MySQL优化系列11-MySQL游标和绑定变量
备注:测试数据库版本为MySQL 8.0
文章目录
- 一. MySQL游标简介
- 二.绑定变量
-
- 2.1 绑定变量的优化
- 2.2 SQL接口的绑定变量
- 2.3 绑定变量的限制
- 参考:
一. MySQL游标简介
MySQL在服务器端提供只读的、单向的游标,而且只能在存储过程或者更底层的客户端API中使用。因为MySQL游标中指向的对象都是存储在临时表中而不是实际查询到的数据,所以MySQL游标总是只读的。它可以逐行指向查询结果,然后让程序做进一步的处理。在一个存储过程中,可以有多个游标,也可以在循环中“嵌套”地使用游标。MySQL的游标设计也为粗心的人“准备”了陷阱。因为是使用临时表实现的,所以它在效率上给开发人员一个错觉。需要记住的最重要的一点是:当你打开一个游标的时候需要执行整个查询。考虑下面的存储过程:
CREATE PROCEDURE bad_cursor()
BEGIN
DECLARE film_id INT;
DECLARE f CURSOR FOR SELECT film_id FROM sakila.film;
OPEN f;
FETCH f INTO film_id;
CLOSE f;
END
从这个例子中可以看到,不用处理完所有的数据就可以立刻关闭游标。使用Oracle或者SQL Server的用户不会认为这个存储过程有什么问题,但是在MySQL中,这会带来很多的不必要的额外操作。使用SHOW STATUS来诊断这个存储过程,可以看到它需要做1000个索引页的读取,做1000个写入。这是因为在表sakila.film中有1000条记录,而所有这些读和写都发生在第五行的打开游标动作。
这个案例告诉我们,如果在关闭游标的时候你只是扫描一个大结果集的一小部分,那么存储过程可能不仅没有减少开销,相反带来了大量的额外开销。这时,你需要考虑使用LIMIT来限制返回的结果集。
游标也会让MySQL执行一些额外的I/O操作,而这些操作的效率可能非常低。因为临时内存表不支持BLOB和TEXT类型,如果游标返回的结果包含这样的列的话,MySQL就必须创建临时磁盘表来存放,这样性能可能会很糟。即使没有这样的列,当临时表大于tmp_table_size的时候,MyQL也还是会在磁盘上创建临时表。
MySQL不支持客户端的游标,不过客户端API可以通过缓存全部查询结果的方式模拟客户端的游标。这和直接将结果放在一个内存数组中来维护并没有什么不同。
二.绑定变量
从MySQL 4.1版本开始,就支持服务器端的绑定变量(prepared statement),这大大提高了客户端和服务器端数据传输的效率。你若使用一个支持新协议的客户端,如MySQL CAPI,就可以使用绑定变量功能了。另外,Java和.NET的也都可以使用各自的客户端Connector/J和Connector/NET来使用绑定变量。最后,还有一个SQL接口用于支持绑定变量,后面我们将讨论这个(这里容易引起困扰)。
当创建一个绑定变量SQL时,客户端向服务器发送了一个SQL语句的原型。服务器端收到这个SQL语句框架后,解析并存储这个SQL语句的部分执行计划,返回给客户端一个SQL语句处理句柄。以后每次执行这类查询,客户端都指定使用这个句柄。
绑定变量的SQL,使用问号标记可以接收参数的位置,当真正需要执行具体查询的时候,则使用具体值代替这些问号。例如,下面是一个绑定变量的SQL语句:
