Rook Ceph浅谈
部署rook-ceph
git clone --single-branch --branch v1.9.2 https://github.com/rook/rook.git
Network
1、osd的三个 ip 分别是
容器组ip,也就是pod ip
与 Client & monitors 对话
与其他 OSD 通信
The Ceph monitors only need access to the public network. The OSDs needs access to both public and cluster networks.
Rook framework
博文源地址

最下层 Kubelet :即 Rook 的组件是运行与 Kubelet 组件之上,以 Pod 的形式存在于 k8s 集群中;
中间层次 :这一层是逻辑实现层,运行在 k8s 集群中的 Ceph 存储节点上,包括 Ceph Daemons 、 Rook-discover 、 Ceph CSI Driver 这三种组件。Ceph Daemons 包括 Ceph 的 OSD 、 Mon 、 MGR 等组件, Rook-discover 用于存储节点上的磁盘设备发现,而 Ceph CSI Driver 组件是 k8s 存储卷管理的插件;
管理层 :即 Rook Operator for Ceph , Operator 是基于 Kubernetes 的资源和控制器概念之上构建,借助自定义的 CRD (自定义资源)来实现创建、配置和管理 Ceph ;
最上层 Client Pods:即存储资源的消费层, Client Pods 调用 Ceph CSI Driver 来实现持久化存储卷的添加 / 挂载等操作。

MON 采用主备模式( leader/follower ),即使系统中有多个 MON 角色,实际工作的也只有一个 MON ,其它 MON 都处于 standby 状态,当 Ceph 失去了 Leader MON 后,其它 MON 会基于 PaxOS 算法,投票选出新的 Leader
osd 依托于 bluestore 来管理裸设备,并在 bluestore 的基础上创建 bluefs, 再依托于 bulefs 构建 rocksdb
mgr
在Rook-Ceph中,mgr代表管理器(Manager)。mgr是一个运行在Ceph集群中的守护进程,负责监控Ceph集群的状态和性能,并提供集群管理和监控功能。
mgr可以通过REST API和命令行工具提供以下功能:
集群状态和性能监控:mgr可以提供有关Ceph集群中各种组件的实时信息,例如存储池,OSD和PG的状态,I/O操作和网络流量的性能指标等。
集群配置和管理:mgr可以管理Ceph集群的配置,例如存储池,网络配置和安全设置。管理员可以使用mgr通过REST API或命令行工具来创建,修改或删除这些配置。
群集监控:mgr可以提供有关Ceph集群的健康状况的警报和通知,并跟踪群集事件并将它们记录下来。
Dashboard:mgr提供了一个Web界面,称为Ceph Dashboard,可以显示Ceph集群的实时状态,性能指标和配置信息。管理员可以使用Ceph Dashboard来监控和管理Ceph集群。
Cleanup
官网教程地址
注意 rm -rf /var/lib/rook 和 sgdisk --zap-all $DISK
# add the cleanupPolicy
kubectl -n rook-ceph patch cephcluster rook-ceph --type merge -p '{"spec":{"cleanupPolicy":{"confirmation":"yes-really-destroy-data"}}}'
kubectl -n rook-ceph delete cephcluster rook-ceph
kubectl delete -f operator.yaml
kubectl delete -f common.yaml
kubectl delete -f crds.yaml
删除集群所有机器的 /var/lib/rook 目录
DISK="/dev/sdX"
sgdisk --zap-all $DISK
blkdiscard $DISK
partprobe $DISK
# 下面这条命令用起来没啥用
# ls /dev/mapper/ceph-* | xargs -I% -- dmsetup remove %
rm -rf /dev/ceph-*
rm -rf /dev/mapper/ceph--*
Multus 双网络
vim ceph-cluster-nad.yaml
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: rook-cluster-nw
spec:
config: '{
"cniVersion": "0.3.0",
"name": "cluster-nad",
"type": "macvlan",
"master": "eno2",
"mode": "bridge",
"ipam": {
"type": "whereabouts",
"range": "192.168.223.0/24"
}
}'
vim ceph-public-nad.yaml
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: rook-public-nw
spec:
config: '{
"cniVersion": "0.3.0",
"name": "public-nad",
"type": "macvlan",
"master": "eno1",
"mode": "bridge",
"ipam": {
"type": "whereabouts",
"range": "192.168.233.0/24"
}
}'
kubectl apply -f ceph-cluster-nad.yaml -f ceph-public-nad.yaml
vim /rook/deploy/examples/cluster.yaml
provider: multus
selectors:
public: default/rook-public-nw
cluster: default/rook-cluster-nw
理论知识

storageclass是最省心的,上面三种删除了容器存储还在

下图是管理员定义pv,用户不知道这些细节 PersistentVolume
pv会跟后端的存储rbd对接

用户通过PVC调用PV ,根据10G容量去pv里找相匹配的自动关联

上图就叫 pvc-demo

StorageClass 更厉害
管理员定义好下面

用户pvc是向storgeclass 申请多少容量,就会调用storgeclass的驱动创造pv出来,这个pv和后端存储对接
这样我们就可以在容器中调用这个pvc

