FLINK API开发
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、Flink开发
-
- 1.DataStream
- 2.并行度
- 3.资源槽slot
- 4.datasource 和 datasink
- 5、Transformation
- 二、Flink API开发
-
- 1.流式执行环境创建
- 2、算子分区发放
- 3、flink连接器
- 4、流式程序特性
- 总结
前言
在Flink计算引擎中,将数据当做:数据流DataStream,分为有界数据流和无界数据流。
一、Flink开发
1.DataStream

datastream的子类:
-
)、
DataStreamSource:- 表示从数据源直接获取数据流DataStream,比如从Socket或Kafka直接消费数据
-
2)、
KeyedStream:- 当DataStream数据流进行分组时(调用keyBy),产生流称为KeyedStream,按照指定Key分组;
- 通常情况下数据流被分组以后,需要进行窗口window操作或聚合操作。
-
3)、
SingleOutputStreamOperator:- 当DataStream数据流没有进行keyBy分组,而是使用转换函数,产生的流称为SingleOutputStreamOperator。
- 比如使用filter、map、flatMap等函数,产生的流就是
SingleOutputStreamOperator
-
4)、
IterativeStream:迭代流,表示对流中数据进行迭代计算,比如机器学习,图计算等。
flink开发流程
-
1)、Obtain an execution environment,
执行环境-env:StreamExecutionEnvironment -
2)、Load/create the initial data,
数据源-source:DataStream -
3)、Specify transformations on this data,
数据转换-transformation:DataStream API(算子,Operator) -
4)、Specify where to put the results of your computations,
数据接收器-sink -
5)、Trigger the program execution
触发执行-execute
2.并行度
一个Operator由多个并行的SubTask(以线程方式)来执行, 一个Operator的并行SubTask(数目就被称为该Operator(任务)的并行度(Parallelism)。
并行度设置的级别有4种:
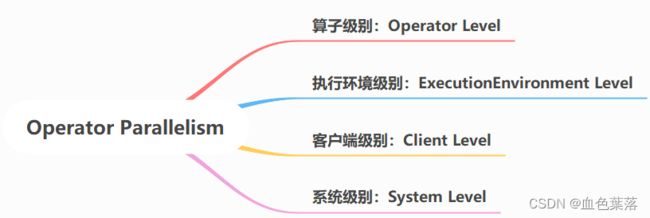
- 1)、Operator Level(算子级别)(可以使用)
一个operator、source和sink的并行度可以通过调用
setParallelism()方法来指定。
- 2)、Execution Environment Level(Env级别,可以使用)
执行环境并行度可以通过调用
setParallelism()方法指定。
- 3)、Client Level(客户端级别,推荐使用)
并行度可以在客户端将job提交到Flink时设定,对于CLI客户端,可以通过
-p参数指定并行度
- 4)、System Level(系统默认级别,尽量不使用)
在系统级可以通过设置
flink-conf.yaml文件中的parallelism.default属性来指定所有执行环境的默认并行度。
并行度的优先级:算子级别 > env级别 > Client级别 > 系统默认级别
3.资源槽slot
每个Slot中运行SubTask子任务,以线程Thread方式运行。
- 1个Job中不同类型SubTask任务,可以运行在同一个Slot中,称为:Slot Sharded 资源槽共享
- 1个Job中相同类型SubTask任务必须运行在不同Slot中
4.datasource 和 datasink
-
1、基于File文件数据源
readTextFile(path) -
2、Sockect 数据源
socketTextStream -
3、基于Collection数据源
fromCollection(Collection)
fromElements(T …)
fromSequence(from, to),相当于Python中range -
4、自定义Custom数据源
env.addSource()
官方提供接口:
SourceFunction 非并行
RichSourceFunction
ParallelSourceFunction 并行
RichParallelSourceFunction
自定义数据源实例:
public class StreamSourceOrderDemo {
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Order {
private String id;
private Integer userId;
private Double money;
private Long orderTime;
}
/**
* 自定义数据源,继承抽象类:RichParallelSourceFunction,并行的和富有的
*/
private static class OrderSource extends RichParallelSourceFunction<Order> {
// 定义变量,用于标识是否产生数据
private boolean isRunning = true ;
// 表示产生数据,从数据源Source源源不断加载数据
@Override
public void run(SourceContext<Order> ctx) throws Exception {
Random random = new Random();
while (isRunning){
// 产生交易订单数据
Order order = new Order(
UUID.randomUUID().toString(), //
random.nextInt(2), //
(double)random.nextInt(100), //
System.currentTimeMillis()
);
// 发送交易订单数据
ctx.collect(order);
// 每隔1秒产生1条数据,休眠1秒钟
TimeUnit.SECONDS.sleep(1);
}
}
// 取消从数据源加载数据
@Override
public void cancel() {
isRunning = false ;
}
}
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment() ;
