K8s集群的部署
文章目录
-
- Kubernetes介绍
-
-
- 背景介绍
- 什么是kubernetes
- Kubernetes优势
- Kubernetes的核心概念
- Kubernetes架构和组件
-
- 架构
- 组件
-
- 实验准备
- 实验步骤
官方文档,参考: https://kubernetes.io/zh/docs/setup/independent/install-kubeadm/
swarm与Kubernetes 的对比参考: https://blog.csdn.net/meltsnow/article/details/95913308
Kubernetes介绍
背景介绍
云计算飞速发展
- IaaS
- PaaS
- SaaS
Docker技术突飞猛进
- 一次构建,到处运行
- 容器的快速轻量
- 完整的生态环境
什么是kubernetes
- 首先,他是一个全新的基于容器技术的分布式架构领先方案。Kubernetes(k8s)是Google开源的容器集群管理系统(谷歌内部:Borg)。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性。
- Kubernetes是一个完备的分布式系统支撑平台,具有完备的集群管理能力,多扩多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和发现机制、內建智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制以及多粒度的资源配额管理能力。同时Kubernetes提供完善的管理工具,涵盖了包括开发、部署测试、运维监控在内的各个环节。
- Kubernetes中,Service是分布式集群架构的核心,一个Service对象拥有如下关键特征:
拥有一个唯一指定的名字
拥有一个虚拟IP(Cluster IP、Service IP、或VIP)和端口号
能够体统某种远程服务能力
被映射到了提供这种服务能力的一组容器应用上 - Service的服务进程目前都是基于Socket通信方式对外提供服务,比如Redis、Memcache、MySQL、Web Server,或者是实现了某个具体业务的一个特定的TCP Server进程,虽然一个Service通常由多个相关的服务进程来提供服务,每个服务进程都有一个独立的Endpoint(IP+Port)访问点,但Kubernetes能够让我们通过服务连接到指定的Service上。有了Kubernetes内建的透明负载均衡和故障恢复机制,不管后端有多少服务进程,也不管某个服务进程是否会由于发生故障而重新部署到其他机器,都不会影响我们对服务的正常调用,更重要的是这个Service本身一旦创建就不会发生变化,意味着在Kubernetes集群中,我们不用为了服务的IP地址的变化问题而头疼了。
- 容器提供了强大的隔离功能,所有有必要把为Service提供服务的这组进程放入容器中进行隔离。为此,Kubernetes设计了Pod对象,将每个服务进程包装到相对应的Pod中,使其成为Pod中运行的一个容器。为了建立Service与Pod间的关联管理,Kubernetes给每个Pod贴上一个标签Label,比如运行MySQL的Pod贴上name=mysql标签,给运行PHP的Pod贴上name=php标签,然后给相应的Service定义标签选择器Label Selector,这样就能巧妙的解决了Service于Pod的关联问题。
- 在集群管理方面,Kubernetes将集群中的机器划分为一个Master节点和一群工作节点Node,其中,在Master节点运行着集群管理相关的一组进程kube-apiserver、kube-controller-manager和kube-scheduler,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理能力,并且都是全自动完成的。Node作为集群中的工作节点,运行真正的应用程序,在Node上Kubernetes管理的最小运行单元是Pod。Node上运行着Kubernetes的kubelet、kube-proxy服务进程,这些服务进程负责Pod的创建、启动、监控、重启、销毁以及实现软件模式的负载均衡器。
- 在Kubernetes集群中,它解决了传统IT系统中服务扩容和升级的两大难题。你只需为需要扩容的Service关联的Pod创建一个Replication Controller简称(RC),则该Service的扩容及后续的升级等问题将迎刃而解。在一个RC定义文件中包括以下3个关键信息。
- 目标Pod的定义
- 目标Pod需要运行的副本数量(Replicas)
- 要监控的目标Pod标签(Label)
- 在创建好RC后,Kubernetes会通过RC中定义的的Label筛选出对应Pod实例并实时监控其状态和数量,如果实例数量少于定义的副本数量,则会根据RC中定义的Pod模板来创建一个新的Pod,然后将新Pod调度到合适的Node上启动运行,知道Pod实例的数量达到预定目标,这个过程完全是自动化。
Kubernetes优势
- 容器编排
- 轻量级
- 开源
- 弹性伸缩
- 负载均衡
Kubernetes的核心概念
1.Master
k8s集群的管理节点,负责管理集群,提供集群的资源数据访问入口。拥有Etcd存储服务(可选),运行Api Server进程,Controller Manager服务进程及Scheduler服务进程,关联工作节点Node。Kubernetes API server提供HTTP Rest接口的关键服务进程,是Kubernetes里所有资源的增、删、改、查等操作的唯一入口。也是集群控制的入口进程;Kubernetes Controller Manager是Kubernetes所有资源对象的自动化控制中心;Kubernetes Schedule是负责资源调度(Pod调度)的进程
2.Node
Node是Kubernetes集群架构中运行Pod的服务节点(亦叫agent或minion)。Node是Kubernetes集群操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机。关联Master管理节点,拥有名称和IP、系统资源信息。运行docker eninge服务,守护进程kubelet及负载均衡器kube-proxy.
