐系统抗击作弊的能力。
2011年的推荐系统大会专门有一个推荐系统健壮性的教程,作者总结了很多作弊方法,最著名的是行为注入攻击(Profile Injection Attack)。就是注册很多账号,用这些账号同时购买某件商品A和自己的商品。此方法针对一种购物网站的推荐方法:“购买商品A的用户也经常购买的其他商品”。
一般会利用模拟攻击来评测算法的健壮性:
给定一个数据集和算法,用算法给数据集中的用户生成推荐列表;
用常用的攻击方法向数据集中注入噪声数据;
利用算法在有噪声的数据集上再次生成推荐列表;
通过比较攻击前后推荐列表的相似度评测算法的健壮性。
提高推荐系统健壮性的方法:
选择健壮性高的算法;
选择代价较高的用户行为,例如收费的用户行为(购物等)、限制用户权限(给用户分级);
在使用数据前进行攻击检测,从而对数据进行清理。
(10) 商业目标
设计推荐系统时,需要考虑最终的商业目标。不同网站具有不同的商业目标,它与网站的盈利模式息息相关。
比如电子商务网站的目标可能是销售额,基于展示广告盈利的网站其商业目标可能是广告展示总数,基于点击广告盈利的网站其商业目标可能是广告点击总数。因此,设计推荐系统时需要考虑最终的商业目标,也就是说网站使用推荐系统的目的除了满足用户发现内容的需求,同时也需要利用推荐系统加快实现商业上的指标。
1.2.3. 评判维度
增加评测维度的目的,就是知道一个算法在什么情况下性能最好,这样可以为融合不同推荐算法取得最好的整体性能带来参考。
一般评测维度分3种:
用户维度:主要包括用户的人口统计学信息、活跃度以及是不是新用户等;
物品维度:包括物品的属性信息、流行度、平均分以及是不是新加入的物品等;
时间维度:包括季节,是工作日还是周末,白天还是晚上等;
如果推荐系统的评测报告中包含了不同维度下的系统评测结果,就能帮我们全面了解系统性能,甚至找到一个看上去比较弱的算法的优势,或者发现一个看上去比较强的算法的缺点。
2. 数据来源
3. 通用推荐模型
3.1. 协同过滤推荐
3.1.1. 基于邻域的模型
基于邻域的算法分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法。
(1)基于用户的协同过滤算法 UserCF
在一个在线个性化推荐系统中,当一个用户A需要个性化推荐时,可以先找到和A有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有关注过的物品推荐给A。这种方法称为基于用户的协同过滤算法(UserCF)。
基于用户的协同过滤算法主要包括两个步骤:
找到和目标用户兴趣相似的用户集合
找到这个集合中的用户喜欢的,且目标用户没有听说过的物品,推荐给目标用户 计算用户兴趣相似度的方法有3种:
计算用户兴趣相似度的方法有3种:
(2)基于物品的协同过滤算法 ItemCF
基于物品的协同过滤算法用于给用户推荐那些与他们之前喜欢的物品相似的物品。
ItemCF算法主要通过分析用户的行为记录来计算物品之间的相似度。该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。
基于物品的协同过滤算法主要分为两步:
计算物品之间的相似度;
根据物品的相似度和用户的历史行为给用户生成推荐列表。
我们给定物品i ii、j jj,设N ( i ) N(i)N(i)为喜欢物品i ii的用户数,N ( j ) N(j)N(j)为喜欢物品j jj的用户数,则物品i ii、j jj的相似度可以表达为:
(3)UserCF 与 ItemCF 的区别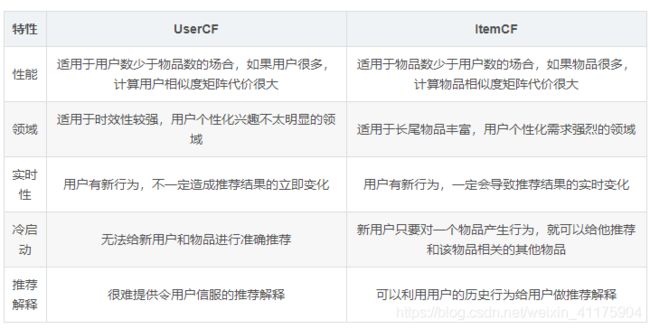
3.1.2. 隐语义模型
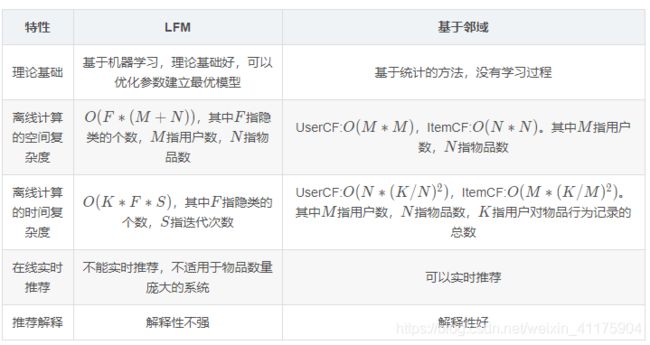
LFM(Latent Factor Model)隐语义模型的核心思想是通过隐含特征(Latent Factor)联系用户兴趣和物品,它采取基于用户行为统计的自动聚类,让用户和物品的分类自动化。
LFM通过如下公式计算用户u对物品i的兴趣:
LFM和基于领域的方法区别大致如下:
3.1.3. 基于图的模型
用户对物品的行为很容易用二分图表示,已知用户行为数据是由一系列二元组组成的,其中每个二元组( u , i ) (u, i)(u,i)表示用户u uu对物品i ii产生过行为,这样的数据可以用二分图G ( V , E )
3.2. 基于内容的推荐
基于内容推荐的原理是根据用户感兴趣的物品A,找到和A内容信息相近的物品B。内容信息是指用户和物品本身的内容特征,如用户的地理位置、性别、年龄,电影物品的导演、演员、发布时间等。比如用户喜欢看《神探夏洛克第一季》,那么就给他推荐《神探夏洛克第二季》。
基于内容推荐的优点如下:
简单、有效,推荐结果直观,容易理解,不需要领域知识;
不需要用户的历史数据,如对对象的评价等;
没有物品冷启动的问题;
没有稀疏问题;
算法成熟,如数据挖掘、聚类分析等。
基于内容的推荐的缺点如下:
特征提取能力有限
比如图像、视频,没有有效的特征提取方法。即便是文本资源,特征提取也只能反应一部分内容,难以提取内容质量,会影响用户满意度。
很难出现新的推荐结果
根据用户兴趣的喜好进行推荐,很难出现惊喜。对于时间敏感的内容,如新闻,推荐内容基本相同,体验度较差。
存在用户冷启动的问题
