几种主流的数据仓库建模方法
数据仓库建模在数据仓库建设中有很重要的地位,是继业务梳理后的第二大要点,是将概念模型转化为物理模型的一个过程。关于建模一向被吹得神乎其神,相关介绍文章以及招聘需求中对此都要求很高,那么了解主流的建模方法和各自的优劣势以及应用场景就变得至关重要了。
选择合适的建模方法要考虑几点要素,分别是:性能、成本、效率和质量,性能是能够快速的查询所需的数据,减少数据IO的吞吐;成本是减少不必要的冗余,实现计算结果的复用,减少大数据系统的计算成本和存储成本;效率则是改善使用数据的效率,计算、查询效率也算在内;质量是改善数据统计口径的不一致性,减少数据计算错误的可能性,提供高质量、一致性的数据访问平台。在实际应用中则会根据这几点要素所占权重的不同来选择合适的建模方法。
ER模型
将事务抽象为“实体”、“属性”和“关系”来表示数据的关联和事物的描述,这种对事务的抽象建模通常称为 E-R 实体关系模型。数据仓库之父Bill Inmon提出的建模方法,从全企业的高度设计一个 3NF 模型,用实体关系( Entity Relationship )模型来描述企业业务,满足 3NF。
数据仓库的 3NF 与 OLTP 系统中的 3NF 的区别在于,它是站在企业角度面向主题的抽象,而不是针对某个具体的业务流程。采用 E-R模型建设数据仓库模型的出发点是整合数据,对各个系统的数据以整个企业角度按主题进行相似的组合和合并,并进行一致性处理,为数据分析决策服务,但是并不能直接用于分析决策。
作为一种标准的数据建模方案,它的实施周期非常长,一致性和扩展性比较好,能经得起时间的考验。但是随着企业数据的高速增长、复杂化,数仓如果全部使用 E-R 模型进行建模就显得越来越不适合现代化复杂、多变的业务组织,因此一般只有在数仓底层 ODS、DWD 会采用 E-R 关系模型进行设计。
维度建模
维度建模是数据仓库领域另一位大师 Ralph Kimball 所倡导,是数据仓库工程领域最流行的数仓建模经典。维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。维度建模是专门用于分析型数据库、数据仓库、数据集市建模的方法。
维度建模的主要构成是维度表和事实表。每一张维度表对应现实世界中的一个对象或者一个主题,例如:客户、产品、时间、地区等,通常是包含了多个属性的列,通常数据量不会太大;事实表则是描述业务的多条记录,包含了描述业务的度量值以及和维度表相关联的外键,外键和维度表通常是多对多的关系,数据量大而且经常发生变化。
维度建模一般包含三个,一般是根据业务需求和业务复杂性加以区分,有区分的方法但没有比较清晰地界限。分别是星型模型、雪花模型和星座模型。
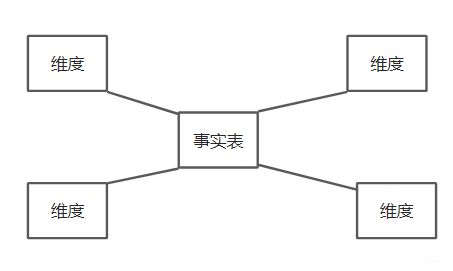
星型模型
星型模式(Star Schema)是面向主题的常用模式,主要由一个事实表和多个维度表构成,不存在二级维度表
雪花模型
雪花模型(Snowflake Schema)是在星型模型基础上将维表再次扩展,每个维表可以继续向外连接多个子维表。
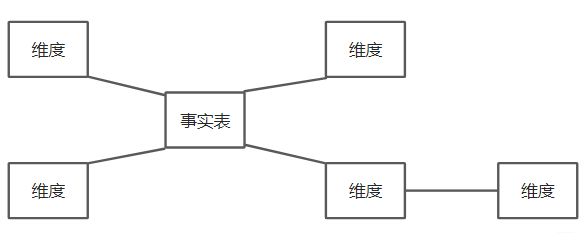
雪花模型相当于将星型模型的大维表拆分成小维表,满足了规范化设计,因为很少会有事实表只关联一层维度的,往往维度还会细分,钻取。然而这种模式在实际应用中很少见,因为跨表查询时效率很慢,所以现在的做法是将部分维度表整合到事实表中,形成宽表,在查询汇总的时候只需要group by就可以了,不需要再进行join操作。
星座模型
星座模型(Fact Constellations Schema)也是星型模型的扩展,存在多个事实表且可共用同一个维表。实际上数仓模型建设后期,大部分维度建模都是星座模型。
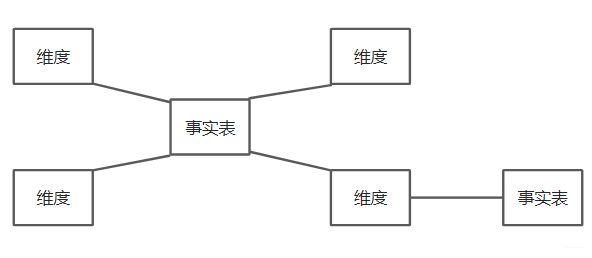
