[学习笔记]黑马程序员python教程
文章目录
- 思维导图
-
- Python基础知识图谱
- 面向对象
- SQL入门和实战
- Python高阶技巧
- 第一阶段
-
- 第九章:Python异常、模块与包
-
- 1.9.1异常的捕获
-
- 1.9.1.1 为什么要捕获异常
- 1.9.1.2 捕获常规的异常
- 1.9.1.3 捕获指定的异常
- 1.9.1.4 捕获多个异常
- 1.9.1.5 捕获全部异常
- 1.9.1.6 异常的else
- 1.9.1.7 异常的finally
- 1.9.2 异常的传递
- 1.9.3 Python模块
-
- 1.9.3.1 什么是模块
- 1.9.3.2 模块的导入
- 1.9.3.3 自定义模块
- 1.9.4 Python包
-
- 1.9.4.1 什么是Python包
- 1.9.4.2 导入包
- 1.9.4.3 安装第三方包
- 第十章:数据可视化-折线图可视化
-
- 1.10.1 json数据格式
- 1.10.2 pyecharts模块
- 1.10.3 数据处理
- 1.10.4 创建折线图
- 第十一章:数据可视化-地图可视化
-
- 1.11.1 基础地图使用
- 1.11.2 国内疫情地图
- 1.11.3 省级疫情地图-河南省
- 第十二章:数据可视化-动态柱状图
-
- 1.12.1 基础柱状图
- 1.12.2 基础时间线柱状图
- 1.12.3 GDP动态柱状图绘制
-
- 1.12.3.1 列表的sort方法
- 1.12.3.2 数据处理
- 第二阶段
-
- 第一章:面向对象
-
- 2.1.1 初识对象
- 2.1.2 类的成员方法
- 2.1.3 类和对象
- 2.1.4 构造方法
- 2.1.5 其他内置方法-魔术方法
-
- 2.1.5.1 __str__字符串方法
- 2.1.5.2 __lt__小于符号比较方法
- 2.1.5.3 __le__小于等于比较符号方法
- 2.1.5.4 __eq__比较运算符实现方法
- 2.1.6 封装
-
- 2.1.6.1 私有成员
- 2.1.7 继承
-
- 2.1.7.1 单继承
- 2.1.7.2 多继承
- 2.1.7.3 复写和使用父类成员
- 2.1.8 类型注解
-
- 2.1.8.1 变量的类型注解
- 2.1.8.2 函数(方法)的类型注解
- 2.1.8.3 Union类型
- 2.1.9 多态
- 2.1.10 综合案例
-
- 2.1.10.1 要求和数据内容
- 2.1.10.2 需求分析
- 2.1.10.3 文件读取
- 2.1.10.4 数据计算
- 2.1.10.5 可视化开发
- 第二章:SQL入门和实战
-
- 2.2.1 数据库介绍
-
- 2.2.1.1 数据库管理系统
- 2.2.1.2 数据库和SQL的关系
- 2.2.2 MySQL的安装
- 2.2.3 MySQL的入门使用
- 2.2.4 SQL基础与DDL
-
- 2.2.4.1 SQL语法特征
- 2.2.4.2 数据库定义语言-DDL
- 2.2.5 SQL-DML
- 2.2.6 SQL-DQL
- 2.2.7 Python & MySQL
-
- 2.2.7.1 安装pymysql
- 2.2.7.2 创建到MySQL的数据库链接
- 2.2.7.3 执行非查询性质的SQL语句
- 2.2.7.4 执行查询性质的SQL语句
- 2.2.7.5 数据插入
- 2.2.8 综合案例
-
- 2.2.8.1 创建表
- 2.2.8.2 实现步骤
- 2.2.8.3 作业
- 第三阶段:PySpark案例实战
-
-
- 3.1.1 Spark是什么
- 3.1.2 PySpark
- 3.2 Python高阶技巧
-
- 3.2.1 闭包
- 3.2.2 装饰器
- 3.2.3 设计模式
-
- 3.2.3.1 单例模式
- 3.2.3.2 工厂模式
- 3.2.4 多线程
-
- 3.2.4.1 进程、线程
- 3.2.4.2 并行执行
- 3.2.4.3 多线程编程
- 3.2.5 网络编程
-
- 3.2.5.1 Socket
- 3.2.5.2 客户端和服务端
- 3.2.5.3 Socket服务端编程
- 3.2.5.4 Socket客户端开发
- 3.2.6 正则表达式
-
- 3.2.6.1 正则的三个基础方法
- 3.2.6.2 元字符匹配
- 3.2.7 递归
-
思维导图
Python基础知识图谱
面向对象
![[学习笔记]黑马程序员python教程_第1张图片](http://img.e-com-net.com/image/info8/5ff273a0717f4f6e8fa119cd950df04a.jpg)
SQL入门和实战
![[学习笔记]黑马程序员python教程_第2张图片](http://img.e-com-net.com/image/info8/a2694e5d128b4bcdb34951cb2709c9f6.jpg)
Python高阶技巧
第一阶段
第九章:Python异常、模块与包
1.9.1异常的捕获
1.9.1.1 为什么要捕获异常
![[学习笔记]黑马程序员python教程_第3张图片](http://img.e-com-net.com/image/info8/c171d47a6f3146b6add82d99c8adf65e.jpg)
1.9.1.2 捕获常规的异常
![[学习笔记]黑马程序员python教程_第4张图片](http://img.e-com-net.com/image/info8/fe160499ac2f4379a0d37d1c9a22f39b.jpg)
1.9.1.3 捕获指定的异常
![[学习笔记]黑马程序员python教程_第5张图片](http://img.e-com-net.com/image/info8/761123a12f634286988bbfcd807992c3.jpg)
e是接受异常信息的变量
1.9.1.4 捕获多个异常
![[学习笔记]黑马程序员python教程_第6张图片](http://img.e-com-net.com/image/info8/0d5249b3cee64e53ae303c43a3a35f78.jpg)
1.9.1.5 捕获全部异常
try:
代码
except Exception as e:
处理异常
1.9.1.6 异常的else
![[学习笔记]黑马程序员python教程_第7张图片](http://img.e-com-net.com/image/info8/c24eb0133b004a6b92f4782c1182220e.jpg)
1.9.1.7 异常的finally
![[学习笔记]黑马程序员python教程_第8张图片](http://img.e-com-net.com/image/info8/8acc8f3f46a6444584e6e5439c2ca172.jpg)
1.9.2 异常的传递
![[学习笔记]黑马程序员python教程_第9张图片](http://img.e-com-net.com/image/info8/c4445695841f43d8bce3f19bc5630282.jpg)
![[学习笔记]黑马程序员python教程_第10张图片](http://img.e-com-net.com/image/info8/f7af314d698c4a419257011e35e4a625.jpg)
如果异常是在某一层产生,但是没有被catch,那么会继续往上层抛出,此时这一层的后续代码就不会执行。直到异常在某一层被catch,这一层的后续代码能继续执行。
1.9.3 Python模块
1.9.3.1 什么是模块
