ZooKeeper(2):组成
前言
在上一章中,我概括性的讲述了什么是ZooKeeper,具体如下:
总结:ZooKeeper 是一个树型结构的资源管理系统,其以key-value(键值对)的方式储存数据,并将绝对路径作为键使用。

上述总结应该令大家对ZooKeeper有了初步认识,但实际内容远比上述复杂,因此需要更深入性的了解。
一.ZooKeeper的组成
ZooKeeper设计的本意是为大型分布式应用程序提供协调服务,大致类似于导游,门卫或疏导员一类的角色。而想达到这个目的,单纯的树型结构远远不够,因此从整体来看,ZooKeeper由三部分组成:数据结构、原语和通知机制。接下来我们便从这三个方面继续讲解。
附:参考文件1:Zookeeper学习之路 (一)初识
二.数据结构
1.树
ZooKeeper采用树作为数据结构,在概括中已经提及。这与标准文件系统非常相似,具体如下:

2.Znode
ZooKeeper树中的节点被称为Znode,每个Znode都允许拥有多个子Znode,Znode的相关特性如下:
引用:Znode使用绝对路径进行引用(示例:/app1/p_1)。 因为Znode的唯一性,所以每个绝对路径也都是唯一的。ZooKeeper默认有一个路径为/zookeeper的Znode,其被用来保存ZooKeeper的相关配置信息。
结构:Znode兼具目录与文件两种功能,既可储存数据,也可作为路径标识的一部分。
类型:Znode具有“持久”和“临时”两种类型。顾名思义,持久节点是永久存在的,而临时节点会随着生命周期(具体后面章节会讲)的结束而删除,当然也可以手动删除。Znode的类型在创建时就会被指定,并且不能改变。
秩序:Znode默认是无序的,但在创建时可以设置有序。序号按顺序递增,格式为%10d(10位数字,空缺数位用0补充,例:0000000001),范围[1, 232-1]。
Znode拥有诸多属性,用于维护其本身的状态(元)数据:
名词解释:事务ID
在Zookeeper中,事务表示能够修改服务器状态的操作,包括但不限于Znode的新增/删除,Znode值的更新等。ZooKeeper会为事务分配一个全局唯一的事务ID(Zxid),通常为有序的64位数字,通过比对事务ID的大小,可以知道事务先后顺序。
| 名称 | 描述 |
|---|---|
| cZxid | 创建Znode的事务的事务ID |
| ctime | 创建Znode的时间 |
| mZxid | 最后一次修改Znode的事务的事务ID |
| mtime | 最后一次修改Znode的时间 |
| pZxid | 最后一次修改子Znode列表的事务的事务ID(注:只有新增/删除子Znode才会修改子Znode列表,修改子Znode的值并不会影响子Znode列表) |
| cversion | 子Znode版本号,子Znode修改(无论是列表还是本身)时会递增 |
| dataversion | 数据版本号,数据修改时递增 |
| aclversion | 权限(关于权限后续会有单独的章节)版本号,权限修改时递增 |
| ephemeralOwner | 创建临时Znode的会话ID(如果是持久节点,该值为0) |
| dataLength | 数据长度 |
| numChildren | 子Znode的数量(只统计直接子Znode) |
注:上述的属性最好能都记住,即使达不到凭空背诵的程度,也要做到见名知意。
