ELK+Filebeat+kafka+zookeeper集群架构的搭建(5.6.3)搭建日志平台
ELK+Filebeat+kafka+zookeeper集群架构的搭建(5.6.3)搭建日志分析平台
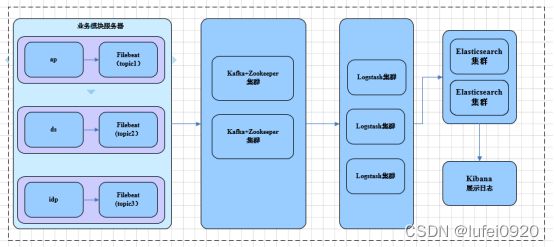
由于机器数量限制,logstash服务是在一台主机上进行搭建的,ELK日志收集系统的架构图
一、jdk的安装及配置
1、在logstash、elasticsearch、zookeeper、kafka等服务器上需要安装jdk,logstash对jdk的要求是1.8版本以上,下面为jdk下载链接:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2、下载好后,将jdk上传到服务器,通过rpm进行安装
rpm -ivh jdk-8u144-linux-x64.rpm
3、编辑profile文件,将java二进制程序添加到环境变量,刷新环境变量
vi /etc/profile
export PATH=/usr/java/jdk1.8.0_144/bin/:$PATH
source /etc/profile
二、zookeeper的安装及配置
1、下载zookeeper软件
软件包下载地址:https://archive.apache.org/dist/zookeeper/
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
2、将下载的zookeeper安装包解压到/usr/local目录下并改名为zookeeper
tar -xvf zookeeper-3.4.12.tar.gz -C /usr/local/
mv /usr/local/zookeeper-3.4.12 /usr/local/zookeeper
3、编辑/etc/profile文件,将zookeeper的执行脚本添加到环境变量里面
vim /etc/profile
export PATH=/usr/local/zookeeper/bin/:$PATH
4、刷新环境变量
source /etc/profile 或者. /etc/profile
5、zookeeper解压完成后可以先配置主机ip地址和主机名
编辑/etc/hosts文件,增加以下两条,使zk可以通过主机名进行解析,这是我的两台主机,注意你自己的主机ip地址和我不一定相同
![]()
6、编辑zookeeper的配置文件
编辑zookeeper的配置文件/usr/local/zookeeper/conf/zoo.cfg,默认有一个zoo_simple.cfg,可以直接讲它改名为zoo.cfg,然后进行如下配置

配置详解:
tickTime: 心跳基本时间单位,毫秒级,ZK基本上所有的时间都是这个时间的整数倍。
initLimit: 当非leader节点(即follower和observer)启动时,需要先从leader那里复制数据,以保证所有ZooKeeper节点数据都是同步的。这个选项设置非leader节点从启动到完成同步的超时时长,它以tickTime为时间单位,所以上面的超时时长为10*2=20秒
syncLimit: tickTime的个数,这时间容易和上面的时间混淆,它也表示follower和observer与leader交互时的最大等待时间,只不过是在与leader同步完毕之后,进入正常请求转发或ping等消息交互时的超时时间
dataDir: 内存数据库快照存放地址,如果没有指定(dataLogDir),默认也是存放在这个路径下,建议两个地址分开存放到不同的设备上。
dataLogDir: 将事务日志存储在该路径下,比较重要,这个日志存储的设备效率会影响ZK的写吞吐量
clientPort: 配置ZK监听客户端连接的端口
server.x=[hostname]:port_A:port_B: 该选项用来指定ZooKeeper集群中的服务器节点,其中:
x:整数。是zookeeper中服务器的一个简单标识。这个数值需要和dataDir下的myid文件内容一致。在启动zookeeper集群中的每个实例时,需要读取数据目录中的myid文件,并将该文件中的数值和配置文件中的server.x做匹配,匹配到哪个就表示是哪个zookeeper服务器节点。
hostname:zookeeper服务器节点的地址。
port_A:这是第一个端口,用于Follower和Leader之间的数据同步和其它通信。
port_B:这是第二个端口,用于Leader选举过程中投票通信。
7、创建数据及日志存储目录
mkdir /usr/local/zookeeper/{data,logs},修改属组信息chown -R zk.zk {data,logs}
有其他节点,则把文件同步到其他集群节点,在其他节点执行同样操作
scp zoo.cfg 192.168.1.175:/usr/local/zookeeper/conf/
8、创建myid,这是每个节点区分标志
在第一个节点执行:echo 1 > /usr/local/zookeeper/data/myid
在第二个节点执行:echo 2 > /usr/local/zookeeper/data/myid
9、启动zookeeper
zkServer.sh start 查看zookeeper状态:zkServer.sh status,成功即可!