当新用户出现时, 系统较难获得该用户的兴趣偏好,无法进行有效推荐。
推荐对象内容分类方法需要的数据量较大
3.3. 基于关联规则的推荐
关联规则是反映一个事物与其他事物之间的相互依存性和关联性,常用于实体商店或在线电商的推荐系统:通过对顾客的购买记录数据库进行关联规则挖掘,最终目的是发现顾客群体的购买习惯的内在共性。
关联规则分析中的关键概念包括:支持度(Support)、置信度(Confidence)与提升度(Lift):
支持度 Support
支持度是两件商品A AA和B BB在总销售笔数N NN中出现的概率,即A AA与B BB同时被购买的概率
S u p p o r t ( A ∩ B ) = F r e q ( A ∩ B ) N Support(A\cap B)=\frac{Freq(A\cap B)}{N}
Support(A∩B)=
N
Freq(A∩B)
置信度 Confidence
置信度是购买A AA后再购买B BB的条件概率。简单来说就是交集部分C CC在A AA中比例,如果比例大说明购买A AA的客户很大可能会购买B BB商品
C o n f i d e n c e = F r e q ( A ∩ B ) F r e q ( A ) Confidence=\frac{Freq(A\cap B)}{Freq(A)}
Confidence=
Freq(A)
Freq(A∩B)
提升度 Lift
提升度表示先购买A对购买B的概率的提升作用,用来判断规则是否有实际价值,即使用规则后商品在购物车中出现的次数是否高于商品单独出现在购物车中的频率。如果大于1说明规则有效,小于1则无效
L i f t = S u p p o r t ( A ∩ B ) S u p p o r t ( A ) ∗ S u p p o r t ( B ) Lift=\frac{Support(A\cap B)}{Support(A)*Support (B)}
Lift=
Support(A)∗Support(B)
Support(A∩B)
例如在某电商平台上,可乐和薯片的关联规则的支持度是20%,购买可乐的支持度是3%,购买薯片的支持度是5%,则提升度为:
L i f t = 0.2 0.03 ∗ 0.05 = 1.33 Lift=\frac{0.2}{0.03*0.05}=1.33
Lift=
0.03∗0.05
0.2
=1.33
这说明购买可乐对购买薯片有提升效果。
该提升效果的置信度为:
C o n f i d e n c e = F r e q ( A ∩ B ) F r e q ( A ) = 0.2 N 0.03 N = 6.67 Confidence=\frac{Freq(A\cap B)}{Freq(A)}=\frac{0.2N}{0.03N}=6.67
Confidence=
Freq(A)
Freq(A∩B)
=
0.03N
0.2N
=6.67
3.4. 基于知识的推荐
基于知识的推荐(Knowledge-based Recommendation),主要应用于知识型的产品中,主要解决的问题是,为用户定制个性化的进阶路线图。
比如用户想学习钢琴,如果该用户是刚入门的小白,那最好从简单的谱子学起。但这样带来一个问题,由于用户的历史行为都在初级范围之内,根据兴趣偏好,推荐给用户的信息也都在初级范围,无法满足用户的进阶需求。
这个时候就需要基于知识的推荐。推荐系统知道用户现在所处的知识级别(用户知识),也知道学习钢琴所有的级别(产品知识),然后根据用户当前的情况为用户推荐合适的进阶信息。
精确的定义表达为:基于知识的推荐使用用户知识和产品知识, 通过推理什么产品能满足用户需求来产生推荐。这种推荐系统不依赖于用户评分等关于用户偏好的历史数据, 故其不存在冷启动方面的问题。基于知识的推荐系统响应用户的即时需求, 当用户偏好发生变化时不需要任何训练。
例如某论文针对海量习题带来的信息过载导致学习针对性不强、效率不高等问题,提出了基于知识点层次图的个性化习题推荐算法。
该算法首先根据课程知识点体系结构的特点,构建了表征知识点层次关系的权重图,该权重图有效反映知识点间的层次关系。然后,根据学生对知识点的掌握情况,在知识点层次图的基础上提出了一种个性化习题推荐算法。该算法通过更新学生-知识点失分率矩阵,获取学生掌握薄弱的知识点,以此实现习题推荐。
3.5. 基于标签的推荐
3.5.1. 基于标签推荐物品
拿到了用户标签行为数据之后,可以通过如下步骤设计一个推荐算法:
统计每个用户最常用的标签;
对于每个标签,统计被打过这个标签次数最多的物品;
找到一个用户常用的标签,然后找到具有这些标签的最热门物品推荐给这个用户。
在第三步中,就是要找到用户所标记标签中有哪些物品是他最感兴趣的,可以通过以下兴趣公式计算:
简单标签算法
p ( u , i ) = ∑ b n u , b n b , i p(u,i)=\sum_{b}n_{u,b}n_{b,i}
p(u,i)=
b
∑
n
u,b
n
b,i
其中,n u , b n_{u,b}n
u,b
是用户u uu打过标签b bb的次数,n b , i n_{b,i}n
b,i
是物品i ii被打过标签b bb的次数
TF-IDF标签算法
p ( u , i ) = ∑ b n u , b log ( 1 + n b ( u ) ) n b , i p(u,i)=\sum_{b}\frac{n_{u,b}}{\log(1+n_b^{(u)})}n_{b,i}
