Linux系列教程——1 Linux磁盘管理、2 Linux进程管理、3 Linux系统服务、 4 Linux计划任务
文章目录
- 1 Linux磁盘管理
-
- 1.磁盘的基本概念
-
- 1.什么是磁盘
- 2.磁盘的基本结构
- 3.磁盘的预备知识
-
- 1.磁盘的接口类型
- 2.磁盘的基本术语
- 3.磁盘在系统上的命名方式
- 4.磁盘基本分区Fdisk
-
- 1.fdisk创建主分区
- 2.fdisk创建扩展分区
- 3.fdisk创建逻辑分区
- 4.fdisk查看分区情况,并保存
- 5.格式化磁盘
- 6.使用mount挂载并使用
- 5.磁盘的基本分区Gdisk
-
- 1.使用gdisk进行磁盘分区
- 2.使用mkfs进行格式化磁盘。前面已经介绍过,此处不反复介绍。
- 3.使用mount命令将某个目录挂载该分区,进行使用。
- 6.磁盘挂载方式Mount
-
- 1.通过mount进行挂载,但重启将会失效。我们称为临时生效。
- 2.挂载的磁盘,如果不想使用可以使用umount进行卸载。
- 3.如果需要实现永久挂载则需要将挂载信息写入/etc/fstab配置文件中实现。
- 7.虚拟磁盘介绍SWAP
-
- 1.创建分区,并格式化为swap分区。
- 2.查看当前swap分区大小,然后进行扩展和缩小
- 3.检查当前swap分区有哪些设备
- 4.如果磁盘没有过多的分区可用,也可以通过文件增加SWAP空间,本质上还是磁盘
- 2 Linux进程管理
-
- 1.介绍
-
- 1.什么是进程
- 2.程序和进程的区别
- 3.进程的生命周期
- 2.监控进程状态
-
- 1.使用ps命令查看当前的进程状态(静态)
- 2.STAT状态的S、Ss、S+、R、R、S+等等,都是什么意思?
- 2.使用top命令查看当前的进程状态(动态)
- 3.管理进程状态
-
- 1.使用kill -l列出当前系统所支持的信号
- 4.管理后台进程
-
- 1.什么是后台进程
- 2.我们为什么要将进程放入后台运行
- 3.使用什么工具将进程放入后台
- 5.进程的优先级[进阶]
-
- 1.什么优先级
- 2.为什么要有系统优先级
- 3.系统中如何给进程配置优先级?
- 6.系统平均负载[进阶]
-
- 1.什么是平均负载
- 2.可运行状态和不可中断状态是什么
- 3.那平均负载为多少时合理
- 4.那么在实际生产环境中,平均负载多高时,需要我们重点关注呢?
- 5.平均负载与 CPU 使用率有什么关系
- 6.平均负载案例分析实战
- 3 Linux系统服务
-
- 1.Linux启动流程
- 2.Linux运行级别
-
- 1.什么是运行级别,运行级别就是操作系统当前正在运行的功能级别
- 2.如何调整系统启动的运行级别?systemd使用’targets’而不是runlevels。默认情况下,有两个主要目标:
- 3.Linux systemd
-
- 1.systemd的由来
- 2.什么是systemd
- 3.systemd的优势
- 4.Linux单用户模式
- 5.Linux下救援模式
- 4 Linux计划任务
-
- 1.计划任务基本概述
-
- 1.什么是crond
- 3.计划任务主要分为以下两种使用情况:
- 2.计划任务时间管理
-
- 1.Crontab配置文件记录了时间周期的含义
- 2.了解crontab的时间编写规范
- 3.使用crontab编写cron定时任务
- 3.计划任务编写实践
-
- 1.使用root用户每5分钟执行一次时间同步
- 2.每天的下午3,5点,每隔半小时执行一次sync命令
- 3.案例:每天凌晨3点做一次备份?备份/etc/目录到/backup下面
- 4.crond注意的事项
- 4.计划任务如何调试
-
- 1.crond调试
- 2.crond编写思路
1 Linux磁盘管理
1.磁盘的基本概念
1.什么是磁盘
绝大多数人对硬盘都不陌生,一块小小的硬盘里,就可以存储海量的照片音乐和电影,尤其是我们喜爱的各类动作片。但如此小的空间,是如何储存那么多信息的呢?

每个硬盘中心都是一摞高速运转的圆盘,在圆盘上附着的一圈金属颗粒,每个金属颗粒都有自己的磁化程度,用于储存0和1。
当记录数据时,硬盘的磁头开始通电,形成强磁场,数据在磁场的作用下转变成电流,使颗粒磁化,从而将信息记录在圆盘上。
由海量颗粒组成的信息,就是我们存在硬盘里的数据。
什么是磁盘、软盘、硬盘?
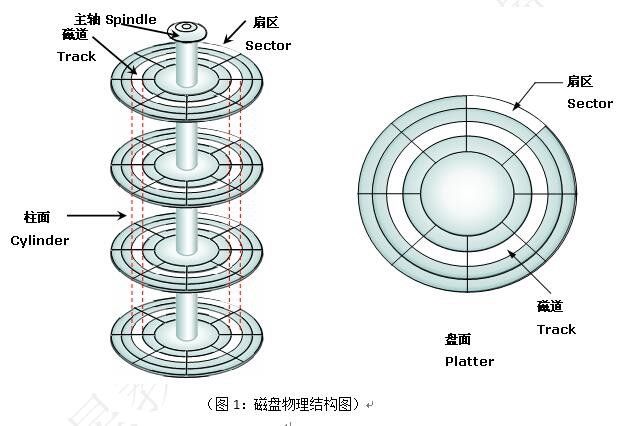
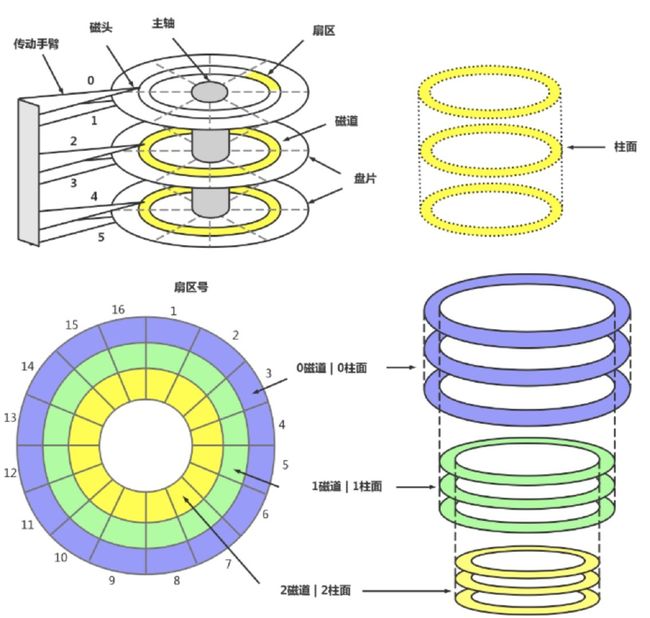
2.磁盘的基本结构
1.什么是盘片: 硬盘一般有一个或多个盘片,每个盘片可以有两面,即第一个盘片的正面为0面,反面为1面然后依次类推。2.什么是磁道:每个盘片的盘面在出厂的时候被划分出了多个同心圆环,数据就存储在这样的同心圆环上面,我们将这样的圆环称为磁道(Track),每个盘面可以划分多个磁道。但肉业不可见。3.什么是扇区: 在硬盘出厂时会对磁盘进行一次低格,其实就是再每个磁道划分为若干个弧段,每个弧段就是一个扇区 (Sector)。扇区是硬盘上存储的物理单位,现在每个扇区可存储512字节数据已经成了业界的约定。4.什么是柱面:柱面实际上就是我们抽象出来的一个逻辑概念,简单来说就是处于同一个垂直区域的磁道称为 柱面 ,即各盘面上面相同位置磁道的集合。这样数据如果存储到相同半径磁道上的同一扇区,这样可以实现并行读取,主要是减少磁头寻道时间。5.什么是磁头: 读取磁盘磁道上面金属块,主要负责读或写入数据。
3.磁盘的预备知识
我们需要简单了解下磁盘的接口类型、磁盘涉及的相关术语、磁盘在Linux下的命名方式。
1.磁盘的接口类型
IDE,Scsi(已经被淘汰) )
)
SATA III 与SAS(企业使用较多)
ssd的Msata接口为超极本设计,但是被m.2接口的SSD替代,而m.2接口(支持SATA、PCI-E双通道协议)
1、M.2接口是为超极本量身定做的新一代接口标准,以取代原来的mSATA接口。拥有更小巧的规格尺寸,还是更高的传输性能,M.2都远胜于mSATA。 m2接口百度百科 固态硬盘SATA和mSATA有什么区别2、M.2几个名词需要各位读者知道了解,SATA和PCI-E AHCI和NVMe3、最后呢,可以扩展了解 M.2固态硬盘使用过程中常见问题?
