使用 Alluxio 优化 EMR 上 Flink Join
业务背景&痛点
- 流式处理的业务场景,经常会遇到实时消息数据需要与历史存量数据关联查询或者聚合,比如电商常见的订单场景,订单表做为实时事实表,是典型的流式消息数据,通常会在 kafka 中,而客户信息,商品 SKU 表是维度表,通常存在业务数据库或者数仓中,是典型的离线数据。实时订单数据在实时处理时通常需要事实表与维度表 join 做 reference 补全,以便拿到订单详情并实时统计当天或截至当天的所有订单的商品分布详情。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里(https://dev.amazoncloud.cn/user/register?show=tab1&sc_channel=CSDN)让它成为你的技术宝库! |
- 流式计算通常采用 Flink 做为数据处理平台,上文中提到的实时和离线数据join 的场景,Flink 提供了 Hive/ jdbc/Hudi/ filesystem 各种 connector 实现与离线数据的提取和读写,这样一来在 Flink 应用程序中,即可使用 Table,Sql API 来 join 关联流态表和离线表数据,实现聚合计算等操作
使用 Flink Sql 离线表 Join 流态表的常规 lookup join,是通过 Flink hive sql connector 或者 filesystem connector,对离线 hive 库表或者 S3上离线数据建 Flink Table,然后对 kafka 消息流中的数据建流态表,然后直接做量表做 join 操作
该方式架构如下图所示:

该方式主要面临的问题是:
- lookup 维度表数据只会在首次拉起 Flink 应用的时候,保存在 task manager state 中,后续持续查询或者开窗聚合等操作时,是不会再次拉取维度表数据,业务需要定期重启 Flink 应用,或者刷新维度表数据到临时表,以便 join 聚合时和最新的维度数据关联:

- 每次需要重新全量拉取维度表数据,存在冷启动问题,且维度表数据量大的时候(如上千万注册用户信息表,上万的商品 SKU 属性字段),造成很大 IO 开销,存在性能瓶颈
- Flink 的 checkpoint 机制在持续查询或者开窗聚合时,需要保存 state 状态及处理数据到检查点快照中,造成 state 快照数据膨胀
解决方案思路
基于以上业务难点,本文提出一种解决方案思路,即通过 Alluxio 缓存层,将 hive 维度表数据自动加载至 Alluxio UFS 缓存中,同时通过 Flink 时态表 join,把维度表数据做成持续变化表上某一时刻的视图
同时使用 Flink 的 Temporal table function 表函数,传递一个时间参数,返回 Temporal table 这一指定时刻的视图,这样实时动态表主表与这个 Temporal table 表关联的时候,可以关联到某一个版本(历史上某一个时刻)的维度数据
优化后的整体架构如下图所示:
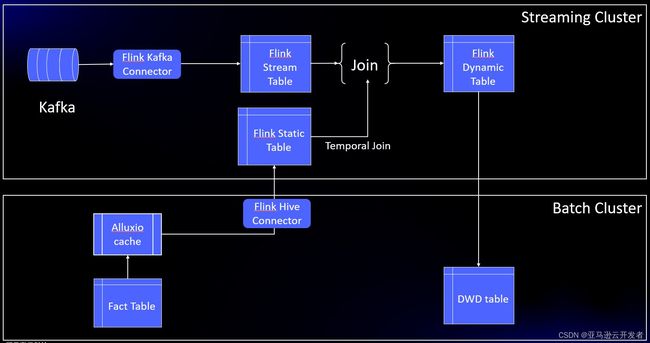
方案实施落地Detail
本文以 Kafka 中用户行为日志数据做为实时流态的事实表数据,hive 上用户信息数据做为离线维度表数据,采用 Alluxio+Flink temproal 的 demo,来验证其 flink join 优化的解决方案
实时事实表
本实例中我们使用 json-data-generator 开源组件模拟的用户行为 json 数据,实时写入 kafka 中,通过 Flink kafka connector 转换为持续查询的 Flink 流态表,从而做为实时 join 的时候的 Fact 事实表数据
用户行为 json 模拟数据如下格式:
[{ "timestamp": "nowTimestamp()",
"system": "BADGE",
"actor": "Agnew",
"action": "EXIT",
"objects": ["Building 1"],
"location": "45.5,44.3",
"message": "Exited Building 1"
}]包含用户行为的业务时间,登录系统,用户署名,行为 activity 动作,操作涉及对象,位置信息,及相关文本消息字段。我们在
Flink Sql 中建选择主要字段建事实表如下
CREATE TABLE logevent_source (`timestamp` string,
`system` string,
actor STRING,
action STRING
) WITH (
'connector' = 'kafka',
'topic' = 'logevent',
'properties.bootstrap.servers' = 'b-6.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092,b-5.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092,b-1.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092 (http://b-6.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092%2Cb-5.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092%2Cb-1.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092/)',
'properties.group.id' = 'testGroup6',
'scan.startup.mode'='latest-offset',
'format' = 'json'
);Alluxio 缓存维度表
Alluxio 是大数据技术堆栈的分布式缓存,它提供了一个统一的 UFS 文件系统可以对接底层 S3,hdfs 数据,在读写 Alluxio UFS 的时候,可以针对 S3,HDFS 分布式存储层实现 warm up,显著提升吞吐量和减少网络开销,且与上层计算引擎如 Hive,spark,Trino 都有深度的集成,很适合做为离线维度数据的缓存加速器