动态创建就是在statefulset里面直接模板的形式,向存储类声明需要多少容量,就会自动创建pvc,pvc调用pv,pv与后端存储构建关联

Rook
rook一条命令就能部署mon osd, 自动扩容,健康检查,资源管理等等都是自动的
每种存储都对应rook专属的operator
比如monitor,k8s会通过deployment等等实现(operator实现的转换)
rook会在每个节点上装个agent,负责mount/attach(把…固定) RBD/CephFS Clients

部署
官网地址
crds 是自定义资源 common是和k8s关联授权等等
cluster.yaml 就是要创建集群了,比如mon osd rbdplugin等等,这里就可以设置网络
所有没有文件系统的盘都会加到osd里面去,如果不想这样cluster.yaml -name: "sdb"那几行就能设置
注意镜像拉不下来 k8s.gcr.io这个google国外的,

除了上面的方式,可以通过operator.yaml获取到image list
解决之道 版本要和你现在的一致,你要改一下。或者一套都直接用现成的–aliang
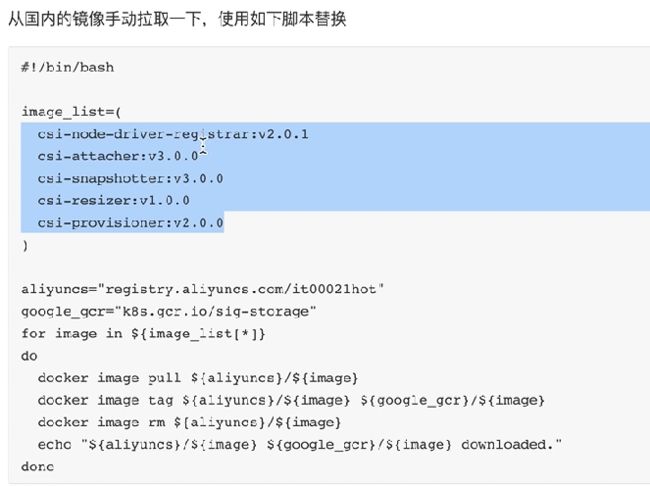
就是把google的换成aliyun的,每个节点都要执行上面的,拉取镜像
osd如果没有调度到master上,就去掉master节点的taint, vi operator.yaml 388 最低扫描集群,可以的会自动加进来,原来是60m,改成60s,kubectl apply -f operator.yaml 成功后,再改回来
Ceph 集群的管理
mon 管理集群
mgr 监控管理
mds CephFS 元数据管理
所有的都已容器的方式部署到k8s里面去了,在 rook-ceph里 kubectl get job deployment ds services -n rook-ceph
Rook Toolbox 连接ceph 集群的工具
Toolbox是一个pod,也可以理解为ceph客户端
cd rook/cluster/examples/kubernetes/
kubectl apply -f toolbox.yaml [ toolbox-job.yaml是用来跑toolbox另一种方式,一次性任务用的,我们现在用的是pod交互式模式 ]
kubectl exec -it rook-ceph-tools-xxxxx -n rook-ceph /bin/bash
进入容器后,ceph -s
ceph osd tree
ceph df
rados df
cat /etc/ceph/ceph.conf 能看到是通过 services mon 的ip地址连接的
本地连接ceph集群
把 /etc/ceph/ceph.conf和 /etc/ceph/keyring 拷到实体机其中的节点对应目录下
配ceph 源,操作系统版本对应
安装客户端 yum install ceph-common -y
运行ceph -s 这样就可以直接通信了
下图是配其他机器的shell
![]()
![]()
![]()
这样在其他机器也可以本地ceph -s
RBD的使用
# 在实体机上
# 创建pool 16个pg 和 pgd
ceph osd pool create rook 16 16
ceph osd lspools
# 在pool上创建RBD块设备
rbd create -p rook --image rook-rbd.img --size 10G
rbd ls -p rook
rbd info rook/rook-rbd.img # 这一步默认features:layering 分层,如果设置其他的,你可以自己弄
# 这样客户端就可以映射使用块
rbd map rook/rook-rbd.img # 就映射成比如/dev/rbd0这样的块设备
rbd showmapped
# 格式化块设备
mkfs.xfs /dev/rbd0
mount /dev/rbd0 /media/
定制Rook 集群
将pod落在你想要的节点上
vi cluster.yaml
# 122行 placement
# nodeAffinity: 节点亲和力调度算法。加入标签就可以让pod调度到固定标签的节点上
# podAffinity:比如将一个pod调度到另一个pod也在的那台机器上
# tolerations: 容忍pod调度到有污点的节点上
清理rook集群
在线上修改,由于之前有些元数据(/var/lib/rook 有一些osd mon的配置信息),所以不一定调度生效,所以要清理干净
还要清理到逻辑卷上的信息
官网清理地址
# 删除
kubectl delete -f operator.yaml -f cluster.yaml -f common.yaml -f crds.yaml
# 查看是否已经完全删除
kubectl get pods -n rook-ceph
kubectl get ns
# 各个节点的这个目录删掉
rm -rf /var/lib/rook/
![]()
#删除逻辑卷,所有节点
# 查看逻辑卷 卷组 pvs
lvs
vgs
pvs
vgremove ceph-xxx --yes
# 再删除pvs
pvremove /dev/vdb
# rook-ceph ns删不干净,因为有些资源还在用它
kubectl get cephclusters.ceph.rook.io -n rook-ceph
kubectl get customresourcedefinitions.apiextensions.k8s.io
kubectl edit customresourcedefinitions.apiextensions.k8s.io
# 搜到finalizers 把这两行删掉 保存 这样就删掉了
重建rook集群
重建的时候就把参数设置好,完成定制
vim cluster.yaml
# 找到 placement
# 调整mon

