2019独角兽企业重金招聘Python工程师标准>>> 
新读一篇论文,试着翻译一下,原文在这。
摘要
CASPaxos是一个无等待,线性化,多读者和多写者的寄存器,支持在不可靠的异步网络上执行任意更新操作,包括compare-and-set(CAS)。 该寄存器充当复制状态机,它通过应用用户提供的任意函数(命令)提供一个更改其值的接口。 与复制命令日志的Multi-Paxos和Raft不同,CASPaxos复制状态,从而避免了相关的复杂性,减少了写放大,提高了磁盘操作的并发性和硬件利用率。
该论文描述了CASPaxos,证明了它的安全属性并评估了基于CASPaxos的kv存储原型的特性。
1 介绍
复制状态机(RSM)协议允许一组节点作为状态机工作,以容忍非拜占庭节点故障和通信问题。 该协议可确保在任意节点崩溃、消息丢失和无序传送的情况下的安全性; 并在N台机器中不多于(N-1)/2个机器停机或断开时保持可用性。
RSM和容错强一致(可线性化)存储在某种意义上是等价的。这就解释了为什么Multi-Paxos和Raft作为分布式系统的基础(例如Chubby,Etcd,Spanner)在业界广泛使用。
尽管这些协议被广泛的使用,但是仍无法避免它们的复杂性。Diego Ongaro和John Ousterhout在“寻找可理解的共识算法”一文中写道:
在NSDI 2012的与会者非正式调查中,我们发现很少有人对Paxos感到满意,即使是经验丰富的研究人员也是如此。 我们自己也与Paxos挣扎了很久 ; 我们无法理解完整的协议,直到阅读了几个简化的解释并设计了我们自己的替代协议,这一过程花费了近一年的时间
Google的工程师写下了他们在“Paxos Made Live”论文中构建Paxos数据库的经验:
尽管在现有的文献中,构建这样一个数据库被证明是不平凡的......虽然Paxos的伪代码可以只用一页来描述,但是我们的完整实现包含数千行C++代码。。。 Paxos算法的描述与真实世界系统的需求之间存在巨大差距。
RSM协议的复杂性可以解释其在实现中的挑战性。 Kyle Kingsbury对分布式一致性存储进行了全面的研究,发现几乎所有他测试的系统在某些版本中都存在违反线性化的问题,包括MongoDB,Etcd,Consul,RethinkDB,VoltDB和CockroachDB。
除了复杂性,这些协议还存在暂时的可用性问题。 “There Is More Consensus in Egalitarian Parliaments”这篇论文中描述了一种适用于Multi-Paxos和Raft的基于领导者系统的缺点:
传统的Paxos变体对长期和瞬时负载尖峰和网络延迟都很敏感,这些都会增加master的网络延迟。。。 这种单主优化会损害可用性:如果主失效,系统将无法为请求提供服务,直到选出新主。。。 Multi-Paxos具有高延迟,因为本地副本必须将所有命令转发给稳定的领导。
我们提出了CASPaxos,一种用于构建RSM的新型无领导者协议,避免了与Multi-Paxos/Raft相关的复杂性以及具有领导者的可用性问题,并且减少了写入放大。
基于Multi-Paxos的系统是建立在复制日志之上的RSM,它将每个日志条目视为命令。 复制日志由一系列Synod(也称为单一Paxos)实例组成。 根据Raft论文,其复杂性来自组合规则:
我们假设Paxos的不透明来源于其选择单一决策作为其基础。。。 Multi-Paxos的组合规则增加了显着的额外复杂性和微妙之处。
其中一个原因是没有广泛认可的Multi Paxos算法。 Lamport的描述主要是关于单一决策的Paxos; 他勾勒出了可能的方法来实现Multi Paxos,但是许多细节都不见了。 结果,实际系统与Paxos几乎没有什么相似之处。 每个实施都从Paxos开始,发现实施它的困难,然后开发出一个截然不同的体系结构。。。 真正的实现与Paxos如此不同,以至于没办法从理论上证明它是对的。
CASPaxos的主要思想是复制状态而不是命令日志。 我们通过扩展Synod而不是直接使用它来构建模块。 因此,没有组成和相关的复杂性。 允许我们用不到500行代码就可以实现它。
作为Synod的扩展,CASPaxos使用其对称的对等方法,并自动实现在EPaxos论文中设置的目标:(1)在真实环境下容错时保证最佳延迟; (2)所有副本的统一负载均衡(从而实现高吞吐量); 和(3)当副本缓慢或崩溃时性能下降。