![[学习笔记]黑马程序员python教程_第11张图片](http://img.e-com-net.com/image/info8/ce6a32d1e5704e06a5faab5a306fad10.jpg)
1.9.3.2 模块的导入
![[学习笔记]黑马程序员python教程_第12张图片](http://img.e-com-net.com/image/info8/7670807576fe491aa95b20d89f63bda9.jpg)
一般不要用from 模块名 import *,因为这样相当于把模块里的全部代码都导入python程序内,可能会出现重名问题。
1.9.3.3 自定义模块
![[学习笔记]黑马程序员python教程_第13张图片](http://img.e-com-net.com/image/info8/c53f28727fa64950b89fd4ae53bdf98c.jpg)
注意:当导入多个模块时,且模块内有同名功能。当调用这个同名功能时,调用的是后面导入的模块的功能。
- __main__
![[学习笔记]黑马程序员python教程_第14张图片](http://img.e-com-net.com/image/info8/5f61925839e2451caaac123777cb5192.jpg)
- __all__变量
![[学习笔记]黑马程序员python教程_第15张图片](http://img.e-com-net.com/image/info8/43b343f9d47c42c1971daa3bb6f0623d.jpg)
指定导入不受__all__影响
1.9.4 Python包
1.9.4.1 什么是Python包
![[学习笔记]黑马程序员python教程_第16张图片](http://img.e-com-net.com/image/info8/161a5e6e812c4758b138d42634936a5e.jpg)
必须有__init__.py文件才是python包
1.9.4.2 导入包
- 方式一:
import 包名.模块名
包名.模块名.功能
from 包名 import 模块名
模块名.功能
from 包名.模块名 import 功能
功能
- 方式二:
必须在__init__.py文件中添加__all__ = [],来控制from 包名 import *允许导入的模块列表
1.9.4.3 安装第三方包
![[学习笔记]黑马程序员python教程_第17张图片](http://img.e-com-net.com/image/info8/49683af974474fd982cbc48b77b1a317.jpg)
- 如何安装第三方包
pip install 包名
- pip的网络优化
pip默认连接国外的服务器下载包,可以通过命令在国内的镜像服务器下载包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
pycharm也可以在右下角“解释器设置”中添加新的python包,下载时可以添加option参数来通过国内镜像服务器下载包
第十章:数据可视化-折线图可视化
![[学习笔记]黑马程序员python教程_第18张图片](http://img.e-com-net.com/image/info8/e1ea3998f6a14c0d8284b143ce9a1b97.jpg)
1.10.1 json数据格式
![[学习笔记]黑马程序员python教程_第19张图片](http://img.e-com-net.com/image/info8/94cae3b1e7304e5da690395c54c318d8.jpg)
![[学习笔记]黑马程序员python教程_第20张图片](http://img.e-com-net.com/image/info8/557fb3372cf44ded87dd67a5184a6686.jpg)
![[学习笔记]黑马程序员python教程_第21张图片](http://img.e-com-net.com/image/info8/dc502dce8aee4078aa57b178a2147198.jpg)
![[学习笔记]黑马程序员python教程_第22张图片](http://img.e-com-net.com/image/info8/ea311f973ec341c5911aec931b0b7abe.jpg)
为了将含中文的python数据转化为json字符串,需要使用参数ensure_ascii为False,表明不使用ascii码进行转化,而把内容直接输出出去,为True,则中文会转化为Unicode的字符
json_str = json.dumps(data, ensure_ascii=False)
1.10.2 pyecharts模块
pyecharts官网:pyecharts.org
pyecharts画廊官网:gallery.pyecharts.org(类似美术的展览会)
![[学习笔记]黑马程序员python教程_第23张图片](http://img.e-com-net.com/image/info8/cf468204488143118874afeb2fa19a66.jpg)
![[学习笔记]黑马程序员python教程_第24张图片](http://img.e-com-net.com/image/info8/3ad5be63def34cadbfe3f53baa3e5a77.jpg)
全局配置:针对图像进行设置,如标题、图例、工具箱
系列配置:针对具体轴数据进行设置
![[学习笔记]黑马程序员python教程_第25张图片](http://img.e-com-net.com/image/info8/aa9bfb1f15d44fadafd0b3638ecab2d9.jpg)
![[学习笔记]黑马程序员python教程_第26张图片](http://img.e-com-net.com/image/info8/20ed3a7a053d468fb27f8e9a1b1d4fb3.jpg)
1.10.3 数据处理
![[学习笔记]黑马程序员python教程_第27张图片](http://img.e-com-net.com/image/info8/3a4dd89a0f104df4b2de7800bd9ef8f1.jpg)
![[学习笔记]黑马程序员python教程_第28张图片](http://img.e-com-net.com/image/info8/13e9cd6dcf204acea5d175eb3a697cc0.jpg)
1.10.4 创建折线图
![[学习笔记]黑马程序员python教程_第29张图片](http://img.e-com-net.com/image/info8/38822e4c54634a7ea06557c8243c6e9f.jpg)
第十一章:数据可视化-地图可视化
![[学习笔记]黑马程序员python教程_第30张图片](http://img.e-com-net.com/image/info8/7fe624825f2846009d4a88831cfaa364.jpg)
1.11.1 基础地图使用
![[学习笔记]黑马程序员python教程_第31张图片](http://img.e-com-net.com/image/info8/fac531c8050a4648a772201def56de33.jpg)
![[学习笔记]黑马程序员python教程_第32张图片](http://img.e-com-net.com/image/info8/67baa07712ac41f18e8a344f803fe7f5.jpg)
is_piecewise=True表示开始手动校准范围
pieces表示具体的范围是多少
可以通过ab173.com的前端rgb颜色对照表来查看某种颜色对应的16位的颜色代码