p(u,i)=
b
∑
log(1+n
b
(u)
)
n
u,b
n
b,i
其中,n b ( u ) n_b^{(u)}n
b
(u)
记录了标签b bb被多少个不同的用户使用过。这个公式可以给热门标签更小的权重,从而反应用户个性化的兴趣
改进的TF-IDF标签算法
p ( u , i ) = ∑ b n u , b log ( 1 + n b ( u ) ) n b , i log ( 1 + n i ( u ) ) p(u,i)=\sum_{b}\frac{n_{u,b}}{\log(1+n_b^{(u)})}\frac{n_{b,i}}{\log(1+n_i^{(u)})}
p(u,i)=
b
∑
log(1+n
b
(u)
)
n
u,b
log(1+n
i
(u)
)
n
b,i
其中,n i ( u ) n_i^{(u)}n
i
(u)
记录了物品i ii被多少个不同的用户打过标签。这个公式可以给热门物品更小的权重,从而反应用户个性化的兴趣。
TF-IDF 公式(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)是文本分析领域的著名公式,它用于计算词的权重:
w i = T F ( e i ) log ( I D F ( e i ) ) w_i=\frac{TF(e_i)}{\log(IDF(e_i))}
w
i
=
log(IDF(e
i
))
TF(e
i
)
其中,词 频 ( T F ) = e i 在 文 本 中 出 现 的 次 数 该 文 本 中 出 现 次 数 最 多 的 词 的 出 现 次 数 词频(TF)=\frac{e_i在文本中出现的次数}{该文本中出现次数最多的词的出现次数}词频(TF)=
该文本中出现次数最多的词的出现次数
e
i
在文本中出现的次数
,逆 文 档 频 率 ( I D F ) = log ( 文 本 总 数 包 含 该 关 键 词 的 文 本 数 + 1 ) 逆文档频率(IDF)=\log(\frac{文本总数}{包含该关键词的文本数+1})逆文档频率(IDF)=log(
包含该关键词的文本数+1
文本总数
)
众多的标签并不是一个个标签孤岛,实际上,大多数标签之间都有一定的联系,例如“强化学习”和“多臂老虎机算法”、“Q学习”三个不一样的标签相交于同一领域,为了衡量不同标签之间的相关性,我们这里介绍一种基于邻域的标签扩展方法,即对每个标签找到和它相似的标签,也就是计算标签之间的相似度。
如果认为同一个物品上的不同标签具有某种相似度,那么当两个标签同时出现在很多物品的标签集合中时,我们就可以认为这两个标签具有较大的相似度。对于标签b bb,令N ( b ) N(b)N(b)为被打上标签b bb的物品的集合,n b , i n_{b,i}n
b,i
为给物品i ii打上标签b bb的用户数,我们可以通过如下余弦相似度公式计算标签b bb和标签b ′ b'b
′
的相似度:
s i m ( b , b ′ ) = ∑ i ∈ N ( b ) ∩ N ( b ′ ) n b , i n b ′ , i ∑ i ∈ N ( b ) n b , i 2 ∑ i ∈ N ( b ′ ) n b ′ , i 2 sim(b,b')=\frac{\sum_{i\in N(b)\cap N(b')}n_{b,i}n_{b',i}}{\sqrt{\sum_{i\in N(b)}n_{b,i}^2\sum_{i\in N(b')}n_{b',i}^2}}
sim(b,b
′
)=
∑
i∈N(b)
n
b,i
2
∑
i∈N(b
′
)
n
b
′
,i
2
∑
i∈N(b)∩N(b
′
)
n
b,i
n
b
′
,i
这样的话就可以让那些含义相同的标签相互关联起来。
同时我们必须注意到,不是所有标签都能反应用户的兴趣。比如,在一个视频网站中,用户可能对一个视频打了一个表示情绪的标签,比如“不好笑”,但我们不能因此认为用户对“不好笑”有兴趣。因此我们需要进行标签清理。
标签清理的另一个重要意义在于将标签作为推荐解释。如果我们要把标签呈现给用户,将其作为给用户推荐某一个物品的解释,对标签的质量要求就很高。一般来说,标签清理有如下几种方法:
去除词频很高的停止词
去除因(词根、翻译、叫法)不同造成的同义词。
去除因分隔符造成的同义词
此外,为了控制标签的质量,很多网站也采用了让用户进行反馈的思想,即让用户告诉系统某个标签是否合适。
为了得到更好的推荐效果,我们利用图模型做基于标签数据的个性化推荐,即基于图的标签推荐算法。
该方法首先需要将用户打标签的行为表示到一张图上。在用户标签数据集上,有3种不同的元素,即用户、物品和标签,因此,我们需要定义3种不同的顶点,即用户顶点、物品顶点和标签顶点。这样就得到了一个表示用户u uu给物品i ii打了标签b bb的用户标签行为( u , i , b ) (u,i,b)(u,i,b)。
如下所示用户—物品—标签图包含3个用户(A AA、B BB、C CC)、3个物品(a aa、 b bb、c cc)和3个标签(1 11、2 22、3 33)
对应的用户标签行为列表为:
用户 标签 物品
A AA 2 22 b bb
A AA 2 22 c cc
B BB 1 11 a aa
C CC 3 33 b bb
