Apache hudi 0.10.1学习笔记之压缩Compaction(下篇)——执行压缩计划
之前的压缩计划生成后,被保存在basePath/.hoodie下的instanttime.compaction.request文件里。 现在可以继续从执行压缩计划的角度进行。同样使用compactor类来提交spark作业,参数里可以带压缩计划对应的instantTime,也可以不带,不带的话则是找到时间最早对应的压缩计划。本文还是以MOR表,经手动异步压缩作为开始。
执行压缩计划部分,需要提前了解下该过程涉及的封装类,例如
RunCompactionActionExecutor、IndexedRecord、各种handle类等等
下方为执行异步压缩计划的提交命令,并给出了目标instantTime:

通常这个spark会跑2-10分钟就自己停了。该作业跑完并不是表示真正完成了压缩,而是把压缩作为一个特殊的commit,继续按照顺序处理各种commit。以0.10.0版本来看,这里触发的压缩过程和正常写入hudi是独占的,即同一时间只能进行写入或压缩。
省掉前面一部分调用,代码从SparkRDDWriteClient.java 的compact方法开始。
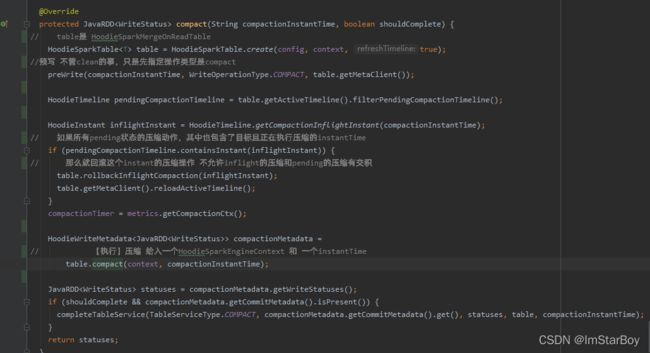
HoodieInstant inflightInstant = HoodieTimeline.getCompactionInflightInstant(compactionInstantTime); pendingCompactionTimeline.containsInstant(inflightInstant)
就是确保给的instantTime,对应其inflight的instant不能也出现在pending状态的hoodieInstant,否则就要回滚这个inflight的instant。简单来说就是不允许该时间的compaction类型的hoodieInstant,又是pending又是inflight,避免逻辑上矛盾。
这步同时也获得了table。于是继续table.compact(context, compactionInstantTime);
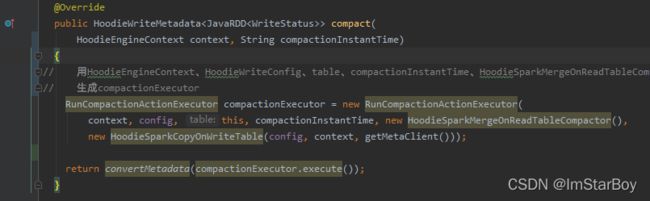
即用HoodieEngineContext、HoodieWriteConfig、table、compactionInstantTime、HoodieSparkMergeOnReadTableCompactor、HoodieSparkCopyOnWriteTable这些变量构造了一个RunCompactionActionExecutor对象。
HoodieEngineContext 由HoodieSparkEngineContext实现,其包括
JavaSparkContext和SQLContext,最后转为spark作业dag才会用到;
HoodieWriteConfig就是用户给定的各种参数,包括压缩策略名等等配置。
table就是HoodieSparkMergeOnReadTable,也就是前面就已经从HoodieWriteConfig和HoodieEngineContext里得到的table
compactionInstantTime是String类型的instantTime,也就是执行压缩时用户指定的(现有最早的可压缩计划)
HoodieSparkMergeOnReadTableCompactor暂时先不讲,他负责preCompact(确保目标instantTime对应的hoodieInstant被pendingCompactionInstant包含着,也就是被先前生成的压缩计划里所包含)和maybePersist(设置RDDstorage level)。
HoodieSparkCopyOnWriteTable一个根据相同HoodieWriteConfig和HoodieEngineContext构建的cow表。
并调用该对象的execute()方法

先经过上方讲过的preCompact过程,即把现存的pending状态的compaction拿出来,然后检查本次压缩时给定的instantTime在不在其中,不在其中就会抛出异常。
然后再是CompactionUtils.getCompactionPlan(table.getMetaClient(), instantTime),目的就是从输入的instantTime对应的istantTime.compaction.requested文件里获取压缩计划(计划怎么写入该文件可参考上一篇)。并将压缩计划和新版本号写入元数据中。
再进一步执行compactor.compact( context, compactionPlan, table, config, instantTime, compactionHandler); 注意这里的compactionHandler就是前面创建的HoodieSparkCopyOnWriteTable对象。

