python情感分析实例
运行结果,代码及所用的图片,以及运行的的数据放到我的资源里面

数据爬取
import requests
from lxml import etree
import time
if __name__ == "__main__":
fp = open('./comment.csv',mode = 'w',encoding='utf-8')
fp .write('author\tp\tvote\n')
url = 'https://movie.douban.com/subject/35051512/comments?start=%d&limit=20&status=P&sort=new_score'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'Accept-Encoding':'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
#'Cookie': '', #用自己浏览器上面的cookie,注释这条也可以运行
'Host': 'movie.douban.com',
'Pragma': 'no-cache',
'Referer': 'https://movie.douban.com/subject/35051512/?from=playing_poster',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
}
for i in range(26):
if i == 25:
url_climb = url % (490)
else:
url_climb = url % (i * 20)
response = requests.get(url=url_climb, headers=headers)
response.encoding = 'utf-8'
text = response.text
html = etree.HTML(text)
comments = html.xpath('//div[@id="comments"]/div[@class="comment-item "]')
for comment in comments:
# 作者
author = comment.xpath('./div[@class="avatar"]/a/@title')[0]
p = comment.xpath('.//span[@class="short"]/text()')[0]
# 点赞
vote = comment.xpath('.//span[@class="votes vote-count"]/text()')[0].strip()
fp.write('%s\t%s\t%s\n'%(author,p,vote))
print('第%d页数据保存成功'%(i+1))
time.sleep(1)
fp.close()
情感分析
import pandas as pd
from snownlp import SnowNLP
#该方法的作用将评论,进行情感分析
def convert(comment):
snow = SnowNLP(str(comment))
sentiments = snow.sentiments #0(消极)————1(积极)
return sentiments
if __name__ == "__main__":
data = pd.read_csv('./comment1.csv','\t')
#获取评论数据,进行情感分析,DataFtame新增加一列
#属性名:情感分析
data['情感评分'] = data.p.apply(convert)
data.sort_values(by = '情感评分',ascending=False,inplace=True)
data.to_csv('./comment_snownlp.csv',sep = '\t',index = False)
分片提取,jieba分析词语重要性,绘制词语柱状图,和词云
import pandas as pd
import jieba
from jieba import analyse
import matplotlib.pyplot as plt
import numpy as np
import wordcloud
from PIL import Image
if __name__ == "__main__":
data = pd.read_csv('./comment1.csv',sep='\t')
#获取评论信息
comments = ';'.join([str(c) for c in data['p'].tolist()])
#使用jieba库对文本内容进行分词
gen = jieba.cut(comments)
words = ' '.join(gen)
#对分好词,进行jieba分析
tags = analyse.extract_tags(words,topK=500,withWeight=True)
word_result = pd.DataFrame(tags,columns=['词语','重要性'])
word_result.sort_values(by = '重要性',ascending=False,inplace=True)#从大到小排序
#可视化,选取20个
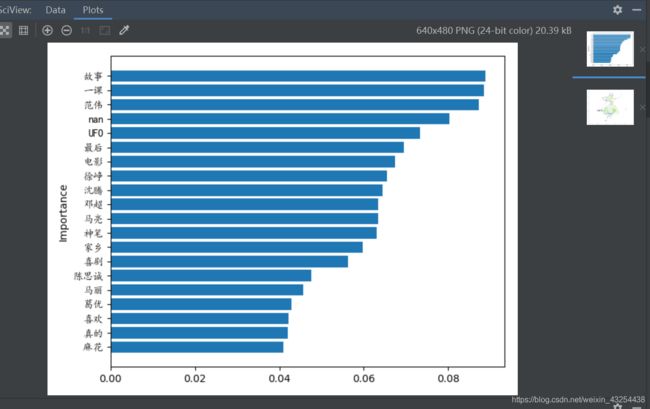
plt.barh(y = np.arange(0,20),width =word_result[:20]['重要性'][::-1])
plt.ylabel('Importance')
plt.yticks(np.arange(0,20),labels=word_result[:20]['词语'][::-1],fontproperties='KaiTi')
plt.show()
#词云操作
person = np.array(Image.open('./111.jpg'))
#将tags,jieba分词提取出数据,dict词典
words = dict(tags)
cloud=wordcloud.WordCloud(width=1200,height=968,font_path='./simkai.ttf',background_color='white',
mask=person,max_words=500,max_font_size=150,)
word_cloud = cloud.generate_from_frequencies(words)
plt.figure(figsize=(12,12))
plt.imshow(word_cloud)
plt.show()