内核空间:kmalloc vmalloc 用户空间:malloc ptmalloc
一.地址映射流程
 二.内核空间
二.内核空间
在内核空间,通过malloc类似的两个系统调用来进行内存的分配,它们分别是kmalloc和vmalloc
1.kmalloc
kmalloc用于为内核空间的直接内存映射区分配内存.
kmaloc以字节为分配单位,通常用于分配小块内存,并且kmalloc确保分配的页在物理地址上是连续的(虚拟地址也必然是连续的),并且kmalloc为了防止内存碎片的问题,其底层页面分配算法是基于slab分配器实现的.
2.vmalloc
vmalloc用于为内核空间中的动态内存映射区进行内存分配.
vmalloc分配的内存只保证了虚拟地址是连续的,而物理地址不一定连续.它通过分配非连续的物理内存块,再通过修正内核页表的映射关系,把内存映射到虚拟地址空间的连续区域,就能够做到这一点.
三.用户空间
3.1 malloc存在的问题
在C语言中我们可以使用malloc来在用户空间中动态的分配内存,而malloc作为库函数,其本质就是对系统调用进行了一层封装,因此在不同的系统中其实现不同.
在Linux中,当我们申请的内存小于128KB时,malloc会使用sbrk或者brk在堆区分配内存.而当我们申请大于128KB的大块空间时,会使用mmap在文件映射区进行分配.
由此会产生两个问题:
- 由于上述的brk/sbrk/mmap都属于系统调用,因此当我们每次调用它们的时,就会从用户态切换至内核态,在内核态完成内存分配后再返回用户态. 倘若每次申请内存都要因为系统调用而产生大量的CPU开销,那么性能就会大打折扣(变差).
- 堆是从低地址往高地址增长,如果高地址的内存没有被释放,则低地址的内存就不能被回收,就会产生内存碎片的问题.
那么这两个问题是如何解决的呢?
为了减少内存碎片和系统调用的开销,malloc在底层采用了内存池的管理方式来解决这个问题.
ptmalloc采用边界标记法将内存划分为很多块,从而对内存的分配与回收进行管理.为了内存分配函数malloc的高效性,ptmalloc会预先向操作系统申请一块内存供用户使用,当我们申请和释放内存的时候,ptmalloc会将这些内存管理起来,并通过一些策略来判断是否将其回收给操作系统.这样做的最大好处是:使用用户申请和释放内存的时候更加高效,避免产生过多的内存碎片.
Linux中使用的是glibc(c运行库,是linux系统最底层的应用程序编程接口)的malloc()接口函数,并且通过glibc的ptmalloc(内存分配器)管理堆内存.
3.2 ptmalloc(内存管理器)
ptmalloc是glibc中默认的内存管理器.其底层采取了分箱式内存管理机制,也就是实现了一个类似的哈希桶结构的内存池,当我们通过malloc和free申请和释放内存的时候,ptmalloc就会代替我们将这些内存进行管理.通过一系列的内存合并,申请策略,来让用户申请和释放内存的时候更加的高效且安全.
Arena(分配区)
设置分配区的原因:
在老版本的glibc中使用的内存分配器是dlmalloc,其底层对于多线程的支持并不友好,因为所有线程共享同一个内存管理结构.所以当多个线程并发执行malloc时,为了保证线程安全,其通过使用互斥锁进行加锁,使得只能有一个线程能够访问临界资源,因此在并发环境下使用dlmalloc时会花费大量的时间在互斥锁的阻塞等待上,因此整个应用的效率就极低.
在ptmalloc中,为了解决多线程并发争抢锁的问题,其设定了主分配区(main_arean)和非主分配区(non_main_arena).
- 每个进程有一个主分配区,以及多个非主分配区
- 主分配区可以使用brk和mmap来分配空间,而非主分配区只能使用mmap
- 非主分配区的数量只能增加,不能减少
- 主分配区和非主分配区使用环形链表进行管理,并使用互斥锁保证线程安全
通过引入多个非主分配区,就可以将线程分发到不同的分配区中,将原先多个线程共享一个分配区变为了多个线程共享多个分配区,在一定程度上减轻了并发的压力.
