基于ES7.7 官方文档
内容包括:
- 索引的统计信息 (Index stats)
- 索引的段 (Index segments)
- 索引的恢复信息 (Index recovery)
- 索引分片的存储 (Index shard stores)
索引的统计信息 (Index stats API)
获取索引的统计信息。官方文档
GET //_stats
GET //_stats/
GET /_stats
使用索引的统计API来获取索引的高级聚合和统计信息。
默认情况下,返回的统计信息是索引级别(index-level)的,包含primaries和total聚合。 primaries只是主分片(primary shards)的信息,total是主分片和副本分片(replica shards)的累加。
要获取分片级(shard-level)的统计信息,请将level参数设置为shards。
当移动到另一个节点时,该分片的分片级统计信息将从原节点清除。 尽管该分片不再是原节点的一部分,但该原节点仍保留了这个分片的所有节点级(node-level)统计信息。
路径参数
(可选, string) 索引名称,支持多个索引名称的英文逗号分割、通配符表达式。如果要获取所有索引的统计信息,使用all或*或干脆直接忽略这个参数。
(可选, string) 索引的指标,支持多个索引名称的英文逗号分割。可选的指标包括:
all返回所有统计信息completion自动完成建议(Completion suggester) 的统计信息。是有关自动完成(auto-complete)、即时搜索(search-as-you-type)的统计信息docs文档及已删除但尚未合并的文档的数量。 索引刷新(index refreshes)会影响这个统计数据。fielddata字段数据(fielddata)的统计信息。flush刷数据到磁盘(flush)统计信息getet的统计信息, 包括丢失的(missing)统计信息。indexing索引(indexing)统计信息merge合并(merge)统计信息query_cache: 查询缓存(query cache) 统计信息refresh刷缓存数据到操作系统缓存(refresh)统计信息request_cache分片请求缓存(shard request cache)统计信息search搜索的统计信息包括建议(suggest)的统计。可以通过添加额外的参数groups(搜索操作可以与一个或多个组关联)来包含自定义组的统计信息。 参数groups接受逗号分割的组名称列表。 使用_all返回所有组的统计信息。segments所有打开的段(segments)使用的内存。 如果参数include_segment_file_sizes设置为true,该指标会包括每个Lucene索引文件的磁盘占用的总和。store索引的大小(size), 使用字节单位(byte unit)suggest[自动补全(suggester)]统计translogtranslog统计warmerwarmer统计. 注: warmers已被移除,有更好的方法替代之。
查询参数
expand_wildcards
(可选, string) 通配符查询时可以匹配的索引的条件, 多个值之间以英文逗号分割, 比如"open,hidden"。
默认open,可用的值有:
all: 匹配所有open和closed的索引, 包括隐藏的(hidden).open: 表示只匹配开放中的索引closed: 只匹配关闭的(closed)的索引hidden: 匹配隐藏的(hidden)的索引, 必须和open/closed联合使用. (官方文档说open和closed可以一起用, WAF??)none: 不接受通配符.
fields
(可选, string) 逗号分割的字段列表或者通配符表达式。
作为默认列表使用,除非参数completion_fields或fielddata_fields中指定了字段列表。
completion_fields
(可选, string) fielddata 和 suggest 统计中要包含的字段,支持逗号分割的字段列表或通配符表达式。
fielddata_fields
(可选, string) fielddata统计中包含的字段,支持逗号分割的字段列表或通配符表达式。
forbid_closed_indices
(可选, bool) 如果为true, 则统计信息不会收集已关闭的索引。默认true。
groups
(可选, string) search统计中包含的搜索群组,支持逗号分割的组名。
level
(可选, string) 规定统计信息在哪个级别聚合,级别包括: cluster, indices, shards
include_segment_file_sizes
(可选,, bool) 如果为true,将返回每个Lucene索引文件的磁盘使用情况的聚合信息(仅在请求段统计数据时应用)。 默认值为false。
include_unloaded_segments
(可选, bool) 如果为true,则响应包含未加载到内存中的段(segment)的信息。 默认false。
几个栗子
1. 获取多个索引的统计信息
# 获取索引index1和index2的统计信息
GET /index1,index2/_stats
# 获取所有以index为前缀的索引的统计信息
GET /index*/_stats
2. 获取所有索引的统计信息
# 最简单的写法
GET /_stats
# 完整的写法
GET /_all/_stats
GET /*/_stats
3. 返回指定的指标的统计信息
# 所有索引: 只返回指标`merge`和`refresh`的统计信息
GET /_stats/merge,refresh
# 索引`index`: 只返回指标`search``的统计信息
GET /index1/_stats/search
4. 获取指标search的groups的统计信息
# 获取索引`index1`的指标`search`的`groups`中的group1和group2的信息
GET /index1/_stats/search?groups=group1,group2
索引的段 (Index segments API)
返回索引分片中的Lucene段(segments)的接近底层的(low-level)信息。官方文档
GET //_segments
GET /_segments
路径参数
(可选, string) 支持英文逗号分割的列表或通配符表达式。
查询参数
allow_no_indices
(可选, bool) 默认true。如果设置为true, 则当全部使用通配符*、_all只检索不存在(missing)或者已关闭(closed)的索引(或索引别名)时,不会抛出错误。
expand_wildcards
(可选, string) 通配符查询时的范围限制。支持多个条件的逗号分割。默认open。
all: 匹配open和closed的索引, 包括隐藏的.open: 默认, 表示只查询开放中的索引closed: 只匹配closed的索引hidden: 隐藏的(hidden)索引, 必须和open/closed联合使用.none: 不接受通配符.