Amazon EMR 对 Alluxio 提供了良好的集成,可以通过 boostrap 启动脚本方式,在 EMR 创建时自动部署 Alluxio 组件并启动 Alluxio master、worker 进程,详细 EMR 安装和部署 Alluxio 步骤可以参考另一篇文章 Alluxio EMR 集成实践
在集成 Alluxio 的 Amazon EMR 集群中,使用 Alluxio 中创建 hive 离线维表数据的缓存表方法如下:
hive-env.sh中设置设置client jar包:
$ export HIVE_AUX_JARS_PATH=//client/alluxio-2.2.0-client.jar:${HIVE_AU
确保安装部署alluxio的EMR集群上ufs已配置,并且表或者db路径已创建
alluxio fs mkdir alluxio://ip-xxx-xxx-xxx-xxx.ap-southeast-1.compute.internal:19998/s3/customer
alluxio fs chown hadoop:hadoop alluxio://ip-xxx-xxx-xxx-xxx.ap-southeast-1.compute.internal:19998/s3/customer
在AWS EMR集群上,创建hive表路径指向alluxio namespace uri:
!connect jdbc:hive2://xxx.xxx.xxx.xxx:10000/default;
hive> CREATE TABLE customer(
c_customer_sk bigint,
c_customer_id string,
c_current_cdemo_sk bigint,
c_current_hdemo_sk bigint,
c_current_addr_sk bigint,
c_first_shipto_date_sk bigint,
c_first_sales_date_sk bigint,
c_salutation string,
c_first_name string,
c_last_name string,
c_preferred_cust_flag string,
c_birth_day int,
c_birth_month int,
c_birth_year int,
c_birth_country string,
c_login string,
c_email_address string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 'alluxio://ip-xxx-xxx-xxx-xxx.ap-southeast-1.compute.internal:19998/s3/customer';
OK
Time taken: 3.485 seconds 如上所示,该 Alluxio 表 location 指向的路径即为 hive 维度表所在 S3路径,因此对 Customer 用户维度信息表的写入操作会自动同步到 alluxio 缓存中。
创建好 Alluxio hive 离线维度表后,在 flink sql中,可以通过 hive 的 catalog,连接到 hive 元数据,即可以查看到 alluxio 缓存表的详细信息:
CREATE CATALOG hiveCatalog WITH ( 'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/etc/hive/conf/',
'hive-version' = '3.1.2',
'hadoop-conf-dir'='/etc/hadoop/conf/'
);
-- set the HiveCatalog as the current catalog of the session
USE CATALOG hiveCatalog;
show create table customer;
create external table customer(
c_customer_sk bigint,
c_customer_id string,
c_current_cdemo_sk bigint,
c_current_hdemo_sk bigint,
c_current_addr_sk bigint,
c_first_shipto_date_sk bigint,
c_first_sales_date_sk bigint,
c_salutation string,
c_first_name string,
c_last_name string,
c_preferred_cust_flag string,
c_birth_day int,
c_birth_month int,
c_birth_year int,
c_birth_country string,
c_login string,
c_email_address string
)
row format delimited fields terminated by '|'
location 'alluxio://ip-xxx-xxx-xxx-xxx.ap-southeast-1.compute.internal:19998/s3/30/customer'
TBLPROPERTIES (
'streaming-source.enable' = 'false',
'lookup.join.cache.ttl' = '12 h'
)如上图所示,可以看到该维度表 location 路径是 alluxio 缓存 ufs 路径的 uri,业务程序读写该维度表时,alluxio 会自动更新缓存中的 customer 维度表数据,并异步写入到 alluxio的backend storage 的 S3表路径,实现数据湖的表数据同步更新。
Flink Temporal 时态表 join