三、kafka的安装及配置
1、kafka软件的安装及配置
kafka官网:https://archive.apache.org/dist/kafka/
wget https://archive.apache.org/dist/kafka/0.10.0.1/kafka_2.11-0.10.0.1.tgz
注意:kafka跟logstash配合有版本限制,我用的logstash是5.6.13版本,要求kafka的版本必须为0.10.0.1版本以上!
2、将软件包解压到/usr/local目录下,并改名为kafka
tar -xvf kafka_2.11-0.9.0.1.tgz -C /usr/local/
mv /usr/local/kafka_2.11-0.9.0.1 /usr/local/kafka
3、配置环境变量并使其生效
vim /etc/profile
export PATH=/usr/local/kafka/bin:$PATH
source /etc/profile
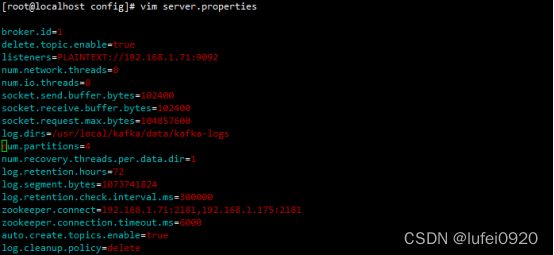
4、编辑kafka配置文件/usr/local/kafka/config/server.properties
如果在其他节点编辑该配置文件,注意修改以下两个属性的值
broker.id
listeners
这是第一个节点的配置
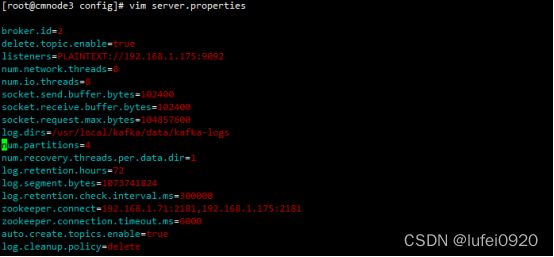
第二个节点的配置,主要是把broker.id和listeners监听ip改为自己的ip
Kafka配置详解:
broker.id: 每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况
delete.topic.enable: 设置为true的时候才允许直接删除kafka的topic
listeners:监听kafka的地址及端口
num.network.threads: broker处理消息的最大线程数,一般情况下数量为cpu核数
num.io.threads: broker处理磁盘IO的线程数,数值为cpu核数2倍
socket.send.buffer.bytes: socket的发送缓冲区,socket的调优参数SO_SNDBUFF
socket.receive.buffer.bytes: socket的接受缓冲区,socket的调优参数SO_RCVBUFF
socket.request.max.bytes: socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖
log.dirs: kafka数据的存放地址,多地址的话用逗号分割,多个目录分布在不同磁盘上可以提高读写性能 /data/kafka-logs-1,/data/kafka-logs-2
num.partitions: 每个topic的分区个数,若是在topic创建时候没有指定的话会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir: 在启动时恢复日志和关闭时刷盘日志时每个数据目录的线程的数量,默认1
log.retention.hours: 数据文件保留多长时间, 存储的最大时间超过这个时间会根据log.cleanup.policy设置数据清除策略
log.segment.bytes: topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖
log.retention.check.interval.ms: 文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略
zookeeper.connect: zookeeper集群的地址,可以是多个,多个之间用逗号分割
zookeeper.connection.timeout.ms: zooKeeper的连接超时时间
auto.create.topics.enable =true: 是否允许自动创建topic,若是false,就需要通过命令创建topic
log.cleanup.policy = delete: 日志清理策略选择有:delete和compact主要针对过期数据的处理,或是日志文件达到限制的额度,会被 topic创建时的指定参数覆盖