Chunk(内存块)
ptmalloc通过名为chunk的数据结构来管理和组织内存单元.为了节约内存,在使用时它的数据结构分为空闲的chunk和使用中的chunk两个版本.
使用中的chunk:

- chunk指针指向chunk的起始地址,mem指向用户使用的内存块的起始地址,而next chunk则指向下一个chunk
- P:表示前一个chunk是否空闲,主要用于合并内存块的操作.当P=1时代表着上一次chunk正在使用,此时prev_size无效.P=0代表前一个chunk空闲,prev_size有效.在ptmalloc分配第一个chunk时,总会将P置为1,防止程序越界访问
- M:用于表示内存所处的区域,当M=1时为mmap内存映射区域分配,M=0为堆区域分配
- A:用于表示分配区,A=1为非主分配区分配,A=0为主分配区分配
空闲的chunk:
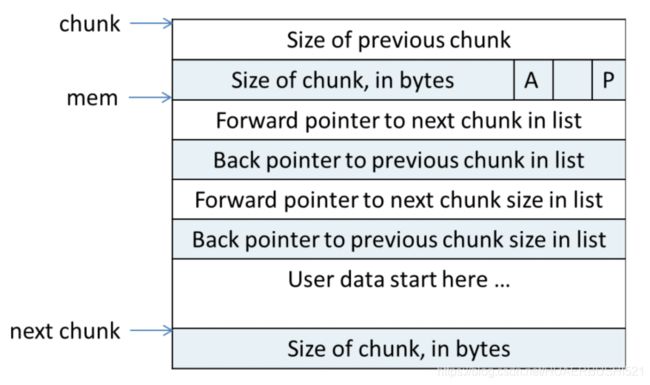
- 空闲的chunk会被放到空闲的链表bins上,当用户申请内存时,其先去bins查找是否存在合适的内存
- 对于空闲的chunk,为了方便其在空闲链表上快速查找合适大小的chunk,它有指向上一个和下一个空闲chunk的指针,同时还有指向上一个和下一个空闲chunk的内存大小指针
Bins
对于空闲的chunk,ptmalloc采用分箱式内存管理,通过bins来维护空闲的chunk.ptmalloc一共维护了128个bin,同时每个bin又维护了一个大小相近的chunk链表.
当用户使用free函数释放内存时,ptmalloc并不会立马将内存交还给操作系统,而是被ptmalloc本身的空闲链表bins管理了起来.这样当下次进程需要malloc申请一块内存的时候,ptmalloc就会从空闲的bins上寻找一块合适大小的内存块分配给用户使用.这样的好处就是可以避免频繁的系统调用导致的用户态到内核态的转换带来的系统开销,降低内存分配的开销.
fastbinsY数组: 用来以保存fast bins
bins数组: 用以保存 unsorted,small,large bins
根据chunk的大小以及状态不同,bins又分为以下四个种类:
- fast bins: 独立bins之外的,大约有10个. fast bins 是 small bins的高速缓存区,享有最快的内存分配,释放速度. 当用户释放一块小于等于MAX_FAST(默认为64字节)的chunk时,会默认将其存放到fast bins中。当用户需要分配小内存时,会首先查看fast bins中是否存在合适的内存块,如果有则直接返回,如果没有才会去查看small bins上的空闲chunk。同时,ptmalloc会遍历fast bins,查看是否有合适的chunk需要合并,则将其合并后放入unsorted bin中
- unsorted bin:只有一个,在bins数组的第一个位置. 当用户释放的内存大于MAX_FAST 或者 fast bins合并后的chunk都会进入unsorted bin上.当用户malloc的时候会先到unsorted bin上查找是否存在合适的bin,如果没有合适的bin,ptmalloc则会将unsorted bin上的chunk放入bins上,然后再到bins上查找合适的空闲chunk。
- small bins: 用来存放固定大小的chunk,bin的大小从16字节开始,以8字节不断递增. 当我们需要分配小内存块时,会采用精准匹配的方式从small bins中查找合适的chunk.
