【MySQL】主从复制(重点:主从复制原理)
【大家好,我是爱干饭的猿,本文重点介绍MySQL的主从复制概述,作用,原理,同步数据一致性问题。
后续会继续分享Redis和其他重要知识点总结,如果喜欢这篇文章,点个赞,关注一下吧】
上一篇文章:《【MySQL】MVCC多版本并发控制(重点:MVCC实现原理之ReadView)》
目录
1. 主从复制概述
1.1 如何提升数据库并发能力
1.2 主从复制的作用
2. 主从复制的原理
2.1 原理剖析
2.2 复制的基本原则
3. 同步数据一致性问题
3.1 理解主从延迟问题
3.2 主从延迟问题原因
3.3 如何减少主从延迟
3.4 如何解决一致性问题
SQL语句中 DDL 、DML 、DQL 、DCL:
- DDL:DDL(Data Definition Language)语句:
数据定义语言,主要是进行定义/改变表的结构、数据类型、表之间的链接等操作。常用的语句关键字有 CREATE、DROP、ALTER 等。 - DML:DML(Data Manipulation Language)语句:
数据操纵语言,主要是对数据进行增加、删除、修改操作。常用的语句关键字有 INSERT、UPDATE、DELETE 等。 - DQL:DQL(Data Query Language)语句:
数据查询语言,主要是对数据进行查询操作。常用关键字有 SELECT、FROM、WHERE 等。 - DCL:DCL(Data Control Language)语句:
数据控制语言,主要是用来设置/更改数据库用户权限。常用关键字有 GRANT、REVOKE 等。
1. 主从复制概述
1.1 如何提升数据库并发能力

一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是采用数据库集群的方案,做主从架构、进行读写分离,这样同样可以提升数据库的并发处理能力。但并不是所有的应用都需要对数据库进行主从架构的设置,毕竟设置架构本身是有成本的。
如果我们的目的在于提升数据库高并发访问的效率,那么首先考虑的是如何优化SQL和索引,这种方式简单有效;其次才是采用缓存的策略,比如使用 Redis将热点数据保存在内存数据库中,提升读取的效率;最后才是对数据库采用主从架构,进行读写分离。
1.2 主从复制的作用
第1个作用:读写分离。
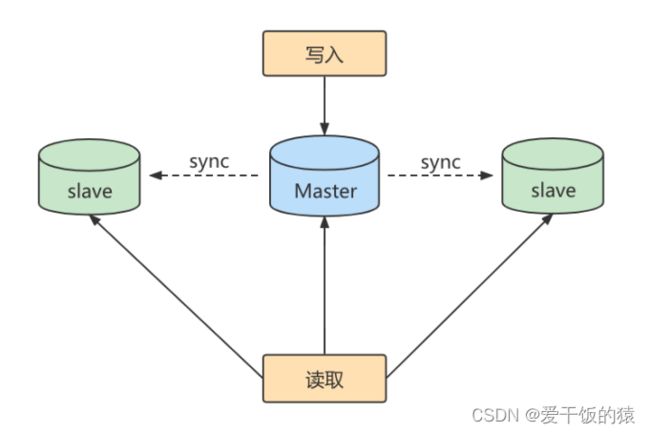
第2个作用:数据备份。
第3个作用:具有高可用性。
2. 主从复制的原理
2.1 原理剖析
三个线程
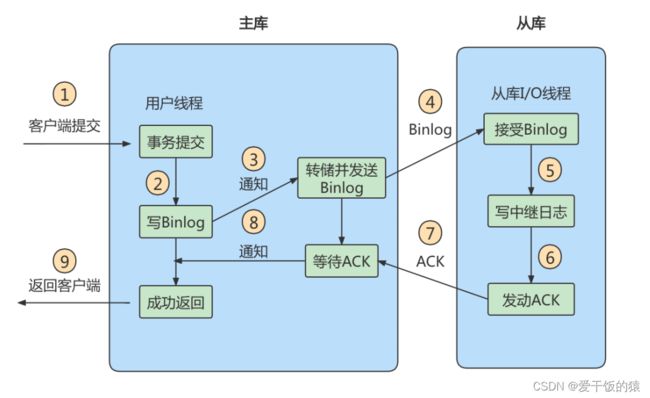
实际上主从同步的原理就是基于 binlog 进行数据同步的。在主从复制过程中,会基于3 个线程来操作,一个主库线程,两个从库线程。
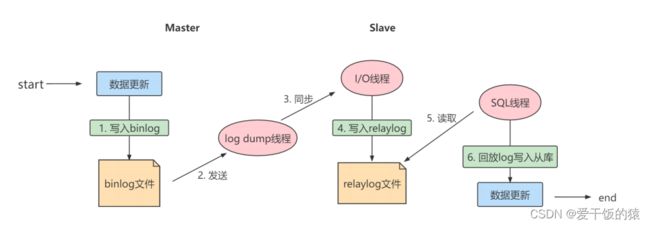
二进制日志转储线程(Binlog dump thread)是一个主库线程。当从库线程连接的时候, 主库可以将二进制日志发送给从库,当主库读取事件(Event)的时候,会在 Binlog 上加锁,读取完成之后,再将锁释放掉。
从库 I/O 线程会连接到主库,向主库发送请求更新 Binlog。这时从库的 I/O 线程就可以读取到主库的二进制日志转储线程发送的 Binlog 更新部分,并且拷贝到本地的中继日志 (Relay log)。