正确性。 该协议有附录A中的正式证明。Tobias Schottdorf和Greg Rogers独立建模,使用TLA+4对协议进行验证。
2 协议
我们首先从主 - 主复制的角度简要描述Synod协议,然后逐步与CASPaxos进行比较。
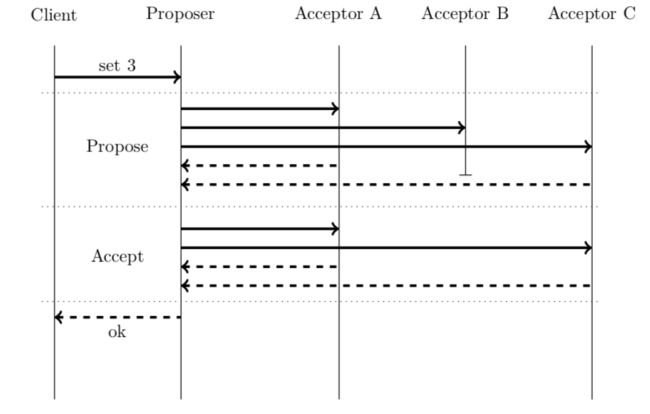
2.1 Synod
Synod协议的实现是一个只能初始化一次的分布式寄存器(译者注:单决策)。 当多个客户端尝试同时初始化它时 , 最多只有一个客户端成功。 一旦客户收到确认,所有后续初始化必须返回先前已经选择的值。
该寄存器属于CAP定理的CP范畴,为了始终保持一致性(线性化),当多于(N-1)/2个节点停机时集群将不可用。
系统中的每个节点扮演client,proposer 和 acceptor。
Client 通过与proposer沟通发起请求; Client可能是无状态的,系统可能有任意数量的Client。
Proposers 通过与acceptors进行通信来执行初始化。 Proposers需要生成唯一的不断增加的更新ID(ballot numbers),系统可能有任意数量的Proposers。
Acceptors存储接受的值; 系统应该有2F+1个Acceptors来容忍F个出现故障。
使用元组作为选票ID(ballot numbers)很方便。 为了生成它,Proposer将其标识ID与本地递增计数器相结合: (counter,ID)。 为了比较选票元组(ballot tuples),我们应该比较元组的第一个元素,并仅将ID用作决胜者。
当proposer收到来自acceptor的冲突消息时,应该更新其计数器以避免将来发生冲突。
2.2 CASPaxos
一个CASPaxos的实现是一个可重写的分布式寄存器(译者注:和单决策的重大不同)。客户端通过提交一个无副作用的函数来改变一个值,这个函数会根据当前状态产生一个新的状态。这在并发请求中只有一个可以成功(译者注:这就是为什么叫CAS,每个变更函数在更改状态之前都会先检查当前状态版本,只有成功的才会进行更改),一旦客户端得到确认,就可以保证所有将来的状态都是它的后来状态:存在一条将它们连接在一起的变化链。
和Synod一样,这也是一个CP系统,也需要2F+1个节点来容忍F个节点故障。因此,它也包含相同的角色:clients, proposers, and acceptors,并且包含一个非常相似的两阶段状态转换机制。
让我们一步步对比着看Synod和CASPaxos协议(译者注:表格中的英文就不翻译了)。



正如我们所看到的,CASPaxos的状态转换与Synod的初始化几乎相同,如果我们使用下面的表达式作为变更函数(change functions),那么它们的确会变得相同。
![]()
通过选择一组不同的变更函数,我们可以将CASPaxos转换为分布式寄存器,并在一次操作中通过使用用户定义的任意函数自动更改其值。 例如,以下变更函数实现了支持CAS的寄存器。
将寄存器初始化为val0
![]()
如果当前值的版本为5就把值改为val1
![]()
读该值
![]()
通过这种特殊化,该协议与Bizur非常相似(译者注:上述的0,5,6就可以表示val的当前版本)。
2.2.1 往返路径优化
由于第一阶段并不依赖变更函数,之后的prepare消息可以通过当前的accept消息进行捎带,从而可以将往返次数从两次降低为一次。
在这种情况下,一个proposer可以缓存上次写入的最新值,并且clients应该使用该proposer来初始化状态转换。即使客户端向另一个proposer发送请求该优化也不会影响安全性。
2.2.2 跨WAN部署的低延迟、高吞吐的共识算法
WPaxos论文描述了如何通过object stealing(译者注:不知怎么翻译)实现跨广域网络的低延迟和高吞吐共识。它利用灵活的大多数(quorums)思想来减少WAN通信成本。 由于CASPaxos是Synod的扩展并支持FPaxos(请参阅附录B中的证明),因此它也支持WPaxos优化。
2.3 集群成员变更
集群成员变更是指在不丧失寄存安全性和可用性的前提下改变集群的节点。这个过程是非常重要的,因为它解决了两个问题:
1.如何调整系统的容错能力。随着时间的推移,系统的容错能力可能需要改变。因为具有N节点基于CASPaxos的系统允许最多(N-1)/2个节点宕机,因此增加或减少集群的节点数也会相应的增加或减少系统的容错能力。