在定义出用户—物品—标签图后,就可以利用PersonalRank算法计算所有物品节点相对于当前用户节点在图上的相关性,然后按照相关性从大到小的排序,给用户推荐排名最高的N NN个物品。
3.5.2. 给用户推荐标签
一般认为,给用户推荐标签有以下好处:
方便用户输入标签
让用户从键盘输入标签无疑会增加用户打标签的难度,这样很多用户不愿意给物品打标签,因此我们需要一个辅助工具来减小用户打标签的难度,从而提高用户打标签的参与度。
提高标签质量
同一个语义不同的用户可能用不同的词语来表示。这些同义词会使标签的词表变得很庞大,而且会使计算相似度不太准确。而使用推荐标签时,我们可以对词表进行选择,首先保证词表不出现太多的同义词,同时保证出现的词都是一些比较热门的、有代表性的词
用户u uu给物品i ii打标签时,我们有四种简单方法可以给用户推荐和物品i ii相关的标签:
PopularTags
给用户u uu推荐整个系统里最热门的标签
ItemPopularTags
给用户u uu推荐物品i ii上最热门的标签
UserPopularTags
用户u uu推荐他自己经常使用的标签
HybridPopularTags
给用户推荐物品i ii上最热门的标签,且他自己经常使用的标签,通过一个系数将两种方法的推荐结果进行线性加权,然后生成最终的推荐结果。
同样的,图模型也可以应用于标签推荐,在根据用户打标签的行为生成图之后,再利用PersonalRank算法进行排名。此时顶点的启动概率定义如下
r v ( k ) = { α , v ( k ) = v ( u ) 1 − α , v ( k ) = v ( i ) 0 , otherwise r_{v(k)} =
⎧⎩⎨α,1−α,0,v(k)=v(u)v(k)=v(i)otherwise
r
v(k)
=
⎩
⎪
⎨
⎪
⎧
α,
1−α,
0,
v(k)=v(u)
v(k)=v(i)
otherwise
也就是说,只有用户u uu和物品i ii对应的顶点有非0的启动概率,而其他顶点的启动概率都为0。
3.6. 基于社交网络的推荐
3.6.1. 给用户推荐内容
社会化推荐受到很多网站的重视,因为其有如下优点:
好友推荐可以增加推荐的信任度
好友往往是用户最信任的。用户往往不一定信任计算机的智能,但会信任好朋友的推荐;
社交网络可以缓解冷启动问题
当一个新用户通过微博或者Facebook账号登录网站时,我们可以从社交网站中获取用户的好友列表,然后给用户推荐好友在网站上喜欢的物品。从而我们可以在没有用户行为记录时就给用户提供较高质量的推荐结果。
(1)基于邻域的社会化推荐算法
最简单算法是给用户推荐好友喜欢的物品集合,设用户 u uu 对物品 i ii 的兴趣 p u i p_{ui}p
ui
,则有如下公式:
p u i = ∑ v ∈ o u t ( u ) r v i p_{ui}=\sum_{v\in out(u)}r_{vi}
p
ui
=
v∈out(u)
∑
r
vi
其中 o u t ( u ) out(u)out(u) 是用户 u uu 的好友集合,如果用户 v vv 喜欢物品 i ii,则 r v i = 1 r_{vi}=1r
vi
=1,否则 r v i = 0 r_{vi}=0r
vi
=0
不过显然的,不同的好友和用户u uu的熟悉程度和兴趣相似度是不同的。因此,我们应该在推荐算法中应该考虑好友和用户的熟悉程度以及兴趣相似度:
p u i = ∑ v ∈ o u t ( u ) w u v r v i p_{ui}=\sum_{v\in out(u)}w_{uv}r_{vi}
p
ui
=
v∈out(u)
∑
w
uv
r
vi
其中w u v w_{uv}w
uv
由两部分相似度构成,一部分是用户u uu和用户v vv的熟悉程度,另一部分是用户u uu和用户v vv的兴趣相似度,两者按照一定权重组合成w u v w_{uv}w
uv
。
用户 u uu 和用户 v vv 的熟悉程度(familiarity)描述了两个用户在现实社会中的熟悉程度,如果用户 u uu 和用户 v vv 很熟悉,那么一般来说他们应该有很多共同的好友:
f a m i l i a r i t y = ∣ o u t ( u ) ∩ o u t ( v ) ∣ ∣ o u t ( u ) ∪ o u t ( v ) ∣ familiarity=\frac{|out(u)\cap out(v)|}{|out(u)\cup out(v)|}
familiarity=
∣out(u)∪out(v)∣
∣out(u)∩out(v)∣
用户u uu和用户v vv的兴趣相似度(similarity)描述了两个用户喜欢的物品集合重合度:
s i m i l a r i t y = ∣ N ( u ) ∩ N ( v ) ∣ ∣ N ( u ) ∪ N ( v ) ∣ similarity=\frac{|N(u)\cap N(v)|}{|N(u)\cup N(v)|}
similarity=
∣N(u)∪N(v)∣
∣N(u)∩N(v)∣
其中N ( u ) N(u)N(u)是用户u uu喜欢的物品集合
(2)基于图的社会化推荐算法
图模型的优点是可以将各种数据和关系都表示到图上去,应用到社交网站中,可以找出两种关系,一种是用户对物品的兴趣关系,一种是用户之间的社交网络关系。
