后端开发——Tornado框架入门学习
自说自话biubiubiu
最近几天想搭建一个图片服务器,想着用tornado框架来写一下应用服务器后端的代码,突然发现有些模块用起来比较生疏,明明一个月前刚刚学习上手敲了一个tornado框架的后端。唉。。。所以还是有必要把自己学的东西再回顾一下,嗯!再预习一遍哈哈哈。
目录
前言
一、Tornado是什么?
二、基本架构
2.1 Tornado性能高效原理图
2.2 Tornado的底层模块
2.3Tornado的主要模块
三、网络服务
3.1非阻塞的HTTP服务器——tornado.httpserver
3.2 路由和传参
3.3 python中的request对象属性
四、异步与协程
4.1 回调异步
4.2 协程异步
4.3 什么是协程
总结
前言
在这篇文章中,我会讲一下Tornado框架的基础知识以及我个人怎么去学习tornado框架的。浅薄地写一点东西了哈哈哈。
一、Tornado是什么?
介绍任何一个东西,万变不离其宗的就是这个问题了。所以Tornado到底是什么?网上也有着很多的解释和定义。而我个人的理解是:Tornado既是一个简单的web后端框架,同样也是一个优秀的异步非阻塞式的web服务器,Tornado比较适合长轮询、高并发的业务场景,在异步逻辑的实现上更为方便。Tornado是一个非常轻量级的web框架,比较适合新手上手开发,部署也比较简单。
二、基本架构
2.1 Tornado性能高效原理图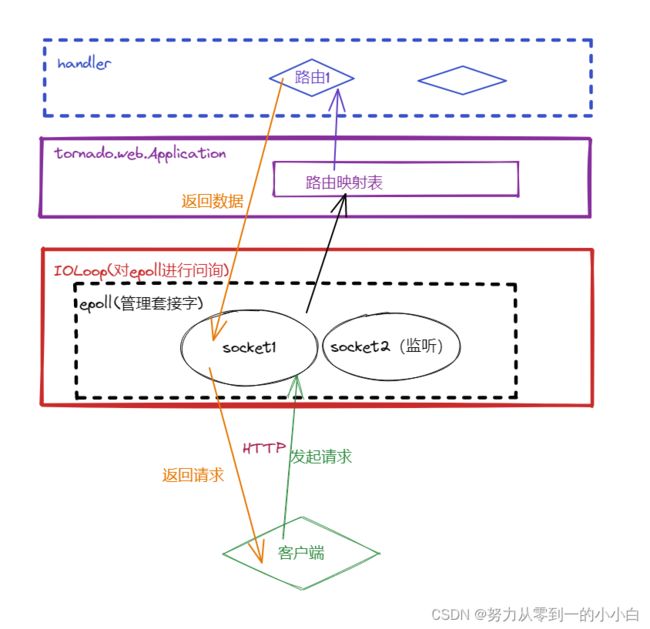
从上图中知晓,Tornado框架是基于Linux内核epoll来实时管理每一个客户端连接服务器产生的socket(套接字),通过IOLoop实例对象不断地对epoll进行轮询,根据路由映射表将获得客户端请求的数据从 socket发送至对应的路由下,由相应的响应函数执行后将数据发送至客户端。
那么Tornado到底高效在哪里?
其实Tornado是单线程的,它基于Linux-epoll对socket进行管理,那么当路由下的响应函数处理完任务后会返回数据到socket中,这个过程是异步的,这意味着单线程的Tornado框架是可以满足同属处理大量的请求的,数据处理的速度会比较快。
2.2 Tornado的底层模块
| 模块 | 功能 |
|---|---|
| httpserver | 异步非阻塞HTTP服务器模块 |
| iostream | 对非阻塞式的socket的建档封装,方便读写操作 |
| ioloop | 核心的I/O循环 |
2.3Tornado的主要模块
| 模块 | 功能 |
|---|---|
| web | 基础的web框架 |
| escape | HTML,JSON,URL解码方式 |
| template | HTML模板 |
| httpclient | 非阻塞式HTTP客户端 |
| options | 解析命令行和配置文件 |
| application | 路由映射列表 |
三、网络服务
3.1非阻塞的HTTP服务器——tornado.httpserver
Tornado的httpserver模块是Tornado框架的web服务的实现基础,在搭建Tornado的web服务时需要创建一个HTTPServer实例对象,并将app对象传递给HTTPServer实例对象,同时需要指定服务器的监听端口和和需要开启的进程数,同时开启IOLoop非阻塞套接字I/O时间循环。
import tornado.web
import tornado.ioloop
import tornado.httpserver
if __name__ == '__main__':
//路由映射表
app = tornado.web.Application([
(r"/",IndexHandler)
])
//初始化httpserver实例对象
httpServer = tornado.httpserver.HTTPServer(app)
//指定服务器的端口
httpServer.bind(8080)
//指定开启进程数,默认为1
httpServer.start(1)
tornado.ioloop.IOLoop.current().start()或许你可能会问前面讲到Tornado不是单进程的吗,为什么还要指定进程数呢?