ignore_unavailable
(可选, bool) 如果设置为true,则 返回数据中不会包含missing或closed的索引。
默认false, 查询时只要有一个索引不存在,就会返回404并抛出错误信息。
verbose
(可选, bool) [实验中的参数,可能会改变会取消] 如果设置为true, 返回的信息中会包含Lucene内存使用的详细信息。默认false。
返回信息的主体(response body)
(string) 段的名称,比如_0,是Lucene在分片目录中创建段的文件时的文件名。
generation
(integer) 版本号的数字(generation number), 比如0。es会在每次段文件写入后增加版本号。ES使用这个版本号作为新的段名。(这个与mysql的binlog文件名的生成类似)
num_docs
(integer) 段中未被删除的文档的数量, 比如25。这个值基于Lucene文档,可能包含nested字段生成的文档。
ES 7.15版本文档中的内容却是这样的: 不包含
nested字段生成的文档, 以及刚刚被索引但是还不属于任何一个segment的文档。
deleted_docs
(integer) 段中被删除的文件数量,比如0。该数值基于Lucene文档。当一个段被合并时,ES会回收已删除的Lucene文档的磁盘空间。
ES 7.15版本文档中的内容: 不包括刚刚被删除的文档以及还不属于任何一个segment的文档。被删除的文档会由"自动合并进程(automatic merge process)"去清理(如果这个进程觉得有必要)。同时,ES会创建额外的删除文档,以便内部去跟踪一个分片上的最近的操作记录。
size_in_bytes
(integer) 段文件占用的磁盘空间,比如50kb。
memory_in_bytes
(integer) 为了提高搜索效率而缓存在内存中的段的数据的字节数,比如1264。如果无法计算字节数则会显示为-1。
search
(bool) 如果是true,则说明该段是可搜索的。如果是false,则该段很有可能是已经写入磁盘但是需要refresh后才可被搜索。
version
(string) 写入段的Lucene的版本号。
compound
(bool) 如果是true,Luncene合并了所有segment文件到一个文件中,以节约文件描述符(file descriptor)
文件描述符: Linux 系统中,把一切都看做是文件,当进程打开现有文件或创建新文件时,内核向进程返回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索引,用来指向被打开的文件,所有执行I/O操作的系统调用都会通过文件描述符。
attributes
(object) 包含了是否启用高压缩率的信息。
几个栗子
1. 从一个数据流或索引中获取段信息
GET /info/_segments
返回数据示例:
{
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"indices" : {
"info" : {
"shards" : {
"0" : [
{
"routing" : {
"state" : "STARTED",
"primary" : true,
"node" : "Yoi-NgOOT2irA04JY79nxA"
},
"num_committed_segments" : 18,
"num_search_segments" : 18,
"segments" : {
"_0" : {
"generation" : 12,
"num_docs" : 185425,
"deleted_docs" : 0,
"size_in_bytes" : 49858547,
"memory_in_bytes" : 2476,
"committed" : true,
"search" : true,
"version" : "8.5.1",
"compound" : true,
"attributes" : {
"Lucene50StoredFieldsFormat.mode" : "BEST_SPEED"
}
},
#其他的segment的信息, 段名后面部分可能是0-9,a-z, 比如: "_a", "_b","_r"
}
}
]
}
}
}
}
2. 从多个数据流或索引中获取信息
GET /info,info2/_segments
3. 获取集群中所有的数据流和索引的段信息
GET /_segments
# 下面两种不常用
GET /_all/_segments
GET /*/_segments
详细模式(verbose mode)
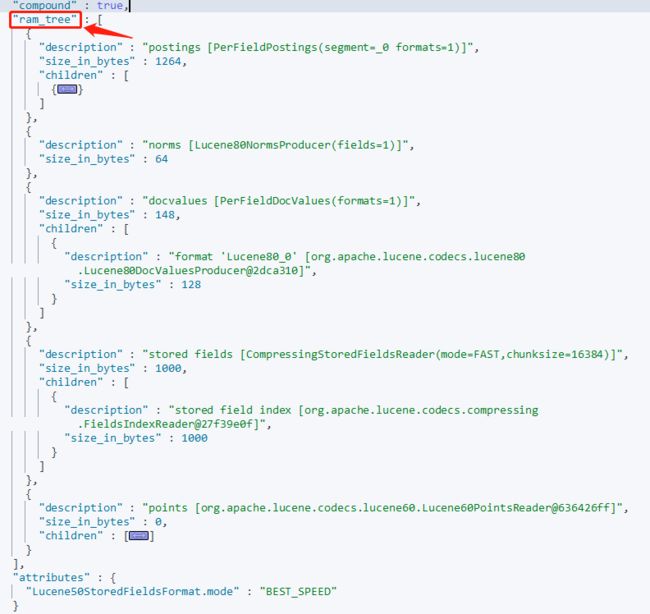
如果想要返回可用于调试(debugging)的附加信息,可以在请求参数中使用参数verbose(设置为true),返回的数据会在segments下面的segment节点数据中增加ram_tree(object):
GET /info/_segments?verbose=true
索引的恢复信息 (Index recovery API)
返回有关正在进行中和已完成的分片恢复(shard recovery)的信息。官方文档
GET //_recovery
