Feast on Amazon 解决方案
背景&引言
众所周知,AI 算法模型开发落地有三个主要阶段:数据准备、模型训练、模型部署。目前已经有较多厂商及开源社区推出通用的 AI、MLOps 平台支撑模型训练与部署阶段,但主要偏重于机器学习模型开发,部署,服务层面,自 2019 年后才陆续有各厂商推出数据准备支撑阶段的产品及服务,即特征平台(如 Amazon Sagemaker feature Store)。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
特征平台的主要能力包含:特征注册中心、离线存储&消费、在线存储&消费、离线&在线特征同步,特征版本,尤其特征版本最为重要,实现特征 point-in-time cross join,避免特征穿越造成 train-server skew 的重要功能特性。
各个厂商在特征平台的架构和实现方式方面迥然不同,缺乏跨平台的通用的特征库方案。
Feast (Feature Store) 是一套开源特征库框架,纯 python 框架,与 Pandas dataframe 无缝集成,对 ML,AI 算法工程师友好,它提供了在线,离线特征库注册,特征库存储,特征数据摄取、训练数据检索、特征版本、离线-在线特征同步等功能;且具有云原生亲和力,可以构建在多个公有云平台上。
本文介绍了 Feast 框架的整体架构及设计思路,并 step by step 详细说明了 Feast on Amazon 集成和使用,包括安装部署离线/在线特征库、使用特征库、特征库同步的方法等。对于使用 Feast 开源框架构建 MLOps 平台的用户,本文可以作为快速构建和开发指南。
Feast 整体架构

Feast的主要功能组件:
- Feast Repo&Registry:轻量级的目录级及 Split 文件数据库格式 Repository,用于特征库基础设施及元数据注册
- Feast Python SDK/CLI: 开发构建及使用特征库的主要功能组件
- Feast Apply:命令行工具执行安装部署配置的特征库到底层基础设施,并且注册特征库元数据到 Runtime 运行态
- Feast Materialize:离线-在线特征库版本同步工具
- Get Online Features:在线特征数据提取,调用对应的在线特征库基础设施 API 抽取特征数据,用于模型推断
- Get Historical Features:离线特征数据抽取,调用对应的离线特征库基础设施 API 抽取历史特征数据,用于模型训练或者特征组合
- Online Store: 在线特征库,根据不同云厂商的 nosql 数据库承载,存储特征快照版本数据
- Offline Store:离线特征库,根据不同云厂商数仓承载,存储特征历史版本数据
Feast On Amazon 安装部署方案
依赖准备
- Feast on Amazon 使用 Redshift 作为离线特征库,需要 Redshift 集群(如果采用 Spectrum 外部表,还需要 Spectrum 角色及 Glue Catalog 权限)
- Feast on Amazon 使用 DynamoDB 作为在线特征库,需要 DynamoDB 读写权限
- 可以用 Terraform 或者 CloudFormation 准备需要的 Redshift,DDB,IAM 角色等
- 以下使用 Terraform 为例安装部署 Feast 需要的 Redshift,S3,IAM 角色等各种基础设施
- 安装部署 Terraform
sudo yum install python3-devel
sudo yum install -y yum-utils
sudo yum-config-manager —add-repo https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo
sudo yum -y install terraform- 编写 Terraform 配置文件
project: feast_aws_repo
registry: data/registry.db
provider: aws
online_store:
type: dynamodb
region: ap-southeast-1
offline_store:
type: redshift
cluster_id: feast-demo2-redshift-cluster
region: ap-southeast-1
database: flinkstreamdb
user: awsuser
s3_staging_location: s3://feastdemobucket
iam_role: arn:aws:iam::**********:role/s3_spectrum_role- 构建基础设施
cd infra
sudo terraform init
sudo terraform plan -var="admin_password=xxxxx"
sudo terraform apply -var="admin_password=xxxxx"- 如果需要 Spectrum 承载离线特征库,需要在 Redshift 中建立 Spectrum 外部 schema,以便指向Glue Catalog 中的 s3 外部表
aws redshift-data execute-statement \
—region ap-southeast-1 \
—cluster-identifier feast-demo-redshift-cluster \
—db-user awsuser \
—database dev —sql "create external schema spectrum from data catalog database 'flinkstreamdb' iam_role \
'arn:aws:iam::**********:role/s3_spectrum_role' create external database if not exists;“Feast 特征库 Repository 准备
- 依赖安装及升级
pip3 install -U numpy==1.21
pip3 install feast[aws]- 初始化 repository
feast init -t xxxxx(repository_name)
AWS Region (e.g. us-west-2): ap-southeast-1
Redshift Cluster ID: feast-demo-redshift-cluster