2.磁盘的基本术语
尺寸: 2.5英寸 3.5英寸容量:KB MB GB TB PB EB转速:7500 15000IOPS:每秒能够发生IO的次数
3.磁盘在系统上的命名方式
设备名称
分区信息
设备类型
/dev/sda
/dev/sda1
第一块物理磁盘第一分区
/dev/sdb
/dev/sdb2
第二块物理磁盘第二个分区
/dev/vdd
/dev/vdd4
第四块虚拟磁盘的第四个分区
PS1:系统中分区由数字编号表示,1~4留给主分区使用和扩展分区,逻辑分区从5开始,为什么分区还有限制?不应该是随意分配?因为MBR分区表只能分配4个主分区?why?MBR为什么只能划分4个主分区
PS2: 前面我们已经提到过MBR分区表只能分配4个主分区,但现在还有一种新型的分区表GPT,GPT支持分配128个主分区。注意MBR与GPT之间不能互转,会导致数据丢失。MBR与GPT之间又有什么区别
4.磁盘基本分区Fdisk
1.添加一块小于2TB的磁盘进行使用,步骤如下:1.给虚拟机添加一块新的硬盘2.使用fdisk进行分区3.使用mkfs进行格式化4.使用mount进行挂载PS: 生产分区建议,如无特殊需求直接使用整个磁盘即可,无需分区。PS: 学习分区建议: 1P+1E(3L) 2P+1E(2L) 3P+1E(1L) (仅适用于练习)
[root@lqz ~]# fdisk -l
[root@lqz ~]# fdisk /dev/sdb
Command (m for help): m #输入m列出常用的命令
Command action
a toggle a bootable flag #切换分区启动标记
b edit bsd disklabel #编辑sdb磁盘标签
c toggle the dos compatibility flag #切换dos兼容模式
d delete a partition #删除分区
l list known partition types #显示分区类型
m print this menu #显示帮助菜单
n add a new partition #新建分区
o create a new empty DOS partition table #创建新的空白分区表
p print the partition table #显示分区表的信息
q quit without saving changes #不保存退出
s create a new empty Sun disklabel #创建新的Sun磁盘标签
t change a partitions system id #修改分区ID,可以通过l查看id
u change display/entry units #修改容量单位,磁柱或扇区
v verify the partition table #检验分区表
w write table to disk and exit #保存退出
x extra functionality (experts only) #拓展功能
1.fdisk创建主分区
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free) #主分区
e extended #扩展分区
Select (default p): p #选择创建主分区
Partition number (1-4, default 1): #默认创建第一个主分区
First sector (2048-2097151, default 2048): #默认扇区回车
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-2097151, default 2097151): +50M #分配50MB
2.fdisk创建扩展分区
Command (m for help): n #新建分区
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
Select (default p): e #创建扩展分区
Partition number (2-4, default 2):
First sector (104448-2097151, default 104448):
Using default value 104448
Last sector, +sectors or +size{K,M,G} (104448-2097151, default 2097151): #空间都给到扩展分区
3.fdisk创建逻辑分区
Command (m for help): n #新建分区
Partition type:
p primary (1 primary, 1 extended, 2 free)
l logical (numbered from 5)
Select (default p): l #创建逻辑分区
Adding logical partition 5
First sector (106496-2097151, default 106496):
Using default value 106496
Last sector, +sectors or +size{K,M,G} (106496-2097151, default 2097151): +100M #分配100MB空间
4.fdisk查看分区情况,并保存
Command (m for help): p #查看分区创建
Device Boot Start End Blocks Id System
/dev/sdb1 2048 104447 51200 83 Linux
/dev/sdb2 104448 2097151 996352 5 Extended
/dev/sdb5 106496 311295 102400 83 Linux
#保存分区
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
#检查磁盘是否是MBR分区方式
[root@lqz ~]# fdisk /dev/sdb -l|grep type
Disk label type: dos
#安装parted, 刷新内核立即生效,无需重启
[root@lqz ~]# yum -y install parted
[root@lqz ~]# partprobe /dev/sdb
5.格式化磁盘
mkfs格式化磁盘,实质创建文件系统,文件系统类似于将房子装修成3室一厅,还是2室一厅。
#选项:
# -b 设定数据区块占用空间大小,目前支持1024、2048、4096 bytes每个块。
# -t 用来指定什么类型的文件系统,可以是ext4, xfs
# -i 设定inode的大小
# -N 设定inode数量,防止Inode数量不够导致磁盘不足
#1.格式化整个磁盘
[root@lqz ~]# mkfs.ext4 /dev/sdb
#2.格式化磁盘的某个分区
[root@lqz ~]# mkfs.xfs /dev/sdb1
6.使用mount挂载并使用
如果需要使用该磁盘的空间,需要准备一个空的目录作为挂载点,与该设备进行关联。
[root@lqz ~]# mkdir /data
[root@lqz ~]# mount /dev/sdb1 /data
5.磁盘的基本分区Gdisk
前面我们已经了解到fdisk分区,但fdisk不支持给高于2TB的磁盘进行分区。如果有单块盘高于2TB,建议使用Gdisk进行分区。
1.使用gdisk进行磁盘分区
#1.安装gdisk分区工具
[root@lqz ~]# yum install gdisk -y
#2.创建一个新分区,500MB大小
[root@lqz ~]# gdisk /dev/sdb
Command (? for help): n #创建新分区
Partition number (1-128, default 1):
First sector (34-2097118, default = 2048) or {+-}size{KMGTP}:
Last sector (2048-2097118, default = 2097118) or {+-}size{KMGTP}: +500M #分配500M大小
Command (? for help): p #打印查看
Number Start (sector) End (sector) Size Code Name
1 2048 1026047 500.0 MiB 8300 Linux filesystem
Command (? for help): w #保存分区
Do you want to proceed? (Y/N): y #确认
OK; writing new GUID partition table (GPT) to /dev/sdb.
The operation has completed successfully.
#3.创建完成后,可以尝试检查磁盘是否为gpt格式
[root@lqz-node1 /]# fdisk /dev/sdb -l|grep type
Disk label type: gpt
#4.安装parted, 刷新内核立即生效,无需重启
[root@lqz ~]# yum -y install parted
[root@lqz ~]# partprobe /dev/sdb
2.使用mkfs进行格式化磁盘。前面已经介绍过,此处不反复介绍。
[root@lqz ~]# mkfs.xfs /dev/sdb
3.使用mount命令将某个目录挂载该分区,进行使用。
[root@lqz ~]# mkdir /data_gdisk
[root@lqz ~]# mount /dev/sdb /data_gdisk
6.磁盘挂载方式Mount
前面我们已经提到过,如果需要使用磁盘的空间,需要准备一个空的目录作为挂载点,与该设备进行关联。mount主要是为文件系统指定一个访问入口。PS: 类似我的商场没有门,那么就无法进入购买商品,此时通过mount命令可以创建一个入口。给超市安装一个门。如图:
1.通过mount进行挂载,但重启将会失效。我们称为临时生效。
# 选项:-t指定文件系统挂载分区 -a 挂载/etc/fstab中的配置文件 -o 指定挂载参数
# 挂载/dev/sdb1至db1目录
[root@lqz ~]# mkdir /db1
[root@lqz ~]# mount -t xfs /dev/sdb1 /db1/
2.挂载的磁盘,如果不想使用可以使用umount进行卸载。
#选项: -l 强制卸载
#1.卸载目录方式
[root@lqz ~]# umount /db1
#2.卸载设备方式
[root@lqz ~]# umount /dev/sdb1
#3.umount不能卸载的情况
[root@lqz db1]# umount /db1
umount: /db1: device is busy.