GET /_recovery
分片恢复是从主分片同步数据到副本分片的过程。 同步过程一旦完成,该副本分片即可用来搜索。
以下过程中会自动启动恢复进程:
- 节点启动(startup)时或节点发生故障(failure)。 这种类型的恢复称为本地存储恢复(local store recovery)。
- 主分片复制(primary shard replication), 比如新增了一个主分片?。
- 将一个分片重定位到同一集群中的另外一个节点(Relocation of a shard to a different node in the same cluster)。
- 快照恢复(Snapshot restoration)。
路径参数
(可选, string) 支持多个数据流/索引/索引别名的英文逗号分割、通配符表达式。如果要获取集群中所有的数据流和索引,使用all或*或干脆直接忽略这个参数。
查询参数
active_only
(可选, bool) 如果设置为true,则只返回分片正在恢复中的数据流和索引。默认false。
detailed
(可选, bool) 如果设置为true,则返回信息中会包含分片恢复的详细信息。默认false。
index
(可选, string) 指定索引名称,支持逗号分割、通配符表达式。
返回信息的主体(response body)
id
(integer) 分片的id
type
(string) 恢复的类型。可能的值包括:
STORAGE在节点启动(startup)或节点发生故障(failure)的情况下导致的恢复。这种类型的恢复又叫本地存储恢复(local store recovery)。SNAPSHOT与快照恢复(Snapshot restoration)有关。REPLICA与主分片复制有关。RELOCATING将一个分片重定位到同一集群中的另外一个节点(the relocation of a shard to a different node in the same cluster)时。
STAGE
(string) 恢复所处的阶段。返回值包括:
INIT初始化中, 恢复任务尚未开始INDEX正在读取索引的元数据(meta data),从来源向目标复制字节(bytes, 数据)VERIFY_INDEX正在验证索引的完整性(integrity)TRANSLOG正在重放事务日志(replay transaction log)FINALIZE正在清理(cleanup)DONE已完成(complete)
primary
(bool) 是否是主分片
start_time
(string) 恢复开始时的时间戳
stop_time
(string) 恢复过程完成时的时间戳
total_time_in_millis
(string) 恢复分片所花费的时间(单位: 毫秒)
source
(object) 恢复的来源。可能包括:
- 从快照恢复时的仓库(repository)的描述。
在能使用从快照恢复之前, 必须先注册快照仓库(snapshot repository)
- 源节点的描述
target
(object) 目标节点
index
(object) 关于物理索引恢复的统计
translog
(object) 关于事务日志(translog)恢复(重放)的统计
start
(object)关于索引的打开(open)和开始(start)的时间的统计
几个栗子
1. 获取多个数据流/索引的恢复信息
GET /info,info2/_recovery?human
查询参数
human可以把时间/字节单位等格式化,以方便我们阅读,比如:
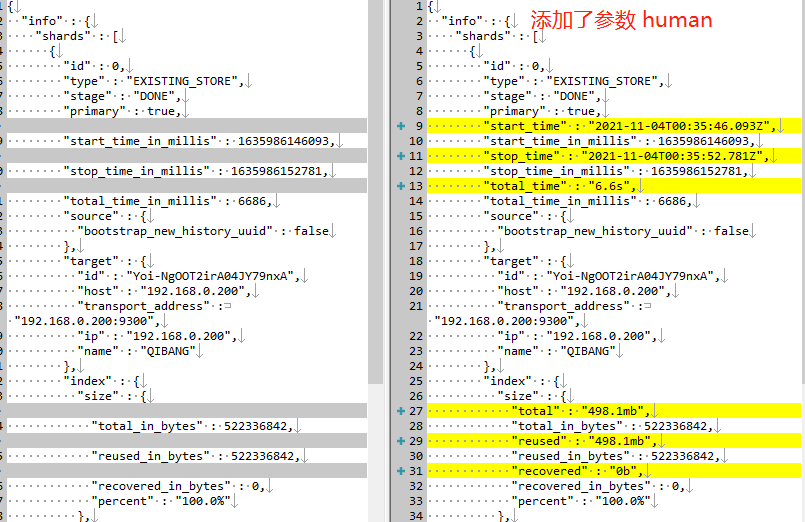
2. 获取所有索引的恢复信息
GET /_recovery?human
# 下面两种不常用
GET /_all/_recovery?human
GET /*/_recovery?human
3. 获取恢复的详细信息
如果要获取恢复的物理文件的列表,可以添加查询参数detailed并设置为true:
GET /users_new/_recovery?human&detailed=true
执行结果:
{
"users_new" : {
"shards" : [
{
"id" : 0,
"type" : "EXISTING_STORE",
"stage" : "DONE",
"primary" : true,
"start_time" : "2021-11-04T00:35:55.767Z",# human参数添加的
"start_time_in_millis" : 1635986155767,
"stop_time" : "2021-11-04T00:35:56.140Z",# human参数添加的
"stop_time_in_millis" : 1635986156140,
"total_time" : "372ms",# human参数添加的
"total_time_in_millis" : 372,
"source" : {
"bootstrap_new_history_uuid" : false
},
"target" : {
"id" : "Yoi-NgOOT2irA04JY79nxA",
"host" : "192.168.0.200",