Redshift Database Name: flinkstreamdb
Redshift User Name: awsuser
Redshift S3 Staging Location (s3://*): s3://feastdemobucket
Redshift IAM Role for S3 (arn:aws:iam::*:role/*): arn:aws:iam::xxxxxx:role/s3_spectrum_role创建好的特征库的 schema 及骨架示例:
$ tree ./feast_aws_repo/
./feast_aws_repo/
├── data
│ └── registry.db
├── driver_repo.py
├── feature_store.yaml- *.yam l 配置指定 Feast repository 的基础环境资源(s3、Redshift、DDB 等)
- *.py 配置特征库元数据,特征 view 及 schema 等
- db 保存基于 *.py 元数据构建后的特征组,特征库对象实例,以便运行态使用
安装部署后的 feature_store.yaml 示例:
project: feast_aws_repo
registry: data/registry.db
provider: aws
online_store:
type: dynamodb
region: ap-southeast-1
offline_store:
type: redshift
cluster_id: feast-demo2-redshift-cluster
region: ap-southeast-1
database: flinkstreamdb
user: awsuser
s3_staging_location: s3://feastdemobucket
iam_role: arn:aws:iam::xxxxxxx:role/s3_spectrum_roledriver_repo 的司机行程特征库元数据示例:
from datetime import timedelta
from feast import Entity, Feature, FeatureView, RedshiftSource, ValueType
driver = Entity(
name="driver_id",
join_key="driver_id",
value_type=ValueType.INT64,
)
driver_stats_source = RedshiftSource(
table="feast_driver_hourly_stats",
event_timestamp_column="event_timestamp",
created_timestamp_column="created",
)
driver_stats_fv = FeatureView(
name="driver_hourly_stats",
entities=["driver_id"],
ttl=timedelta(weeks=52),
features=[
Feature(name="conv_rate", dtype=ValueType.FLOAT),
Feature(name="acc_rate", dtype=ValueType.FLOAT),
Feature(name="avg_daily_trips", dtype=ValueType.INT64),
],
batch_source=driver_stats_source,
tags={"team": "driver_performance"},
)部署成功后可以在 Redshift 看到离线特征库的 Spectuam schema 及库表,DDB 中可以看到在线特征库的表
Redshift 离线特征库:

DDB 在线特征库:
使用Feast SDK API进行特征库操作
连接特征库
安装部署完成后,在 python 代码中,可以方便的通过加载注册的 repository 路径,来连接到特征库及特征组
在 repository 中注册的特征组,也可以直接 import 实例化
from datetime import datetime, timedelta
import pandas as pd
from feast import FeatureStore
from driver_repo import driver, driver_stats_fv
fs = FeatureStore(repo_path="./")
>>> print(fs)
>>> print(driver_stats_fv)
{
"spec": {
"name": "driver_hourly_stats",
"entities": [
"driver_id"
],
"features": [
{
"name": "conv_rate",
"valueType": "FLOAT"
},
{
"name": "acc_rate",
"valueType": "FLOAT"
},
{
"name": "avg_daily_trips",
"valueType": "INT64"
}
],
"tags": {
"team": "driver_performance"
},
"ttl": "31449600s",
"batchSource": {
"type": "BATCH_REDSHIFT",
"eventTimestampColumn": "event_timestamp",
"createdTimestampColumn": "created",
"redshiftOptions": {
"table": "feast_driver_hourly_stats"
},
"dataSourceClassType": "feast.infra.offline_stores.redshift_source.RedshiftSource"
},
"online": true
},
"meta": {}
} 离线特征数据提取
通过 Feast get_historical_features API,可以抽取离线特征库数据用于离线训练或特征组合
features = ["driver_hourly_stats:conv_rate", "driver_hourly_stats:acc_rate"]
entity_df = pd.DataFrame(
{
"event_timestamp": [
pd.Timestamp(dt, unit="ms", tz="UTC").round("ms")