二.原语
注:所谓原语,即是关于Znode的操作。ZooKeeper中关于Znode的基本操作有9种,具体如下:
| 名称 | 描述 |
|---|---|
| create | 创建Znode |
| delete | 删除Znode |
| exists | 判断Znode是否存在,并获取属性(元数据) |
| setACL | 设置权限(关于权限后续会有单独的章节) |
| getACL | 获取权限(关于权限后续会有单独的章节) |
| getChildren | 获取子Znode列表 |
| setData | 设置Znode值 |
| getData | 获取Znode值 |
| sync | 使客户端的Znode视图与服务端同步(关于客户端/服务端后续会有单独的章节) |
上述操作在后续章节中都会有具体演示,大家有大致印象就好。而这些指令应该也不需要刻意记忆,毕竟确实挺简单直白的。需要说明的一点是,上述操作是非阻塞的,也就是说允许多个线程同时操作同一个Znode,Zookeeper采用乐观锁机制保证线程安全,而充当乐观锁的即是Znode属性中的诸多版本号。
三.Watcher
其实从设计上讲,拥有了数据结构和原语,ZooKeeper就已具备了协调服务的能力。当各个服务都部署在同一台服务器的情况下,每个服务都能实时、持续的对目标Znode进行监控,并进行回应。
但关键在于,ZooKeeper是为大型分布式应用程序提供协调服务的,而在分布式环境下,服务散落在不同的服务器中,以网络进行通信,这使得的服务对目标Znode进行实时、持续的监控变得不可能。因此ZooKeeper需要一种通知机制,令其能够在Znode状态发生变化时对监控该Znode的服务进行通知,而这个机制被命名为Watcher,相信大家也都猜到了,其核心在于监听器。
1.设置
在ZooKeeper中,客户端可以通过对目标Znode进行getData、exists及getChildren三种操作来设置Watcher。
2.类型
- Data Watcher(数据):监听Znode值是否发生变化,通过getData及exists设置
- Children Watcher(孩子):监听子Znode列表否发生变化,通过getChildren设置
由上可得
- setData将触发Data Watcher
- create将触发Data Watcher及Children Watcher
- delete将触发Data Watcher及Children Watcher
3.原理
Watcher 可以分为四个步骤(部分文章描述为三个,合并了前两个步骤):
- 客户端注册 Watcher
- 服务端处理 Watcher
- 服务端触发 Watcher
- 客户端回调 Watcher
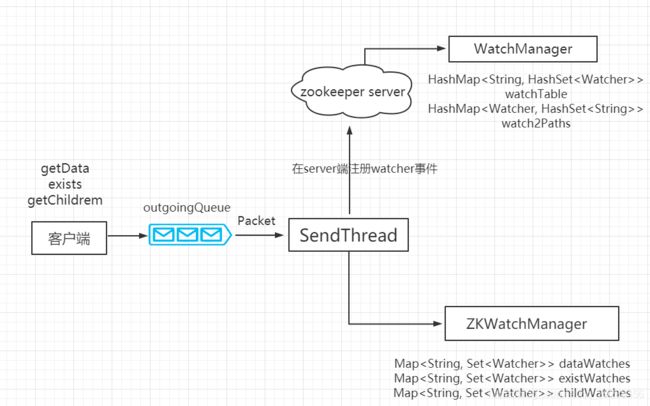
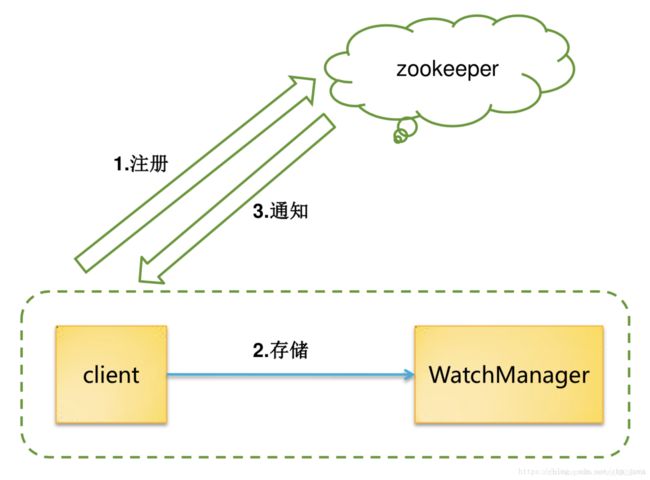
客户端通过对目标Znode进行操作向服务端请求注册Watcher。服务端会处理该请求,对目标Znode创建监听并回应。客户端接收到回应后将Watcher保存在WatchManager中。
当被监听的Znode状态发生变化,会触发Watcher事件,服务器随即通知相应客户端。
客户端接收通知,从WatchManager中取出对应Watcher并执行回调逻辑。