"transport_address" : "192.168.0.200:9300",
"ip" : "192.168.0.200",
"name" : "eslocal"
},
"index" : {
"size" : {
"total" : "3.1kb",# human参数添加的
"total_in_bytes" : 3220,
"reused" : "3.1kb",# human参数添加的
"reused_in_bytes" : 3220,
"recovered" : "0b",# human参数添加的
"recovered_in_bytes" : 0,
"percent" : "100.0%"
},
"files" : {
"total" : 4,
"reused" : 4,
"recovered" : 0,
"percent" : "100.0%",
"details" : [
{
"name" : "_0.cfe",
"length" : "352b",# human参数添加的
"length_in_bytes" : 352,
"reused" : true,
"recovered" : "0b",# human参数添加的
"recovered_in_bytes" : 0
},
{
"name" : "_0.si",
"length" : "356b",# human参数添加的
"length_in_bytes" : 356,
"reused" : true,
"recovered" : "0b",# human参数添加的
"recovered_in_bytes" : 0
},
{
"name" : "_0.cfs",
"length" : "2.1kb",# human参数添加的
"length_in_bytes" : 2216,
"reused" : true,
"recovered" : "0b",# human参数添加的
"recovered_in_bytes" : 0
},
{
"name" : "segments_3",
"length" : "296b",# human参数添加的
"length_in_bytes" : 296,
"reused" : true,
"recovered" : "0b",# human参数添加的
"recovered_in_bytes" : 0
}
]
},
"total_time" : "4ms",# human参数添加的
"total_time_in_millis" : 4,
"source_throttle_time" : "-1",# human参数添加的
"source_throttle_time_in_millis" : 0,
"target_throttle_time" : "-1",# human参数添加的
"target_throttle_time_in_millis" : 0
},
"translog" : {
"recovered" : 0,
"total" : 0,
"percent" : "100.0%",
"total_on_start" : 0,
"total_time" : "320ms",# human参数添加的
"total_time_in_millis" : 320
},
"verify_index" : {
"check_index_time" : "0s",# human参数添加的
"check_index_time_in_millis" : 0,
"total_time" : "0s",# human参数添加的
"total_time_in_millis" : 0
}
}
]
}
}
返回数据中包括了任何从物理文件中恢复的列表及其文件大小。
还包括恢复的以下阶段的以毫秒为单位的执行时间:
- 获取索引 (index retrieval)
- 事务日志的重放(translog replay)
- 索引开始时间
上面的返回结果中的stage值是DONE, 表示恢复已经完成(done)。所有的恢复任务,不管是正在进行中(ongoing)还是已完成(complete)的, 都会保存在集群状态中,且可能在任何时间上报。
如果仅仅想获取正在进行中的恢复的信息,可以把查询参数active_only设置为true。
GET /users_new/_recovery?human&active_only=true&detailed=true
索引分片的存储 (Index shard stores API)
返回一个或多个索引的副本分片的存储信息。官方文档
ES7.15文档补充: 对于数据流, 会返回流的后备索引(backing indices)的存储信息。
GET //_shard_stores
GET /_shard_stores
返回的信息包括:
- 每个副本分片所在的节点
- 每个副本分片的定位id (Allocation ID)
- 每个副本分片的唯一id
- 打开分片索引时的错误,或更早的错误
默认只返回主分片未分配,或至少有一个副本分片未分配的存储信息。
文档原文: By default, the API only returns store information for primary shards that are unassigned or have one or more unassigned replica shards.