env.setParallelism(1);
// 2. 数据源-source
DataStreamSource<Order> orderDataStream = env.addSource(new OrderSource());
// 3. 数据转换-transformation
// 4. 数据接收器-sink
orderDataStream.printToErr();
// 5. 触发执行-execute
env.execute("StreamSourceOrderDemo") ;
}
}
自定义数据库数据源:
public class StreamSourceMySQLDemo {
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Student {
private Integer id;
private String name;
private Integer age;
}
/**
* 自定义数据源,从MySQL表中加载数据,并且实现增量加载
*/
private static class MySQLSource extends RichParallelSourceFunction<Student> {
// 定义变量,标识是否加载数据
private boolean isRunning = true ;
// 定义变量,open方法初始化,close方法关闭连接
private Connection conn = null ;
private PreparedStatement pstmt = null ;
private ResultSet result = null ;
// 初始化方法,在获取数据之前,准备工作
@Override
public void open(Configuration parameters) throws Exception {
// step1、加载驱动
Class.forName("com.mysql.jdbc.Driver") ;
// step2、获取连接Connection
conn = DriverManager.getConnection(
"jdbc:mysql://node1:3306/?useSSL=false",
"root",
"123456"
);
// step3、创建Statement对象,设置语句(INSERT、SELECT)
pstmt = conn.prepareStatement("SELECT id, name, age FROM db_flink.t_student") ;
}
@Override
public void run(SourceContext<Student> ctx) throws Exception {
while (isRunning){
// step4、执行操作,获取ResultSet对象
result = pstmt.executeQuery();
// step5、遍历获取数据
while (result.next()){
// 获取每个字段的值
int stuId = result.getInt("id");
String stuName = result.getString("name");
int stuAge = result.getInt("age");
// 构建实体类对象
Student student = new Student(stuId, stuName, stuAge);
// 发送数据
ctx.collect(student);
}
// 每隔5秒加载一次数据库,获取数据
TimeUnit.SECONDS.sleep(5);
}
}
@Override
public void cancel() {
isRunning = false ;
}
// 收尾工作,当不再加载数据时,一些善后工作
@Override
public void close() throws Exception {
// step6、关闭连接
if(null != result) result.close();
if(null != pstmt) pstmt.close();
if(null != conn) conn.close();
}
}
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment() ;
env.setParallelism(1);
// 2. 数据源-source
DataStreamSource<Student> studentDataStream = env.addSource(new MySQLSource());
// 3. 数据转换-transformation
// 4. 数据终端-sink
studentDataStream.printToErr();
// 5. 触发执行-execute
env.execute("StreamSourceMySQLDemo") ;
}
}
自定义sink:
public class StreamSinkMySQLDemo {
@Data
@NoArgsConstructor
@AllArgsConstructor
private static class Student {
private Integer id;
private String name;
private Integer age;
}
/**
* 自定义Sink接收器,将DataStream中数据写入到MySQL数据库表中
*/
private static class MySQLSink extends RichSinkFunction<Student> {
// 定义变量,在open方法实例化,在close方法关闭
private Connection conn = null ;
private PreparedStatement pstmt = null ;
// 初始化工作
@Override
public void open(Configuration parameters) throws Exception {
// step1、加载驱动
Class.forName("com.mysql.jdbc.Driver") ;
// step2、获取连接Connection
conn = DriverManager.getConnection(
"jdbc:mysql://node1.itcast.cn:3306/?useSSL=false",
"root",
"123456"
);
// step3、创建Statement对象,设置语句(INSERT)
pstmt = conn.prepareStatement("INSERT INTO db_flink.t_student(id, name, age) VALUES (?, ?, ?)");
}
// TODO:数据流中每条数据进行输出操作,调用invoke方法