INSERT INTO tbl(col1, col2, col3) VALUES (?, ?, ?);
可以通过向服务器端发送各个问号的取值和这个SQL的句柄来执行一个具体的查询。反复使用这样的方式执行具体的查询,这正是绑定变量的优势所在。具体如何发送取值参数和SQL句柄,则和各个客户端的编程语言有关。使用Java和.NET的MySQL连接器就是一种办法。很多使用MySQL C语言链接库的客户端可以提供类似的接口,需要根据使用的编程语言的文档来了解如何使用绑定变量。
因为如下的原因,MySQL在使用绑定变量的时候可以更高效地执行大量的重复语句:
- 在服务器端只需要解析一次SQL语句。
- 在服务器端某些优化器的工作只需要执行一次,因为它会缓存一部分的执行计划。
- 以二进制的方式只发送参数和句柄,比起每次都发送ASCII码文本效率更高,一个二进制的日期字段只需要三个字节,但如果是ASCII码则需要十个字节。不过最大的节省还是来自于BLOB和TEXT字段,绑定变量的形式可以分块传输,而无须一次性传输。二进制协议在客户端也可能节省很多内存,减少了网络开销,另外,还节省了将数据从存储原始格式转换成文本格式的开销。
- 仅仅是参数——而不是整个查询语句——需要发送到服务器端,所以网络开销会更小。
- MySQL在存储参数的时候,直接将其存放到缓存中,不再需要在内存中多次复制。
绑定变量相对也更安全。无须在应用程序中处理转义,一则更简单了,二则也大大减少了SQL注入和攻击的风险。(任何时候都不要信任用户输入,即使是使用绑定变量的时候。)
可以只在使用绑定变量的时候才使用二进制传输协议。如果使用普通的mysql_query()接口则不会使用二进制传输协议。还有一些客户端让你使用绑定变量,先发送带参数的绑定SQL,然后发送变量值,但是实际上,这些客户端只是模拟了绑定变量的接口,最后还是会直接用具体值代替参数后,再使用mysql_query()发送整个查询语句。
2.1 绑定变量的优化
对使用绑定变量的SQL,MySQL能够缓存其部分执行计划,如果某些执行计划需要根据传入的参数来计算时,MySQL就无法缓存这部分的执行计划。根据优化器什么时候工作,可以将优化分为三类。在本书编写的时候,下面的三点是适用的。
- 在准备阶段
服务器解析SQL语句,移除不可能的条件,并且重写子查询。 - 在第一次执行的时候
如果可能的话,服务器先简化嵌套循环的关联,并将外关联转化成内关联。 - 在每次SQL语句执行时
服务器做如下事情:
1)过滤分区。
2)如果可能的话,尽量移除COUNT()、MIN()和MAX()。
3)移除常数表达式。
4)检测常量表。
5)做必要的等值传播。
6)分析和优化ref、range和索引优化等访问数据的方法。
7)优化关联顺序。
2.2 SQL接口的绑定变量
MySQL支持了SQL接口的绑定变量。不使用二进制传输协议也可以直接以SQL的方式使用绑定变量。下面案例展示了如何使用SQL接口的绑定变量:
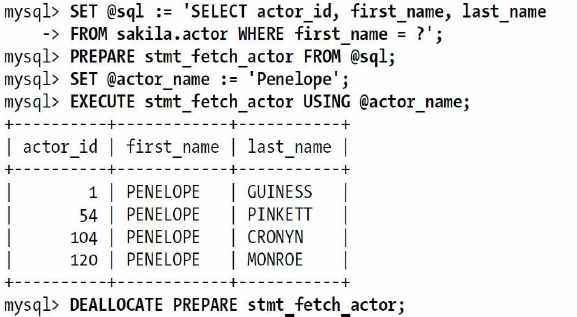
当服务器收到这些SQL语句后,先会像一般客户端的链接库一样将其翻译成对应的操作。
这意味着你无须使用二进制协议也可以使用绑定变量。
正如你看到的,比起直接编写的SQL语句,这里的语法看起来有一些怪怪的。那么,这种写法实现的绑定变量到底有什么优势呢?