路径参数
(可选, string) 支持多个索引的英文逗号分割、通配符表达式。如果要获取集群中所有的索引,使用all或*或干脆直接忽略这个参数。
查询参数
allow_no_indices
(可选, bool) 默认true。如果设置为true, 则当全部使用通配符*、_all只检索不存在(missing)或者已关闭(closed)的索引(或索引别名)时,不会抛出错误。
expand_wildcards
(可选, string) 通配符查询时可以匹配的索引的条件, 多个值之间以英文逗号分割, 比如"open,hidden"。
默认open,可用的值有:
all: 匹配所有open和closed的索引, 包括隐藏的(hidden).open: 默认,表示只匹配开放中的索引closed: 只匹配关闭的(closed)的索引hidden: 匹配隐藏的(hidden)的索引, 必须和open/closed联合使用. (官方文档说open和closed可以一起用, WAF??)none: 不接受通配符.
ignore_unavailable
(可选, bool) 如果有索引不存在时是否忽略。
默认false,就是返回404并抛出错误信息。查询时只要有一个索引不存在,则都抛出错误。
官方文档说"If true, missing or closed indices are not included in the response." 这个与实测不同
status
(可选, string) 支持英文逗号分割的分片健康状态代码。状态代码包括:
- green 主分片和副本分片都已分配
- yellow 至少有一个副本分片未分配
- red 主分片未分配
- all 返回所有分片, 不管健康状态如何
默认是yellow,red
几个栗子
1. 获取指定素银的分片存储信息
GET /twitter/_shard_stores
如果索引没有副本分片, 则返回空对象;
如果索引不存在,则返回404状态, 抛出错误信息。
2. 同时获取多个索引的分片存储信息
GET /twitter,catalog/_shard_stores
默认不会返回没有副本的索引的信息。
如果有一个索引不存在,就会返回404状态,抛出错误信息。
3. 获取所有索引的分片存储信息
GET /_shard_stores
# 下面两种不常用
GET /_all/_shard_stores
GET /*/_shard_stores
4. 按集群健康状态获取分片存储信息
通过添加查询参数status来按健康状态过滤索引。
比如, 我们只查询主分片和副本分片都分配了的索引, 设置参数status为green:
GET /_shard_stores?status=green
也包括主分片已分配,但是没有副本分片的索引。
返回数据示例:
{
"indices" : {
"kibana_sample_data_logs" : {
"shards" : {
"0" : { # 分片id
"stores" : [ #所有分片副本的存储信息
{
"k7M9dNEARce3SKuHqNqcFA" : { #存储副本的节点id, 是一个唯一id
"name" : "ABEN_PC",
"ephemeral_id" : "OWhPg97KQiGcNJ-68gjwlQ",
"transport_address" : "127.0.0.1:9300",
"attributes" : {
"ml.machine_memory" : "16977100800",
"xpack.installed" : "true",
"transform.node" : "true",
"ml.max_open_jobs" : "20"
}
},
"allocation_id" : "oo41W9unTHqcvpJQ4T-N6Q",# 副本存储的定位id
"allocation" : "primary" #存储副本的状态: primary|replica|unused
"store_exception": .... # 开启分片时或之前有引擎错误, 会显示在这里
}
]
}
}
},
# 其他的索引信息结构一样, 省略....
}
}
last updated at 2021/11/4 21:45