for dt in pd.date_range(
start=datetime.now() - timedelta(days=3),
end=datetime.now(),
periods=3,
)
],
"driver_id": [1001, 1002, 1003],
}
)
training_df = fs.get_historical_features(
features=features, entity_df=entity_df
).to_df()如上我们抽取特征标识(entity 字段为 driver_id)为 1001,1002,1003, 时间版本为最近 3 天的离线特征库数据
>>> training_df
event_timestamp driver_id conv_rate acc_rate
0 2022-07-04 02:33:54.114 1001 0.036082 0.707744
1 2022-07-05 14:33:54.114 1002 0.522306 0.983233
2 2022-07-07 02:33:54.114 1003 0.734294 0.034062离线特征组合
多个特征组需要联合并抽取作为模型训练时,get_historical_features 可以指定多个特征 view 的 features,基于 event_timestamp 做 point-in-time 关联,从而得到同一时间版本的离线特征组合的数据
feast_features = [
"zipcode_features:city",
"zipcode_features:state",
"zipcode_features:location_type",
"zipcode_features:tax_returns_filed",
"zipcode_features:population",
"zipcode_features:total_wages",
"credit_history:credit_card_due",
"credit_history:mortgage_due",
"credit_history:student_loan_due",
"credit_history:vehicle_loan_due",
"credit_history:hard_pulls",
"credit_history:missed_payments_2y",
"credit_history:missed_payments_1y",
"credit_history:missed_payments_6m",
"credit_history:bankruptcies",
]
training_df = self.fs.get_historical_features(
entity_df=entity_df, features=feast_features
).to_df()如上代码示例,在抽取离线特征时,关联了 credit_history 和 zipcode_features 两个离线特征库的相应特征字段,Feast 会在后台拼接 Redshift Sql 关联对应的库表及 event_timestamp 等条件
离线特征数据同步在线特征库
通过Feast 提供的 materialize cli,可以将指定时间版本的 Redshift 离线特征数据同步到 DynamoDB 的在线特征库中
materialize-incremental cli 会记录该 repository 特征库下每次同步的增量时间版本,因此每次执行会把自上次执行至今的最新数据增量同步到 DynamoDB
CURRENT_TIME=$(date -u +"%Y-%m-%dT%H:%M:%S")
feast materialize-incremental $CURRENT_TIME
Materializing 1 feature views to 2022-07-07 08:00:03+00:00 into the sqlite online
store.
driver_hourly_stats from 2022-07-06 16:25:47+00:00 to 2022-07-07 08:00:03+00:00:
100%|████████████████████████████████████████████| 5/5 [00:00<00:00, 592.05it/s]当然也可以使用 materialize 显式指定开始时间(startdt)和截止时间(enddt), feast 会将指定时间版本的离线特征库数据同步到在线特征库
feast materialize 2022-07-13T00:00:00 2022-07-19T00:00:00
Materializing 1 feature views from 2022-07-13 00:00:00+00:00 to 2022-07-19 00:00:00+00:00 into the dynamodb online store.
driver_hourly_stats:
100%|█████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 51.18it/s]在线特征查询
>>> online_features = fs.get_online_features(
features=features, entity_rows=[{"driver_id": 1001}, {"driver_id": 1002}],
).to_dict()
>>> print(pd.DataFrame.from_dict(online_features))
acc_rate conv_rate driver_id
0 0.179407 0.984951 1001
1 0.023422 0.069323 1002Feast offline store on Spark 方案
上文我们看到的是 Feast 依托 Amazon Redshift 作为离线特征库存储和特征抽取的方案,虽然安装部署简介明快,上手方便,但 Redshift 定位是云服务数据仓库,虽然在 sql 兼容性、扩展性上优秀,但灵活性不足,如:
- 离线特征抽取必须要指定 event_timestamp 版本,无法直接查询最新 snapshot
- point-in-time 关联查询直接拼接 partition over 分组 sql 并下压,海量数据情况下,多历史版本的特征库 time travel 抽取时会膨胀数倍,存在性能瓶颈
Feast 自0.19版本开始,支持 Spark 作为离线特征库历史数据提取,版本查询,同步在线特征库的计算框架