新的instant就是instantTime.compaction.requested,instantTime还是一开始给的那个目标时间。
然后把这个requested的instant,经过transitionState方法转为inflight的instant,即开始执行压缩计划。
下方try部分,就是从一开始给定的schema里(已经在HoodieTableMetaClient)创建新的schema,注意这里指定了不添加新的元数据字段。如果添加那schema就多5个字段,包括主键(_hoodie_record_key)、分区(_hoodie_partition_path)等字段。
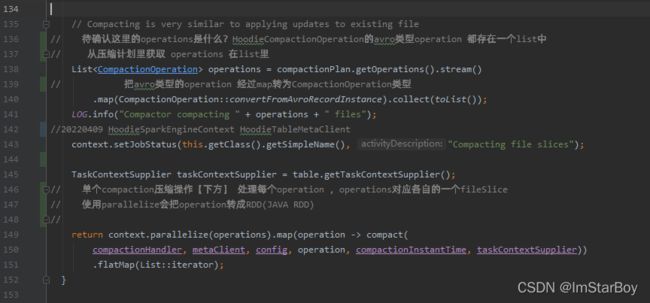
这里是把上方拿到的压缩计划,取出其operations(operation包含什么信息请看上篇)转成流,就能进行map操作。map里的逻辑是把每个operation从HoodieCompactionOperation转为CompactionOperation并保存到List中(前者是avro格式,其他详细的后面再区分)。
context.parallelize(operations).map(operation -> compact(
compactionHandler, metaClient, config, operation, compactionInstantTime, taskContextSupplier))
.flatMap(List::iterator);
context.parallelize(operations)就是把operation转为spark的JavaRDD(不准确,本身还是HoodieData)。之后对每个RDD都单独调用一次中间的compact( compactionHandler, metaClient, config, operation, compactionInstantTime, taskContextSupplier)
到此,compactionHandler即上方的cow表、HoodieTableMetaClient、writeConfig、压缩计划operation、目标instantTime以及SparkTaskContextSupplier都参与进一步的针对每个operation,如下所示:

先给上一步拿到的schema增加提到的5个元数据字段,是否额外添加第6个字段operation,则要看用户配置的writeConfig中是否明确相关参数为true,否则还是默认的只加5个字段。
maxInstantTime是在所有active的timeline里拿出deltacommit commit rollback这三种action且timeline对应的instant为completed状态的timeline,并且取其最新(最大的时间值)。
maxMemoryPerCompaction是从writeConfig里读取到的参数,表示压缩可用最大的内存,超出这个阈值的则会被暂存到本地磁盘上。

logFiles说的就是FileSlice里哪些avro的*.log*文件。这里他从CompactionOperation的deltaFileNames里获得。那么这个daltaFileNames当初怎么初始化的值呢?其实同样也是从logFiles里折腾出来的:

回到daltaFileNames,他经过给自己加上bastPath(含表名)和分区目录后,也就是重新回到了logFile。
这里的scanner是比较麻烦的部分,包含了很多用户指定(或default)参数,以及提到的logfile、带meta字段的新schema等等。下方会用到一个scanner.getRecords()
this.records = new ExternalSpillableMap<>(maxMemorySizeInBytes, spillableMapBasePath, new DefaultSizeEstimator(),
new HoodieRecordSizeEstimator(readerSchema), diskMapType, isBitCaskDiskMapCompressionEnabled);
ExternalSpillableMap类按照其类最上方的解释来看,是为了防止内存满时,以kv形式存储数据,同时也存储了Key-ValueMetadata即保存在磁盘上的位置。这一点还需要进一步确认
其参数分别是
hoodie.memory.compaction.max.size、
hoodie.memory.spillable.map.path、也就是baseFilepath(待补全)
DefaultSizeEstimator用来评估key大小、
HoodieRecordSizeEstimator(readerSchema)用来评估value大小、
diskMapType(分为BITCASK或ROCKS_DB)、
hoodie.common.diskmap.compression.enabled默认是true
oldDataFileOpt暂时理解为basefile,是否为空取决于是只有logfile还是logfile和basefile都存在。前者情况下oldDataFileOpt为空,后者则为basefile。(因为oldDataFileOpt也是来在option中的bootstrapFilePath,所以他跟basefile一样可能有也可能不存在)
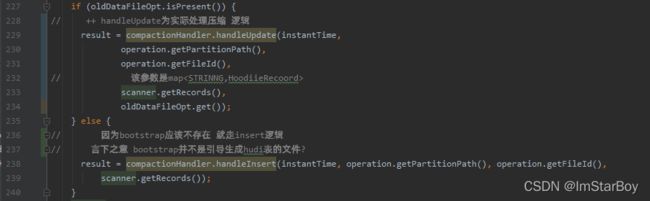
所以这里走else的逻辑,即handleInsert()。下方继续构建HoodieCreateHandle实例,注意
taskContextSupplier就是上方构建过的,recordMap就是上面提到的map类型的数据。
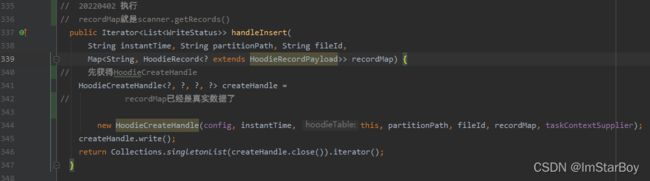
write方法如下:
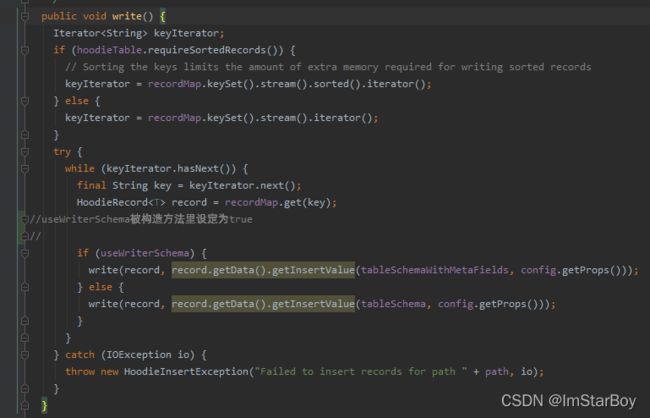
hoodieTable.requireSortedRecords()首先是false,因为当前basefile都是.parquet文件,只有当为.hfile时才为true。
再把上方说的map形式的recordMap,其key的集合搞Iterator
关于useWriterSchema,上方new这个HoodieCreateHandle对象时,已经把useWriterSchema写死了。

所以继续 write(record, record.getData().getInsertValue(tableSchemaWithMetaFields, config.getProps()))。注意后续一系列方法调用中都是这两个参数,均来自value:"record"这个值。
其中,record.getData().getInsertValue(tableSchemaWithMetaFields, config.getProps())
tableSchemaWithMetaFields变量就是之前写入writeConfig的schema并且是有5个元数据字段的schema。config.getProps()就是所有writeConfig的配置。
后续会走processNotMatchedRecord来处理这些消息,把byte消息转为avro,再结合schema生成GenericRecord以及后面的SqlTypedRecord,省掉getEvaluator等逻辑,最后会把这些消息的结果返回(avro的IndexedRecord类型,可以理解为avro包下实现了一种对数据的封装,可以set和get其中的值)。
再回到这里的write方法延申,注意preserveHoodieMetadata参数为false,创建HoodieCreateHandle对象时依然保持其为false。
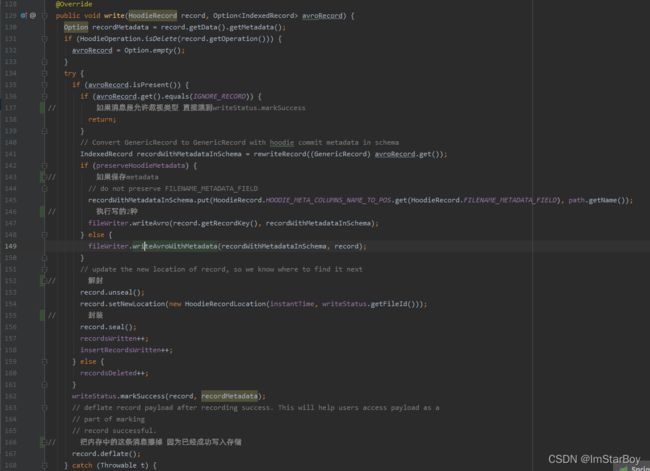
IndexedRecord recordWithMetadataInSchema = rewriteRecord((GenericRecord) avroRecord.get());
大致是把老数据重新写入一个新schema里,依旧是IndexedRecord 。(待确认:过程中writeSchemaWithMetaFields 这个schema是怎么生成的?)
fileWriter.writeAvroWithMetadata(recordWithMetadataInSchema, record);
这个就是把参数里的recordWithMetadataInSchema调用org.apache.parquet.hadoop的write方法去写入。写parquet文件的同时再把对应的消息的key更新到布隆过滤器中(顺便也判断下是否再插入后修改布隆过滤器的最大最小边界为刚才的key)

record.setNewLocation(new HoodieRecordLocation(instantTime, writeStatus.getFileId()));
给本条消息确认出他归属的位置(文件名中的instant和Fileid)并保存。
到此insert场景大致流程已经有了,下方继续update分支
回到 HoodieCompactor.java此处
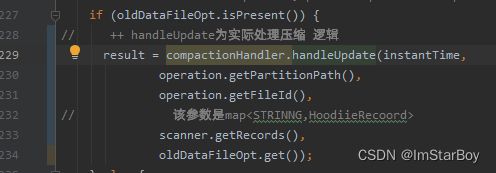