用户的社交网络可以表示为社交网络图,用户对物品的行为可以表示为用户物品二分图,而这两种图可以结合成一个图,例如下图中的用户顶点(圆圈)和物品顶点(方块)
在定义完图中的顶点和边后,需要定义边的权重。其中用户和用户之间边的权重可以定义为用户之间相似度的α \alphaα倍(包括熟悉程度和兴趣相似度),而用户和物品之间的权重可以定义为用户对物品喜欢程度的 β \betaβ倍。之后就可以利用PersonalRank图排序算法给每个用户生成推荐结果。
在社交网络中,除了常见的、用户和用户之间直接的社交网络关系,还有一种关系,即两个用户属于同一个社群
为了表达这种社群关系,可以加入一种节点表示社群(下图最左边一列的节点),而如果用户属于某一社群,图中就有一条边联系用户对应的节点和社群对应的节点。在建立完图模型后,我们就可以通过前面提到的基于图的推荐算法(比如PersonalRank)给用户推荐物品。
(3)信息流推荐
在大多数社交软件中,我们都可以通过信息流看到好友最近的言论,但信息流里面夹杂了很多用户并不关心的信息。基于信息流的推荐就是进一步帮助用户从信息流中挑选有用的信息。
目前最流行的信息流推荐算法是Facebook的EdgeRank,该算法综合考虑了信息流中每个会话的时间、长度与用户兴趣的相似度,它的主要思想为:
将其他用户对当前用户信息流中的会话产生过行为的行为称为edge,而一条会话的权重定义为:
∑ edges e u e w e d e \sum_{\text{edges } e}u_ew_ed_e
edges e
∑
u
e
w
e
d
e
其中:u e u_eu
e
指产生行为的用户和当前用户的相似度,这里的相似度主要是在社交网络图中的熟悉度;w e w_ew
e
指行为的权重,这里的行为包括创建、评论、like(喜欢)、打标签等。d e d_ed
e
指时间衰减参数,越早的行为对权重的影响越低。
从上面的算法描述中可以得出看出在该算法中:如果一个会话被你熟悉的好友最近产生过重要的行为,它就会有比较高的权重。
3.6.2. 给用户推荐好友
好友推荐系统的目的是根据用户现有的好友、用户的行为记录给用户推荐新的好友,从而增加整个社交网络的稠密程度和社交网站用户的活跃度。好友推荐算法在社交网络上被称为链接预测(Link Prediction),主要包括以下几种场景:
(1)基于内容的匹配
可以给用户推荐和他们有相似内容属性的用户作为好友。下面给出了常用的内容属性:
用户人口统计学属性,包括年龄、性别、职业、毕业学校和工作单位等
用户的兴趣,包括用户喜欢的物品和发布过的言论等
用户的位置信息,包括用户的住址、IP地址和邮编等
计算用户在上述内容信息上的相似度就可以找出相似的用户,然后相互推荐。
(2)基于共同兴趣的好友推荐
在Twitter和微博为代表的以兴趣图谱为主的社交网络中,用户往往不关心对于一个人是否在现实社会中认识,而只关心是否和他们有共同的兴趣爱好。因此,在这种网站中需要给用户推荐和他有共同兴趣的其他用户作为好友。
因此可以基于用户的利用协同过滤算法(UserCF)计算用户之间的兴趣相似度,其主要思想就是如果用户喜欢相同的信息和内容,则说明他们具有相似的兴趣。此外,也可以根据用户在社交网络中的发言提取用户的兴趣标签,来计算用户的兴趣相似度。
(3)基于社交网络图的好友推荐
基于好友的好友推荐算法可以用来给用户推荐他们在现实社会中互相熟悉,而在当前社交网络中没有联系的其他用户。
介绍3种基于社交网络的好友推荐算法:
指出相似度
w o u t ( u , v ) = ∣ o u t ( u ) ∩ o u t ( v ) ∣ ∣ o u t ( u ) ∣ ∣ o u t ( v ) ∣ w_{out}(u,v)=\frac{|out(u)\cap out(v)|}{\sqrt{|out(u)||out(v)|}}
w
out
(u,v)=
∣out(u)∣∣out(v)∣
∣out(u)∩out(v)∣
其中o u t ( u ) out(u)out(u)是在社交网络图中用户u uu指向的其他好友的集合
指入相似度
w i n ( u , v ) = ∣ i n ( u ) ∩ i n ( v ) ∣ ∣ i n ( u ) ∣ ∣ i n ( v ) ∣ w_{in}(u,v)=\frac{|in(u)\cap in(v)|}{\sqrt{|in(u)||in(v)|}}
w
in
(u,v)=
∣in(u)∣∣in(v)∣
∣in(u)∩in(v)∣
其中i n ( u ) in(u)in(u)是指在社交网络图中指向用户u uu的其他好友的集合
互指相似度
w o u t , i n ( u , v ) = ∣ o u t ( u ) ∩ i n ( v ) ∣ ∣ o u t ( u ) ∣ w_{out,in}(u,v)=\frac{|out(u)\cap in(v)|}{|out(u)|}
w
out,in
(u,v)=
∣out(u)∣
∣out(u)∩in(v)∣
这个相似度的含义是用户u uu指向的用户中,有多大比例也指向了用户v vv
改进的互指相似度
w o u t , i n ( u , v ) = ∣ o u t ( u ) ∩ i n ( v ) ∣ ∣ o u t ( u ) ∣ ∣ i n ( v ) ∣ w_{out,in}(u,v)=\frac{|out(u)\cap in(v)|}{\sqrt{|out(u)||in(v)|}}