Spark 作为高性能分布式计算引擎,在海量数据场景下性能优异,且使用 Spark 时,Feast FeatureView 的 DataSource 既可以是指向 Hive 中的表,也可以是指向对象存储上的文件,通过 Hive 表可以兼容诸如 Hudi、iceberg 等多种数据湖架构。
同时,通过 Spark 离线特征库抽取的特征数据,Feast 将其封装为 Spark DataFrame,从而可以方便的加载到 S3分布式存储,因而也避免了 Pandas DataFrame 保存在本地磁盘的存储空间问题。
Feast point-in-time correct join Spark 实现
point-in-time correct join,根据源码来看,使用 pySpark+SparkSQL 实现,因此整体思路和 Redshift 类似:
- 将 entity_df 由 DataFrame 转化为 Spark DataFrame,并注册成临时表
- 根据用户指定要关联的 features,找到对应的 FeatureView,进而找到底层的 DataSource 和相关的元数据
- 根据以上信息,即 query_context,通过 jinjia 渲染一个 SparkSQL,并提交给 Spark 集群计算
- 计算完成的结果就是实现 point-in-time correct join 之后的 training dataset
Feast offline store on Amazon EMR安装部署
Amazon EMR 是全托管的 hadoop 大数据集群,提供了良好的弹性伸缩,高可用,存算分离等特性,且通过 EMRFS 原生集成 Amazon S3云存储,用于承载 Feast 的 Spark 离线特征库具有天然的亲和力。
以下详细介绍 Feast Spark 离线特征库在 Amazon EMR 的安装部署步骤及使用方法
启动 Amazon EMR 集群
Amazon EMR 的启动方法本文不再赘述,感兴趣的同学可以参阅 Amazon EMR 文档
此处选择 emr 6.5版本,Spark 3.1.2

Offline store on EMR 特征库配置
我们在 emr 主节点上可以 feast init 特征库,从而直接利用 Amazon EMR上spark 与 S3的原生集成,通过 emrfs 读写 S3数据湖上各种格式文件,不再需要 hadoop s3开源 lib 的支持
feast init my_project 后,在该特征库的 yaml 配置文件中,指定 Feast spark 的对应参数即可:
project: feast_spark_project
registry: data/registry.db
provider: local
offline_store:
type: spark
spark_conf:
spark.master: yarn
spark.ui.enabled: "true"
spark.eventLog.enabled: "true"
spark.sql.catalogImplementation: "hive"
spark.sql.parser.quotedRegexColumnNames: "true"
spark.sql.session.timeZone: "UTC"配置完成后,通过 feast apply cli 同样部署到 EMR spark
注:在 EMR master 节点上 pyspark lib 路径需要在环境变量中设置,以便 feast 找到 spark 的 home 目录及相应配置
source /etc/spark/conf/spark-env.sh
export PYTHONPATH="${SPARK_HOME}/python/:$PYTHONPATH"
export PYTHONPATH="${SPARK_HOME}/python/lib/py4j-0.10.9-src.zip:$PYTHONPATH"Feast on Spark 离线特征库元数据
from feast.infra.offline_stores.contrib.spark_offline_store.spark_source import ( SparkSource,)
driver_hourly_stats= SparkSource(
name="driver_hourly_stats",
query="SELECT event_timestamp as ts, created_timestamp as created, conv_rate,conv_rate,conv_rate FROM emr_feature_store.driver_hourly_stats",
event_timestamp_column="ts",
created_timestamp_column="created"
)
Feast 的 sparkSource 提供了 query, table,及原始 raw 文件路径几种初始化方法,本文中使用 query 方式。
需要注意 query 方式中,需要指定 event timestamp field 特征字段以便 Feast 识别作为 point-in-time cross join 时间版本抽取及特征 join 的依据
Feast Spark offline store 执行
配置 Spark 作为 Feast offline store 后,通过 Amazon EMR 上 spark history UI,可以清楚的看到其 get_historical_features 方法,底层 Feast 使用 SparkSQL 创建临时视图,拼接 event time join 的 sql,并查询上文中 source 数据湖上 hive 库表等各个步骤的业务逻辑:
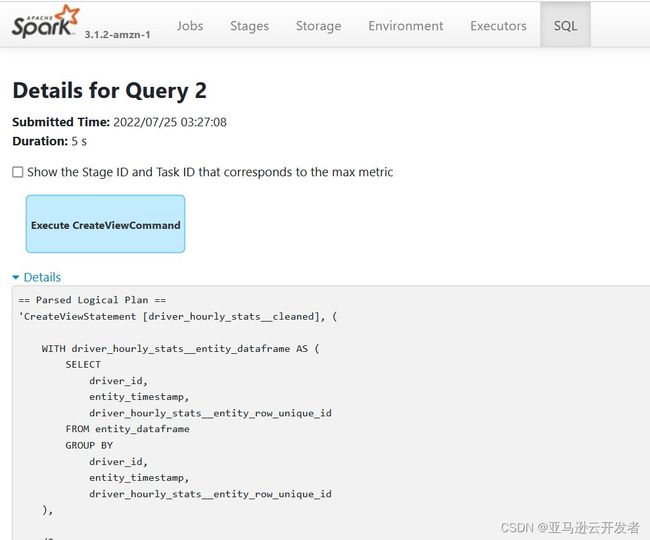
跟踪 Spark history UI 上,Spark Sql 的各个 query 可以看到,Feast 的 get_historical_features 方法执行时,会构造临时表 entity_dataframe,即用户调用 get_historical_features 方法时,传入的样本列表。再构建 driver_hourly_stats_base,即需要 join 及 point-in-time 查询的即样例特征时序表
== Parsed Logical Plan ==
'CreateViewStatement [driver_hourly_stats__cleaned], (