Flink 时态表(Temporal table)也是动态表的一种,时态表的每条记录都会有一个或多个时间字段相关联,当我们事实表 join 维度表的时候,通常需要获取实时的维度表数据做 lookup,所以通常需要在事实表 create table 或者 join 时,通过 proctime()函数指定事实表的时间字段,同时在 join 时,通过 FOR SYSTEM_TIME AS OF 语法,指定维度表 lookup 时对应的事实表时间版本的数据
在本 Demo 示例中,客户信息在 hive 离线表作为一个变化的维度表的角色,客户行为在 kafka 中作为事实表的角色,因此在 flink kafka source table 中,通过 proctime()指定时间字段,然后在 flink hive table 做 join 时,使用 FOR SYSTEM_TIME AS OF 指定 lookup 的 kafka source table 的时间字段,从而实现 Flink temporal 时态表 join 业务处理
如下所示,Flink Sql 中通过 Kafka connector 创建用户行为的事实表,其中 ts 字段即为时态表 join 时的时间戳:
CREATE TABLE logevent_source (`timestamp` string,
`system` string,
actor STRING,
action STRING,
ts as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'logevent',
'properties.bootstrap.servers' = 'b-6.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092,b-5.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092,b-1.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092 (http://b-6.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092%2Cb-5.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092%2Cb-1.msk06.dr04w4.c3.kafka.ap-southeast-1.amazonaws.com:9092/)',
'properties.group.id' = 'testGroup-01',
'scan.startup.mode'='latest-offset',
'format' = 'json'
);Flink 离线维度表与流式实时表具体 join 方法如下:
select a.`timestamp`,a.`system`,a.actor,a.action,b.c_login from
(select *, proctime() as proctime from user_logevent_source) as a
left join customer FOR SYSTEM_TIME AS OF a.proctime as b on a.actor=b.c_last_name;如上代码示例,在事实表 logevent_source join lookup 维度表时,通过 proctime 函数获取到维度表的瞬时最新的版本数据,保障 join 时的一致性和实时性
同时,该维度表数据已经在 alluxio cache,因此读取时性能远高于离线读取 s3上的表数据
通过 hive 切换 S3和 alluxio 路径的 customer 信息 维度表,对比测试 flink join 可以看出 alluxio 缓存后性能明显优势
通过 alter table 方便切换本地和 cache 的 location路径:
alter table customer set location "s3://xxxxxx/data/s3/30/customer";
alter table customer set location "alluxio://ip-xxx-xxx-xxx-xxx.ap-southeast-1.compute.internal:19998/s3/30/customer";选取某一 split 数据分片的 TaskManager 日志:
- cache 前(S3路径读取): 5s 加载
2022-06-29 02:54:34,791 INFO com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem [] - Opening 's3://salunchbucket/data/s3/30/customer/data-m-00029' for reading
2022-06-29 02:54:39,971 INFO org.apache.flink.table.filesystem.FileSystemLookupFunction [] - Loaded 433000 row(s) into lookup join cache- cache 后(alluxio 读取): 2s 加载
2022-06-29 03:25:14,476 INFO com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem [] - Opening 's3://salunchbucket/data/s3/30/customer/data-m-00029' for reading
2022-06-29 03:25:16,397 INFO org.apache.flink.table.filesystem.FileSystemLookupFunction [] - Loaded 433000 row(s) into lookup join cache在 JobManager 上查看 Timeline,对比 alluxio 和 s3路径下 job 的执行时间可以看到更加清楚

可以看到, 单个 task 查询提升1倍以上,整体 job 性能提升更加明显
其他需要考虑的问题
持续 Join 每次都需要拉取维度数据做 join,Flink 的 checkpoint state 是否一直膨胀导致 TM 的 RockDB 撑爆或者内存溢出?