每个Node节点都运行着以下一组关键进程
kubelet:负责对Pod对于的容器的创建、启停等任务
kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件
Docker Engine(Docker):Docker引擎,负责本机容器的创建和管理工作
Node节点可以在运行期间动态增加到Kubernetes集群中,默认情况下,kubelet会向master注册自己,这也是Kubernetes推荐的Node管理方式,kubelet进程会定时向Master汇报自身情报,如操作系统、Docker版本、CPU和内存,以及有哪些Pod在运行等等,这样Master可以获知每个Node节点的资源使用情况,并实现高效均衡的资源调度策略。
3.Pod
运行于Node节点上,若干相关容器的组合。Pod内包含的容器运行在同一宿主机上,使用相同的网络命名空间、IP地址和端口,能够通过localhost进行通。Pod是Kurbernetes进行创建、调度和管理的最小单位,它提供了比容器更高层次的抽象,使得部署和管理更加灵活。一个Pod可以包含一个容器或者多个相关容器。
Pod其实有两种类型:普通Pod和静态Pod,后者比较特殊,它并不存在Kubernetes的etcd存储中,而是存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动。普通Pod一旦被创建,就会被放入etcd存储中,随后会被Kubernetes Master调度到某个具体的Node上进行绑定,随后该Pod被对应的Node上的kubelet进程实例化成一组相关的Docker容器并启动起来,在默认情况下,当Pod里的某个容器停止时,Kubernetes会自动检测到这个问起并且重启这个Pod(重启Pod里的所有容器),如果Pod所在的Node宕机,则会将这个Node上的所有Pod重新调度到其他节点上。
4.Replication Controller
Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。集群中副本的数量大于指定数量,则会停止指定数量之外的多余容器数量,反之,则会启动少于指定数量个数的容器,保证数量不变。Replication Controller是实现弹性伸缩、动态扩容和滚动升级的核心。
5.Service
Service定义了Pod的逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了一个统一的服务访问入口以及服务代理和发现机制,关联多个相同Label的Pod,用户不需要了解后台Pod是如何运行。
外部系统访问Service的问题
首先需要弄明白Kubernetes的三种IP这个问题
Node IP:Node节点的IP地址
Pod IP: Pod的IP地址
Cluster IP:Service的IP地址
首先,Node IP是Kubernetes集群中节点的物理网卡IP地址,所有属于这个网络的服务器之间都能通过这个网络直接通信。这也表明Kubernetes集群之外的节点访问Kubernetes集群之内的某个节点或者TCP/IP服务的时候,必须通过Node IP进行通信
其次,Pod IP是每个Pod的IP地址,他是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络。
最后Cluster IP是一个虚拟的IP,但更像是一个伪造的IP网络,原因有以下几点:
Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配P地址
Cluster IP无法被ping,他没有一个“实体网络对象”来响应
Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备通信的基础,并且他们属于Kubernetes集群这样一个封闭的空间。
Kubernetes集群之内,Node IP网、Pod IP网于Cluster IP网之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊路由规则。
6.Label
Kubernetes中的任意API对象都是通过Label进行标识,Label的实质是一系列的Key/Value键值对,其中key于value由用户自己指定。Label可以附加在各种资源对象上,如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去。Label是Replication Controller和Service运行的基础,二者通过Label来进行关联Node上运行的Pod。
我们可以通过给指定的资源对象捆绑一个或者多个不同的Label来实现多维度的资源分组管理功能,以便于灵活、方便的进行资源分配、调度、配置等管理工作。
一些常用的Label如下:
版本标签:"release":"stable","release":"canary"......