@Override
public void invoke(Student student, Context context) throws Exception {
// step4、执行操作
pstmt.setInt(1, student.id);
pstmt.setString(2, student.name);
pstmt.setInt(3, student.age);
pstmt.executeUpdate();
}
// 收尾工作
@Override
public void close() throws Exception {
// step5、关闭连接
if(null != pstmt) pstmt.close();
if(null != conn) conn.close();
}
}
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. 数据源-source
DataStreamSource<Student> inputDataStream = env.fromElements(
new Student(13, "wangwu", 20),
new Student(14, "zhaoliu", 19),
new Student(15, "laoda", 25),
new Student(16, "laoer", 23)
);
// inputDataStream.printToErr();
// 3. 数据转换-transformation
// 4. 数据终端-sink
MySQLSink mySQLSink = new MySQLSink();
inputDataStream.addSink(mySQLSink) ;
// 5. 触发执行-execute
env.execute("StreamSinkMySQLDemo");
}
}
5、Transformation
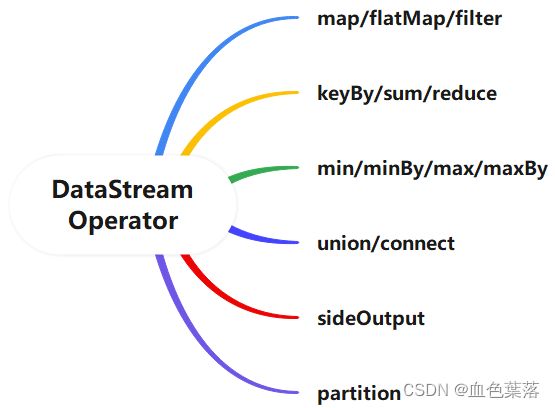
- map算子:将每条数据转换,如转换成对象
// TODO: 函数一【map函数】,将JSON转换为JavaBean对象
DataStream<ClickLog> clickDataStream = inputDataStream.map(new MapFunction<String, ClickLog>() {
@Override
public ClickLog map(String line) throws Exception {
return JSON.parseObject(line, ClickLog.class);
}
});
- flatMap:将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果,flatMap = map + flattern
DataStream<String> flatMapDataStream = clickDataStream.flatMap(new FlatMapFunction<ClickLog, String>() {
@Override
public void flatMap(ClickLog clickLog, Collector<String> out) throws Exception {
// 获取访问数据
Long entryTime = clickLog.getEntryTime();
// 格式一:yyyy-MM-dd-HH
String hour = DateFormatUtils.format(entryTime, "yyyy-MM-dd-HH");
out.collect(hour);
// 格式二:yyyy-MM-dd
String day = DateFormatUtils.format(entryTime, "yyyy-MM-dd");
out.collect(day);
// 格式三:yyyy-MM
String month = DateFormatUtils.format(entryTime, "yyyy-MM");
out.collect(month);
}
});
- filter:按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素
DataStream<ClickLog> filterDataStream = clickDataStream.filter(new FilterFunction<ClickLog>() {
@Override
public boolean filter(ClickLog clickLog) throws Exception {
return "谷歌浏览器".equals(clickLog.getBrowserType());
}
});
- keyBy算子表示:按照指定的key来对流中的数据进行分组,分组后流称为KeyedStream,要么聚合操作(调用reduce、fold或aggregate函数等等),要么进行窗口操作window。
SingleOutputStreamOperator<Tuple2<String, Integer>> outputStream = inputDataStream
// 3-1. 过滤脏数据, TODO: Java 8 提供Lambda表达式
.filter(line -> line.trim().length() > 0)
// 3-2. 每行数据分割为单词,并转换为二元组
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = line.trim().split("\\s+");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
})
// 3-3. 按照单词分组,并且组内数据求和,TODO: Java 8 提供Lambda表达式
.keyBy(tuple -> tuple.f0).sum("f1");
- reduce:对Key分组中的元素进行聚合,有2个参数 (x, y),其中 x :tmp为聚合中间临时变量, y:item为聚合中每个元素。
SingleOutputStreamOperator<Tuple2<String, Integer>> outputDataStream = tupleDataStream
.keyBy(tuple -> tuple.f0)
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
// todo: sc.parallisize([1, 2, 3, 4, 5]).reduce(lambda tmp, item: tmp + item)), tmp 初始值为分区第一个元素
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> tmp,