1.11.2 国内疫情地图
![[学习笔记]黑马程序员python教程_第33张图片](http://img.e-com-net.com/image/info8/0833ed504e0a40cf941ed180d89fe862.jpg)
1.11.3 省级疫情地图-河南省
略
第十二章:数据可视化-动态柱状图
![[学习笔记]黑马程序员python教程_第34张图片](http://img.e-com-net.com/image/info8/394ec81d5b014520ab6a6af8466e0834.jpg)
1.12.1 基础柱状图
![[学习笔记]黑马程序员python教程_第35张图片](http://img.e-com-net.com/image/info8/79fe8468ef9a4a63a5fadcdd00b98102.jpg)
- 反转柱状图,同时将数值标签放在右边
bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
bar.reversal_axis()
1.12.2 基础时间线柱状图
![[学习笔记]黑马程序员python教程_第36张图片](http://img.e-com-net.com/image/info8/7a7a8d508814402689f5d1482d158b47.jpg)
![[学习笔记]黑马程序员python教程_第37张图片](http://img.e-com-net.com/image/info8/02b34646a49e45a3b0d68cfe4a46f0fc.jpg)
- 设置自动播放
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=True
)
- 时间线设置主题
![[学习笔记]黑马程序员python教程_第38张图片](http://img.e-com-net.com/image/info8/fd4a51dd135e40c783058daf394aa3d4.jpg)
import pyecharts.globals import ThemeType
timeline = Timeline(
{"theme": ThemeType.LIGHT}
)
1.12.3 GDP动态柱状图绘制
![[学习笔记]黑马程序员python教程_第39张图片](http://img.e-com-net.com/image/info8/011be651c4d743749dac1ddb34a711be.jpg)
1.12.3.1 列表的sort方法
![[学习笔记]黑马程序员python教程_第40张图片](http://img.e-com-net.com/image/info8/fa4287657af840db905a991bcce4b089.jpg)
![[学习笔记]黑马程序员python教程_第41张图片](http://img.e-com-net.com/image/info8/b1ed9197b33c4202b63ae8bf1bdca158.jpg)
1.12.3.2 数据处理
![[学习笔记]黑马程序员python教程_第42张图片](http://img.e-com-net.com/image/info8/96fc641328a142fd83c80b3b2130e35e.jpg)
python3.6后,字典是有序的,参考:https://juejin.cn/post/7041433783362387982
由于bar.reversal_axis()会将从左到右从大到小变成从上到下,从小到大,所以在绘制柱状图之前需要将x_data和y_data都反转一下
![[学习笔记]黑马程序员python教程_第43张图片](http://img.e-com-net.com/image/info8/82ab2057043a4b26902911e26d78a4da.jpg)
![[学习笔记]黑马程序员python教程_第44张图片](http://img.e-com-net.com/image/info8/5152701761fb47809b6f20d0b8e58a7e.jpg)
from pyecharts.charts import Bar, Timeline
from pyecharts.options import LabelOpts, TitleOpts
from pyecharts.globals import ThemeType
with open("D:\计算机\Python\黑马程序员python教程\资料\可视化案例数据\动态柱状图数据\\1960-2019全球GDP数据.csv", "r", encoding="GB18030") as f:
data_lines = f.readlines()
data_lines.pop(0)
data_dict = {}
for line in data_lines:
line_list = line.split(",")
year = int(line_list[0])
country = line_list[1]
gdp = float(line_list[2])
try:
data_dict[year].append([country, gdp])
except KeyError:
data_dict[year] = [[country, gdp]]
timeline = Timeline(
{"theme": ThemeType.LIGHT}
)
for year in data_dict:
data_dict[year].sort(key = lambda x: x[1], reverse=True)
year_data = data_dict[year][:8]
x_data = []
y_data = []
for country_gdp in year_data:
x_data.append(country_gdp[0])
y_data.append(country_gdp[1] / 1E8)
bar = Bar()
x_data.reverse()
y_data.reverse()
bar.add_xaxis(x_data)
bar.add_yaxis("GDP(亿)", y_data, label_opts=LabelOpts(position="right"))
bar.reversal_axis()
bar.set_global_opts(
title_opts=TitleOpts(title=f"{year}年全球前8GDP数据")
)
timeline.add(bar, str(year))
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=True
)
timeline.render("1960-2019全球GDP前8国家.html")
第二阶段
第一章:面向对象
2.1.1 初识对象
![[学习笔记]黑马程序员python教程_第45张图片](http://img.e-com-net.com/image/info8/d88dbe98300c4811b0f1c4e3d0c1f271.jpg)
2.1.2 类的成员方法
![[学习笔记]黑马程序员python教程_第46张图片](http://img.e-com-net.com/image/info8/815aa748550d420f833e5937908c3269.jpg)
定义在类内部的函数称之为类的方法
self相当于以后会创建但在定义类时还不存在的对象
![[学习笔记]黑马程序员python教程_第47张图片](http://img.e-com-net.com/image/info8/fdff8f07b52844d1a3096e652335c180.jpg)