环境标签:"environment":"dev","environment":"qa","environment":"production"
架构标签:"tier":"frontend","tier":"backend","tier":"middleware"
分区标签:"partition":"customerA","partition":"customerB"
质量管控标签:"track":"daily","track":"weekly"
Label相当于我们熟悉的标签,给某个资源对象定义一个Label就相当于给它大了一个标签,随后可以通过Label Selector(标签选择器)查询和筛选拥有某些Label的资源对象,Kubernetes通过这种方式实现了类似SQL的简单又通用的对象查询机制。
Label Selector在Kubernetes中重要使用场景如下:
kube-Controller进程通过资源对象RC上定义Label Selector来筛选要监控的Pod副本的数量,从而实现副本数量始终符合预期设定的全自动控制流程
kube-proxy进程通过Service的Label Selector来选择对应的Pod,自动建立起每个Service到对应Pod的请求转发路由表,从而实现Service的智能负载均衡
通过对某些Node定义特定的Label,并且在Pod定义文件中使用Nodeselector这种标签调度策略,kube-scheduler进程可以实现Pod”定向调度“的特性
Kubernetes架构和组件
架构
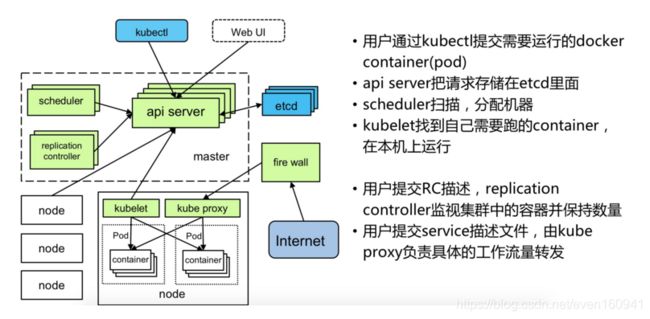
组件
- Kubernetes Master控制组件,调度管理整个系统(集群),包含如下组件:
1.Kubernetes API Server
作为Kubernetes系统的入口,其封装了核心对象的增删改查操作,以RESTful API接口方式提供给外部客户和内部组件调用。维护的REST对象持久化到Etcd中存储。
2.Kubernetes Scheduler
为新建立的Pod进行节点(node)选择(即分配机器),负责集群的资源调度。组件抽离,可以方便替换成其他调度器。
3.Kubernetes Controller
负责执行各种控制器,目前已经提供了很多控制器来保证Kubernetes的正常运行。 - Replication Controller
管理维护Replication Controller,关联Replication Controller和Pod,保证Replication Controller定义的副本数量与实际运行Pod数量一致。 - Node Controller
管理维护Node,定期检查Node的健康状态,标识出(失效|未失效)的Node节点。 - Namespace Controller
管理维护Namespace,定期清理无效的Namespace,包括Namesapce下的API对象,比如Pod、Service等。 - Service Controller
管理维护Service,提供负载以及服务代理。 - EndPoints Controller
管理维护Endpoints,关联Service和Pod,创建Endpoints为Service的后端,当Pod发生变化时,实时更新Endpoints。 - Service Account Controller
管理维护Service Account,为每个Namespace创建默认的Service Account,同时为Service Account创建Service Account Secret。 - Persistent Volume Controller
管理维护Persistent Volume和Persistent Volume Claim,为新的Persistent Volume Claim分配Persistent Volume进行绑定,为释放的Persistent Volume执行清理回收。 - Daemon Set Controller
管理维护Daemon Set,负责创建Daemon Pod,保证指定的Node上正常的运行Daemon Pod。 - Deployment Controller
管理维护Deployment,关联Deployment和Replication Controller,保证运行指定数量的Pod。当Deployment更新时,控制实现Replication Controller和 Pod的更新。 - Job Controller
管理维护Job,为Jod创建一次性任务Pod,保证完成Job指定完成的任务数目 - Pod Autoscaler Controller
实现Pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行Pod的伸缩动作。
- Kubernetes Node运行节点,运行管理业务容器,包含如下组件:
- Kubelet