w
out,in
(u,v)=
∣out(u)∣∣in(v)∣
∣out(u)∩in(v)∣
这个公式考虑了指入的因素,可以避免出现网红被当做好友被推荐过来的现象。
4. 冷启动问题
推荐系统需要根据用户的历史行为和兴趣预测用户未来的行为和兴趣,因此大量的用户行为数据就成为推荐系统的重要组成部分和先决条件。因此很多在开始阶段就希望有个性化推荐应用的网站来说,如何在没有大量用户数据的情况下设计个性化推荐系统并且让用户对推荐结果满意从而愿意使用推荐系统,就是冷启动(Cold Start)的问题。
冷启动主要分3类:
用户冷启动
用户冷启动主要解决如何给新用户做个性化推荐的问题。当新用户到来时,我们没有他的行为数据,所以也无法根据他的历史行为预测其兴趣,从而无法借此给他做个性化推荐。
物品冷启动
物品冷启动主要解决如何将新的物品推荐给可能对它感兴趣的用户这一问题。
系统冷启动
系统冷启动主要解决如何在一个新开发的网站上(物品信息远多于用户行为信息)设计个性化推荐系统,从而在网站刚发布时就让用户体验到个性化推荐服务这一问题。
对于这3类不同的冷启动问题,有不同的解决方案。一般来说,可以参考如下解决方案:
4.1. 利用用户注册信息
显而易见,利用用户的注册信息可以很好地缓解注册用户的冷启动问题。用户的注册信息分3种:
人口统计学信息
包括用户的年龄、性别、职业、民族、学历和居住地;
用户兴趣的描述
有一些网站会让用户用文字描述他们的兴趣;
站外行为数据
比如用户通过豆瓣、新浪微博的账号登录,就可以在得到用户同意的情况下获取用户在豆瓣或者新浪微博的一些行为数据和社交网络数据
基于注册信息的个性化推荐流程基本如下:
获取用户的注册信息
根据用户的注册信息对用户分类
给用户推荐他所属分类中用户喜欢的物品
如图所示新用户,资料显示他是一位28岁的男性,是一位物理学家。然后,查询3张离线计算好的相关表:
性别-电视剧相关表。从中可以查询男性最喜欢的电视剧;
年龄-电视剧相关表,从中可以查询到28岁用户最喜欢的电视剧;
职业-电视剧相关表,可以查询到物理学家最喜欢的电视剧。
然后,我们可以将用这3张相关表查询出的电视剧列表按照一定权重相加,得到给用户的最终推荐列表。
基于用户注册信息的推荐算法其核心问题是计算每种特征的用户喜欢的物品。也就是说,对于每种特征f ff,计算具有这种特征的用户对各个物品的兴趣程度p ( f , i ) p(f,i)p(f,i)。有计算两种方法:
物品 i ii 在具有 f ff 特征的用户中的热门程度
p ( f , i ) = ∣ N ( i ) ∩ U ( f ) ∣ p(f,i)=|N(i)\cap U(f)|
p(f,i)=∣N(i)∩U(f)∣
其中 N ( i ) N(i)N(i) 是喜欢物品 i ii 的用户集合,U ( f ) U(f)U(f) 是具有特征 f ff 的用户集合
喜欢物品 i ii 的用户中具有特征 f ff 的比例
p ( f , i ) = ∣ N ( i ) ∩ U ( f ) ∣ ∣ N ( i ) ∣ + α p(f,i)=\frac{|N(i)\cap U(f)|}{|N(i)|+\alpha}
p(f,i)=
∣N(i)∣+α
∣N(i)∩U(f)∣
其中,参数 α \alphaα 用于解决数据稀疏问题。比如有一个物品只被1个用户喜欢过,而这个用户刚好就有特征 f ff,那么就有 p ( f , i ) = 1 p(f,i)=1p(f,i)=1 。但是,这种情况并没有统计意义,因此我们为分母加上一个比较大的数,可以避免这样的物品产生比较大的权重。
通过p ( f , i ) p(f,i)p(f,i)我们就可以知道什么样的用户适合推荐什么样的物品,从而可以进行粗粒度推荐,在一定程度上缓解冷启动问题。
4.2. 提供非个性化推荐启动用户需求
解决用户冷启动问题的另一个方法是在新用户第一次访问推荐系统时,不立即给用户展示推荐结果,而是给用户提供一些物品,让用户反馈他们对这些物品的兴趣,用这些反馈启动用户兴趣,然后根据用户兴趣给提供个性化推荐。
一般来说,能够用来启动用户兴趣的物品需要具有以下特点:
比较热门
如果要让用户对一个物品进行反馈,就需要选用用户知晓的物品;
具有代表性和区分性
启动用户兴趣的物品不能是大众化或老少皆宜的,因为这样的物品对用户的兴趣没有区分性。;
具有多样性
在冷启动时,我们不知道用户的兴趣,而用户兴趣的可能性非常多,为了匹配多样的兴趣,我们需要提供具有很高覆盖率的启动物品集合,这些物品能覆盖几乎所有主流的用户兴趣。
上面这些因素都是选择启动物品时需要考虑的,但如何设计一个选择启动物品集合的系统呢?首先,给定一群用户,可以用这群用户对物品评分的方差来度量这群用户兴趣的一致程度。如果方差很大,说明这一群用户的兴趣不太一致,反之则说明这群用户的兴趣比较一致。令σ u ∈ U ′ \sigma_{u\in U'}σ
u∈U
′
为用户集合U ′ U'U
′
中所有评分的方差,可以通过如下方式度量一个物品的区分度D ( i ) D(i)D(i):
D ( i ) = σ u ∈ N + ( i ) + σ u ∈ N − ( i ) + σ u ∈ N ‾ ( i ) D(i)=\sigma_{u\in N^+(i)}+\sigma_{u\in N^-(i)}+\sigma_{u\in \overline N(i)}