5、启动kafka服务
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
在另一个节点同样命令启动即可,至此,kafka+zookeeper集群搭建完毕
6、Kafka的操作
1)创建topic,这里创建了两个,以供后续使用
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic idsp-ap
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic vals-ap
2)查看已经创建的topic列表
kafka-topics.sh --list --zookeeper localhost:2181
3)查看topic的详细信息
kafka-topics.sh --describe --zookeeper localhost:2181 --topic idsp-ap
4)给kafka增加分区
kafka-topics.sh --zookeeper localhost:2181 --alter --topic idsp-ap --partitions 4
5)删除kafka的topic,需开启delete.topic.enable=true参数
kafka-topics.sh --delete --zookeeper localhost:2181 --topic idsp-ap
6)如果无法删除,可以去zookeeper中删除
zkCli.sh
ls /brokers/topics
rmr /brokers/topics/idsp-ap
四、filebeat的安装及配置
1、官网下载filebeat安装包:ELK官网:https://www.elastic.co/cn/
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.6.13-x86_64.rpm
直接rpm安装即可
rpm -ivh filebeat-5.6.13-x86_64.rpm
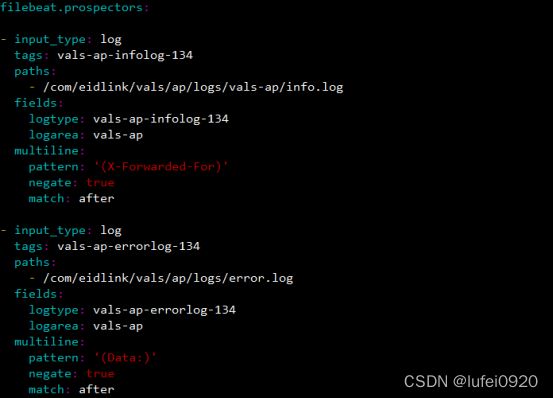
2、编辑配置文件filebeat.yml,rpm下载后配置文件默认路径在/etc/filebeat/目录下
读取的日志文件,下面为在vals-ap服务器上搭建的filebeat配置,这里只截取了两个日志的配置,其他类似,每增加一个日志,就有一个- input_type段来配置(注意冒号后面都有空格,否则filebeat会启动失败)
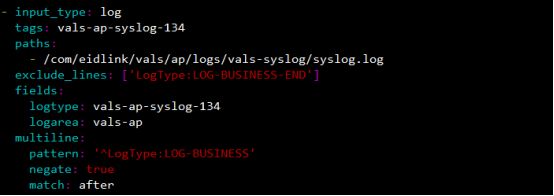
输出到 kafka的topic中
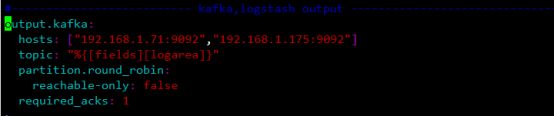
output.kafka中参数含义:
Hosts:kafka所在主机信息
Topic: 将日志存放到kafka的哪个topic里面,这里根据日志中的fields字段的logarea字段输出到相应的topic中
Partition.round_robin: kafka分发策略,表轮询
Reachable-only:false:
Required_acks: 1 :kafka的响应返回值,0位无等待响应返回,继续发送下一条消息;1表示等待本地提交(leader broker已经成功写入,但follower未写入),-1表示等待所有副本的提交,默认为1
max_message_bytes: 1000000 :超过1000byte的Event直接丢弃
3、启动服务:systemctl start filebeat即可
查看是否启动成功: systemctl status filebeat,如启动不成功,应该是语法有问题,重新检查一下配置文件是否有写错的地方即可
五、logstash的安装及配置
1、官网下载logstash安装包:https://artifacts.elastic.co/downloads/logstash/logstash-5.6.13.rpm
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.6.13.rpm
直接rpm安装:rpm -ivh logstash-5.6.13.rpm
2、配置环境变量并刷新环境变量
vim /etc/profile
