redis的主从复制配置
通过持久化功能,redis保证了即使在服务器重启的情况下也不会丢失或少量丢失数据,但是由于数据存储在一台服务器上,如果这台服务器出现故障,比如磁盘坏了,也会导致数据丢失。为了避免这个单点故障,可以使用主从复制的方式,将主更新的数据,自动更新同步到其他服务器上。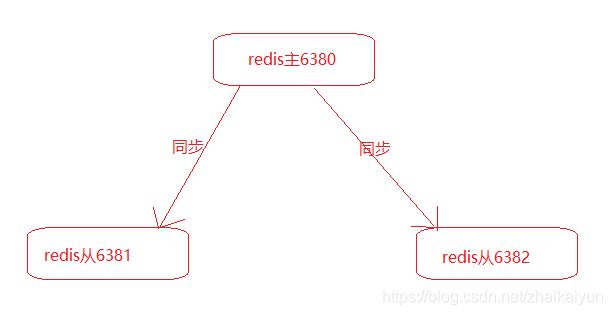
主从节点配置
[root@k8smaster config]# more redis6380.conf
include /data/redis/redis-3.0.7/redis.conf
daemonize yes #以守护进程模式运行
port 6380 #端口
logfile /data/redis/redis/log/redis6380.log #日志文件
pidfile /var/run/redis6380.pid #pid进程文件
dbfilename dump6380.rdb #rdb文件名
bind 192.168.23.100
requirepass 123456 #密码
masterauth 123456 #认证master时需要的密码,必须和master配置的requirepass保持一致
[root@k8smaster config]# more redis6381.conf
include /data/redis/redis-3.0.7/redis.conf
daemonize yes
port 6381
logfile /data/redis/redis/log/redis6381.log
pidfile /var/run/redis6381.pid
dbfilename dump6381.rdb
bind 192.168.23.100
requirepass 123456
slaveof 192.168.23.100 6380 #指定master ip port
masterauth 123456
[root@k8smaster config]# more redis6382.conf
include /data/redis/redis-3.0.7/redis.conf
daemonize yes
port 6382
logfile /data/redis/redis/log/redis6382.log
pidfile /var/run/redis6382.pid
dbfilename dump6382.rdb
bind 192.168.23.100
requirepass 123456
slaveof 192.168.23.100 6380
masterauth 123456
[root@k8smaster config]#
使用info replication查看集群角色
[root@k8smaster bin]# ./redis-cli -h 192.168.23.100 -p 6380 -a 123456
192.168.23.100:6380> ping
PONG
192.168.23.100:6380> info replication #6380为主,6381和6382为从
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.23.100,port=6381,state=online,offset=239,lag=1
slave1:ip=192.168.23.100,port=6382,state=online,offset=239,lag=0
master_repl_offset:239
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:238
[root@k8smaster ~]# cd /data/redis/redis/bin/
[root@k8smaster bin]# ./redis-cli -h 192.168.23.100 -p 6381 -a 123456
192.168.23.100:6381> info replication
# Replication
role:slave
master_host:192.168.23.100
master_port:6380
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:309
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
[root@k8smaster ~]# cd /data/redis/redis/bin/
[root@k8smaster bin]# ./redis-cli -h 192.168.23.100 -p 6382 -a 123456
192.168.23.100:6382> info replication
# Replication
role:slave
master_host:192.168.23.100
master_port:6380
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:351
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
主从日志
从日志可以发现主从数据同步情况
4491:M 12 Feb 01:57:58.146 * The server is now ready to accept connections on port 6380
4491:M 12 Feb 01:58:01.951 * Slave 192.168.23.100:6381 asks for synchronization
4491:M 12 Feb 01:58:01.951 * Full resync requested by slave 192.168.23.100:6381
4491:M 12 Feb 01:58:01.951 * Starting BGSAVE for SYNC with target: disk
4491:M 12 Feb 01:58:01.951 * Background saving started by pid 4498
4498:C 12 Feb 01:58:01.956 * DB saved on disk
4498:C 12 Feb 01:58:01.957 * RDB: 0 MB of memory used by copy-on-write
4491:M 12 Feb 01:58:01.962 * Background saving terminated with success
4491:M 12 Feb 01:58:01.962 * Synchronization with slave 192.168.23.100:6381 succeeded
4491:M 12 Feb 01:58:05.608 * Slave 192.168.23.100:6382 asks for synchronization
4491:M 12 Feb 01:58:05.608 * Full resync requested by slave 192.168.23.100:6382
4491:M 12 Feb 01:58:05.608 * Starting BGSAVE for SYNC with target: disk
4491:M 12 Feb 01:58:05.608 * Background saving started by pid 4503
4503:C 12 Feb 01:58:05.613 * DB saved on disk
4503:C 12 Feb 01:58:05.614 * RDB: 0 MB of memory used by copy-on-write
4491:M 12 Feb 01:58:05.687 * Background saving terminated with success
4491:M 12 Feb 01:58:05.687 * Synchronization with slave 192.168.23.100:6382 succeeded
验证数据是否主从同步
1)在主写入数据
[root@k8smaster bin]# ./redis-cli -h 192.168.23.100 -p 6380 -a 123456
192.168.23.100:6380> ping
PONG
192.168.23.100:6380> set test zhaiky
OK
192.168.23.100:6380> get test
"zhaiky"
2)在从的redis能查到数据
[root@k8smaster bin]# ./redis-cli -h 192.168.23.100 -p 6381 -a 123456