D(i)=σ
u∈N
+
(i)
+σ
u∈N
−
(i)
+σ
u∈
N
(i)
其中,N + ( i ) N^+(i)N
+
(i)是喜欢物品i ii的用户集合, N − ( i ) N^-(i)N
−
(i)是不喜欢物品i ii的用户集合,N ‾ ( i ) \overline N(i)
N
(i)是没有对物品i ii评分的用户集合。
应用上述公式计算所有物品,就可以从中找到具有最高区分度的物品i ii,然后将用户分成3类:喜欢该物品、不喜欢该物品、未评价该物品的用户。然后对每类用户再找到最具区分度的物品,然后将每一类用户又各自分为3类,如此反复组织成一颗树。
而在用户冷启动时,我们从根节点开始询问用户对该节点物品的看法,然后根据用户的选择将用户放到不同的分枝,直到进入最后的叶子节点,此时我们就已经对用户的兴趣有了比较清楚的了解,从而可以开始对用户进行比较准确地个性化推荐。
4.3. 利用物品内容信息
物品冷启动需要解决的问题是如何将新加入的物品推荐给对它感兴趣的用户。物品冷启动在新闻网站等时效性很强的网站中非常重要,因为那些网站中时时刻刻都有新加入的物品,而且每个物品必须能够在第一时间展现给用户,否则经过一段时间后,物品的价值就大大降低了。
一般来说,物品的内容可以通过向量空间模型表示,例如对于物品d dd,由于物品的内容信息中通常包含一些关键词,所以该模型会将物品表示成一个关键词向量
d i = { ( e 1 , w 1 ) , ( e 2 , w 2 ) , . . . , ( e n , w n ) } d_i=\{(e_1,w_1),(e_2,w_2),...,(e_n,w_n)\}
d
i
={(e
1
,w
1
),(e
2
,w
2
),...,(e
n
,w
n
)}
其中, e i e_ie
i
就是关键词, w i w_iw
i
是关键词对应的权重。
在给定物品内容的关键词向量后,物品的内容相似度可以通过向量之间的余弦相似度计算:
c s i j = d i ⋅ d j ∥ d i ∥ ∥ d j ∥ cs_{ij}=\frac{d_i\cdot d_j}{\sqrt{\Vert d_i\Vert\Vert d_j \Vert}}
cs
ij
=
∥d
i
∥∥d
j
∥
d
i
⋅d
j
得到物品的相似度之后,就可以利用ItemCF算法的思想,给用户推荐和他历史上喜欢的物品内容相似的物品。
不过需要注意的是,如果内容信息不足,关键词很少或者不同,向量空间模型就很难计算出准确的相似度。例如有两篇论文,它们的标题分别是“推荐系统的动态特性”和“基于时间的协同过滤算法研究”,这两篇文章的研究方向是类似的,但是它们标题中没有一样的关键词。换句话说,这两篇文章的关键词虽然不同,但关键词所属的话题是相同的。
在这种情况下,首先需要知道文章的话题分布,然后才能准确地计算文章的相似度。如何建立文章、话题和关键词的关系是话题模型(Topic Model)研究的重点。一种成熟的话题模型是LDA(Latent Dirichlet Allocation)模型。
该模型对一篇文档产生的过程进行了建模,它的基本思想是,一个人在写一篇文档的时候,会首先想这篇文章要讨论哪些话题,然后思考这些话题应该用什么词描述,从而最终用词写成一篇文章。因此,文章和词之间是通过话题联系的。
在使用LDA计算物品的内容相似度时,我们可以先计算出物品在话题上的分布,然后利用两个物品的话题分布计算物品的相似度。比如,如果两个物品的话题分布相似,则认为两个物品具有较高的相似度,反之则认为两个物品的相似度较低。计算话题分布的相似度可以利用KL散度:
D K L ( p ∥ q ) = ∑ i p ( i ) ln p ( i ) q ( i ) D_{KL}(p\Vert q)=\sum_{i}^{}p(i)\ln\frac{p(i)}{q(i)}
D
KL
(p∥q)=
i
∑
p(i)ln
q(i)
p(i)
其中i ii是指某个物品,p pp和q qq是两个分布,D K L D_{KL}D
KL
越大说明分布的相似度越低。
4.4. 发挥专家的作用
为了在推荐系统建立时就让用户得到比较好的体验,很多系统都利用专家进行标注。例如让专家给电影进行标注,可以得到以下标注分类:
分类 描述
心情(Mood) 表示用户观看电影的心情,比如对于《功夫熊猫》观众会觉得很幽默,很兴奋
剧情(Plot) 包括电影剧情的标签
类别(Genres) 表示电影的类别,主要包括动画片、喜剧片、动作片等分类
时间(Time/Period) 电影故事发生的时间
地点(Place) 电影故事发生的地点
观众(Audience) 电影的主要观众群
获奖(Praise) 电影的获奖和评价情况
风格(Style) 功夫片、全明星阵容等
态度(Attitudes) 电影描述故事的态度
画面(Look) 电脑拍摄的画面技术,比如《功夫熊猫》是用电脑动画制作的
标记(Flag) 主要表示电影有没有暴力和色情内容
5. 推荐系统实例
5.1. 外围架构
推荐系统要发挥强大的作用,除了推荐系统本身,主要还依赖于两个条件——界面展示和用户行为数据,统称为外围架构。目前流行的推荐系统界面大致都包含如下共性:
通过一定方式展示物品
主要展示物品的标题、缩略图和介绍等
提供了推荐理由
向用户展示推荐理由可以增加用户对推荐结果的信任度
提供渠道让用户进行反馈
不断的反馈让推荐算法持续改善用户的个性化推荐体验