2.1.3 类和对象
![[学习笔记]黑马程序员python教程_第48张图片](http://img.e-com-net.com/image/info8/0099d0d76bce40bfa10746cc3a2b1999.jpg)
面向对象编程:设计类,基于类创建对象,由对象做具体的工作
2.1.4 构造方法
![[学习笔记]黑马程序员python教程_第49张图片](http://img.e-com-net.com/image/info8/19afe5168b64477a9700a02bef8534ea.jpg)
2.1.5 其他内置方法-魔术方法
![[学习笔记]黑马程序员python教程_第50张图片](http://img.e-com-net.com/image/info8/6b7a374ebd3e461aae0025d65cc79ea9.jpg)
2.1.5.1 __str__字符串方法
![[学习笔记]黑马程序员python教程_第51张图片](http://img.e-com-net.com/image/info8/0ff4cd4167e94ca184a73d194290968b.jpg)
2.1.5.2 __lt__小于符号比较方法
![[学习笔记]黑马程序员python教程_第52张图片](http://img.e-com-net.com/image/info8/008533df328f4eb88dfae91d9666cf9a.jpg)
2.1.5.3 __le__小于等于比较符号方法
![[学习笔记]黑马程序员python教程_第53张图片](http://img.e-com-net.com/image/info8/54afcde9b1d243a48ca48ff4427ff867.jpg)
2.1.5.4 __eq__比较运算符实现方法
![[学习笔记]黑马程序员python教程_第54张图片](http://img.e-com-net.com/image/info8/13f457f2034f46a492b38b209ca9767d.jpg)
2.1.6 封装
面向对象包含3大特性:封装、继承、多态
![[学习笔记]黑马程序员python教程_第55张图片](http://img.e-com-net.com/image/info8/aa838e1db3a34bd48fb53df7ca2e4e77.jpg)
2.1.6.1 私有成员
![[学习笔记]黑马程序员python教程_第56张图片](http://img.e-com-net.com/image/info8/e6027a6af7164003943770ec19595965.jpg)
![[学习笔记]黑马程序员python教程_第57张图片](http://img.e-com-net.com/image/info8/28838d0730e84943844b57d54b78080c.jpg)
![[学习笔记]黑马程序员python教程_第58张图片](http://img.e-com-net.com/image/info8/3cb111c8be2947d0af203576ae5f1069.jpg)
2.1.7 继承
2.1.7.1 单继承
![[学习笔记]黑马程序员python教程_第59张图片](http://img.e-com-net.com/image/info8/3abc7cadb6524bf29cc0c3cfbb0a7547.jpg)
继承表示:将从父类那里继承(复制)成员变量和成员方法(不含私有)
2.1.7.2 多继承
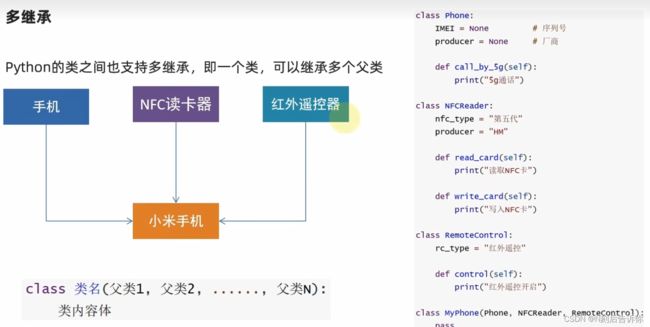
![[学习笔记]黑马程序员python教程_第60张图片](http://img.e-com-net.com/image/info8/058e5edda3de476c978c98f4676d5c33.jpg)
pass关键字是用来补全语法的
2.1.7.3 复写和使用父类成员
![[学习笔记]黑马程序员python教程_第61张图片](http://img.e-com-net.com/image/info8/630489994eed45f8bb9c40905ae0172f.jpg)
![[学习笔记]黑马程序员python教程_第62张图片](http://img.e-com-net.com/image/info8/dd953a6a4be9436db2cbc68140323e30.jpg)
2.1.8 类型注解
2.1.8.1 变量的类型注解
![[学习笔记]黑马程序员python教程_第63张图片](http://img.e-com-net.com/image/info8/9af6c732f103458c9432007bca33bdc8.jpg)
![[学习笔记]黑马程序员python教程_第64张图片](http://img.e-com-net.com/image/info8/88883aa4729544779069e89daf228521.jpg)
![[学习笔记]黑马程序员python教程_第65张图片](http://img.e-com-net.com/image/info8/56307355a2cd4b7cba691d190accfbe6.jpg)
![[学习笔记]黑马程序员python教程_第66张图片](http://img.e-com-net.com/image/info8/fba3d0bb9f5f47f2a49ba63338255541.jpg)
![[学习笔记]黑马程序员python教程_第67张图片](http://img.e-com-net.com/image/info8/b5694c07bc394beb87e150bc98853319.jpg)
![[学习笔记]黑马程序员python教程_第68张图片](http://img.e-com-net.com/image/info8/ee00a26e24cf4c869b747e75e6cbc627.jpg)
![[学习笔记]黑马程序员python教程_第69张图片](http://img.e-com-net.com/image/info8/6324d381d97e436aa8cb01d89accb26e.jpg)
2.1.8.2 函数(方法)的类型注解
- 函数(方法)的形参的类型注解
![[学习笔记]黑马程序员python教程_第70张图片](http://img.e-com-net.com/image/info8/1fd3b85ca3d14e0b9487ef3238d4940e.jpg)
- 函数(方法)的返回值的类型注解
![[学习笔记]黑马程序员python教程_第71张图片](http://img.e-com-net.com/image/info8/d4242d5bd9734055ae0d9bab8a6b7f59.jpg)
2.1.8.3 Union类型
![[学习笔记]黑马程序员python教程_第72张图片](http://img.e-com-net.com/image/info8/5f36e2258832466ca6eedb93ab5ab547.jpg)
![[学习笔记]黑马程序员python教程_第73张图片](http://img.e-com-net.com/image/info8/9c8494db148d4adebf6fca41f0ac16dd.jpg)
2.1.9 多态
![[学习笔记]黑马程序员python教程_第74张图片](http://img.e-com-net.com/image/info8/4eeece2ac6b446eabdd5053469c68d1c.jpg)