磁盘设置不要都用掉,我自己配置,否则我们一般在业务少的时候扩容,而他一加进来就扩容,是不行的,而且我们的每块磁盘是有它特殊的用处

然后执行
kubectl apply -f common.yaml -f crds.yaml -f cluster.yaml -f operator.yaml
发现ceph-detect一直处于pending ,describe发现没有合适node
# 查看所有node的label
kubectl get node --show-labels
# 设置一个标签
kubectl label node node-1 ceph-mon=enabled
# 那个detect就是mon,设置好标签后,就有mon running了
kubectl label node node2 node3 node1 ceph-mon=enabled --overwrite
下图为磁盘设置 cluster.yaml 操作osd, 改完apply就生效了

这样可以再加一个条件
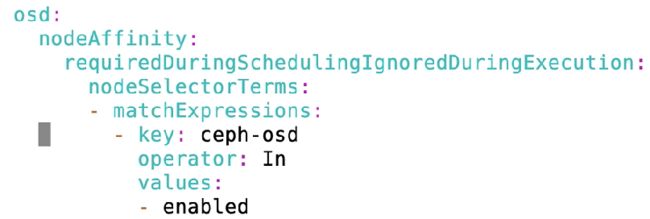
资源定制
如果mon mgr osd再一台机器上,如果比如内存不够用了,会驱逐组件的,所以要做好资源预留
mon一般需要内存128g,最少也要64g
osd一般是每T磁盘,4g内存,数据平衡时候很吃内存的
这里只是示范写法,limits和request设置成一样的,1000m就是一个cpu,没起来可能是因为分配的资源不够

healthCheck
daemonHealth是检查守护进程是否启动,disabled:false,就是不禁用,启动,间隔45s搞一次
status就是mgr,做监控用的那个
livenessProbe: 检查是否存活,默认都是开启的
一般k8s会重启pod,但是如果pod是running,pod内部有问题,就用这个健康检查

RBD块存储
k8s管理员定义好storageClass 对接后端存储,用户只需要写pvc就能自动关联storageClass,把pv挂到pod上
手工方式
下面这几个脚本依次执行kubectl apply -f ,这些官网都有
csi-rbd-sc.yaml 关联ceph集群,pool,连接集群所需要的认证信息
raw-block-pvc.yaml 通过pvc连接 sc
raw-block-pod.yaml 最终容器就可以使用pvc调用存储
rook方式
storageclass.yaml 直接创建pool ,再建storageClass,
你写的方式符合k8s规范的yaml,就叫云原生,故障域是主机,副本是3个
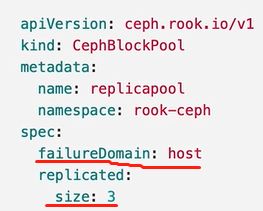
provisioner–驱动
cd csi/rbd/
# 里面有个sc.yaml,创建出pool
# 查看provisioner
kubectl get storageclasses.storage.k8s.io
# 然后创建pvc,在sc中生成空间
# 在容器里面消费pvc
# 案例就是
kubectl apply -f wordpress.yaml -f mysql.yaml
# wordpress 要连mysql,这两个应该通过pvc消费存储
ReadWriteOnce 读跟写只允许一次,只允许一个客户端来写,不支持多个客户端同时写
多个客户端同时写,要文件存储
ClusterIP表示集群内部访问即可
LoadBalancer 就是port方式