Tuple2<String, Integer> item) throws Exception {
System.out.println("tmp = " + tmp + ", item = " + item);
/*
tmp:表示keyBy分组中每个Key对应结果值
key -> spark, tmp -> (spark, 10)
todo: 如果第一次对key数据聚合,直接将数据赋值给tmp
item: 表示使用keyBy分组后组内数据
(spark, 1)
*/
// 获取以前计算你只
Integer historyValue = tmp.f1;
// 获取现在传递值
Integer currentValue = item.f1;
// 计算最新值
int latestValue = historyValue + currentValue ;
//返回结果
return Tuple2.of(tmp.f0, latestValue);
}
});
- max或min:只会求出最大或最小的那个字段,其他的字段不管
- minBy:会求出最大或最小的那个字段和对应的其他的字段
DataStream<Tuple3<String, String, Integer>> minDataStream = inputDataStream
.keyBy(tuple -> tuple.f0)
.max(2);
minDataStream.printToErr("max>");
// TODO: maxBy 最大值使用
DataStream<Tuple3<String, String, Integer>> minByDataStream = inputDataStream
.keyBy(tuple -> tuple.f0)
.maxBy(2);
minByDataStream.print("maxBy");
union函数:可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。
connect函数:与union函数功能类似,用来连接两个数据流,且2个数据流数据类型可不一样。
- connect只能连接两个数据流,union可以连接多个数据流;
- connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致;
DataStream<String> unionDataStream = dataStream01.union(dataStream02);
//unionDataStream.printToErr();
// TODO: 两个流进行连接, connect 应用场景在于 -> 大表对小表(偶尔变化)数据 关联操作
ConnectedStreams<String, Integer> connectDataStream = dataStream01.connect(dataStream03);
// 对连接流中数据进行处理操作
connectDataStream.map(new CoMapFunction<String, Integer, String>() {
// 对连接左边流中每条数据计算操作
@Override
public String map1(String leftValue) throws Exception {
return "map1: left -> " + leftValue;
}
// 对连接右边流中每条数据计算操作
@Override
public String map2(Integer rightValue) throws Exception {
return "map2: right -> " + rightValue;
}
});
侧边输出SideOutput方式,可以将1个流进行侧边输出多个流。
// step1、定义分割流标签
OutputTag<Integer> oddTag = new OutputTag<Integer>("side-odd") {};
OutputTag<Integer> evenTag = new OutputTag<Integer>("side-even") {};
// step2、调用process函数,对流中数据处理及打标签
SingleOutputStreamOperator<String> mainStream = inputStream.process(new ProcessFunction<Integer, String>() {
// 表示对流中每条数据处理
@Override
public void processElement(Integer value, Context ctx, Collector<String> out) throws Exception {
// todo: 流中每条数据原来该怎么计算依然如何计算,比如值平方
int squareValue = value * value ;
out.collect(squareValue + "");
// step3、判断数据是奇数还是偶数,打上对应标签
if(value % 2 == 0){
ctx.output(evenTag, value);
}else{
ctx.output(oddTag, value);
}
}
});
// 4. 数据终端-sink
mainStream.printToErr();
// step4、获取侧边流,依据标签
DataStream<Integer> oddStream = mainStream.getSideOutput(oddTag);
oddStream.print("odd>");
DataStream<Integer> evenStream = mainStream.getSideOutput(evenTag);
evenStream.print("even>");
二、Flink API开发
1.流式执行环境创建
流式执行环境StreamExecutionEnvironment,有三种创建方式:
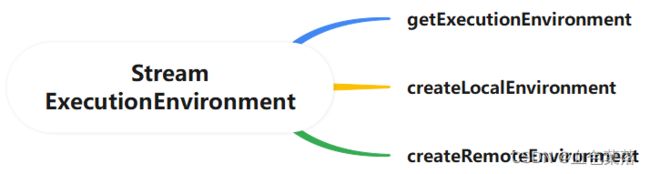
第1种:getExecutionEnvironment方法,自动依据当前环境,获取执行环境
第2种:createLocalEnvironment 方法,获取本地执行环境,启动1个JVM,运行多个线程
第三种:createRemoteEnvironment 方法,指定JobManager地址,获取远程执行环境,提交应用到集群
/ TODO: 此种方式,依据运行环境,自动确定创建本地环境还是集群环境
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO: 创建本地执行环境,启动一个JVM进程,其中Task任务(SubTask子任务)
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