前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表可能被多个事实表用到。在业务发展的后期,绝大部分维度建模都采用的都是星座模型。
Data Vault模型
Data Vault 是 Dan Linstedt 发起创建的一种模型,它是 E-R 模型的衍生,其设计的出发点也是为了实现数据的整合,但不能直接用于数据分析决策。主要在对自然界中发现的复杂网络建模。
Data Vault 是面向细节的,可追踪历史的,一组有连接关系的规范化的表的集合。这些表可以支持一个或多个业务功能。从建模风格上看,它采用了一种由第三范式方法(3NF)与维度建模方法混合而成的方式,以二者的独特组合来满足企业需求。
同时它基于主题概念将企业数据进行结构化组织,并引入了更进一步的范式处理来优化模型,以应对源系统变更的扩展性。 Data Vault 型由以下几部分组成:
- Hub - 中心表:是企业的核心业务实体,由实体 Key、数仓序列代理键、装载时间、数据来源组成,不包含非键值以外的业务数据属性本身。
- Link - 链接表:代表 Hub 之间的关系,一个链接表意味着两个或多个中心表之间有关联。这里与 ER 模型最大的区别是将关系作为一个独立的单元抽象,可以提升模型的扩展性。它可以直接描述 1:1、1:2 和 n:n 的关系,而不需要做任何变更。它由 Hub 的代理键、装载时间、数据来源组成。
- Satellite - 卫星表:数仓中数据的主要载体,包括对链接表、中心表的数据描述、数值度量等信息。Anchor 模型
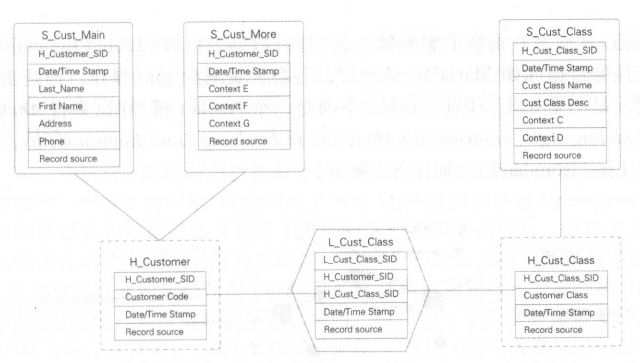
Data Vault 模型比 E-R 模型更容易设计和产出,它的 ETL 加工可实现配置化。我们可以将 Hub 想象成人的骨架,那么 Link 就是连接骨架的韧带,而 SateIIite 就是骨架上面的血肉。
Anchor模型
Anchor 是对 Data Vault 模型做了进一步的规范化处理,它的核心思想是所有的扩展只是添加而不是修改,因此将模型规范到6NF,基本变成了 k-v 结构化模型。
- Anchors :类似于
Data Vault的 Hub ,代表业务实体,且只有主键。 - Attributes :功能类似于
Data Vault的 Satellite,但是它更加规范化,将其全部 k-v 结构化, 一个表只有一个 Anchors 的属性描述。 - Ties :就是
Anchors之间的关系,单独用表来描述,类似于Data Vault的 Link ,可以提升整体模型关系的扩展能力。 - Knots :代表那些可能会在
Anchors中公用的属性的提炼,比如性别、状态等这种枚举类型且被公用的属性。
由于过度规范化,使用中牵涉到太多的Join操作,这里我们就仅作了解。
MOLAP
MOLAP区别于以上几种建模方法,适用于 ADS 层。它是将数据进行预结算,并将结果存到 CUBE 模型中,在查询的时候效率就会快很多。CUBE模型以多维数组的形式,存储在系统中,加快后续的查询,但是需要耗费巨大的时间和空间成本,维度预处理可能会导致数据膨胀。

常见的MOLAP产品有Kylin和Druid,其中Kylin使用的会比较多一点,它是将数据仓库中的数据抽取过来进行维度组合,加工成CUBE后存储到Hbase数据库(Hbase具有并发能力,所以查询性能会很高)中,业务端或者前端需要数据的时候Kylin则会从Hbase中将数据取出并返回。
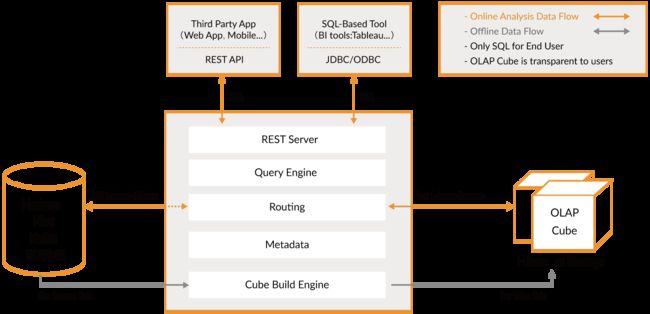
以上就是几种主流的建模方向,针对每一种建模方法还会有不少的细节问题,留到后面详细讨论。学习一项新技术就是要由上而下,由总体到局部抽丝剥茧,化繁为简。