按照所收集用户行为数据的规模和是否需要实时存取,不同的行为数据将被存储在不同的媒介中。一般来说,需要实时存取的数据存储在数据库和缓存中,而大规模的非实时地存取数据存储在分布式文件系统(如HDFS)中。
5.2. 推荐系统架构
推荐系统联系用户和物品的方式主要有如下图所示的3种。
在第三种方法中,推荐系统需要为用户生成特征,然后对每个特征找到和特征相关的物品,从而最终生成用户的推荐列表。因而,推荐系统的核心任务就被拆解成两部分,一个是如何为给定用户生成特征,另一个是如何根据特征找到物品。
同时要考虑到,如果要在一个系统中把所有特征和任务都统筹考虑,那么系统将会非常复杂,而且很难通过配置文件方便地配置不同特征和任务的权重。因此,推荐系统需要由多个推荐引擎组成,每个推荐引擎负责一种任务,而推荐系统的任务只是将推荐引擎的结果按照一定权重或者优先级合并、排序然后返回,如下图:
这种做法有两个好处:
方便增删引擎
控制不同引擎对推荐结果的影响。
可以实现推荐引擎级别的用户反馈
每一个推荐引擎都代表了一种推荐策略,而不同的用户可能喜欢不同的推荐策略。
5.3. 推荐引擎架构
具体到每一种推荐引擎到架构,推荐引擎架构主要包括下图中到三部分:
图中A部分负责从数据库或缓存中拿到用户行为数据,通过分析不同行为,生成当前用户的特征向量,如果使用非行为特征,就不需要行为提取和分析模块了,该模块的输出就是用户特征向量。
图中B部分负责将用户的特征向量通过特征-物品相关矩阵转化为初始推荐物品列表。
图中C部分负责对初始的推荐列表进行过滤、排名等处理,从而生成该引擎的最终推荐结果。
A部分输出的特征向量一般有两种类型,一种是用户的注册信息中可以提取出来的,主要包括用户的人口统计学特征。另一种特征则主要是从用户的行为中计算出来的。
一个特征向量由特征及其权重组成,在利用用户行为计算特征向量时需要考虑以下因素
用户行为的种类
在一个网站中,用户可以对物品产生很多不同种类的行为,不同行为对物品特征的权重产生到影响不同,大多时候很难确定什么行为更加重要,一般的标准就是用户付出代价越大的行为权重越高。
用户行为产生的时间
一般来说,用户近期的行为比较重要,而用户很久之前的行为相对比较次要。
用户行为的次数
有时用户对一个物品会产生很多次行为。因此用户对同一个物品的同一种行为发生的次数也反映了用户对物品的兴趣,行为次数多的物品对应的特征权重越高。
物品的热门程度
如果用户对一个很热门的物品产生了行为,反之,如果用户对一个不热门的物品产生了行为,就说明了用户的个性需求。
对于B部分到特征-物品相关推荐而言。在得到用户的特征向量后,可以根据事先训练好的相关表和候选物品集合得到初始推荐列表。
离线相关表存储在数据库中,其存储格式如下:
src_id dst_id weight
特征ID 物品ID 权重
候选物品集合用于保证推荐结果只包含候选物品集合中的物品,即进行筛选。另外,特征—物品相关推荐模块除了给用户返回物品推荐列表,还需要给推荐列表中的每个推荐结果产生一个解释列表,表明这个物品是因为哪些特征推荐出来的。
在得到初步的推荐列表后,接着按照产品需求对结果进行过滤,过滤掉那些不符合要求的物品。
候选物品集合与过滤都可以对推荐物品进行筛选,那么应该如何选用呢?
一般来说,如果可供推荐的物品较少,那么可以考虑候选物品集合的方法。但是如果可供推荐的物品非常多,那么可以考虑在初始推荐列表中加上过滤模块筛选掉一些不满足条件的物品。
它们最主要的区别在于候选物集合会影响初始推荐列表的生成,而过滤模块是在初始推荐列表上进行操作的。过滤模块可以对推荐结果进行比候选物集合更加精细的控制。
一般来说,过滤模块会过滤掉以下物品:
用户已经产生过行为的物品
因为推荐系统的目的是帮助用户发现物品,因此没必要给用户推荐他已经知道的物品;
候选物品以外的物品
候选物品集合一般有两个来源,一个是产品需求,另一个是用户的选择,过滤模块需要过滤掉不满足这两个条件的物品
某些质量很差的物品
为了提高用户的体验,推荐系统需要给用户推荐质量好的物品,那么对于一些绝大多数用户反馈都很差的物品,推荐系统需要过滤掉。
经过过滤后的推荐结果可以在进行排名,一般排名模块需要包括很多不同的子模块,例如:
新颖性排名
新颖性排名模块的目的是给用户尽量推荐他们不知道的、长尾中的物品。例如通过使用如下公式对推荐结果中热门的物品进行降权:
p u i = p u i log ( 1 + α ⋅ p o p u l a r i t y ( i ) ) p_{ui}=\frac{p_{ui}}{\log(1+\alpha\cdot popularity(i))}
p
ui
=
log(1+α⋅popularity(i))
p
ui
此外,也可以引入内容相似度矩阵,因为内容相似度矩阵中与每个物品都相似的物品可以看作不热门物品;
内容多样性
一是可以将推荐结果按照某种物品的内容属性分成几类,然后在每个类中都选择该类中排名最高的物品进行组合;二是可以让推荐结果尽量来自不同的特征。
时间多样性
提高时间多样性最关键的地方在于保证推荐系统对用户行为响应的实时性;其次是要在用户没有新的行为时,保证推荐结果每天都有变化,一种实现方法是:记录用户曾经看过的推荐结果,然后对当前推荐结果中将已经看过的推荐结果进行降权。
用户反馈
用户反馈模块主要通过分析用户之前和推荐结果的交互日志,预测用户会对什么样的推荐结果比较感兴趣