// TODO: 创建本地执行环境,启动WEB UI界面,默认端口号:8081
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(1);
2、算子分区发放
DataStream提供物理分区算子:决定上游Operator中各个分区数据如何发送到下游Operator的各个分区中。
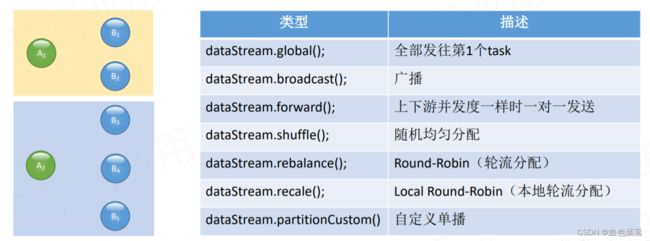
- 第一、物理分区算子【global】
功能:将所有的数据都发送到下游的某个算子实例(subtask id = 0)。
- 第二、物理分区算子【broadcast】
功能:发送到下游所有的算子实例。
- 第三、物理分区算子【forward】
功能:发送到下游对应的第1个task,保证上下游算子并行度一致,即上游算子与下游算子是1:1关系。
- 第四、物理分区算子【shuffle】
功能:随机选择一个下游算子实例进行发送
- 第五、物理分区算子【rebalance】
功能:通过循环的方式依次发送到下游的task。
- 第六、物理分区算子【rescale】
功能:基于上下游Operator并行度,将记录以循环的方式输出到下游Operator每个实例。
- 第七、物理分区算子【custom】
功能:当Flink 供的所有分区策略都不能满足用户的需求时,使用
partitionCustom()方法来自定义分区策略。
// TODO: 1、global函数,将所有数据发往1个分区Partition
DataStream<Tuple2<Integer, String>> globalDataStream = dataStream.global();
//globalDataStream.print().setParallelism(3);
// TODO: 2、broadcast函数, 广播数据
DataStream<Tuple2<Integer, String>> broadcastDataStream = dataStream.broadcast();
//broadcastDataStream.printToErr().setParallelism(3);
// TODO: 3、forward函数,上下游并发一样时 一对一发送
//DataStream> forwardDataStream = dataStream.setParallelism(3).forward();
//forwardDataStream.print().setParallelism(3) ;
// TODO: 4、shuffle函数,随机均匀分配
DataStream<Tuple2<Integer, String>> shuffleDataStream = dataStream.shuffle();
//shuffleDataStream.printToErr().setParallelism(3);
// TODO: 5、rebalance函数,轮流分配
DataStream<Tuple2<Integer, String>> rebalanceDataStream = dataStream.rebalance();
//rebalanceDataStream.print().setParallelism(3) ;
// TODO: 6、rescale函数,本地轮流分配
// DataStream> rescaleDataStream = dataStream.setParallelism(4).rescale();
// rescaleDataStream.printToErr().setParallelism(2);
// TODO: 7、partitionCustom函数,自定义分区规则
DataStream<Tuple2<Integer, String>> customDataStream = dataStream.partitionCustom(
new Partitioner<Integer>() {
@Override
public int partition(Integer key, int numPartitions) {
return key % 2;
}
},
tuple -> tuple.f0
);
-
RichFunction富函数,具有生命周期的特性,数据库连接、网络连接以及文件描述符的创建和关闭
open()方法:- rich function的初始化方法,当一个算子例如map或者filter被调用之前open()会被调用。
close()方法:
- 生命周期中的最后一个调用的方法,做一些清理工作。getRuntimeContext()方法:
- 提供了函数的RuntimeContext的一些信息,例如函数执行的并行度,任务的名字,以及state状态。
-
Flink DataStream API中最底层API,提供
process方法,其中需要实现ProcessFunction函数
SingleOutputStreamOperator<String> processStream = inputStream.process(
new ProcessFunction<String, String>() {
@Override
public void processElement(String line, Context ctx, Collector<String> out) throws Exception {
if(line.trim().length() > 0){
out.collect(line);
}
}
}
);
3、flink连接器
- FlinkKafkaConsumer
// 2-1. 创建消费Kafka数据时属性
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.setProperty("group.id", "test");
// 2-2. 构建FlinkKafkaConsumer实例对象
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<String>(
"flink-topic", //
new SimpleStringSchema(), //
props
);
// 2-3. 添加Source
DataStream<String> kafkaStream = env.addSource(kafkaConsumer);
kafka连接器指定消费位置:

动态分区发现:
构建 FlinkKafkaConsumer 时的 Properties 中设置flink.partition-discovery.interval-millis 参数为非负值,表示开启动态发现的开关,及设置的时间间隔,启动一个单独的线程定期去Kafka获取最新的meta信息。

- KafkaSource
Flink 1.12 版本中,提供基于新API接口Data Source实现Kafka 数据源:KafkaSource,消费数据更加简单