![]()
多个容器使用一个存储卷,rbd不行了
做mysql的集群,三个容器不一样的,每个容器需要自己的存储空间,保证它们的数据一致性,这种场景需要Statefulset—专门针对有状态化数据存储的,deployment就不行了。可以创建多个pod,每个pod 有独立的存储空间
副本有多少个,通过下图模板创建多少个pvc出来,并且与pod各自关联,一一对应
kubectl apply -f xxx.yaml 应用起来

对象存储
可以在k8s之上部署,Rook也可以连接在外部构建的RGW service
object.yaml 这个是副本的,如果想用纠删码就用object-ec.yaml
kind: CephObjectStore 这个资源对象是专门用来对象存储的
port:80 默认的
kubectl apply -f object.yaml

ceph osd lspools 多出几个rgw
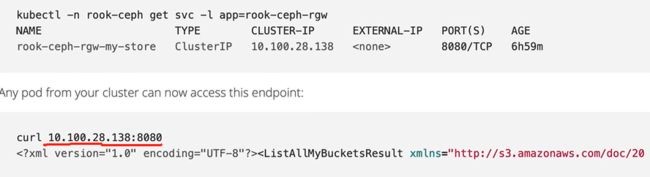
kubectl get services -n rook-ceph 得到ip:80访问对象存储
现在是一个实例,我们需要多个实例,需要负载均衡
vi object.yaml
# instances 改成2, apply -f 后会出现两个pod
# 对外提供服务的时候通过services来提供服务,自己就实现了负载均衡
kubectl get services -n rook-ceph

上图中两个地址就是pod的地址
ToomanyBuckets
因为账户权限是有限的,只能维护单个bucket. 创建权限高的用户
kubectl create -f object-user.yaml
kubectl get secrets -n rook-ceph
kubectl get secrets -n rook-ceph rook-ceph-object-user-my-store-my-user -o yaml
echo UUEwMTlCRzZHR0xxxxxxx=|base64 -d
echo YUl4elFHOE1RN1hHcllHdmVIQUhlVGFXb0FwOUFseVlxxxxxxxx==|base64 -d
RGW调度
下图上半部分是规制到某个节点上,下面是不能规制到同一节点上,因为放一个篮子里,不安全

# apply后 pod就会被删除 然后打标签后,就可以自动运行,多给几个节点打标签,否则某节点挂了,没别的地方调度了
Rook管理外部RGW存储

在k8s内部还是用service的形式对应外部集群的ip
使用RGW
先要创建Bucket
用k8s 规范书写的云原生是怎样使用RGW的呢?请看下面
用ObjectBucketClaim向 storageclass申请bucket

delete是回收的策略,bucket删除后把对应的数据删掉,这里用的create,到时你apply就行

# 查看创建出来的bucket
radosgw-admin bucket list
使用bucket
先要连接bucket
configmaps有我们要访问的地址


![]()
接着获取访问的key


这个key加密了,我们把它解密


进入到rook-ceph-tools pod里面去
安装
yum install s3cmd -y # s3客户端,访问对象存储的客户端工具
s3cmd --configure
填入解密后的双key ,Endpoint是 svc那个加上冒号80,Region默认即可
vim /root/.s3cfg
host_base = http://ip:port
host_bucket = rook-ceph-rgw-my-store.rook-ceph.svc:80/%(bucket)
![]()

Test access with supplied credentials? [Y/n] no
Save settings? [y/N] y
剩下的直接回车即可
然后往下面这里传就行了
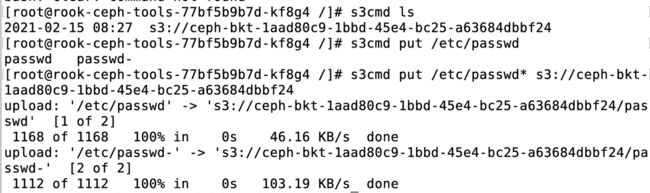
下面是get的例子