WITH driver_hourly_stats__entity_dataframe AS (
SELECT
driver_id,
entity_timestamp,
driver_hourly_stats__entity_row_unique_id
FROM entity_dataframe
GROUP BY
driver_id,
entity_timestamp,
driver_hourly_stats__entity_row_unique_id
),
driver_hourly_stats__base AS (
SELECT
subquery.*,
entity_dataframe.entity_timestamp,
entity_dataframe.driver_hourly_stats__entity_row_unique_id
FROM driver_hourly_stats__subquery AS subquery
INNER JOIN driver_hourly_stats__entity_dataframe AS entity_dataframe
ON TRUE
AND subquery.event_timestamp <= entity_dataframe.entity_timestamp
AND subquery.event_timestamp >= entity_dataframe.entity_timestamp - 86400 * interval '1' second
AND subquery.driver_id = entity_dataframe.driver_id
),后续的 subquery、dedup 及 cleaned 子查询,会基于以上的两张基础表,进行基于特征标识字段 driver_id 和时序时间戳字段 event_timestamp 的分组排序,剔重等操作,最后 join 样本列表临时表 entity_dataframe,整个流程与 Redshift 上基本一致
driver_hourly_stats__subquery AS (
SELECT
ts as event_timestamp,
created as created_timestamp,
driver_id AS driver_id,
conv_rate as conv_rate,
acc_rate as acc_rate
FROM (SELECT driver_id,event_timestamp as ts, created_timestamp as created, conv_rate,acc_rate,avg_daily_trips FROM emr_feature_store.driver_hourly_stats)
WHERE ts <= '2022-07-25T03:27:05.903000'
AND ts >= '2022-07-21T03:27:05.903000'
),
driver_hourly_stats__dedup AS (
SELECT
driver_hourly_stats__entity_row_unique_id,
event_timestamp,
MAX(created_timestamp) as created_timestamp
FROM driver_hourly_stats__base
GROUP BY driver_hourly_stats__entity_row_unique_id, event_timestamp
),
driver_hourly_stats__latest AS (
SELECT
event_timestamp,
created_timestamp,
driver_hourly_stats__entity_row_unique_id
FROM
(
SELECT *,
ROW_NUMBER() OVER(
PARTITION BY driver_hourly_stats__entity_row_unique_id
ORDER BY event_timestamp DESC,created_timestamp DESC
) AS row_number
FROM driver_hourly_stats__base
INNER JOIN driver_hourly_stats__dedup
USING (driver_hourly_stats__entity_row_unique_id, event_timestamp, created_timestamp)
)
WHERE row_number = 1
)API 结果返回可以 to_df 为 Spark 的 Dataframe,从而实现 remote 存储离线特征库抽取结果数据的操作,这也从另一方面解决了原有 Redshift 离线特征存储,特征抽取只能返回 pandas Dataframe 的劣势,在大数据量离线特征场景下更有优势
总结
综上所述,Feast 框架整体架构和在 Amazon 的构建是非常简洁明快的,对构建 MLOps 平台的用户而言,其主要有价值的优势如下:
- 同时提供了离线,在线特征库,离线-在线特征库快照版本同步功能
- 轻量级,快速部署使用, 代码即配置,feast apply 即可部署到 Amazon
- 通过 repository 文件系统隔离特征库,方便 MLOps 多租户多 CICD 协同开发
- API 抽象程度高,贴近 AI/ML 算法工程师业务语言
对于海量离线特征数据抽取时 point-in-time cross join 的版本查询数据膨胀的业界难点,Feast 也可以通过 on EMR Spark 的构建方式,优化解决其性能问题
参考资料
Amazon Sagemaker Feature Store: 使用亚马逊功能商店创建、存储和共享 SageMaker 功能 - 亚马逊 SageMaker
Feast官方:Overview - Feast
Amazon EMR集群部署:什么是 Amazon EMR? - Amazon EMR
本篇作者

唐清原
Amazon 数据分析解决方案架构师,负责 Amazon Data Analytic 服务方案架构设计以及性能优化,迁移,治理等 Deep Dive 支持。10+数据领域研发及架构设计经验,历任 Oracle 高级咨询顾问,咪咕文化数据集市高级架构师,澳新银行数据分析领域架构师职务。在大数据,数据湖,智能湖仓,及相关推荐系统 /MLOps 平台等项目有丰富实战经验
文章来源:https://dev.amazoncloud.cn/column/article/6309bf4a0c9a20404da7914b?sc_channel=CSDN