// 2-1. 创建KafkaSource对象,设置属性
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,node2:9092,node3:9092")
.setTopics("flink-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
// 2-2. 添加数据源
DataStream<String> kafkaStream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "KafkaSource");
- FlinkKafkaProducer
// 4-1. 向Kafka写入数据时属性配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
// 4-2. 创建FlinkKafkaProducer实例
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<String>(
"flink-topic", //
new KafkaStringSchema("flink-topic"), //
props, //
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
);
// 4-3. 数据流添加Sink
jsonDataStream.addSink(kafkaSink);
// 5. 触发执行-execute
env.execute("StreamFlinkKafkaProducerDemo") ;
}
/**
* 实现接口KafkaSerializationSchema,将交易订单数据JSON字符串进行序列化操作
*/
private static class KafkaStringSchema implements KafkaSerializationSchema<String> {
private String topic ;
public KafkaStringSchema(String topic){
this.topic = topic ;
}
public String getTopic() {
return topic;
}
public void setTopic(String topic) {
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, @Nullable Long timestamp) {
return new ProducerRecord<>(this.topic, element.getBytes());
}
}
- JdbcSink
从Flink 1.11版本开始,增加JDBC Connector连接器,可以将DataStream数据直接保存RDBMS表中。
// 4-1. 创建JdbcSink实例对象,传递参数信息
SinkFunction<Student> jdbcSink = JdbcSink.sink(
// a. 插入语句
"REPLACE INTO db_flink.t_student (id, name, age) VALUES (?, ?, ?)", //
// b. 构建Statement实例对象
new JdbcStatementBuilder<Student>() {
@Override
public void accept(PreparedStatement pstmt, Student student) throws SQLException {
pstmt.setInt(1, student.id);
pstmt.setString(2, student.name);
pstmt.setInt(3, student.age);
}
},
// c. 设置执行插入参数
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
// d. 设置连接MySQL数据库信息
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("com.mysql.jdbc.Driver")
.withUrl("jdbc:mysql://node1:3306/?useUnicode=true&characterEncoding=utf-8&useSSL=false")
.withUsername("root")
.withPassword("123456")
.build()
);
- StreamingFileSink
StreamingFileSink`是Flink1.7中推出的新特性,可以用来将分区文件写入到支持 Flink FileSystem 接口的文件系统中,支持Exactly-Once语义。
使用 StreamingFileSink 时需要启用 Checkpoint ,每次做 Checkpoint 时写入完成。如果 Checkpoint 被禁用,部分文件(part file)将永远处于 ‘in-progress’ 或 ‘pending’ 状态,下游系统无法安全地读取。
// TODO: 设置检查点
env.enableCheckpointing(5000) ;
// 4. 数据终端-sink
StreamingFileSink<String> fileSink = StreamingFileSink
// 4-1. 设置存储文件格式,Row行存储
.forRowFormat(
new Path("datas/file-sink"), new SimpleStringEncoder<String>()
)
// 4-2. 设置桶分配政策,默认基于时间的分配器,每小时产生一个桶,格式如下yyyy-MM-dd--HH
.withBucketAssigner(new DateTimeBucketAssigner<>())
// 4-3. 设置数据文件滚动策略
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.SECONDS.toMillis(5))
.withInactivityInterval(TimeUnit.SECONDS.toMillis(10))
.withMaxPartSize(2 * 1024 * 1024)
.build()
)
// 4-4. 设置文件名称
.withOutputFileConfig(
OutputFileConfig.builder()
.withPartPrefix("test")
.withPartSuffix(".log")
.build()
)
.build();