(In some cases useful info about processes that use
the device is found by lsof(8) or fuser(1)
#PS: 如上情况解决办法有两种, 1.切换至其他目录 2.使用'-l'选项强制卸载
[root@student db1]# umount -l /db1
3.如果需要实现永久挂载则需要将挂载信息写入/etc/fstab配置文件中实现。
#1.使用blkid命令获取各设备的UUID
[root@lqz ~]# blkid |grep "sdb1"
/dev/sdb1: UUID="e271b5b2-b1ba-4b18-bde5-66e394fb02d9" TYPE="xfs"
#2.使用UUID挂载磁盘sdb1分区至于db1, 测试挂载
[root@lqz ~]# mount UUID="e271b5b2-b1ba-4b18-bde5-66e394fb02d9" /db1
#3.写入/etc/fstab中,实现开机自动挂载
[root@lqz ~]# tail -1 /etc/fstab
UUID=e271b5b2-b1ba-4b18-bde5-66e394fb02d9 /db1 xfs defaults 0 0
#4.加载fstab配置文件, 同时检测语法是否有错误
[root@lqz ~]# mount –a
3./etc/fstab配置文件编写格式
要挂载的设备
挂载点(入口)
文件系统类型
挂载参数
是否备份
是否检查
/dev/sdb1
/db1
xfs
defaults
0
0
第四列:挂载参数。挂载参数有很多,在这块我们了解即可,不必深究。
参数
含义
async/sync
是否为同步方式运行。默认async
user/nouser
是否允许普通用户使用mount命令挂载。默认nouser
exec/noexe
是否允许可执行文件执行。默认exec
suid/nosuid
是否允许存在suid属性的文件。默认suid
auto/noauto
执行mount -a 命令时,此文件系统是否被主动挂载。默认auto
rw/ro
是否以只读或者读写模式进行挂载。默认rw
default
具有rw,suid,dev,exec,auto,nouser,async等默认参数的设定
第五列:是否进行备份。通常这个参数的值为0或者1
选项
含义
0
代表不做备份
1
代表要每天进行备份操作
2
代表不定日期的进行备份操作
第六列:是否检验扇区:开机的过程中,系统默认会以fsck检验我们系统是否为完整
选项
含义
0
不要检验磁盘是否有坏道
1
检验
2
校验 (当1级别检验完成之后进行2级别检验)
7.虚拟磁盘介绍SWAP
Swap分区在系统的物理内存不够时,将硬盘空间中的一部分空间释放出来,以供当前运行的程序使用。PS: 当物理内存不够时会随机kill占用内存的进程,从而产生oom,临时使用swap可以解决。
1.创建分区,并格式化为swap分区。
[root@lqz ~]# fdisk /dev/sdb #分1个G大小
[root@lqz ~]# mkswap /dev/sdb1 #格式化为swap
2.查看当前swap分区大小,然后进行扩展和缩小
[root@lqz ~]# free -m
total used free shared buff/cache available
Mem: 1980 1475 80 10 424 242
Swap: 2047 4 2043
#1.扩展swap分区大小
[root@lqz ~]# swapon /dev/sdb2
[root@lqz ~]# free -m
total used free shared buff/cache available
Mem: 1980 1475 80 10 424 242
Swap: 3047 4 2043
[root@lqz ~]# swapon -a #代表激活所有的swap
#2.缩小swap分区大小
[root@lqz ~]# swapoff /dev/sdb1
[root@lqz ~]# free -m
total used free shared buff/cache available
Mem: 1980 1475 80 10 424 242
Swap: 2047 4 2043
[root@lqz ~]# swapoff -a #代表关闭所有的swap
3.检查当前swap分区有哪些设备
[root@lqz ~]# swapon -s
文件名 类型 大小 已用 权限
/dev/dm-1 partition 2097148 4616 -2
/dev/sdb1 partition 1048572 0 -2
4.如果磁盘没有过多的分区可用,也可以通过文件增加SWAP空间,本质上还是磁盘
[root@lqz ~]# dd if=/dev/zero of=/opt/swap_file bs=1M count=500
[root@lqz ~]# chmod 0600 /opt/swap_file
[root@lqz ~]# mkswap -f /opt/swap_file
[root@lqz ~]# swapon /opt/swap_file
[root@lqz ~]# free -m
PS: 如果希望swap开机自动挂载,将swap信息追加至/etc/fstab即可。
tion 2097148 4616 -2
/dev/sdb1 partition 1048572 0 -2
### 4.如果磁盘没有过多的分区可用,也可以通过文件增加SWAP空间,本质上还是磁盘
```python
[root@lqz ~]# dd if=/dev/zero of=/opt/swap_file bs=1M count=500
[root@lqz ~]# chmod 0600 /opt/swap_file
[root@lqz ~]# mkswap -f /opt/swap_file
[root@lqz ~]# swapon /opt/swap_file
[root@lqz ~]# free -m
PS: 如果希望swap开机自动挂载,将swap信息追加至/etc/fstab即可。
2 Linux进程管理
1.介绍
1.什么是进程
比如: 开发写的代码我们称为程序,那么将开发的代码运行起来。我们称为进程。总结一句话就是: 当我们运行一个程序,那么我们将运行的程序叫进程。PS1: 当程序运行为进程后,系统会为该进程分配内存,以及进程运行的身份和权限。PS2: 在进程运行的过程中,系统会有各种指标来表示当前运行的状态。
2.程序和进程的区别
1.程序是数据和指令的集合,是一个静态的概念。比如/bin/ls、/bin/cp等二进制文件。同时程序可以长期存在系统中。2.进程是程序运行的过程,是一个动态的概念。进程是存在生命周期的概念的,也就是说进程会随着程序的终止而销毁,不会永久存在系统中。
3.进程的生命周期
生命周期就是指一个对象的生老病死。用处很广。
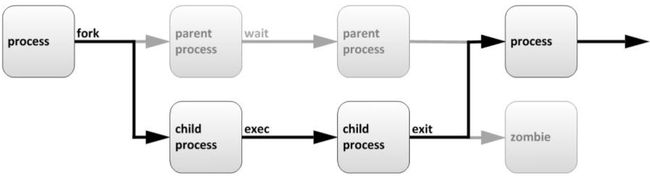
当父进程接收到任务调度时,会通过fock派生子进程来处理,那么子进程会继承父进程属性。1.子进程在处理任务代码时,父进程会进入等待状态中…2.子进程在处理任务代码后,会执行退出,然后唤醒父进程来回收子进程的资源。3.如果子进程在处理任务过程中,父进程退出了,子进程没有退出,那么这些子进程就没有父进程来管理了,就变成僵尸进程。PS: 每个进程都父进程的PPID,子进程则叫PID。
例: 假设现在我是蒋先生(system进程)….故事持续中……
2.监控进程状态
程序在运行后,我们需要了解进程的运行状态。查看进程的状态分为: 静态和动态两种方式
1.使用ps命令查看当前的进程状态(静态)
1)示例、ps -aux常用组合,查看进程 用户、PID、占用cpu百分比、占用内存百分比、状态、执行的命令等

状态
描述
USER
启动进程的用户
PID
进程运行的ID号
%CPU
进程占用CPU百分比
%MEM
进程占用内存百分比
VSZ
进程占用虚拟内存大小 (单位KB)
RSS
进程占用物理内存实际大小 (单位KB)
TTY
进程是由哪个终端运行启动的tty1、pts/0等 ?表示内核程序与终端无关(远程连接会通过tty打开一个bash:tty)
STAT
进程运行过程中的状态 man ps (/STATE)
START
进程的启动时间
TIME
进程占用 CPU 的总时间(为0表示还没超过秒)
COMMAND
程序的运行指令,[ 方括号 ] 属于内核态的进程。 没有 [ ] 的是用户态进程。systemctl status 指令
2.STAT状态的S、Ss、S+、R、R、S+等等,都是什么意思?