![[学习笔记]黑马程序员python教程_第75张图片](http://img.e-com-net.com/image/info8/a3c9b1a9892145049a333407f9c850af.jpg)
![[学习笔记]黑马程序员python教程_第76张图片](http://img.e-com-net.com/image/info8/bb83afa6b68446f1bfa42ccf7080ba4c.jpg)
2.1.10 综合案例
2.1.10.1 要求和数据内容
![[学习笔记]黑马程序员python教程_第77张图片](http://img.e-com-net.com/image/info8/ef7f76ca39d04ab3a2d1b5a2354e2445.jpg)
![[学习笔记]黑马程序员python教程_第78张图片](http://img.e-com-net.com/image/info8/2c2f3851e4de48bf9cc2eea750fff506.jpg)
2.1.10.2 需求分析
![[学习笔记]黑马程序员python教程_第79张图片](http://img.e-com-net.com/image/info8/5686760ba4124034b393d7ac7ffb9d2e.jpg)
2.1.10.3 文件读取
- data_define.py
"""
数据定义的类
"""
class Record:
def __init__(self, date, order_id, money, province):
self.date = date # 订单日期
self.order_id = order_id # 订单ID
self.money = money # 订单金额
self.province = province # 销售省份
def __str__(self):
return f"{self.date}, {self.order_id}, {self.money}, {self.province}"
- file_define.py
"""
和文件相关的类定义
"""
import json
from data_define import Record
# 先定义一个抽象类用来做顶层设计,确定有哪些功能需要实现
class FileReader:
def read_data(self) -> list[Record]:
"""读取文件的数据,读到的每一条数据都转换为Record对象,将它们都封装到list内返回即可"""
pass
class TextFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
# 复写(实现抽象方法)父类的方法
def read_data(self) -> list[Record]:
with open(self.path, 'r', encoding='utf-8') as f:
record_list: list[Record] = []
for line in f.readlines():
line = line.strip() # 消除读取到的每一行数据中的\n
data_list = line.split(",")
record = Record(data_list[0], data_list[1], int(data_list[2]), data_list[3])
record_list.append(record)
return record_list
class JsonFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
def read_data(self) -> list[Record]:
with open(self.path, 'r', encoding='utf-8') as f:
record_list: list[Record] = []
for line in f.readlines():
data_dict = json.loads(line)
record = Record(data_dict['date'], data_dict['order_id'], int(data_dict['money']), data_dict['province'])
record_list.append(record)
return record_list
if __name__ == '__main__':
text_file_reader = TextFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年2月销售数据JSON.txt")
list1 = text_file_reader.read_data()
list2 = json_file_reader.read_data()
for l in list1:
print(l)
for l in list2:
print(l)
2.1.10.4 数据计算
- main.py
from file_define import FileReader, TextFileReader, JsonFileReader
from data_define import Record
text_file_reader = TextFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年2月销售数据JSON.txt")
jan_data: list[Record] = text_file_reader.read_data()
feb_data: list[Record] = json_file_reader.read_data()
# 将2个月份的数据合并为1个list来存储
all_data: list[Record] = jan_data + feb_data
# 开始进行数据计算
data_dict = {}
for record in all_data:
if record.date in data_dict:
data_dict[record.date] += record.money
else:
data_dict[record.date] = record.money
2.1.10.5 可视化开发
# 可视化图表开发
bar = Bar(init_opts=InitOpts(ThemeType.LIGHT))
bar.add_xaxis(list(data_dict.keys())) # 添加x轴数据
bar.add_yaxis("销售额", list(data_dict.values()), label_opts=LabelOpts(is_show=False))
bar.set_global_opts(
title_opts=TitleOpts(title="每日销售额")
)
bar.render("每日销售额柱状图.html")
第二章:SQL入门和实战
![[学习笔记]黑马程序员python教程_第80张图片](http://img.e-com-net.com/image/info8/9e14c04160bf4f05944dd20a3e78ad02.jpg)
2.2.1 数据库介绍
![[学习笔记]黑马程序员python教程_第81张图片](http://img.e-com-net.com/image/info8/e48f5af77bfb4a2bbcc43d844b2a04cc.jpg)
2.2.1.1 数据库管理系统
![[学习笔记]黑马程序员python教程_第82张图片](http://img.e-com-net.com/image/info8/f152787b9fc64e669f37039a1ed57963.jpg)