Flink 1.12 中,提供流批统一的 FileSink connector,以替换现有的 StreamingFileSink connector (FLINK-19758),允许为 BATCH 和 STREAMING 两种执行模式,实现不同的运行时策略,以达到仅使用一种 sink 实现。
// TODO: 设置检查点
env.enableCheckpointing(1000) ;
// 4. 数据终端-sink
FileSink<String> fileSink = FileSink
// 4-1. 设置存储文件格式,Row行存储
.forRowFormat(
new Path("datas/file-sink"), new SimpleStringEncoder<String>("UTF-8")
)
// 4-2. 设置桶分配政策,默认基于时间的分配器,每小时产生一个桶,格式如下yyyy-MM-dd--HH
.withBucketAssigner(new DateTimeBucketAssigner<>())
// 4-3. 设置数据文件滚动策略
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.SECONDS.toMillis(5))
.withInactivityInterval(TimeUnit.SECONDS.toMillis(10))
.withMaxPartSize(2 * 1024 * 1024)
.build()
)
// 4-4. 设置文件名称
.withOutputFileConfig(
OutputFileConfig.builder()
.withPartPrefix("test")
.withPartSuffix(".log")
.build()
)
.build();
- RedisSink
// 4-1. 构建Redis Server配置
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("node1")
.setPort(6379)
.setDatabase(0)
.setMinIdle(3)
.setMaxIdle(8)
.setMaxTotal(8)
.build();
// 4-2. 构建RedisMapper实例
RedisMapper<Tuple2<String, Integer>> redisMapper = new RedisMapper<Tuple2<String, Integer>>() {
// HSET flink:word:count spark 15 -> 拆分到如下三个方法中
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "flink:word:count");
}
@Override
public String getKeyFromData(Tuple2<String, Integer> data) {
return data.f0;
}
@Override
public String getValueFromData(Tuple2<String, Integer> data) {
return data.f1 + "";
}
};
// 4-3. 创建RedisSink对象
RedisSink<Tuple2<String, Integer>> redisSink = new RedisSink<Tuple2<String, Integer>>(
config, redisMapper
);
4、流式程序特性
- 累加器
1.创建累加器
private IntCounter numLines = new IntCounter();
2.注册累加器
getRuntimeContext().addAccumulator(“num-lines”, this.numLines);
3.使用累加器
this.numLines.add(1);
4.获取累加器的结果
myJobExecutionResult.getAccumulatorResult(“num-lines”)
// TODO: 此处,使用map函数,不做任何处理,仅仅为了使用累加器
MapOperator<String, String> mapDataSet = dataset.map(new RichMapFunction<String, String>() {
// TODO:step1、定义累加器
private IntCounter counter = new IntCounter() ;
@Override
public void open(Configuration parameters) throws Exception {
// TODO: step2、注册累加器
getRuntimeContext().addAccumulator("counter", counter);
}
@Override
public String map(String value) throws Exception {
// TODO: step3、使用累加器进行计数
counter.add(1);
return value;
}
});
// 4. 数据终端-sink
mapDataSet.writeAsText("datas/click.txt").setParallelism(1);
// 5. 触发执行-execute
JobExecutionResult jobResult = env.execute("BatchAccumulatorDemo");
// TODO: step4. 获取累加器的值
Object counter = jobResult.getAccumulatorResult("counter");
System.out.println("Counter = " + counter);
- 广播变量
Flink支持广播,可以将数据广播到TaskManager上就可以供TaskManager中的SubTask/task去使用,数据存储到内存中。 - 第一、广播变量是要把
dataset广播到内存中,所以广播的数据量不能太大,否则会出现OOM - 第二、广播变量的值不可修改,这样才能确保每个节点获取到的值都是一致的
// 2. 数据源-source:从本地集合构建2个DataSet
// 大表数据
DataSource<Tuple3<Integer, String, Integer>> scoreDataSet = env.fromCollection(
Arrays.asList(
Tuple3.of(1, "语文", 50),
Tuple3.of(1, "数学", 70),
Tuple3.of(1, "英语", 86),
Tuple3.of(2, "语文", 80),
Tuple3.of(2, "数学", 86),
Tuple3.of(2, "英语", 96),
Tuple3.of(3, "语文", 90),
Tuple3.of(3, "数学", 68),