2.如何替换系统中的失效节点。CASPaxos容忍节点出现短暂的失效,但是如果是硬件出现故障,如果不进行替换,时间长了宕机节点数就会超过(N-1)/2这个限制,因此系统将变得不可用。一个具有N节点的集群的失效节点替换可以被抽象成先缩容再扩容的过程。
成员变更处理是基于Raft关于两种不同配置在转换期间同时生效的联合共识的想法。 它允许群集在配置更改期间继续正常运行。
这个想法适用于CASPaxos的证据基于两个发现:
- 灵活的多数派(quorums):从前面我们可以观察到,基于paxos的系对“prepare”和“accept”的唯一要求就是它们之间的多数派存在交集。例如,在一个含有4个节点的集群中,在“prepare”阶段我们可能只需要得到2个确认,而在“accept”阶段需要3个确认(译者注:他们之间一定存在交集)。
- 网络等级原则:如果一个基于Paxos的系统的行为可以通过延迟或者删除一个节点间的消息进行改变,那么这个改变不会影响一致性,因为Paxos容忍这种干扰。只要可以在未修改的系统之上将变更设计成为一个消息过滤器,就可以自由更改系统。
2.3.1 扩容具有奇数个节点的集群
将acceptors集合从A(1)...A(2F +1)改变到A(1) ... A(2F +2)的算法如下:
1.上线A(2F+2) acceptor。
2.连接每一个proposer并更新其配置信息,并向A(1) ... A(2F +2) acceptors发送“accept”消息并要求获得F+2个确认。
3.任选一个proposer并执行一个身份状态变更函数x->x。
4.连接每一个proposer并更新它的配置信息,向A(1) ... A(2F +2) acceptors发送“prepare”消息并要求获得F+2个确认。
从2F + 1节点集群的角度来看,第二步可以用网络等价原则来解释,所以系统可以继续保持正确。当所有proposers都被修改后,系统也可以作为一个具有2F+2节点的集群,并要求“prepare”多数派为F+1和“accept”的多数派为F+2。
读取操作完成后,集群的状态变为F+2,因此我们可以忘记F+1的状态。 最后一步将系统从减的“prepare”多数派切换到常规。
以相反顺序执行的相同序列将缩容偶数集群。
2.3.2 扩容偶数个节点的集群
从A(1)...A(2F+2)到A(1)...A(2F+3)扩容协议更加直接,因为我们可以将2F+2节点集群看成2F+3节点集群,只是2F+3节点集群中一开始就有一台节点是下线状态的:
1.连接每一个prepare并更新其配置,向A(1)...A(2F+3) accepts发送prepare和accept消息。
2.上线A(2F+3) accept。
一个重要并需要注意的是,上述整个过程都是建立在第2F+3非节点一直处于下线状态的假设上的。如果一个集群从技术配置编程偶数配置,在扩容之前是必须执行身份状态转换的(re-scan),以避免状态丢失。
否则,可能会依次用空acceptor替换每个acceptor,这回丢失所有数据并违反线性化。
2.3.3 优化
一个kv存储引擎通常被实现成一些列独立的CASPaxos实例,我们需要为每一个实例(key)执行上面的三步。它会导致重新扫描所有记录。 如果存储器有K个键,则在A(1)···A(2F +1)到A(1)···A(2F +2)转换期间,重新扫描将移动K(2F + 3)个记录。
身份状态转换的目标是使群集的状态从F+2角度看上去是有效的。达到这种状态的另一种方式是在2步后的任何时刻复制大部分A1 ... A(2F +1)节点到A(2F +2),通过选择具有更高选票号码的接受值来解决冲突。 从而将重扫描(re-scan)成本从K(2F +3)降低到K(F +1)。
一个后台保持acceptors同步到最近时刻的追赶进程可以进一步将成本降低到(K-k)+k(F+1),其中k是自同步的最后时刻以来更新的键的数量。
2.3.4 变更proposers数目
由于算法的一致性和可用性不依赖于proposer的数量,因此可以随时添加和删除proposer。唯一需要注意的是像acceptors的扩容和缩容(3.1)过程,这些过程需要将所有proposers更新为其中一个步骤。 幸运的是,这些步骤是幂等的,所以我们可以提出一个proposer,更新所有proposer的列表,并在下一次尝试这些步骤成功。
删除proposer的算法:
1.关闭一个proposer。