外部业务如何访问对象存储
通过NodePort形式

kubectl get service -n rook-ceph
访问哪个节点的那个端口都能访问对象存储

将node-1暂时作为客户端,在上面
yum install s3cmd -y
s3cmd --configure 接着还是那一套配置
![]()
Endpoint可以任一 一个节点的端口,不一定是node-1
![]()
![]()
上传下载还是那套东西
下面是上传一个目录
![]()
Create a user

自己就把key都给创建出来了
这个key是没有属于任何一个bucket,它是全局的

直接改 vim .s3cfg root根目录执行就可以
解密后替换掉双key
Endpoint 用外部NodePort的方式访问就行了,不用改
创建新的bucket出来

用 radosgw-admin bucket list 也能看到
查看用户
radosgw-admin user list
radosgw-admin user info --uid my-user 能看到对应的key
rgw 运维
去看rgw的pod
OSD日常管理
每个osd都是一个pod,可以通过查看pod
ceph -s 查看osd
# 可以看到每个osd属于哪个host,是 hdd还是ssd
ceph osd tree
# 查看总容量和used 的容量,
ceph osd status
ceph osd df
OSD 扩容
添加更多磁盘 osd,就是下图这么简单

添加额外的host

kubectl apply -f cluster.yaml
加osd排错
看operator pod 的日志
给node-1加标签了吗?能在上面调度osd,
资源限制后,资源还够吗?
bluestore加速
Ceph 支持两种存储引擎
Filestore 日志先写到SSD盘里面,然后数据到hdd
Bluestore WAL+DB这两个分区放到SSD 下,完成加速目的
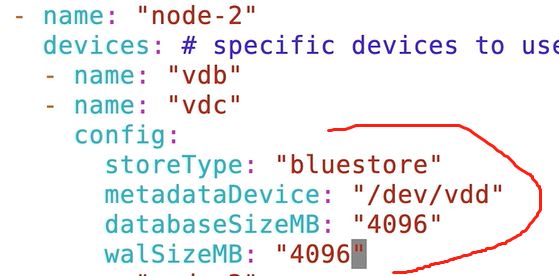
node-2上加了一块ssd盘,作为加速盘
vim cluster.yaml vdd就是ssd
Remove an OSD
OSD故障,或者重新配置osd
删除前确保有足够的空间,删除后确保ceph的状态是健康的状态,不要一次性删除多个,挨个删除
删除方法
1、云原生方式 CrashLoopBackoff 或者 error
vim osd_purge.yaml
# kind是job,运行一次的批处理脚本

如果需要删除多个,用逗号分隔开来
如下图,vim clustor.yaml 把下面参数改成true,他会定期的把坏掉的osd deployment 删掉, 你也可以手动删除

最后我们还要把cluster.yaml 里面你添加时候的 -name: "vdb"删掉
2、ceph 里就是down状态

out 删除的 crush map
ceph osd purge 5
然后ceph做数据的同步
手动delete deployment
cluster.yaml里面也删掉
apply -f cluster.yaml
Replace an OSD
先踢掉,
输 lvs
把没用的lvm删掉
再加回来
Prometheus + Grafana
dashboard只是基础的,不够
-p 前面的端口修改,就能不影响kubesphere自带的监控
docker run -d --name=grafana -p 3333:3000 grafana/grafana #--restart=always 这个命令不好用
# 部署prometheus不需要了,
#docker run -d --name=prometheus -p 9999:9090 prom/prometheus #--restart=always
kubectl get svc -n monitoring
找到 prometheus-k8s和它的端口, 将http://主机ip:port填入 datasource ,即可
注意选好你填的那个datasource
kubectl get service -n rook-ceph
# 拿到 rook-ceph-mgr 的 ClusterIP和 PORT
docker exec -it prometheus sh
vi /etc/prometheus/prometheus.yml
- job_name: 'ceph'
static_configs:
- targets: ['192.168.31.71:9283']
docker restart prometheus
2.已存在的容器配置自启
----亲试有用
docker update --restart=always 容器id 或 容器名称
另外:1)取消容器自启
docker update --restart=no 容器id 或 容器名称
http://IP:3000
默认用户名密码均为admin
- 添加Prometheus为数据源:Configuration -> Data sources -> Promethes -> 输入URL http://IP:9090
- 导入Ceph监控仪表盘:Dashboards -> Manage -> Import -> 输入仪表盘ID,加载
• Ceph-Cluster ID:2842
• Ceph-OSD ID:5336
• Ceph-Pool ID:5342
grafana ceph 模板
如果创建时未指定 --restart=always,可通过update 命令设置
docker update --restart=always 容器ID(或者容器名)