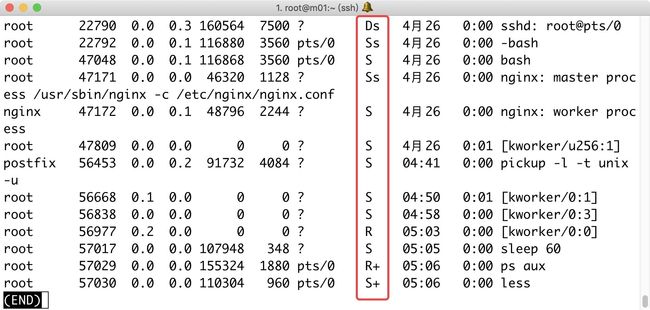
STAT基本状态
描述
STAT状态+符号
描述
R
进程运行
s
进程是控制进程, Ss进程的领导者,父进程
S
可中断睡眠
<
进程运行在高优先级上,S<优先级较高的进程
T
进程被暂停
N
进程运行在低优先级上,SN优先级较低的进程
D
不可中断睡眠
+
当前进程运行在前台,R+该表示进程在前台运行(正在io操作,一旦停止,数据丢失)
Z
僵尸进程
l
进程是多线程的,Sl表示进程是以线程方式运行
案例一、PS命令查看进程状态切换
#1.在终端1上运行vim
[root@lqz ~]# vim oldboy
#2.在终端2上运行ps命令查看状态
[root@lqz ~]# ps aux|grep oldboy #S表示睡眠模式,+表示前台运行
root 58118 0.4 0.2 151788 5320 pts/1 S+ 22:11 0:00 oldboy
root 58120 0.0 0.0 112720 996 pts/0 R+ 22:12 0:00 grep --color=auto oldboy
#在终端1上挂起vim命令,按下:ctrl+z
#3.回到终端2再次运行ps命令查看状态
[root@lqz ~]# ps aux|grep oldboy #T表示停止状态
root 58118 0.1 0.2 151788 5320 pts/1 T 22:11 0:00 vim oldboy
root 58125 0.0 0.0 112720 996 pts/0 R+ 22:12 0:00 grep --color=auto oldboy
案例二、PS命令查看不可中断状态进程
#1.使用tar打包文件时,可以通过终端不断查看状态,由S+,R+变为D+
[root@lqz ~]# tar -czf etc.tar.gz /etc/ /usr/ /var/
[root@lqz ~]# ps aux|grep tar|grep -v grep
root 58467 5.5 0.2 127924 5456 pts/1 R+ 22:22 0:04 tar -czf etc.tar.gz /etc/
[root@lqz ~]# ps aux|grep tar|grep -v grep
root 58467 5.5 0.2 127088 4708 pts/1 S+ 22:22 0:03 tar -czf etc.tar.gz /etc/
[root@lqz ~]# ps aux|grep tar|grep -v grep
root 58467 5.6 0.2 127232 4708 pts/1 D+ 22:22 0:03 tar -czf etc.tar.gz /etc/
2.使用top命令查看当前的进程状态(动态)

任务
含义
Tasks: 129 total
当然进程的总数
1 running
正在运行的进程数
128 sleeping
睡眠的进程数
0 stopped
停止的进程数
0 zombie
僵尸进程数
%Cpu(s)
平均cpu使用率,按1 查看每个cup具体状态
0.7 us
用户进程占用cpu百分比
0.7 sys
内核进程占用百分比
0.0 ni
优先级进程占用cpu的百分比
98.7 id
空闲cup
0.0 wa
CPU等待IO完成的时间,大量的io等待,会变高
0.0 hi
硬中断,占的CPU百分比
0.0 si
软中断,占的CPU百分比
0.0 st
虚拟机占用物理CPU的时间
# w load average:平均负载 一分钟,5分钟,15分钟
04:05:43 up 11:35, 3 users, load average: 0.00, 0.01, 0.05
# uptime
04:06:21 up 11:35, 3 users, load average: 0.00, 0.01, 0.05
PS: 如何理解中断这个东西
top 常见指令
字母
含义
h
查看帮出
1
数字1,显示所有CPU核心的负载
z
以高亮显示数据
b
高亮显示处于R(进行中)状态的进程
M
按内存使用百分比排序输出
P
按CPU使用百分比排序输出
q
退出top
# 第三方top
htop,top高级:yum install htop -y
iftop网卡流量:yum install iftop -y
glances,直观的显示:yum install glances -y
-rz上传文件,可以动态看到,网卡情况
3.管理进程状态
当程序运行为进程后,如果希望停止进程,怎么办呢? 那么此时我们可以使用linux的kill命令对进程发送关闭信号。当然除了kill、还有killall,pkill
1.使用kill -l列出当前系统所支持的信号
 虽然linux支持信号很多,但是我们仅列出我们最为常用的3个信号
虽然linux支持信号很多,但是我们仅列出我们最为常用的3个信号
数字编号
信号含义
信号翻译
1
SIGHUP
通常用来重新加载配置文件,重新读取一次参数的配置文件 (类似 reload)
9
SIGKILL
强制杀死进程(有状态的服务(存磁盘的,如mysql)强制停止可能会导致下次起不来)
15
SIGTERM
终止进程,默认kill使用该信号
1.我们使用kill命令杀死指定PID的进程。
#1.给 vsftpd 进程发送信号 1,15
[root@lqz ~]# yum -y install vsftpd
[root@lqz ~]# systemctl start vsftpd
[root@lqz ~]# ps aux|grep vsftpd
#2.发送重载信号,例如 vsftpd 的配置文件发生改变,希望重新加载
[root@lqz ~]# kill -1 9160
#3.发送停止信号,当然vsftpd 服务有停止的脚本 systemctl stop vsftpd
[root@lqz ~]# kill 9160
#4.发送强制停止信号,当无法停止服务时,可强制终止信号
[root@lqz ~]# kill -9 9160
2.Linux系统中的killall、pkill命令用于杀死指定名字的进程。我们可以使用kill命令杀死指定进程PID的进程,如果要找到我们需要杀死的进程,我们还需要在之前使用ps等命令再配合grep来查找进程,而killall、pkill把这两个过程合二为一,是一个很好用的命令。
#例0、通过服务名称杀掉进程
[root@lqz ~]# vim nginx.conf # 修改为worker_processes 10;
[root@lqz ~]# kill -1 26093 # 平滑reload nginx,可以看到很多ngixn进程
[root@lqz ~]# kill 26121 # 杀掉一个子进程,会迅速的被master启动起来,只是id号不一致了
[root@lqz ~]# kill 26093 # 主进程,子进程都会被杀掉
#例1、通过服务名称杀掉进程
[root@lqz ~]# pkill nginx
[root@lqz ~]# killall nginx
#例2、使用pkill踢出从远程登录到本机的用户,终止pts/0上所有进程, 并且bash也结束(用户被强制退出)
[root@lqz ~]# pkill -9 bash
# 一般程序都会有自己的启动和停止
/usr/local/nginx/sbin/nginx -h
4.管理后台进程
1.什么是后台进程
通常进程都会在终端前台运行,一旦关闭终端,进程也会随着结束,那么此时我们就希望进程能在后台运行,就是将在前台运行的进程放入后台运行,这样及时我们关闭了终端也不影响进程的正常运行。
2.我们为什么要将进程放入后台运行
比如:我们此前在国内服务器往国外服务器传输大文件时,由于网络的问题需要传输很久,如果在传输的过程中出现网络抖动或者不小心关闭了终端则会导致传输失败,如果能将传输的进程放入后台,是不是就能解决此类问题了。
3.使用什么工具将进程放入后台
早期的时候大家都选择使用&符号将进程放入后台,然后在使用jobs、bg、fg等方式查看进程状态,但太麻烦了。也不直观,所以我们推荐使用screen。
1.jobs、bg、fg的使用(强烈不推荐,了解即可)
[root@lqz ~]# sleep 3000 & //运行程序(时),让其在后台执行
[root@lqz ~]# sleep 4000 //^Z,将前台的程序挂起(暂停)到后台
[2]+ Stopped sleep 4000
[root@lqz ~]# ps aux |grep sleep
[root@lqz ~]# jobs //查看后台作业
[1]- Running sleep 3000 &
[2]+ Stopped sleep 4000
[root@lqz ~]# bg %2 //让作业 2 在后台运行
[root@lqz ~]# fg %1 //将作业 1 调回到前台
[root@lqz ~]# kill %1 //kill 1,终止 PID 为 1 的进程
[root@lqz ~]# (while :; do date; sleep 2; done) & //进程在后台运行,但输出依然在当前终端
[root@lqz ~]# (while :; do date; sleep 2; done) &>/dev/null &
2.screen的使用(强烈推荐,生产必用)
#1.安装
[root@oldboy ~]# yum install screen -y
#2.开启一个screen窗口,指定名称
[root@oldboy ~]# screen -S wget_mysql
#3.在screen窗口中执行任务即可
[root@oldboy ~]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.30-linux-glibc2.12-x86_64.tar.gz --no-check-certificate
#4.平滑的退出screen,但不会终止screen中的任务。注意: 如果使用exit 才算真的关闭screen窗口
ctrl+a+d
#5.查看当前正在运行的screen有哪些
[root@oldboy ~]# screen -list
There is a screen on:
22058.wget_mysql (Detached)