最主要的用途就是在存储过程中使用。在MySQL 5.0版本中,就可以在存储过程中使用绑定变量,其语法和前面介绍的SQL接口的绑定变量类似。这意味,可以在存储过程中构建并执行“动态”的SQL语句,这里的“动态”是指可以通过灵活地拼接字符串等参数构建SQL语句。例如,下面的示例存储过程中可以针对某个数据库执行OPTIMIZE TABLE的操作:
DROP PROCEDURE IF EXISTS optimize_tables;
DELIMITER //
CREATE PROCEDURE optimize_tables(db_name VARCHAR(64))
BEGIN
DECLARE t VARCHAR(64);
DECLARE done INT DEFAULT 0;
DECLARE c CURSOR FOR
SELECT table_name FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = db_name AND TABLE_TYPE = 'BASE TABLE';
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
OPEN c;
tables_loop: LOOP
FETCH c INTO t;
IF done THEN
LEAVE tables_loop;
END IF;
SET @stmt_text := CONCAT("OPTIMIZE TABLE ", db_name, ".", t);
PREPARE stmt FROM @stmt_text;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END LOOP;
CLOSE c;
END//
DELIMITER ;
可以这样调用这个存储过程:
mysql> CALL optimize_tables('sakila')
另一种实现存储过程中循环的办法是:
REPEAT
FETCH c INTO t;
IF NOT done THEN
SET @stmt_text := CONCAT("OPTIMIZE TABLE ", db_name, ".", t);
PREPARE stmt FROM @stmt_text;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END IF;
UNTIL done END REPEAT;
这两种循环结构最重要的区别在于:REPEAT会为每个循环检查两次循环条件。在这个例子中,因为循环条件检查的是一个整数判断,并不会有什么性能问题,如果循环的判断条件非常复杂的话,则需要注意这两者的区别。
像这样使用SQL接口的绑定变量拼接表名和库名是很常见的,这样的好处是无须使用任何参数就能完成SQL语句。而库名和表名都是关键字,在二进制协议的绑定变量中是不能将这两部分参数化的。另一个经常需要动态设置的就是LIMIT子句,因为二进制协议中也无法将这个值参数化。
另外,编写存储过程时,SQL接口的绑定变量通常可以很大程度地帮助我们调试绑定变量,如果不是在存储过程中,SQL接口的绑定变量就不是那么有用了。因为SQL接口的绑定变量,它既没有使用二进制传输协议,也没有能够节省带宽,相反还总是需要增加至少一次额外网络传输才能完成一次查询。所有只有在某些特殊的场景下SQL接口的绑定变量才有用,比如当SQL语句非常非常长,并且需要多次执行的时候。
2.3 绑定变量的限制
关于绑定变量的一些限制和注意事项如下:
- 绑定变量是会话级别的,所以连接之间不能共用绑定变量句柄。同样地,一旦连接断开,则原来的句柄也不能再使用了。(连接池和持久化连接可以在一定程度上缓解这个问题。)
- 在MySQL 5.1版本之前,绑定变量的SQL是不能使用查询缓存的。
- 并不是所有的时候使用绑定变量都能获得更好的性能。如果只是执行一次SQL,那么使用绑定变量方式无疑比直接执行多了一次额外的准备阶段消耗,而且还需要一次额外的网络开销。(要正确地使用绑定变量,还需要在使用完成后,释放相关的资源。)
- 当前版本下,还不能在存储函数中使用绑定变量(但是存储过程中可以使用)。
- 如果总是忘记释放绑定变量资源,则在服务器端很容易发生资源“泄漏”。绑定变量 SQL总数的限制是一个全局限制,所以某一个地方的错误可能会对所有其他的线程都产生影响。
- 有些操作,如BEGIN,无法在绑定变量中完成。
不过使用绑定变量最大的障碍可能是:它是如何实现以及原理是怎样的,这两点很容易让人困惑。有时,很难解释如下三种绑定变量类型之间的区别是什么:
- 客户端模拟的绑定变量
客户端的驱动程序接收一个带参数的SQL,再将指定的值带入其中,最后将完整的查询发送到服务器端。 - 服务器端的绑定变量
客户端使用特殊的二进制协议将带参数的字符串发送到服务器端,然后使用二进制协议将具体的参数值发送给服务器端并执行。 - SQL接口的绑定变量
客户端先发送一个带参数的字符串到服务器端,这类似于使用PREPARE的SQL语句,然后发送设置参数的SQL,最后使用EXECUTE来执行SQL。所有这些都使用普通的文本传输协议。
参考:
- 《高性能MySQL》