2.2.1.2 数据库和SQL的关系
![[学习笔记]黑马程序员python教程_第83张图片](http://img.e-com-net.com/image/info8/ba8a1f84d9b9495ead13d0bc47824a59.jpg)
2.2.2 MySQL的安装
mysql的官网:www.mysql.com
略,详细请参考视频
2.2.3 MySQL的入门使用
![[学习笔记]黑马程序员python教程_第84张图片](http://img.e-com-net.com/image/info8/ebf905d58cae4b0992bf115fbd60f2d9.jpg)
2.2.4 SQL基础与DDL
![[学习笔记]黑马程序员python教程_第85张图片](http://img.e-com-net.com/image/info8/8f7eef41e87d4dd690484211459ef7e3.jpg)
![[学习笔记]黑马程序员python教程_第86张图片](http://img.e-com-net.com/image/info8/5a1ec184722f436bb43498c1318fcbf2.jpg)
2.2.4.1 SQL语法特征
![[学习笔记]黑马程序员python教程_第87张图片](http://img.e-com-net.com/image/info8/9f67db88b3844ba6a56940c7aaf96b71.jpg)
2.2.4.2 数据库定义语言-DDL
- DDL-库管理
# 查看数据库
SHOW DATABASES;
# 使用数据库
USE 数据库名称;
# 创建数据库
CREATE DATABASE 数据库名称 [CHARSET UTF8];
# 删除数据库
DROP DATABASE 数据库名称;
# 查看当前使用的数据库
SELECT DATABASE();
- DDL-表管理
# 查看有哪些表
show tables;
# 删除表
drop table 表名称;
drop table if exists 表名称;
# 创建表
create table 表名称(
列名称 列类型,
列名称 列类型,
......
);
-- 列类型有
int -- 整数
float -- 浮点数
varchar(长度) -- 文本,长度为数字,做最大长度限制
date -- 日期类型
timestamp -- 时间戳类型
2.2.5 SQL-DML
DML-数据操作语言。
- 插入
![[学习笔记]黑马程序员python教程_第88张图片](http://img.e-com-net.com/image/info8/095dbf4b930c4f859297ffc1c5597308.jpg)
- 删除
![[学习笔记]黑马程序员python教程_第89张图片](http://img.e-com-net.com/image/info8/e4acdea9da784a27bdafee77a8d31900.jpg)
- 更新
![[学习笔记]黑马程序员python教程_第90张图片](http://img.e-com-net.com/image/info8/14ae66bec9974634973ebdddd2996d45.jpg)
2.2.6 SQL-DQL
![[学习笔记]黑马程序员python教程_第91张图片](http://img.e-com-net.com/image/info8/fb2ecc1b1d8a465fa17987eea071fcae.jpg)
![[学习笔记]黑马程序员python教程_第92张图片](http://img.e-com-net.com/image/info8/bbb67ee791e94a4cbc024f6a38ae6c18.jpg)
![[学习笔记]黑马程序员python教程_第93张图片](http://img.e-com-net.com/image/info8/838c03a3561544c68c0801d984b03e7f.jpg)
2.2.7 Python & MySQL
2.2.7.1 安装pymysql
![[学习笔记]黑马程序员python教程_第94张图片](http://img.e-com-net.com/image/info8/24ef1ff45dec4800a707ff2d487f9bfe.jpg)
2.2.7.2 创建到MySQL的数据库链接
![[学习笔记]黑马程序员python教程_第95张图片](http://img.e-com-net.com/image/info8/a2e6dab464054767be7856c31dac7c3e.jpg)
2.2.7.3 执行非查询性质的SQL语句
cursor = conn.cursor()
conn.select_db("test")
cursor.execute("create table test_pymysql2(id int)")
2.2.7.4 执行查询性质的SQL语句
cursor = conn.cursor()
conn.select_db("world")
cursor.execute("select * from student")
results = cursor.fetchall()
for r in results:
print(r)
2.2.7.5 数据插入
- commit提交
![[学习笔记]黑马程序员python教程_第96张图片](http://img.e-com-net.com/image/info8/1df4028e9e6c49bcaa41ef16a861a399.jpg)
- 自动conmmit
![[学习笔记]黑马程序员python教程_第97张图片](http://img.e-com-net.com/image/info8/5338cab7cec6491ba852c8bbc5ff1218.jpg)
2.2.8 综合案例
2.2.8.1 创建表
![[学习笔记]黑马程序员python教程_第98张图片](http://img.e-com-net.com/image/info8/c93d52d9418942ca82401f3dd76876f5.jpg)
2.2.8.2 实现步骤
![[学习笔记]黑马程序员python教程_第99张图片](http://img.e-com-net.com/image/info8/06cf3dfe0fed4f6b8249e2cd857e5f24.jpg)
from file_define import FileReader, TextFileReader, JsonFileReader
from data_define import Record
from pymysql import Connection
text_file_reader = TextFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年2月销售数据JSON.txt")
jan_data: list[Record] = text_file_reader.read_data()
feb_data: list[Record] = json_file_reader.read_data()
# 将2个月份的数据合并为1个list来存储
all_data: list[Record] = jan_data + feb_data
conn = Connection(
host="127.0.0.1",
port=3306,
user="root",
password="xxxxxx",
autocommit=True
)
cursor = conn.cursor()
conn.select_db("py_sql")
for record in all_data:
sql = f"INSERT INTO orders(`order_date`, `order_id`, `money`, `province`) " \
f"VALUES ('{record.date}', '{record.order_id}', {record.money}, '{record.province}')"
cursor.execute(sql)
conn.close()
2.2.8.3 作业
![[学习笔记]黑马程序员python教程_第100张图片](http://img.e-com-net.com/image/info8/0789509585804e35a5126e844aaa00ff.jpg)
import json
from file_define import FileReader, TextFileReader, JsonFileReader
from data_define import Record
from pymysql import Connection
text_file_reader = TextFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:\\计算机\\Python\\黑马程序员python教程\\资料\\数据分析案例\\2011年2月销售数据JSON.txt")
jan_data: list[Record] = text_file_reader.read_data()
feb_data: list[Record] = json_file_reader.read_data()
# 将2个月份的数据合并为1个list来存储
all_data: list[Record] = jan_data + feb_data
conn = Connection(
host="127.0.0.1",
port=3306,
user="root",
password="xxxxxx",
autocommit=True
)
cursor = conn.cursor()
conn.select_db("py_sql")
sql = f"select * from orders"
cursor.execute(sql)
with open("./json.txt", 'a', encoding='utf-8') as f:
for line in cursor.fetchall():
dict = {}
dict['date'] = str(line[0])
dict['order_id'] = line[1]
dict['money'] = line[2]
dict['province'] = line[3]
tmp = json.dumps(dict, ensure_ascii=False)
f.write(tmp + '\n')
conn.close()
第三阶段:PySpark案例实战
3.1.1 Spark是什么
Apache Spark是用于大规模数据处理的统一分析引擎。简单来说,Spark是一款分布式计算框架,可以调度成百上千的服务器集群。
3.1.2 PySpark
![[学习笔记]黑马程序员python教程_第101张图片](http://img.e-com-net.com/image/info8/ec785d09fe174ae0bacf4c66a423e460.jpg)
![[学习笔记]黑马程序员python教程_第102张图片](http://img.e-com-net.com/image/info8/71adb6f5eb074d9d91eb5c91c76aea1e.jpg)
因为已经学过PySpark了,这里略。
3.2 Python高阶技巧
3.2.1 闭包
-
闭包(函数)
![[学习笔记]黑马程序员python教程_第103张图片](http://img.e-com-net.com/image/info8/e9aa51e378d546e5bf3f43a0d82d1a1e.jpg)
-
在闭包(函数)内修改外部函数的值-nonlocal关键字
![[学习笔记]黑马程序员python教程_第104张图片](http://img.e-com-net.com/image/info8/6144357c3eea4b6980bccec561d456ca.jpg)
-
优缺点
![[学习笔记]黑马程序员python教程_第105张图片](http://img.e-com-net.com/image/info8/b63bceb43fb440f8a64a653d9926cab8.jpg)
3.2.2 装饰器
![[学习笔记]黑马程序员python教程_第106张图片](http://img.e-com-net.com/image/info8/825031cbfb9a4220a64143da303f0ca2.jpg)
装饰器核心思想是:将需要被包装的函数作为参数传递
语法糖:也叫糖衣语法,对语言的功能并没有影响,而是更方便程序员使用
![[学习笔记]黑马程序员python教程_第107张图片](http://img.e-com-net.com/image/info8/360990c70df94673b63f72623e50a0c5.jpg)
3.2.3 设计模式
![[学习笔记]黑马程序员python教程_第108张图片](http://img.e-com-net.com/image/info8/ab23badd09e84dbbae65b968ec3d8fca.jpg)
3.2.3.1 单例模式
![[学习笔记]黑马程序员python教程_第109张图片](http://img.e-com-net.com/image/info8/d7fbc0b8cd5c48df87c463ecce18bc5b.jpg)
![[学习笔记]黑马程序员python教程_第110张图片](http://img.e-com-net.com/image/info8/486a0718562a4207a3c50218aad7c034.jpg)
3.2.3.2 工厂模式
![[学习笔记]黑马程序员python教程_第111张图片](http://img.e-com-net.com/image/info8/ef6631a1351945adb51f39e565b1ed46.jpg)
![[学习笔记]黑马程序员python教程_第112张图片](http://img.e-com-net.com/image/info8/cd720ff054864109b9734b947dc6bd8b.jpg)
3.2.4 多线程
3.2.4.1 进程、线程
![[学习笔记]黑马程序员python教程_第113张图片](http://img.e-com-net.com/image/info8/0860b770e468441bbe59ef9f9a82575c.jpg)
进程是系统资源调度的基本单位,线程是系统资源的最小单位
![[学习笔记]黑马程序员python教程_第114张图片](http://img.e-com-net.com/image/info8/959f02f5facd4151bec63c2dd91d981b.jpg)
3.2.4.2 并行执行
![[学习笔记]黑马程序员python教程_第115张图片](http://img.e-com-net.com/image/info8/a82be3bc0d434a48b666b51cd15c05c1.jpg)
3.2.4.3 多线程编程
- threading模块
![[学习笔记]黑马程序员python教程_第116张图片](http://img.e-com-net.com/image/info8/3979bfe597ce4c06b6e96983e89d0c65.jpg)