新创建HoodieMergeHandle对象,其中
keyToNewRecords和insert过程一样,scanner.getRecords()返回的一个ExternalSpillableMap
oldDataFile是现存的baseFile

config.populateMetaFields()这个值默认为true,于是keyGeneratorOpt暂时为空。
requireSortedRecords还是false,因为是parquet不是hfile。
再创建对象:
new HoodieMergeHandle(config, instantTime, this, keyToNewRecords, partitionPath, fileId,
dataFileToBeMerged, taskContextSupplier, keyGeneratorOpt);
注意dataFileToBeMerged就是oldDataFile。
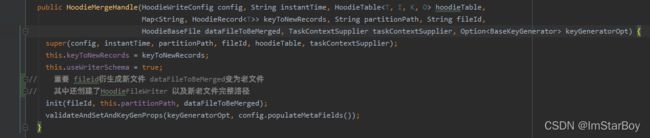
重点说下init方法
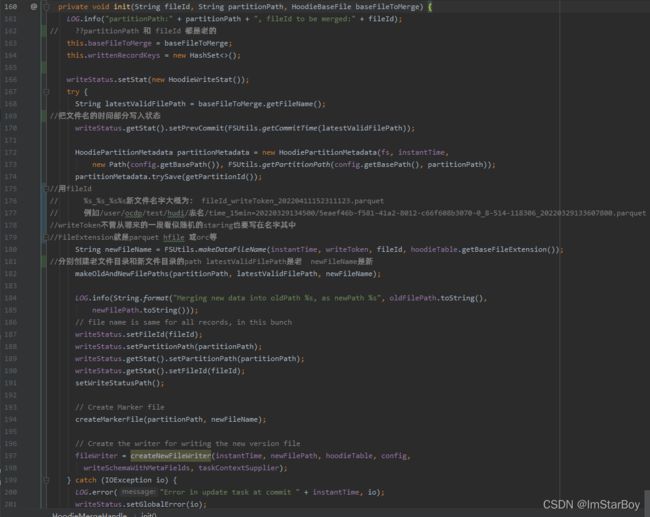
baseFileToMerge为dataFileToBeMerged 现存的basefile。
String latestValidFilePath = baseFileToMerge.getFileName();获得baseFile名且包含了完整的路径。
String newFileName = FSUtils.makeDataFileName(instantTime, writeToken, fileId, hoodieTable.getBaseFileExtension());
大致就是根据提供的instantTIme等因素,拼凑出一个.parquet文件的名字例如
/user/ocdp/test/hudi/表名/time_15min=20220329134500/5eaef46b-f581-41a2-8012-c66f608b3070-0_8-514-118306_20220329133607800.parquet
上方就先后获取了老的和新baseFile的完整名字,再进行
makeOldAndNewFilePaths(partitionPath, latestValidFilePath, newFileName);

也就是为HoodieMergeHandle的两个path oldFilePath、newFilePath附上各自处理后的值。也就是新老各自的basePath+分区名+xxx.parquet。
到此init方法结束,继续把包括空的keyGeneratorOpt等变量都继续赋给HoodieMergeHandle对象upsertHandle。再回到handleUpdateInternal(upsertHandle, instantTime, fileId)
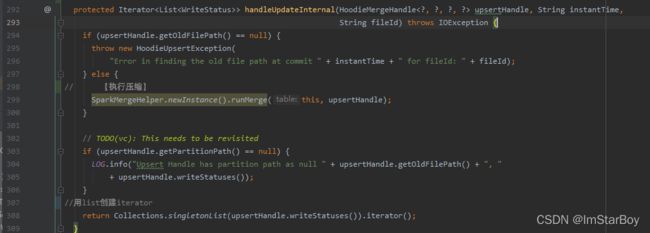
因为upsertHandle.getOldFilePath()是上一步刚获得的oldFilePath,正常情况下肯定不为空。
所以走分支:SparkMergeHelper.newInstance().runMerge(this, upsertHandle)
(未完待续)