1 Socket in /var/run/screen/S-root.
#6.进入正在运行的screen
[root@oldboy ~]# screen -r wget_mysql
[root@oldboy ~]# screen -r 22058
#7 终止(ctrl+d),退出才能停止screen
exit
5.进程的优先级[进阶]
1.什么优先级
优先级指的是优先享受资源,比如排队买票时,军人优先、老人优先。等等
2.为什么要有系统优先级
举个例子: 海底捞火锅正常情况下响应就特别快,那么当节假日来临时人员突增则会导致处理请求特别慢,那么假设我是海底捞VIP客户(最高优先级),无论门店多么繁忙,我都不用排队,海底捞人员会直接服务于我,满足我的需求。至于没有VIP的人员(较低优先级)则进入排队等待状态。(PS: 至于等多久,那……)
3.系统中如何给进程配置优先级?
在启动进程时,为不同的进程使用不同的调度策略。nice 值越高: 表示优先级越低,例如+19,该进程容易将CPU 使用量让给其他进程。nice 值越低: 表示优先级越高,例如-20,该进程更不倾向于让出CPU。
- 使用top或ps命令查看进程的优先级
#1.使用top可以查看nice优先级。
NI: 实际nice级别,默认是0。
PR: 显示nice值,-20映射到0,+19映射到39
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1083 root 20 0 298628 2808 1544 S 0.3 0.1 2:49.28 vmtoolsd
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:+
#2.使用ps查看进程优先级
[root@m01 ~]# ps axo command,nice |grep sshd|grep -v grep
/usr/sbin/sshd -D 0
sshd: root@pts/2 0
- nice指定程序的优先级。语法格式 nice -n 优先级数字 进程名称
#1.开启vim并且指定程序优先级为-5
[root@m01 ~]# nice -n -5 vim &
[1] 98417
#2.查看该进程的优先级情况
[root@m01 ~]# ps axo pid,command,nice |grep 98417
98417 vim -5
- renice命令修改一个正在运行的进程优先级。语法格式 renice -n 优先级数字 进程pid
#1.查看sshd进程当前的优先级状态
[root@m01 ~]# ps axo pid,command,nice |grep 折叠shd
70840 sshd: root@pts/2 0
98002 /usr/sbin/sshd -D 0
#2.调整sshd主进程的优先级
[root@m01 ~]# renice -n -20 98002
98002 (process ID) old priority 0, new priority -20
#3.调整之后记得退出终端
[root@m01 ~]# ps axo pid,command,nice |grep 折叠shd
70840 sshd: root@pts/2 0
98002 /usr/sbin/sshd -D -20
[root@m01 ~]# exit
#4.当再次登陆sshd服务,会由主进程fork子进程(那么子进程会继承主进程的优先级)
[root@m01 ~]# ps axo pid,command,nice |grep 折叠shd
98002 /usr/sbin/sshd -D -20
98122 sshd: root@pts/0 -20
生产案例、Linux出现假死,怎么办,又如何通过nice解决?
6.系统平均负载[进阶]
每次发现系统变慢时,我们通常做的第一件事,就是执行 top 或者 uptime 命令,来了解系统的负载情况。比如像下面这样,我在命令行里输入了 uptime 命令,系统也随即给出了结果。
[root@m01 ~]# uptime
04:49:26 up 2 days, 2:33, 2 users, load average: 0.70, 0.04, 0.05
#我们已经比较熟悉前面几列,它们分别是当前时间、系统运行时间以及正在登录用户数。
# 而最后三个数字呢,依次则是过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average)。
1.什么是平均负载
平均负载不就是单位时间内的 CPU 使用率吗?上面的 0.70,就代表 CPU 使用率是 70%。其实上并……那到底如何理解平均负载: 平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数, PS: 平均负载与 CPU 使用率并没有直接关系。
2.可运行状态和不可中断状态是什么
1.可运行状态进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们ps 命令看到处于 R 状态的进程。2.不可中断进程,(你做什么事情的时候是不能打断的?) 系统中最常见的是等待硬件设备的 I/O 响应,也就是我们 ps 命令中看到的 D 状态(也称为 Disk Sleep)的进程。例如: 当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
划重点,因此你可以简单理解为,平均负载其实就是单位时间内的活跃进程数。
3.那平均负载为多少时合理
最理想的状态是每个 CPU 上都刚好运行着一个进程,这样每个 CPU 都得到了充分利用。所以在评判平均负载时,首先你要知道系统有几个 CPU,这可以通过 top 命令获取,或grep 'model name' /proc/cpuinfo
例1、假设现在在 4、2、1核的CPU上,如果平均负载为 2 时,意味着什么呢?Q1.在4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。Q2.在2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。Q3.而1 个 CPU 的系统上,则意味着有一半的进程竞争不到 CPU。
PS: 平均负载有三个数值,我们应该关注哪个呢?实际上,我们都需要关注。就好比上海4月的天气,如果只看晚上天气,感觉在过冬天呢。但如果你结合了早上、中午、晚上三个时间点的温度来看,基本就可以全方位了解这一天的天气情况了。
1.如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。2.但如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。3.反过来,如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续上升,所以就需要持续观察。PS: 一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析问题,并要想办法优化了
在来看个例子3、假设我们在有2个 CPU 系统上看到平均负载为 2.73,6.90,12.98那么说明在过去1 分钟内,系统有 136% 的超载 (2.73/2=136%)而在过去 5 分钟内,有 345% 的超载 (6.90/2=345%)而在过去15 分钟内,有 649% 的超载,(12.98/2=649%)但从整体趋势来看,系统的负载是在逐步的降低。
4.那么在实际生产环境中,平均负载多高时,需要我们重点关注呢?