每个Thread类对象就是多线程中的一个线程
把工作封装到函数里,然后传入到target参数
- 具体需求
![[学习笔记]黑马程序员python教程_第117张图片](http://img.e-com-net.com/image/info8/330828e01f2949d899ab055371008de8.jpg)
- 代码实现
![[学习笔记]黑马程序员python教程_第118张图片](http://img.e-com-net.com/image/info8/97871aabde154d3780644701d55938d4.jpg)
- 传参
![[学习笔记]黑马程序员python教程_第119张图片](http://img.e-com-net.com/image/info8/dd6d5af12d86456984e6825026d3abc7.jpg)
![[学习笔记]黑马程序员python教程_第120张图片](http://img.e-com-net.com/image/info8/706003809bf14315ae7da818ada24ec4.jpg)
3.2.5 网络编程
3.2.5.1 Socket
![[学习笔记]黑马程序员python教程_第121张图片](http://img.e-com-net.com/image/info8/b2180b3361a948aaa3a3a9d903a5f9bc.jpg)
3.2.5.2 客户端和服务端
![[学习笔记]黑马程序员python教程_第122张图片](http://img.e-com-net.com/image/info8/74b08129bfab43fda8db14eda5c35980.jpg)
3.2.5.3 Socket服务端编程
![[学习笔记]黑马程序员python教程_第123张图片](http://img.e-com-net.com/image/info8/f76ea6ae8e8d4f38a8fdae096968b6bf.jpg)
![[学习笔记]黑马程序员python教程_第124张图片](http://img.e-com-net.com/image/info8/bb219c3e39f9415db339c906934ad712.jpg)
- 实现服务端并结合客户端进行测试
![[学习笔记]黑马程序员python教程_第125张图片](http://img.e-com-net.com/image/info8/67a985fd2609489c8b063d6c6cd2c720.jpg)
import socket
# 创建Socket对象
socket_server = socket.socket()
# 绑定ip地址和端口
socket_server.bind(('localhost', 8888))
# 监听端口
socket_server.listen(1)
# listen方法内接受一个整数传参数,表示接受链接数量
# 等待客户端链接
conn, address = socket_server.accept()
# accpet方法返回的是二元元组(链接对象, 客户端地址信息)
# accpet方法是阻塞方法,等待客户端链接,如果没有链接,就卡在这一行不向下执行
print(f"接收到了客户端的链接,客户端的信息是:{address}")
# 接受客户端信息
data = conn.recv(1024).decode('utf8')
# recv也是阻塞方法,等待客户端发送信息
# recv接受的参数是缓冲区大小,一般给1024即可
# recv方法的返回值是一个字节数组(bytes对象),不是字符串,可以通过decode方法通过utf0编码,将字节数组转换为字符串对象
print(f"客户端发来的消息是:{data}")
# 发送恢复消息
msg = input("请输入你要和客户端回复的消息:")
conn.send(msg.encode('utf8'))
# encode可以将字符串编码为字节数组对象
conn.close()
socket_server.close()
3.2.5.4 Socket客户端开发
![[学习笔记]黑马程序员python教程_第126张图片](http://img.e-com-net.com/image/info8/d0baf4cf867b491aa006c0a12e3fdf38.jpg)
![[学习笔记]黑马程序员python教程_第127张图片](http://img.e-com-net.com/image/info8/185f66e24b9b4bc2ad80cf9bb4eb71e4.jpg)
3.2.6 正则表达式
![[学习笔记]黑马程序员python教程_第128张图片](http://img.e-com-net.com/image/info8/fca80d7bc8474de5ba52b676422569a0.jpg)
3.2.6.1 正则的三个基础方法
- re.match
![[学习笔记]黑马程序员python教程_第129张图片](http://img.e-com-net.com/image/info8/9b74055c0d714062abb04cbc90b97774.jpg)
- re.search
![[学习笔记]黑马程序员python教程_第130张图片](http://img.e-com-net.com/image/info8/be94509358464cd3a8e3a78e4908ecf0.jpg)
- re.findall
![[学习笔记]黑马程序员python教程_第131张图片](http://img.e-com-net.com/image/info8/2b89d1e4330d4ef99fc8cdeea6b860ba.jpg)
3.2.6.2 元字符匹配
- 单字符匹配
![[学习笔记]黑马程序员python教程_第132张图片](http://img.e-com-net.com/image/info8/2252bf2e8c524ee39dffb1765e14b609.jpg)
字符串前面带上r的标记,表示字符串中转义字符无效,就是普通字符的意思
- 数量匹配
![[学习笔记]黑马程序员python教程_第133张图片](http://img.e-com-net.com/image/info8/32bb0d75a17a4a7788362d4aa8761142.jpg)
- 边界匹配
![[学习笔记]黑马程序员python教程_第134张图片](http://img.e-com-net.com/image/info8/b3d8c4dc9e8b46bf9579d6276772d9e2.jpg)
- 分组匹配
![[学习笔记]黑马程序员python教程_第135张图片](http://img.e-com-net.com/image/info8/2cdb04fee8f34760b5ac2c7c677147ee.jpg)
- 案例
![[学习笔记]黑马程序员python教程_第136张图片](http://img.e-com-net.com/image/info8/87bd8f3946954a57a3266c08c8b0146d.jpg)
{}中间别带空格
3.2.7 递归
![[学习笔记]黑马程序员python教程_第137张图片](http://img.e-com-net.com/image/info8/0239ab4c94dd4711b0aeaec5ac1dd1fb.jpg)
![[学习笔记]黑马程序员python教程_第138张图片](http://img.e-com-net.com/image/info8/4e48b2982996476d8f098034c2185d16.jpg)