我个人觉得其实应该这么理解,Tornado的高效性体现在其异步实现逻辑的简便高效,更体现Tornado在单进程模式下的高并发量,它的事件循环(IOLoop)是一个单线程。当它不是只能以一个线程来是使用的,你当然可以把它丢到线程池中去。同时,Tornado为用户部署网络服务提供了一个方法httpServer.listen(),但该方法仅适用于单进程状态下。
if __name__ == '__main__':
app = Application()
httpServer = tornado.httpserver.HTTPServer(app)
httpServer.listen(config.options["port"])
tornado.ioloop.IOLoop.current().start()3.2 路由和传参
在映射路由表中主要是以如下的形式记录路由的:
(r'/../../',RequestHandler)
在真实的项目开发中,我们在进行页面之间的数据传递有时需要在路由中加上查询参数来实现,那么如何为路由初始化添加查询参数呢?Tornado的handle语法是支持自定义初始化的查询参数的值的,示例代码如下:
//路由中
(r'/crj/(\w+)/(\w+)',index.CrjHandler)//视图中
class CrjHandler(RequestHandler):
def get(self,key1,key2,*args,**kwargs):
print(key1+key2)
self.write("crj is a nice man")需要注意的是,像上述代码中这样定义的查询参数不只是在get方法中可行,在post方法中也可以获取到查询参数噢!
那如何在传递前就指定参数的名称?
//其中(P\w+)即可实现在定义路由时就可以指定参数
(r'/crj/(?P\w+)/(P\w+)') 还有一种方法可以在传递路由时将参数传出:
(r'/../../',Handler,{"key1":"value1","key2":"value2"})此时在对应路由下的方法(以get()方法为例)可以获取参数:
class Handler(RequestHandler):
def initialize(self,key1,key2):
self.key1 = key1
self.key2 = key2
def get(self,*args,**kwargs):
print(self.key1)
self.write(self.key2)反向解析
即通过我们定义给路由的名字来获取到目标路由的正则匹配。
示例代码如下:
//路由中代码
tornado.web.url(r'/crj',index.CrjHandler,{"key":"values"},name="crj")class IndexHandler(RequestHandler):
def get(self,*args,**kwargs):
url = self.reverse_url("crj")
self.write("来到我的主页"%(url))3.3 python中的request对象属性
| 属性 | 功能 |
|---|---|
| method | http请求的方式 |
| host | 被请求的主机名 |
| uri | 请求的完整路由 |
| path | 请求路径 |
| query | 请求的参数 |
| headers | 请求的协议头 |
| body | 请求体 |
| remote_ip | 客户端的ip地址 |
| files | 用户上传的文件类型 |
这里总结一下吧,app是一个后端实例,可以理解为一个路由映射表,记载着不同路由地址及其所对应的handler。handler就是我们后端应用的业务逻辑,主要用来处理socket转发来的请求数据,ioloop就是Tornado的核心,可以理解为服务器引擎,ioloop轮询epoll内核并将有收到客户端请求的socket中的数据发送给对应的handler。
其实对于初学者来说没有熟悉上述的模块看到这里其实是很懵的,我在入门学习的时候也是比较困惑,这一些些模块有啥子用?哈哈,其实硬刚官方文档是比较枯燥且耗时的,而且很多概念不是很清楚,这时候我建议是去看相关的视频教程,有了初步了解了之后再去看文档,一些概念就会清楚多了。
四、异步与协程

4.1 回调异步
@tornado.web.asynchronous
def get(self,*args,**kwargs):
...
client = AsyncHTTPClient()
client.fetch(url,callback)4.2 协程异步
@tornado.gen.coroutine
def get(self,*args,**kwargs):
res = yield callback()
//或者
@tornado.gen.coroutine
def get(self,*args,**kwargs):
ret = yield client.fetch(url)
if res.error:
ret = {"ret": 0}
else:
ret = "successfully"
raise tornado.gen.Return(ret) 4.3 什么是协程
协程运行在线程之上,当一个协程执行完成后,可以选择主动让出,让另一个协程运行在当前线程之上。协程并没有增加线程数量,只是在线程的基础之上通过分时复用的方式运行多个协程,而且协程的切换在用户态完成,切换的代价比线程从用户态到内核态的代价小很多。
前面提到Tornado是单线程的,那么在面对一些耗时操作时Tornado为了保证其高并发的能力,会在单一线程中将耗时操作挂起,即单一线程分出协程挂起耗时操作,主线程来做一些简单的操作。
//Tornado开启协程其实很简单,在要实现异步的函数前加上
@gen.coroutine
//然后用python中的生成器yield修饰Future实例对象
总结
以上只是我个人学习Tornado框架基础应用的总结,个人感觉自己做一个小项目的话初期其实没必要学习太过深入,理解几个基本概念(比如协程),会灵活地使用异步操作,懂得如何部署一个基本地后端服务就可以了,然后在之后地学习不断深入。其实刚刚开始了解一个框架可能会面临大量的问题,很多东西不懂,看完就忘。我个人的建议还是先看教程再刚文档,文档最好还是要过一遍,这样学习的周期比较短呐,有时间就做个项目玩玩咯。一起加油吧!