Tuple3.of(3, "英语", 92)
)
);
// 小表数据
DataSource<Tuple2<Integer, String>> studentDataSet = env.fromCollection(
Arrays.asList(
Tuple2.of(1, "张三"),
Tuple2.of(2, "李四"),
Tuple2.of(3, "王五")
)
);
// 3. 数据转换-transform:使用map函数,定义加强映射函数RichMapFunction,使用广播变量值
/*
(1, "语文", 50) -> "张三" , "语文", 50
*/
MapOperator<Tuple3<Integer, String, Integer>, String> resultDataSet = scoreDataSet
.map(new RichMapFunction<Tuple3<Integer, String, Integer>, String>() {
// 定义Map集合,存储广播数据,方便依据key获取value值
private Map<Integer, String> stuMap = new HashMap<>() ;
@Override
public void open(Configuration parameters) throws Exception {
// TODO: step2、获取广播的数据集
List<Tuple2<Integer, String>> list = getRuntimeContext().getBroadcastVariable("students");
// TODO: step3、使用广播数据集,将数据放入到Map集合中
for (Tuple2<Integer, String> tuple : list) {
stuMap.put(tuple.f0, tuple.f1) ;
}
}
@Override
public String map(Tuple3<Integer, String, Integer> value) throws Exception {
// value : (1, "语文", 50) -> "张三" , "语文", 50
Integer studentId = value.f0;
String subjectName = value.f1;
Integer score = value.f2;
// 依据学生ID获取名称
String studentName = stuMap.getOrDefault(studentId, "未知");
// 拼凑字符串并返回
return studentName + ", " + subjectName + ", " + score;
}
})
// TODO: step1、将小表数据广播出去,哪个函数使用,就在后面进行广播
.withBroadcastSet(studentDataSet, "students");
- 分布式缓存cache
- 广播变量:使用数据为数据集DataSet,将其广播到TaskManager内存中,被Task使用;
- 分布式缓存:缓存数据文件数据,数据放在文件中;
// 1. 执行环境-env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// TODO: step1、将数据文件进行缓存,不能太大,属于小文件数据
env.registerCachedFile("datas/distribute_cache_student", "cache_students");
// 2. 数据源-source:从本地集合构建DataSet
DataSource<Tuple3<Integer, String, Integer>> scoreDataSet = env.fromCollection(
Arrays.asList(
Tuple3.of(1, "语文", 50),
Tuple3.of(1, "数学", 70),
Tuple3.of(1, "英语", 86),
Tuple3.of(2, "语文", 80),
Tuple3.of(2, "数学", 86),
Tuple3.of(2, "英语", 96),
Tuple3.of(3, "语文", 90),
Tuple3.of(3, "数学", 68),
Tuple3.of(3, "英语", 92)
)
);
// 3. 数据转换-transform:使用map函数,定义加强映射函数RichMapFunction,使用广播变量值
/*
(1, "语文", 50) -> "张三" , "语文", 50
*/
MapOperator<Tuple3<Integer, String, Integer>, String> resultDataSet = scoreDataSet.map(new RichMapFunction<Tuple3<Integer, String, Integer>, String>() {
// 定义Map集合,存储缓存文件中数据
private Map<Integer, String> stuMap = new HashMap<>() ;
@Override
public void open(Configuration parameters) throws Exception {
// TODO: step2、获取分布式缓存文件数据
File file = getRuntimeContext().getDistributedCache().getFile("cache_students");
// TODO: step3、获取缓存文件中数据
List<String> list = FileUtils.readLines(file, Charset.defaultCharset()); // 1,张三
for (String item : list) {
String[] array = item.split(",");
stuMap.put(Integer.valueOf(array[0]), array[1]) ;
}
}
@Override
public String map(Tuple3<Integer, String, Integer> value) throws Exception {
// value : (1, "语文", 50) -> "张三" , "语文", 50
// 获取学生id,查询出学生名称
String studentName = stuMap.getOrDefault(value.f0, "未知");
// 拼凑字符串,返回数据
return studentName + ", " + value.f1 + ", " + value.f2;
}
});
// 4. 数据终端-sink
resultDataSet.printToErr();
总结
flink基础api开发
时光如水,人生逆旅矣。