大数据技术架构_建设大数据中台架构思考与总结
简介
本文介绍完善的大数据中台架构了解这些架构里每个部分的位置,功能和含义及背后原理及应用场景。
帮助技术与产品经理对大数据技术体系有个全面的了解。
数据中台定义:集成离线数仓与实时数仓,并以多数据源统一整合采集到kafka,再通过kafka进行离线数据仓库及实时数据仓库,并集用户标签,统一数据资产管理(对数据资产目录、元数据、数据质量、数据血缘、数据生命周期等进行管理和展示,以一种更直观的方式展现企业的数据资产,提升企业的数据意识)提供给客户以及上层领导进行数据分析、数据运营等功能。
直观框架图如下:

整个数据流程分为五个环节
从数据采集-->数据传输-->数据存储-->数据计算及查询-->数据可视化及分析。
1、数据采集
根据平台产生的日志,将数据采集后写入到HDFS,HBase,Hive ,提供后续计算流程进行消费使用。
数据来源有网络的Python爬虫数据、java后台日志数据、还有各种 API 接口及数据文件等等,汇聚到服务器本地磁盘。针对不同的数据来源有各自的采集方式,其中因为日志数据有数据量多,数据结构多样,产生环境复杂等特点,属于主要采集的对象。日志采集框架挑应用较广泛的有 Flume,Logstash进行数据采集。
Flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
主要特点:
可靠性当节点出现故障时,日志能够被传送到其他节点上而不会丢失。
可扩展性Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
可管理性
(1)所有agent和colletor由master统一管理,这使得系统便于维护。
(2)多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。
(3)用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。
(4)Flume提供了web 和shell script command两种形式对数据流进行管理。
功能可扩展性用户可以根据需要添加自己的agent,collector或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
文档丰富,社区活跃Flume 已经成为 Hadoop 生态系统的标配,它的文档比较丰富,社区比较活跃,方便我们学习。

Flume组成架构
Logstash
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
Logstash最常用于ELK(elasticsearch + logstash + kibane)logstash(收集)、elasticsearch(存储+搜索)、kibana(展示)作为日志收集器使用。
主要特点:
集中、转换和存储你的数据Logstash是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的“存储” 。首选Elasticsearch 是我们的输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
支持访问任何类型数据如:file,redis,kafka,mq
支持各种自定义插件可扩展插件生态系统,提供超过200个插件,以及创建和贡献自己的灵活性。
Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。

从两者的设计思想来看,Flume本身最初设计的目的是为了把数据传入HDFS中(并不是为了采集日志而设计,这和Logstash有根本的区别),所以理所应当侧重于数据的传输,程序员要非常清楚整个数据的路由,并且比Logstash还多了一个可靠性策略,其中channel就是用于持久化目的,数据除非确认传输到下一位置了,否则不会删除,这一步是通过事物来控制的,这样的设计使得可靠性非常好。相反,Logstash则明显侧重对数据的预处理,因为日志的字段需要大量的预处理,为解析做铺垫。
2、数据传输
应用较广泛的有Kafka,Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
应用场景如:

数据的传递,使用Flume消费Kafka数据存储到HDFS/Hbase
业务日志数据实时存储到Kafka集群,然后通过Flume Source组件实时去消费Kafka业务Topic采集数据,将消费后的数据通过Flume Sink组件发送到HDFS/Hbase进行存储。
3、数据存储
数据库存储方面,可分不同类别的数据存储组件,各类数据存储组件的设计是为满足不同场景下数据存储的需求,提供不同的数据模型抽象,以及面向在线和离线的不同的优化偏向。
比较常见的数据存储组件如下表:

存储组件的选型
做架构设计时,最大的挑战是如何对计算组件和存储组件进行选型和组合。存储组件包含数据库(又分为SQL和NoSQL两类,NoSQL下又根据各类数据模型细分为多类)、对象存储、文件存储和高速缓存等不同类别。
存储组件选型需要综合考虑数据分层、成本优化以及面向在线和离线的查询优化偏向等各种因素。平台根据不同的场景使用不同的存储组件进行数据写入、存储、查询和分析等需求。
大数据领域常用的存储组件有:
HDFS
Hadoop Distributed File System (HDFS) — Apache Hadoop 项目的一个子项目, 是一个高度容错的分布式文件系统,可以理解成HDFS一个以集群方式实现的一个文件系统,HDFS设计用于在低成本硬件上运行。HDFS 提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
使用场景如下:
HDFS不适合大量小文件的存储。
HDFS适用于高吞吐量,而不适合低时间延迟的访问。
流式读取的方式,不适合多用户写入一个文件(一个文件同时只能被一个客户端写),以及任意位置写入(不支持随机写),支持文件尾部apend操作,或者文件的覆盖操作。
HDFS更加适合写入一次,读取多次的应用场景,通过线上HDFS集群的监控,hadoop目前业务的读写比为10:1,在设计上也是考虑了这一点,读速度比较快。
HDFS 适合用来做大数据分析的底层存储服务。
HBase
HBase是一个分布式存储、数据库引擎,可以支持千万的QPS、PB级别的存储,这些都已经在生产环境验证,并且在广大的公司已经验证。
使用场景如下图:
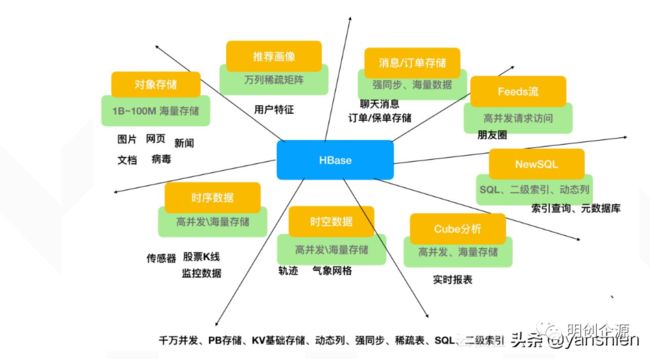
对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中。
时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求。
推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上。
时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外该技术所有大一点的数据量的车联网企业,数据都是存在HBase之中。
CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求。
消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上。
Feeds流:典型的应用就是xx朋友圈类似的应用。
NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求。
Hive
Hive最初是Facebook为了满足对海量社交网络数据的管理和机器学习的需求而产生和发展的。Hive是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析和管理。
使用场景如下:
日志分析:大部分互联网公司使用hive进行日志分析。如:统计网站一个时间段内的pv、uv及多维度数据分析等。
海量结构化数据离线分析。
ElasticSearch简称ES
ElasticSearch天然支持分布式,具备存储海量数据的能力,其搜索和数据分析的功能都建立在ElasticSearch存储的海量的数据之上。
使用场景如下:
全文检索,高亮,搜索推荐。
用户行为日志(点击,浏览,收藏,评论)+社交网络数据,数据分析。
站内搜索(电商,招聘,门户,等等)具体如:电商网站检索商品。
日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)。
商品价格监控网站。
Elasticsearch作为传统数据库的一个补充,提供了数据库所不能提供的很多功能。如:比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理。
4、数据计算及查询
数据计算
大数据计算场景可分为批处理和流处理分别对应离线分析和实时分析。
常用框架分类有:
流处理框架(实时分析):Storm,Samza。
批处理框架(离线分析):Hadoop MapReduce 简称:MR。
混合框架:Spark、Flink。
Spark
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势:
Spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。
Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍。
Spark与hadoop
Hadoop有两个核心模块,分布式存储模块HDFS和分布式计算模块Mapreduce。
spark本身并没有提供分布式文件系统,因此spark的分析大多依赖于Hadoop的分布式文件系统HDFS。
Hadoop的Mapreduce与spark都可以进行数据计算,而相比于Mapreduce,spark的速度更快并且提供的功能更加丰富。
Flink