- large bins:用于存放大于512字节,小于128KB的空闲chunk.bin按照顺序不定长升序排列,同时每个bin中的chunk按照大小降序排列
由此可以得出以下几点结论:
- fast bins相当于small bins的cache,用于提高小内存的分配,释放效率,但也同时可能加剧内存碎片化
- unsorted bin其实就是 最近释放的内存集合,他会保留最近释放的chunk(free chunk),从而消除了寻找合适的bin的时间开销,提高了内存分配和释放的效率
- small bins和large bins可以合并相邻的空闲chunk,减轻了内存碎片化,但也同时降低了效率.
当然,如果通过以上几种方式都没能找到合适的内存块,ptmalloc中还预留了其它的一些后备方式.
- top chunk:在分配区中最顶部的chunk被称为top chunk,它不属于任何一个bin。当所有bin中都没有合适的内存时,就由它来响应用户请求。当用户申请的内存小于top chunk的内存时,其会将自己分割为两部分,一部分返回,另一部分则成为新的top chunk。如果用户申请的内存大于top chunk的内存,则top chunk会根据分配区的不同,分别调用sbrk或者mmap来进行扩容。
- last remainder chunk:即最后一次small request中因分割而得到的剩余部分,它有利于改进局部性,当在small bins中找不到合适的chunk时,如果last remainded chunk的大小大于所需要的small chunk大小时,其就会将用户需要的那一部分分出去,剩余的部分则成为新的last remainded chunk,因此后续请求的chunk最终将被分配得彼此接近。
- mmaped chunk:当分配的内存非常大的时候(大于128K),此时就需要通过mmap来申请内存,通过mmap申请的内存会被放到mmaped chunk上。同时,在释放的时候会通过判断chunk中的M是否为1来判断是否属于mmaped chunk,如果是则直接将内存交还给操作系统
内存分配与释放流程:
分配流程:
- 获取分配区的锁
- 计算出需要分配内存的chunk大小
- 判断chunk的大小,如果小于MAX_FAST(64字节),则到fast_bins上查找,如果小于512字节,则到small bins上查找
- 如果还没有找到,此时则进入unsorted bin上查找,如果找到合适的chunk并进行分配后还有剩余的空间,则根据其空间大小将其放入small bins或者large bins中
- 如果还没有找到, 则进入large bins中查找,找到合适的bin后反向进行遍历,找到第一个大小满足的chunk进行分配,如果chunk分配完后还有剩余的空间,则将其放入unsorted bin中。
- 如果查找了所有的bin都没有找到合适的chunk,此时就需要操作top chunk来进行分配,如果满足大小小于top chunk,则切割top chunk来进行分配。如果大小大于top chunk,则此时会申请内存来满足分配需求
- mmap chunk,对于大于128K,需要从mmap中申请
简而言之: 获取分配区(arena)并加锁–> fast bin –> unsorted bin –> small bin –> large bin –> top chunk –> 扩展堆
释放流程:
- 获取分配区的锁
- 判断free的参数是否为空节点,如果是则什么都不做
- 判断当前chunk是否是mmap映射出的大块内存(M=1),如果是的话直接munmap释放掉
- 判断当前chunk是否和top chunk连续,如果连续则直接和top chunk合并
- 判断chunk大小是否大于MAX_FAST,如果大于则放入unsorted bin中,并检查是否能够进行合并,如果不能合并则直接free,如果能则进入步骤7
- 如果chunk大小小于MAX_FAST,则放入fast bins中,并判断是否有合并的情况,如果不能合并则直接free;否则将合并后的chunk放入unsorted bin中
- 判断top chunk的大小是否大于mmap收缩阈值,如果top chunk的值大于mmap的收缩阈值,则将多余的部分归还于操作系统.
总结:
ptmalloc虽然能够很好的进行内存管理,但是仍然存在一些小问题:
- 由于ptmalloc收缩内存是从top chunk开始,如果与top chunk相邻的chunk不能够释放,则top chunk以下的chunk都无法释放(即使后分配的内存先释放,也无法及时归还给系统)
- 每个chunk至少为8字节(可能会导致内存碎片)
- 虽然采用了主分配区+非主分配区的策略来优化多线程环境下的并发问题,但是在内存分配和释放的时候仍会首先进行加锁(影响性能)
- 由于采用了非主分配区,导致内存不能在不同分配区间移动,内存使用不均衡(内存浪费)
- 不定期分配长生命周期的内存(不利于回收,容易导致内存碎片)