2.更新GC进程中的proposers列表。
3.更新正在控制acceptors扩缩容进程的proposers列表。
添加一个proposer的算法:
1. 更新正在控制acceptors扩缩容进程的proposers列表。
2.更新GC进程中的proposers列表。
3.开启proposer。
3 基于CASPaxos的kv存储引擎
轻量的CASPaxos为设计复杂的分布式系统提供了一种新方法。在这一节,我们将讨论一个基于CASPaxos的kv存储引擎,并会和其他的原型(etcd,MongoDB等)作比较。
我们不会讲kv存储设计为一个单独的RSM,而是将其作为一组CASPaxos实例。Gryadka6是这个想法的设计原型。
3.1 如何删除一个记录
CASPaxos只支持更新操作,所以为了删除一个值客户端必须将寄存器更新为一个空值(tombstone,墓碑),这种做法的缺点就是空间的利用率:即使这个值是空的,系统也必须花费空间和资源来保持这个被删除寄存器的信息。
如果直接删除这些信息可能导致一些一致性问题,比如考虑下面acceptors状态:
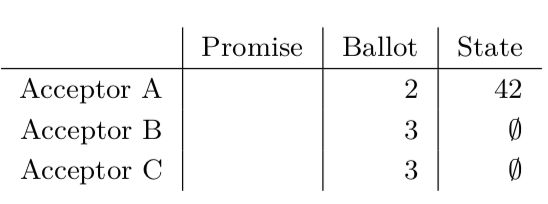
根据CASPaxos协议,一个读操作(被实现为一个x->x变更函数)应该返回∅。然而,如果我们移除相关寄存器的信息,此时一个读请求正好要读系统,然而此时acceptors B和C上的数据已经被删除了,因此我们将读到结果为42,这显然是去线性一致性。
将在删除之前写入空值的“accept”多数派增加到2F+1可以解决问题,但这会使得系统的可用性降低,因为有可能节点宕机时无法删除寄存器。
一个多步删除策略可以解决这个问题:
1. 在一个删除请求中,一个proposer写一个墓碑同时需要得到至少F+1个“accept”确认。启动一个垃圾收集并想客户端返回确认信息。
2. 垃圾收集器会做如下操作(后台运行):
a. 通过执行身份转换(identity transform)将空值(墓碑)复制到所有节点,并要求得到2F+1个确认。
b. 连接每一个proposer,失效他们的关于删除key的缓存(参看2.2.1),并将他们的counter直接增加到大于墓碑的ballot numbers,同时增加proposer的年代。
c. 连接每一个acceptor,要求他们拒绝来自proposers的任何信息如果它们的年代比上一步设置的年代小(译者注:就是如果acceptor年代没有proposer大就拒绝这个消息)。
d. 从每一个 acceptor删除包含墓碑的寄存器。
GC进程的每一步都是独立的,因此如果任何proposer或acceptor挂了进程会重新调度执行。
proposer的缓存失效和年代检查对于消除丢失的删除异常是必要的,当通道延迟的消息(或与缓存值相关的接受消息)恢复一个没有因果链接的消息时删除事件。
需要更新计数器以避免丢失的更新异常,这可能发生在同时更新的值的选票号码小于逻辑删除的选票号码时,并且读者将逻辑删除优先于新值。
为了使年代检查成为可能,proposers应该将他们的年代信息包括在他们发送的每条消息中,并且acceptors应该持久化每个由GC过程设置的proposer的年代(age)。
3.2 低延迟(略)
3.3 容错
EPaxos论文阐述了为什么基于leader的一致性协议在当leader发生crash或者网络分区时会导致集群不可用。
Multi-Paxos或者其他类似的变体,都依赖一个稳定的leader,leader的失效将导致系统无法处理客户端的请求直到一个新的leader被选出来。尽管客户端可以尝试直接请求其他的副本(在客户端超时之后),但是这个副本一般不会立刻就编程新leader。
CASPaxos并不会有这个问题,因为它的所有节点都是对等相同的角色,所以其中任何一个节点宕机或者被网络隔离,都不会影响其他节点继续对外提供服务。在leader被网络隔离期间,一个具有默认设置的分布式一致性数据库的实验研究支持这种先验推理 - 除Gryadka之外的所有系统都有一个非零的完整不可用窗口。

4 相关工作的比较(略)
5 结论
我们证明了CASPaxos是一个简单的RSM协议,因为没有leader所有没有可用性影响,并具有较高的磁盘并发操作和硬件利用率。
该协议比较适合kv存储引擎和基于状态响应的服务,如Microsoft Orleans。 我们工作的间接贡献是安全属性的证明,这也适用于Paxos的其他变体。
参考文献(略)