负责管控容器,Kubelet会从Kubernetes API Server接收Pod的创建请求,启动和停止容器,监控容器运行状态并汇报给Kubernetes API Server。 - Kubernetes Proxy
负责为Pod创建代理服务,Kubernetes Proxy会从Kubernetes API Server获取所有的Service信息,并根据Service的信息创建代理服务,实现Service到Pod的请求路由和转发,从而实现Kubernetes层级的虚拟转发网络。 - Docker
Node上需要运行容器服务。
实验准备
| 主机名(IP) | 服务 |
|---|---|
| server1(172.25.11.1) | master |
| server2(172.25.11.2) | node1 |
| server3(172.25.11.3) | node2 |
- 一个或者多个兼容 deb 或者 rpm 软件包的操作系统,比如 Ubuntu 或者 CentOS
- 每台机器 2 GB 以上的内存,内存不足时应用会受限制
- 主节点上 2 CPU 以上
- 集群里所有的机器有完全的网络连接,公有网络或者私有网络都可以
实验步骤
- 首先在每个节点清理之前做过的swarm的实验。(如果没有则这一步跳过)
server2~4:
[root@server4 ~]# docker swarm leave
[root@server4 ~]# docker network prune
[root@server4 ~]# docker volume prune
[root@server4 ~]# docker ps -a
server1:
[root@server1 wordpress]# docker node ls
[root@server1 wordpress]# docker node rm server2
[root@server1 wordpress]# docker node rm server3
[root@server1 wordpress]# docker node rm server4
[root@server1 wordpress]# docker node ls
[root@server1 wordpress]# docker swarm leave -f
[root@server1 wordpress]# docker network prune
[root@server1 ~]# docker volume prune
- 在3个节点上,关闭系统的交换分区。
swapoff -a
vim /etc/fstab #注释swap的定义
#/dev/mapper/rhel-swap swap swap defaults 0 0
- 在3个节点上安装以下软件:
其中:kubeadm: 用来初始化集群的指令。 kubelet: 在集群中的每个节点上用来启动 pod 和 container 等。 kubectl: 用来与集群通信的命令行工具。
yum install -y cri-tools-1.13.0-0.x86_64.rpm kubectl-1.15.0-0.x86_64.rpm kubelet-1.15.0-0.x86_64.rpm kubernetes-cni-0.7.5-0.x86_64.rpm kubeadm-1.15.0-0.x86_64.rpm

- 在3个节点上导入镜像:
[root@server1 images]# ls
coredns.tar kube-apiserver.tar kube-proxy.tar pause.tar
etcd.tar kube-controller-manager.tar kube-scheduler.tar
[root@server1 images]# for i in *.tar;do docker load -i $i;done
[root@server1 images]# docker images
[root@server1 images]# scp * server2:
[root@server1 images]# scp * server3:

- 由于可能会出现iptables 被绕过导致网络请求被错误的路由,需要给所有节点进行相应配置,并且所有节点开启服务,设置服务开机自启动。
[root@server1 images]# vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
[root@server1 images]# sysctl --system
[root@server1 sysctl.d]# scp k8s.conf server2:/etc/sysctl.d/
[root@server1 sysctl.d]# scp k8s.conf server3:/etc/sysctl.d/
[root@server2 images]# sysctl --system
[root@server3 images]# sysctl --system
[root@server1 sysctl.d]# systemctl enable kubelet