当平均负载高于 CPU 数量 70% 的时候,你就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。但 70% 这个数字并不是绝对的,最推荐的方法,还是把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势。当发现负载有明显升高趋势时,比如说负载翻倍了,你再去做分析和调查。
5.平均负载与 CPU 使用率有什么关系
在实际工作中,我们经常容易把平均负载和 CPU 使用率混淆,所以在这里,我也做一个区分。可能你会疑惑,既然平均负载代表的是活跃进程数,那平均负载高了,不就意味着 CPU 使用率高吗?我们还是要回到平均负载的含义上来,平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
6.平均负载案例分析实战
下面,我们以三个示例分别来看这三种情况,并用 stress、mpstat、pidstat 等工具,找出平均负载升高的根源。stress 是 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。mpstat 是多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
#如果出现无法使用mpstat、pidstat命令查看%wait指标建议更新下软件包
wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.7.3-1.x86_64.rpm
rpm -Uvh sysstat-11.7.3-1.x86_64.rpm
场景一:CPU 密集型进程
1.首先,我们在第一个终端运行 stress 命令,模拟一个 CPU 使用率 100% 的场景:
[root@m01 ~]# stress --cpu 1 --timeout 600
2.接着,在第二个终端运行 uptime 查看平均负载的变化情况
# 使用watch -d 参数表示高亮显示变化的区域(注意负载会持续升高)
[root@m01 ~]# watch -d uptime
17:27:44 up 2 days, 3:11, 3 users, load average: 1.10, 0.30, 0.17
3.最后,在第三个终端运行 mpstat 查看 CPU 使用率的变化情况
# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据
[root@m01 ~]# mpstat -P ALL 5
Linux 3.10.0-957.1.3.el7.x86_64 (m01) 2019年04月29日 _x86_64_ (1 CPU)
17时32分03秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
17时32分08秒 all 99.80 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时32分08秒 0 99.80 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 0.00
#单核CPU所以只有一个all和0
4.从终端二中可以看到,1 分钟的平均负载会慢慢增加到 1.00,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。那么,到底是哪个进程导致了 CPU 使用率为 100% 呢?可以使用 pidstat 来查询
# 间隔 5 秒后输出一组数据
[root@m01 ~]# pidstat -u 5 1
Linux 3.10.0-957.1.3.el7.x86_64 (m01) 2019年04月29日 _x86_64_(1 CPU)
17时33分21秒 UID PID %usr %system %guest %CPU CPU Command
17时33分26秒 0 110019 98.80 0.00 0.00 98.80 0 stress
#从这里可以明显看到,stress 进程的 CPU 使用率为 100%。
场景二:I/O 密集型进程
1.首先还是运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync
[root@m01 ~]# stress --io 1 --timeout 600s
2.然后在第二个终端运行 uptime 查看平均负载的变化情况:
[root@m01 ~]# watch -d uptime
18:43:51 up 2 days, 4:27, 3 users, load average: 1.12, 0.65, 0.00
3.最后第三个终端运行 mpstat 查看 CPU 使用率的变化情况:
# 显示所有 CPU 的指标,并在间隔 5 秒输出一组数据
[root@m01 ~]# mpstat -P ALL 5
Linux 3.10.0-693.2.2.el7.x86_64 (bgx.com) 2019年05月07日 _x86_64_ (1 CPU)
14时20分07秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
14时20分12秒 all 0.20 0.00 82.45 17.35 0.00 0.00 0.00 0.00 0.00 0.00
14时20分12秒 0 0.20 0.00 82.45 17.35 0.00 0.00 0.00 0.00 0.00 0.00
#会发现cpu的与内核打交道的sys占用非常高
4.那么到底是哪个进程,导致 iowait 这么高呢?我们还是用 pidstat 来查询
# 间隔 5 秒后输出一组数据,-u 表示 CPU 指标
[root@m01 ~]# pidstat -u 5 1
Linux 3.10.0-957.1.3.el7.x86_64 (m01) 2019年04月29日 _x86_64_(1 CPU)
18时29分37秒 UID PID %usr %system %guest %wait %CPU CPU Command
18时29分42秒 0 127259 32.60 0.20 0.00 67.20 32.80 0 stress
18时29分42秒 0 127261 4.60 28.20 0.00 67.20 32.80 0 stress
18时29分42秒 0 127262 4.20 28.60 0.00 67.20 32.80 0 stress
#可以发现,还是 stress 进程导致的。
场景三:大量进程的场景当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。
1.首先,我们还是使用 stress,但这次模拟的是 4 个进程
[root@m01 ~]# stress -c 4 --timeout 600
2.由于系统只有 1 个 CPU,明显比 4 个进程要少得多,因而,系统的 CPU 处于严重过载状态
[root@m01 ~]# watch -d uptime
19:11:07 up 2 days, 4:45, 3 users, load average: 4.65, 2.65, 4.65
3.然后,再运行 pidstat 来看一下进程的情况:
# 间隔 5 秒后输出一组数据
[root@m01 ~]# pidstat -u 5 1
平均时间: UID PID %usr %system %guest %wait %CPU CPU Command
平均时间: 0 130290 24.55 0.00 0.00 75.25 24.55 - stress
平均时间: 0 130291 24.95 0.00 0.00 75.25 24.95 - stress
平均时间: 0 130292 24.95 0.00 0.00 75.25 24.95 - stress
平均时间: 0 130293 24.75 0.00 0.00 74.65 24.75 - stress
可以看出,4 个进程在争抢 1 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 75%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
分析完这三个案例,我再来归纳一下平均负载与CPU平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:平均负载高有可能是 CPU 密集型进程导致的;平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源
stress工具使用参考
3 Linux系统服务
1.Linux启动流程
CentOS6启动级别CentOS6 VS Centos7开机启动流程图解
2.Linux运行级别
1.什么是运行级别,运行级别就是操作系统当前正在运行的功能级别
System V init运行级别
systemd目标名称
作用
0
runlevel0.target, poweroff.target
关机
1
runlevel1.target, rescue.target
单用户模式
2
runlevel2.target, multi-user.target
暂未使用
3
runlevel3.target, multi-user.target
多用户的文本界面(黑框)
4
runlevel4.target, multi-user.target
没有使用
5