192.168.23.100:6381> get test
"zhaiky"
192.168.23.100:6381>
主故障恢复
当主redis出现故障,对对外不能提供服务,需要手工将slave中的一个提升为master,剩下的slave挂到新的主上,步骤如下:
1)salveof no one,将一台slave服务器提升为主
2)slaveof ip port,将其他slave挂到新的主上
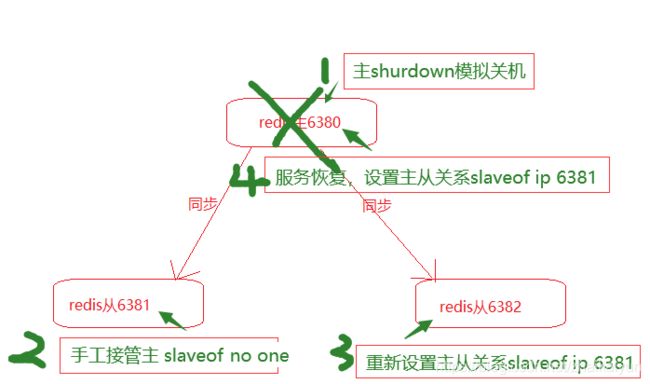
1)主6380关闭服务,模拟故障
192.168.23.100:6380> shutdown
not connected> exit
主的日志,进行关机处理
4491:M 12 Feb 02:02:54.164 # User requested shutdown...
4491:M 12 Feb 02:02:54.164 * Saving the final RDB snapshot before exiting.
4491:M 12 Feb 02:02:54.169 * DB saved on disk
4491:M 12 Feb 02:02:54.169 * Removing the pid file.
4491:M 12 Feb 02:02:54.169 # Redis is now ready to exit, bye bye...
从的日志出现连接主拒绝(Connection refused)
495:S 12 Feb 01:58:01.950 * Connecting to MASTER 192.168.23.100:6380
4495:S 12 Feb 01:58:01.950 * MASTER <-> SLAVE sync started
4495:S 12 Feb 01:58:01.950 * Non blocking connect for SYNC fired the event.
4495:S 12 Feb 01:58:01.950 * Master replied to PING, replication can continue...
4495:S 12 Feb 01:58:01.951 * Partial resynchronization not possible (no cached master)
4495:S 12 Feb 01:58:01.951 * Full resync from master: 2b1dce3355b4c3a7b23e35bd81957575a05836c7:1
4495:S 12 Feb 01:58:01.962 * MASTER <-> SLAVE sync: receiving 18 bytes from master
4495:S 12 Feb 01:58:01.962 * MASTER <-> SLAVE sync: Flushing old data
4495:S 12 Feb 01:58:01.962 * MASTER <-> SLAVE sync: Loading DB in memory
4495:S 12 Feb 01:58:01.962 * MASTER <-> SLAVE sync: Finished with success
4495:S 12 Feb 02:02:54.170 # Connection with master lost.
4495:S 12 Feb 02:02:54.170 * Caching the disconnected master state.
4495:S 12 Feb 02:02:54.868 * Connecting to MASTER 192.168.23.100:6380
4495:S 12 Feb 02:02:54.868 * MASTER <-> SLAVE sync started
4495:S 12 Feb 02:02:54.868 # Error condition on socket for SYNC: Connection refused 出现连接主失败
2)查看角色状态,主处于下线down状态
192.168.23.100:6381> info replication
# Replication
role:slave
master_host:192.168.23.100
master_port:6380
master_link_status:down 主处于下线状态
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:407
master_link_down_since_seconds:80
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
192.168.23.100:6382> info replication
# Replication
role:slave
master_host:192.168.23.100
master_port:6380
master_link_status:down 主处于下线状态
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:407
master_link_down_since_seconds:84
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
3)将6381提升为主
192.168.23.100:6381> slaveof no one
OK
192.168.23.100:6381> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
4)slave6382重新挂到6381的主下面作为从
192.168.23.100:6382> slaveof 192.168.23.100 6381
OK
192.168.23.100:6382> info replication
# Replication
role:slave
master_host:192.168.23.100
master_port:6381
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:15
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
192.168.23.100:6382>
192.168.23.100:6381> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.23.100,port=6382,state=online,offset=141,lag=0
master_repl_offset:141
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:140
192.168.23.100:6381>
192.168.23.100:6381>
5)恢复6380,将其挂载6381下作为从
[root@k8smaster bin]# ./redis-cli -h 192.168.23.100 -p 6380 -a 123456
192.168.23.100:6380> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
192.168.23.100:6380> slaveof 192.168.23.100 6381
OK
192.168.23.100:6380> info replication
# Replication
role:slave
master_host:192.168.23.100
master_port:6381
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:589
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
192.168.23.100:6380>
192.168.23.100:6381> info replication #此时主由6380切换到了6381,集群状态恢复正常
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.23.100,port=6382,state=online,offset=589,lag=0
slave1:ip=192.168.23.100,port=6380,state=online,offset=589,lag=0
master_repl_offset:589
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:588
192.168.23.100:6381>