state 自带有 ttl 机制,可以设置 ttl 过期策略,触发 Flink 清理过期 state 数据,Flink Sql 可以通过 Hint 方式设置
insert into logevent_sink
select a.`timestamp`,a.`system`,a.actor,a.action,b.c_login from
(select *, proctime() as proctime from logevent_source) as a
left join
customer/*+ OPTIONS('lookup.join.cache.ttl' = '5 min')*/ FOR SYSTEM_TIME AS OF a.proctime as b
on a.actor=b.c_last_name;Flink Table/Streaming API 类似:
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.days(7))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupInRocksdbCompactFilter()
.build();
ValueStateDescriptor lastUserLogin =
new ValueStateDescriptor<>("lastUserLogin", Long.class);
lastUserLogin.enableTimeToLive(ttlConfig);
StreamTableEnvironment.getConfig().setIdleStateRetentionTime(min, max); 设置后重新启动 lookup join,从 Flink TM 日志中可以看到,ttl 到期后,会触发清理并重新拉取 hive 维表数据:
2022-06-29 04:17:09,161 INFO org.apache.flink.table.filesystem.FileSystemLookupFunction
[] - Lookup join cache has expired after 5 minute(s), reloading此外,可以通过配置 flink state retain,减少 checkpoint 时候快照数量,从而减少快照时候 state 的占用空间
Flink job中配置:
-D state.checkpoints.num-retained=5设置后,可以看到 s3 checkpoint 路径上,Flink Job 会自动清理历史快照,只保留最近的5次快照数据,从而确保 checkpoint 快照数据不会堆积
[hadoop@ip-172-31-41-131 ~]$ aws s3 ls s3://salunchbucket/data/checkpoints/7b9f2f9becbf3c879cd1e5f38c6239f8/
PRE chk-3/
PRE chk-4/
PRE chk-5/
PRE chk-6/
PRE chk-7/附录
Alluxio整体架构
Alluxio on EMR 快速部署
在 Amazon EMR 中利用 Alluxio 的分层存储架构
EMR Alluxio集成detail
Flink Temporal Join 详细
本篇作者

唐清原
Amazon 数据分析解决方案架构师,负责 Amazon Data Analytic 服务方案架构设计以及性能优化,迁移,治理等 Deep Dive 支持。10+数据领域研发及架构设计经验,历任 Oracle 高级咨询顾问,咪咕文化数据集市高级架构师,澳新银行数据分析领域架构师职务。在大数据,数据湖,智能湖仓,及相关推荐系统 /MLOps 平台等项目有丰富实战经验

陈昊
Amazon 合作伙伴解决方案架构师,有将近 20 年的 IT 从业经验,在企业应用开发、架构设计及建设方面具有丰富的实践经验。目前主要负责 Amazon (中国)合作伙伴的方案架构咨询和设计工作,致力于 Amazon 云服务在国内的应用推广以及帮助合作伙伴构建更高效的 Amazon 云服务解决方案。
文章来源:https://dev.amazoncloud.cn/column/article/6309af45d4155422a4610a40?sc_channel=CSDN