[root@server1 sysctl.d]# systemctl start kubelet
- server1(master节点初始化),选择一个 Pod 网络插件,并检查是否在 kubeadm 初始化过程中需要传入什么参数。设置 --Pod-network-cidr 来指定网络驱动的 CIDR。
[root@server1 sysctl.d]# kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=172.25.11.1
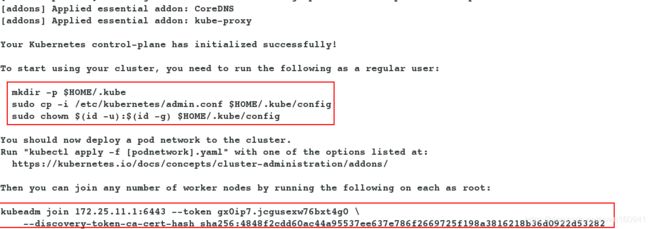
- server2和server3,利用server1master节点的初始化信息,加入集群。
[root@server2 ~]# kubeadm join 172.25.11.1:6443 --token gx0ip7.jcgusexw76bxt4g0 \
> --discovery-token-ca-cert-hash sha256:4848f2cdd60ac44a95537ee637e786f2669725f198a3816218b36d0922d53282
[root@server3 ~]# kubeadm join 172.25.11.1:6443 --token gx0ip7.jcgusexw76bxt4g0 \
> --discovery-token-ca-cert-hash sha256:4848f2cdd60ac44a95537ee637e786f2669725f198a3816218b36d0922d53282
- 在所有节点安装:
[root@server1 sysctl.d]# yum install yum-utils device-mapper-persistent-data lvm2 - 在server1(master节点)创建普通用户管理集群,如果需要让普通用户可以运行 kubectl,运行如下命令,这也是 kubeadm init 输出的一部分:
server1:新建普通用户 授权。
[root@server1 sysctl.d]# useradd kubeadm
[root@server1 sysctl.d]# vim /etc/sudoers
kubeadm ALL=(ALL) NOPASSWD:ALL
[root@server1 ~]# su - kubeadm
[kubeadm@server1 ~]$ mkdir -p $HOME/.kube
[kubeadm@server1 ~]$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[kubeadm@server1 ~]$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
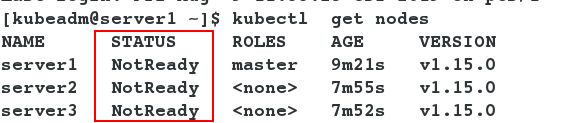
[kubeadm@server1 ~]$ kubectl get nodes

- 此时所有节点的状态为not ready。
[kubeadm@server1 ~]$ kubectl get nodes
- 配置server1的kubectl命令的补齐功能。
lftp 172.25.11.250:/pub/k8s> mget flannel.tar kube-flannel.yml
[root@server1 ~]# cp kube-flannel.yml /home/kubeadm/
[root@server1 ~]# su - kubeadm
[kubeadm@server1 ~]$ echo "source <(kubectl completion bash)" >>.bashrc


- 给所有节点安装pod网络:
[root@server1 ~]# docker load -i flannel.tar #在3个节点都要导入镜像
[root@server1 ~]# scp flannel.tar server2:
[root@server1 ~]# scp flannel.tar server3:
[root@server2 ~]# docker load -i flannel.tar
[root@server3 ~]# docker load -i flannel.tar
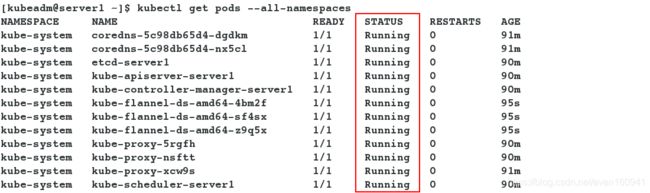
- 下载并应用.yml文件,再次查看,发现所有节点的状态已经变为ready。
[kubeadm@server1 ~]$ kubectl apply -f kube-flannel.yml
[kubeadm@server1 ~]$ kubectl get nodes
[kubeadm@server1 ~]$ kubectl get pods --all-namespaces
[kubeadm@server1 ~]$ systemctl status kubelet.service

- 至此,k8s集群部署完成。