Flink 作为更新一代的处理框架,拥有更快的计算能力,更低的延迟。
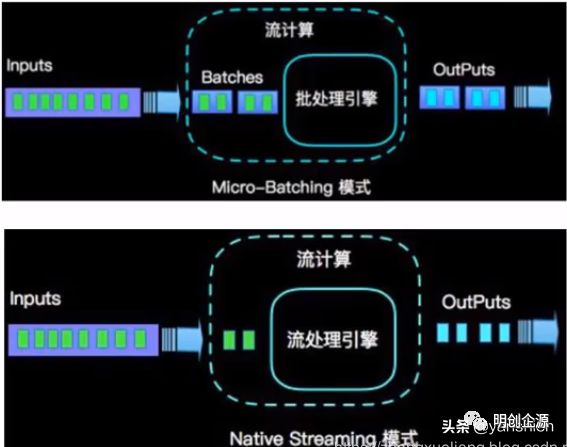
Fink与Spark Streaming 对应 流(Stream)与微批(Micro-batch)
如下图:
数据模型
spark采用RDD模型,spark streaming的DStream实际上也就是一组组小批数据RDD的集合。
fink基础数据模型是数据流,以及事件(Event)序列。
运行时架构
spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个。
fink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。
flink内部支持多种函数,其中包括窗口函数和各种算子和spark很像,但是flink在性能和实时上比 spark高。
Storm
storm流式处理,低延迟(ms级延迟),高吞吐,且每条数据都会触发计算。
Spark与storm对比, spark属于批处理转化为流处理即将流式数据根据时间切分成小批次进行计算,对比与storm而言延迟会高于0.5s(秒级延迟),但是性能上的消耗低于storm。流式计算是批次计算的特例(流式计算是拆分计算的结果)。
fink与storm对比 ,flink为流式计算而生属于每一条数据触发计算,在性能的消耗低于storm,吞吐量高于storm,延时低于storm,但比storm更加易于编写。因为storm如果要实现窗口需要自己编写逻辑,但是flink中有窗口方法。
综合对比spark、storm和flink的功能、容错和性能
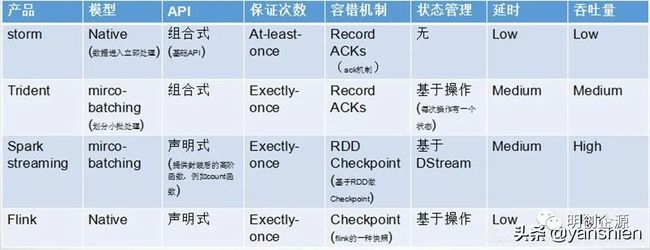
相比于storm ,spark和flink两个都支持窗口和算子,减少了不少的编程时间。
flink相比于storm和spark,flink支持乱序和延迟时间(在实际场景中,这个功能很牛逼),这个功能就可以胜spark。
对于spark而言他的优势就是机器学习,如果我们的场景中对实时要求不高可以考虑spark,但是如果是要求很高就考虑使用flink,比如对用户异常消费进行监控,如果这个场景使用spark的话那么等到系统发现开始预警的时候(0.5s),已经完成了交易,可想而知在某些场景下flink的实时有多重要。
数据查询
数据计算结果后,还需要面向用户接触和使用的高效查询引擎。
术语
ETL:也即是数据抽取、清理、装载,是数据仓库建设的核心一环。
ODS:操作数据存储 ODS(Operational Data Store)是数据仓库体系结构中的一个重要部
分,ODS 具备数据仓库的部分特征和 OLTP 系统的部分特征,主要存储原始库表同步过来的
数据以及接口上报采集过来的数据。
DW:数据仓库(Data Warehouse), 面向主题的、集成的、相对稳定的、随时间不断变
(不同时间)的数据集合。
OLAP:OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理。OLAP允许以一种称为多维数据集的结构,访问业务数据源经过聚合和组织整理后的数据。
统一数仓分层规范
ODS(贴源数据层):
对各业务系统数据进行采集、汇聚,尽可能保留原始业务流程数据,与业务系统基本保持一致,仅做简单整合、非结构化数据结构化处理或者增加标识数据日期描述信息,不做深度清洗加工。
统一拉通层:
把DW层的数据做统一的清洗处理。去重、去噪、字典翻译、空值转化,日期格式化等操作。
DWD(明细层):
和ODS粒度一致的明细数据,对数据进行去重,脏数据过滤和砍字段处理,空处理,保证
数据质量,简单逻辑通过视图实现,并解决数据的完整度问题。
DWS(服务层):
轻度汇总数据及集市大宽表(按主题)存放数据。
DIM:(维表层):
通过ods层获取得到。
应用数据ADS层(kylin/impala)
应用数据层ADS(Application Data Store):按照业务的需要从统一数仓层、标签层抽取数据,并且面向业务的特殊需要加工业务特定数据,以满足业务以及性能需求,向特定应用组装应用数据。
目前 OLAP 的查询分析框架有:
基于 HBase 做预聚合:如Kylin 等,均需指定预聚合的指标,在数据接入的时候进行聚合运算,适合相对固定,维度较多的业务报表类需求。
基于 Parquet 做列式存储:如impala 等,基本是完全基于内存的并行计算,Parquet 系能降低存储空间,提高IO效率,以离线处理为主,很难提高数据写的实时性,超大表的 Join 支持可能不够好。
标签数据层TDM
标签数据层TDM(Tag Data Model):面向对象建模,把跨业务板块、跨数据域的特定对象数据进行整合,通过ID-Mapping把各个业务板块各个业务过程同一对象的数据打通,形成对象的全域标签体系,方便深度的分析、挖掘、应用。
5、大数据应用
数据运营方面:用户画像、精准推荐、智能检索。
数据分析方面:olap报表、决策支持、可视化大屏。

大数据可视化

企业信息化专业实施与服务、自主研发智慧农旅云平台、院校实训平台建设。

明创企源:www.sxmcqy.cn
西部信息化的领航者
提供教育+培训+企业信息化解决方案
↓↓↓点击【