runlevel5.target, graphical.target
多用户的图形界面
6
runlevel6.target, reboot.target
重启
2.如何调整系统启动的运行级别?systemd使用’targets’而不是runlevels。默认情况下,有两个主要目标:
multi-user.target:类似于运行级别3graphical.target: 类似于运行级别5

#1.查看系统默认运行级别
# ls /usr/lib/systemd/system/runlevel*
[root@student ~]# runlevel(6,7通用)
[root@student ~]# systemctl get-default
#2.要设置默认目标,请运行
[root@student ~]# systemctl set-default graphical.target # 切换图形界面
[root@student ~]# systemctl set-default multi-user.target # 切换命令界面
3.Linux systemd
1.systemd的由来
Linux一直以来都是采用init进程作为祖宗进程,但是init有两个缺点:1、启动时间长。Init进程是串行启动,只有前一个进程启动完,才会启动下一个进程。2、启动脚本复杂,初始化完成后系统会加载很多脚本,脚本都会处理各自的情况,这会让脚本多而复杂。Centos5 是启动速度最慢的,串行启动过程,无论进程相互之间有无依赖关系。Centos6 相对启动速度有所改进。有依赖的进程之间依次启动而其他与之没有依赖关系的则并行同步启动。Centos7 所有进程无论有无依赖关系则都是并行启动(当然很多时候进程没有真正启动而是只有一个信号或者说是标记而已,在真正利用的时候才会真正启动。)
2.什么是systemd
systemd即为system daemon守护进程,systemd主要解决上文的问题而诞生,systemd的目标是,为系统的启动和管理提供一套完整的解决方案。
3.systemd的优势
1、最新系统都采用systemd管理(RedHat7,CentOS7,Ubuntu15等)2、Centos7支持开机并行启动服务,显著提高开机启动效率。3、Centos7关机只关闭正在运行的服务,而Centos6全部都关闭一次。4、Centos7服务的启动与停止不在使用脚本进行管理,也就是/etc/init.d下不在有脚本。5、Centos7使用systemd解决原有模式缺陷,比如原有service不会关闭程序产生的子进程。
3.systemd相关配置文件/usr/lib/systemd/system/ #类似Centos6系统的启动脚本,/etc/init.d//etc/systemd/system/ #类似Centos6系统的/etc/rc.d/rcN.d//etc/systemd/system/multi-user.target.wants/,开机要启动的程序
4.systemd管理服务相关命令systemctl管理服务的启动、重启、停止、重载、查看状态等常用命令
systemctl命令
作用
systemctl start crond.service
启动服务
systemctl stop crond.service
停止服务
systemctl restart crond.service
重启服务
systemctl reload crond.service
重新加载配置
systemctl status crond.servre
查看服务运行状态
systemctl is-active sshd.service
查看服务是否在运行中
systemctl mask crond.servre
禁止服务运行
systemctl unmask crond.servre
取消禁止服务运行
systemctl cat vsftpd
查看启动文件
当我们使用systemctl启动一个守护进程后,可以通过sysytemctl status查看此守护进程的状态
状态
描述
loaded
服务单元的配置文件已经被处理
active(running)
服务持续运行
active(exited)
服务成功完成一次的配置
active(waiting)
服务已经运行但在等待某个事件
inactive
服务没有在运行
enabled
服务设定为开机运行
disabled
服务设定为开机不运行
static
服务开机不启动,但可以被其他服务调用启动
systemctl 设置服务开机启动、不启动、查看各级别下服务启动状态等常用命令
systemctl命令(7系统)
作用
systemctl enable crond.service
开机自动启动
systemctl disable crond.service
开机不自动启动
systemctl list-unit-files
查看各个级别下服务的启动与禁用
systemctl is-enabled crond.service
查看特定服务是否为开机自启动
systemctl daemon-reload
创建新服务文件需要重载变更
CentOS7系统, 管理员可以使用 systemctl 命令来管理服务器启动与停止
#关机相关命令
systemctl poweroff #立即关机,常用
#重启相关命令
systemctl reboot #重启命令,常用
systemctl的journalctl日志
journalctl -n 20 #查看最后20行
journalctl -f #动态查看日志
journalctl -p err #查看日志的级别
journalctl -u crond #查看某个服务的单元的日志
# journalctl -xe
# systemctl status nginx -l
systemcltl 其他
### 1 centos6 中启动服务,centos7启动服务
/etc/init.d/network restart
service network restart #(只会干掉父进程,不会关掉子进程)
# centos7启动服务
systemctl restart network # 所有服务都放在/usr/lib/systemd/system/
####2 制作系统服务(nginx为例)
# /usr/lib/systemd/system/vsftpd.service
[Unit]
Description=Vsftpd ftp daemon # 描述
After=network.target # 在XX后启动
[Service]
Type=forking # 程序后台运行
ExecStart=/usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf # 命令
# ExecStartPre 启动之前执行
# ExecStop 停止
# ExecRestart 重启
# ExecReload 重新加载
[Install]
WantedBy=multi-user.target # 在哪个运行级别下
####3 制作系统服务
# cd /usr/lib/systemd/system/
# vim mynginx.service
[Unit]
Description=my nginx
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/nginx/sbin/nginx
ExecStop=/usr/local/nginx/sbin/nginx -s stop
ExecRestart=/usr/local/nginx/sbin/nginx -s restart
ExecReload=/usr/local/nginx/sbin/nginx -s reload
[Install]
WantedBy=multi-user.target # 在哪个运行级别下
# chmod 754 mynginx.service
# systemctl start mynginx # 启动nginx
# systemctl enable mynginx.service # 开机启动
# systemctl status mynginx.service # 查看是否成功
# systemctl disable mynginx.service # 取消开机启动
4.Linux单用户模式
如何使用单用户模式进行变更系统密码?以Centos7系统为例:(Centos6破解方式请自行百度)
第1步:重启Linux系统主机并出现引导界面时,按下键盘上的e键进入内核编辑界面 第2步:在linux16这行的后面添加
第2步:在linux16这行的后面添加enforcing=0 init=/bin/bash,然后按下Ctrl + X组合键来运行修改过的内核程序 第3步:大约5秒过后,进入到系统的单用户模式,依次输入以下命令,等待系统重启操作完毕,然后就可以使用新密码来登录Linux系统了。命令行执行效果如图所示。
第3步:大约5秒过后,进入到系统的单用户模式,依次输入以下命令,等待系统重启操作完毕,然后就可以使用新密码来登录Linux系统了。命令行执行效果如图所示。 Centos7单用户破解密码更为详细版
Centos7单用户破解密码更为详细版
5.Linux下救援模式
场景一:当系统坏了,无法登陆系统,但需要把里面的数据复制出来,怎么办?
步骤一、先挂载光盘,然后选择光盘引导为第一位 步骤二、进入故障排除模式–>然后选择救援模式
步骤二、进入故障排除模式–>然后选择救援模式
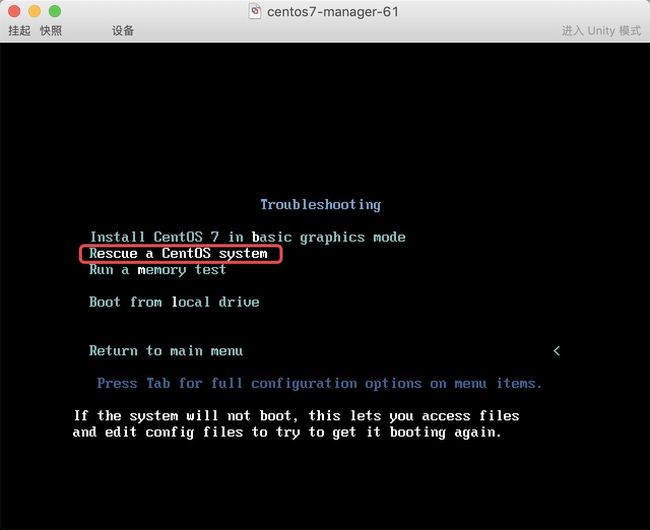 步骤三、挂载真实系统后,发现数据都还存在