从库 SQL 线程会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
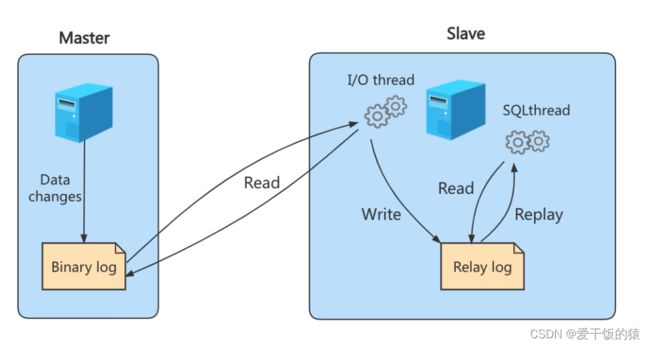
复制三步骤(面试重点)
步骤1:Master将写操作记录到二进制日志(binlog)。
步骤2:Slave将Master的binary log events拷贝到它的中继日志(relay log);
步骤3:Slave重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL复制是异步的且串行化的,而且重启后从接入点开始复制。
复制的问题
复制的最大问题:延时
2.2 复制的基本原则
-
每个
Slave只有一个Master -
每个
Slave只能有一个唯一的服务器ID -
每个
Master可以有多个Slave
3. 同步数据一致性问题
主从同步的要求:
-
读库和写库的数据一致(最终一致);
-
写数据必须写到写库;
-
读数据必须到读库(不一定);
3.1 理解主从延迟问题
进行主从同步的内容是二进制日志,它是一个文件,在进行网络传输的过程中就一定会存在主从延迟(比如 500ms),这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的数据不一致性问题。
3.2 主从延迟问题原因
在网络正常的时候,日志从主库传给从库所需的时间是很短的,即T2-T1的值是非常小的。即,网络正常情况下,主备延迟的主要来源是备库接收完binlog和执行完这个事务之间的时间差。
主备延迟最直接的表现是,从库消费中继日志(relay log)的速度,比主库生产binlog的速度要慢。造成原因:
1、从库的机器性能比主库要差
2、从库的压力大
3、大事务的执行
3.3 如何减少主从延迟
若想要减少主从延迟的时间,可以采取下面的办法:
-
降低多线程大事务并发的概率,优化业务逻辑
-
优化SQL,避免慢SQL,
减少批量操作,建议写脚本以update-sleep这样的形式完成。 -
提高从库机器的配置,减少主库写binlog和从库读binlog的效率差。 -
尽量采用
短的链路,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输的网络延时。 -
实时性要求的业务读强制走主库,从库只做灾备,备份。
3.4 如何解决一致性问题
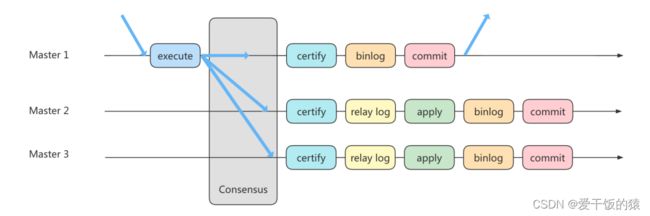
读写分离情况下,解决主从同步中数据不一致的问题, 就是解决主从之间 数据复制方式 的问题,如果按照数据一致性 从弱到强 来进行划分,有以下 3 种复制方式。
方法 1:异步复制
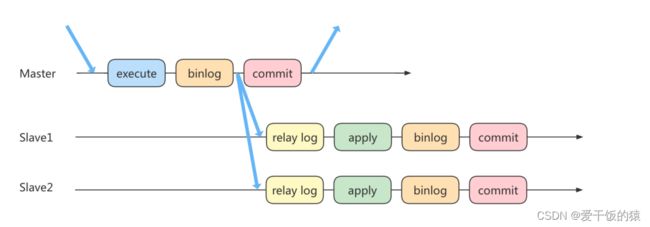
方法 2:半同步复制
方法 3:组复制
首先我们将多个节点共同组成一个复制组,在执行读写(RW)事务的时候,需要通过一致性协议层(Consensus 层)的同意,也就是读写事务想要进行提交,必须要经过组里“大多数人”(对应 Node 节点)的同意,大多数指的是同意的节点数量需要大于 (N/2+1),这样才可以进行提交,而不是原发起方一个说了算。而针对只读(RO)事务则不需要经过组内同意,直接 COMMIT 即可。
分享到此,感谢大家观看!!!
如果你喜欢这篇文章,请点赞加关注吧,或者如果你对文章有什么困惑,可以私信我。