步骤三、挂载真实系统后,发现数据都还存在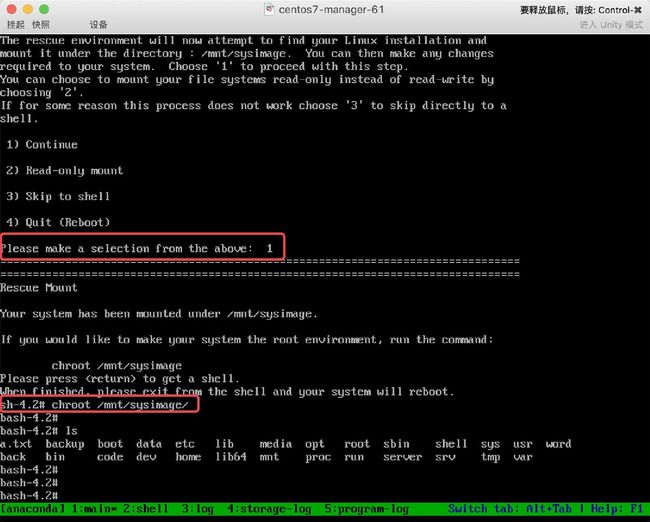
场景二、修复MBR,主要出现在安装双系统时,后安装的系统把原来系统的MBR删除了,需要修复。
步骤一、破坏硬盘的前446字节,模拟MBR引号损坏,会发现重启无法启动系统
[root@m01 ~]# dd if=/dev/zero of=/dev/sda bs=1 count=446
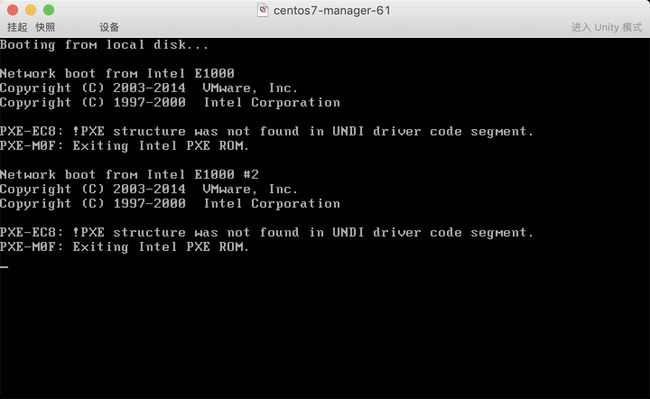 步骤二、重启系统,然后按照之前的操作进入救援模式,然后分配一个shell终端,挂载真实的操作系统进行修复
步骤二、重启系统,然后按照之前的操作进入救援模式,然后分配一个shell终端,挂载真实的操作系统进行修复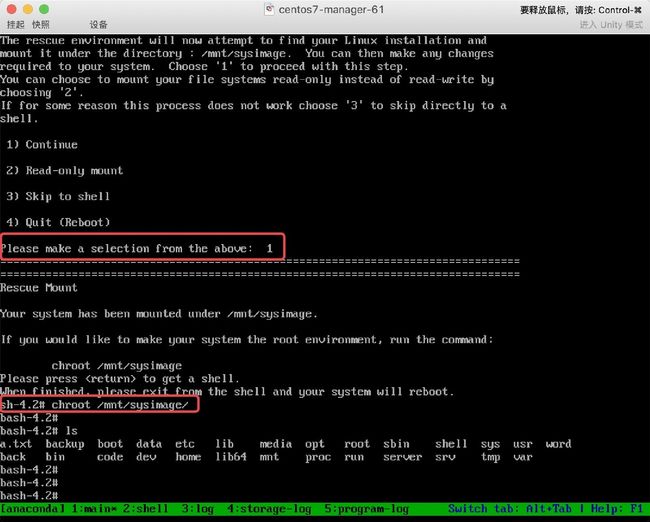 步骤二、修复MBR引导,然后重启连接服务器
步骤二、修复MBR引导,然后重启连接服务器
#1.使用grub修复
# grub2-install /dev/sda
#2.然后退出
# exit
#3.最后重启进入系统
# reboot
场景三、Centos7误删除grub文件如何进行修复。步骤一、模拟误删故障
#1.删除grub2
[root@m01 ~]# rm -rf /boot/grub2
#2.重启计算机
[root@m01 ~]# reboot
 步骤二、重启系统,然后按照之前的操作进入救援模式,然后分配一个shell终端,挂载真实的操作系统进行修复
步骤二、重启系统,然后按照之前的操作进入救援模式,然后分配一个shell终端,挂载真实的操作系统进行修复 步骤三、使用grub2-install、grub2-mkconfig恢复配置文件
步骤三、使用grub2-install、grub2-mkconfig恢复配置文件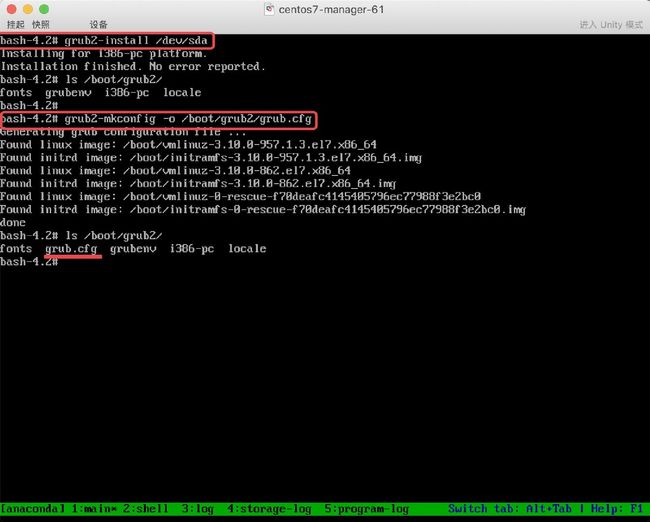
PS: 最后别忘记修改 BIOS 引导,让硬盘回归到第一引导
4 Linux计划任务
1.计划任务基本概述
1.什么是crond
crond就是计划任务,类似于我们平时生活中的闹钟。定点执行。
2.为什么要使用crondcrond主要是做一些周期性的任务,比如: 凌晨3点定时备份数据。比如:11点开启网站抢购接口,12点关闭网站抢购接口。
3.计划任务主要分为以下两种使用情况:
1.系统级别的定时任务: 临时文件清理、系统信息采集、日志文件切割
2.用户级别的定时任务: 定时向互联网同步时间、定时备份系统配置文件、定时备份数据库的数据
2.计划任务时间管理
1.Crontab配置文件记录了时间周期的含义
[root@lqz ~]# vim /etc/crontab
SHELL=/bin/bash #执行命令的解释器
PATH=/sbin:/bin:/usr/sbin:/usr/bin #环境变量
MAILTO=root #邮件发给谁
# Example of job definition:
# .---------------- minute (0 - 59) #分钟
# | .------------- hour (0 - 23) #小时
# | | .---------- day of month (1 - 31) #日期
# | | | .------- month (1 - 12) OR jan,feb,mar,apr #月份
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat #星期
# | | | | |
# command to be executed
# 表示任意的(分、时、日、月、周)时间都执行
# - 表示一个时间范围段, 如5-7点
# , 表示分隔时段, 如6,0,4表示周六、日、四
# /1 表示每隔n单位时间, 如/10 每10分钟
2.了解crontab的时间编写规范
00 02 ls #每天的凌晨2点整执行
00 02 1 ls #每月的1日的凌晨2点整执行
00 02 14 2 ls #每年的2月14日凌晨2点执行
00 02 7 ls #每周天的凌晨2点整执行
00 02 6 5 ls #每年的6月周五凌晨2点执行
00 02 14 7 ls #每月14日或每周日的凌晨2点都执行
00 02 14 2 7 ls #每年的2月14日或每年2月的周天的凌晨2点执行
/10 02 ls #每天凌晨2点,每隔10分钟执行一次
ls #每分钟都执行
00 00 14 2 ls #每年2月14日的凌晨执行命令
/5 ls #每隔5分钟执行一次
00 02 1,5,8 ls #每年的1月5月8月凌晨2点执行
00 02 1-8 ls #每月1号到8号凌晨2点执行
0 21 ls #每天晚上21:00执行
45 4 1,10,22 ls #每月1、10、22日的4:45执行
45 4 1-10 l #每月1到10日的4:45执行
3,15 8-11 /2 ls #每隔两天的上午8点到11点的第3和第15分钟执行
0 23-7/1 ls #晚上11点到早上7点之间,每隔一小时执行
15 21 1-5 ls #周一到周五每天晚上21:15执行
3.使用crontab编写cron定时任务
参数
含义
-e
编辑定时任务
-l
查看定时任务
-r
删除定时任务
-u
指定其他用户
3.计划任务编写实践
1.使用root用户每5分钟执行一次时间同步
#1.如何同步时间
[root@lqz ~]# ntpdate time.windows.com &>/dev/null
#2.配置定时任务
[root@lqz ~]# crontab -e -u root
[root@lqz ~]# crontab -l -u root
/5 ntpdate time.windows.com &>/dev/null
2.每天的下午3,5点,每隔半小时执行一次sync命令
[root@lqz ~]# crontab -l
/30 15,17 sync &>/dev/null
3.案例:每天凌晨3点做一次备份?备份/etc/目录到/backup下面
- 将备份命令写入一个脚本中2) 每天备份文件名要求格式: 2019-05-01_hostname_etc.tar.gz3) 在执行计划任务时,不要输出任务信息4) 存放备份内容的目录要求只保留三天的数据
#1.实现如上备份需求
[root@lqz ~]# mkdir /backup
[root@lqz ~]# tar zcf $(date +%F)_$(hostname)_etc.tar.gz /etc
[root@lqz ~]# find /backup -name “.tar.gz” -mtime +3 -exec rm -f {};
#2.将命令写入至一个文件中
[root@lqz ~]# vim /root/back.sh
mkdir /backup
tar zcf $(date +%F)_$(hostname)_etc.tar.gz /etc
find /backup -name “.tar.gz” -mtime +3 -exec rm -f {};
#3.配置定时任务
[root@lqz ~]# crontab -l
00 03 bash /root/back.sh &>/dev/null
#3.备份脚本
4.crond注意的事项
- 给定时任务注释2) 将需要定期执行的任务写入Shell脚本中,避免直接使用命令无法执行的情况tar date3) 定时任务的结尾一定要有&>/dev/null或者将结果追加重定向>>/tmp/date.log文件4) 注意有些命令是无法成功执行的 echo “123” >>/tmp/test.log &>/dev/null5.如果一定要是用命令,命令必须使用绝对路径
5.crond如何备份 - 通过查找/var/log/cron中执行的记录,去推算任务执行的时间2) 定时的备份/var/spool/cron/{usernmae}
6.crond如何拒绝某个用户使用
#1.使用root将需要拒绝的用户加入/etc/cron.deny
[root@lqz ~]# echo "lqz" >> /etc/cron.deny
#2.登陆该普通用户,测试是否能编写定时任务
[oldboy@lqz ~]$ crontab -e
You (lqz) are not allowed to use this program (crontab)
See crontab(1) for more information
4.计划任务如何调试
1.crond调试
- 调整任务每分钟执行的频率, 以便做后续的调试。2) 如果使用cron运行脚本,请将脚本执行的结果写入指定日志文件, 观察日志内容是否正常。3) 命令使用绝对路径, 防止无法找到命令导致定时任务执行产生故障。4) 通过查看/var/log/cron日志,以便检查我们执行的结果,方便进行调试。
2.crond编写思路
- 1.手动执行命令,然后保留执行成功的结果。
- 2.编写脚本
脚本需要统一路径/scripts
脚本内容复制执行成功的命令(减少每个环节出错几率)
脚本内容尽可能的优化, 使用一些变量或使用简单的判断语句
脚本执行的输出信息可以重定向至其他位置保留或写入/dev/null - 3.执行脚本
使用bash命令执行, 防止脚本没有增加执行权限(/usr/bin/bash)
执行脚本成功后,复制该执行的命令,以便写入cron - 4.编写计划任务
加上必要的注释信息, 人、时间、任务
设定计划任务执行的周期
粘贴执行脚本的命令(不要手敲) - 5.调试计划任务
增加任务频率测试
检查环境变量问题
检查crond服务日志