export PATH=/usr/share/logstash/bin:$PATH
source /etc/profile
3、进入logstash配置文件目录/etc/logstash/conf.d/目录,编辑一个vals-ap.conf配置文件
Logstash主要由三个组件,输入input,过滤filter和输出output。注意,下面的logstash配置信息为下图中红色框框里的logstash集群。
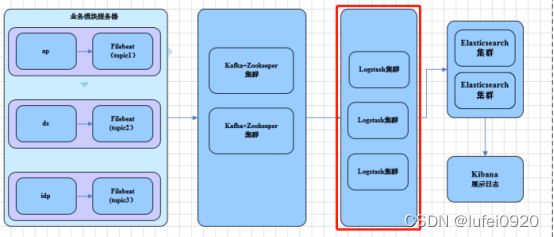
这里配置的从kafka端获取输入数据,输出端为elasticsearch端,具体配置如下,仅参考vals-ap,其他服务端日志都类似,这里在/etc/logstash/conf.d/all.conf文件,然后把所有的从kafka读出来的数据送到了elasticsearch集群中,这样logstash只启动一个all.conf即可,这里只截取了一部分,后面的依次把相应的topic输出到elasticsearch的配置都是重复的,只是注意有区别的地方即可,注释以vals-ap的案例为主
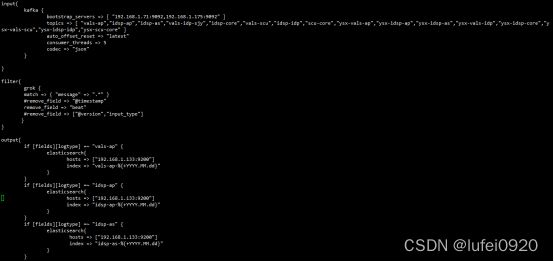
对上图的配置的注释:
输入端:
input{
kafka {
bootstrap_servers => [ "192.168.1.71:9092,192.168.1.175:9092" ] :kafka地址
topics => [ "vals-ap" ] :kafka的topic,这里就以vals-ap举例了
auto_offset_reset => "latest" : 自动从最新偏移量开始消费
consumer_threads => 5 :消费者线程数
codec => "json" :读取日志的格式
}
}
过滤:
filter{
grok { # 模块,处理message信息
match => { "message" => ".*" } :匹配的日志,.*表示全部匹配
remove_field => "beat" :移除不需要的字段
}
}
输出:
output{
if [fields][logtype] =~ "vals-ap" { :匹配logtype以vals-ap开头的日志
elasticsearch{
hosts => ["192.168.1.133:9200"] :输出到elasticsearch主机上
index => "vals-ap-%{+YYYY.MM.dd}" :输出到elasticsearch的vals-ap-日期index上
}
}
}
注释:上面的index上添加日期是为了后续要按日期删除日志做准备的,这样就可以根据日期删除多少天前的日志了
4、可以直接运行该配置文件,因为我们需要实时获取数据,所以可以将下面的命令放到后台执行:
nohup logstash -f /etc/logstash/conf.d/all.conf > /etc/logstash/all.out &
注意:如果想运行多个logstash实例,需要进行按如下命令执行
nohup logstash -f idsp-ap.conf --path.data=/var/lib/logstash/ap > ap.out &
每运行一个实例,都需要修改path.data的路径,否则会启动失败,运行完可以查看ap.out文件,看看启动信息,如失败请查看配置文件是否有误:tail -f ap.out
如果需要运行一个目录下的所有配置文件,可以按如下方式执行:
nohup logstash -f /etc/logstash/conf.d/ > ../all.out &
tail -f ../all.out 可以查看启动信息,看看是否启动成功
5、在下面这个文件里面可以看到logstash支持的kafka版本信息
/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-input-kafka-5.1.11/logstash-input-kafka.gemspec
六、elasticsearch的安装和配置
1、下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.13.rpm
下载:wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.13.rpm
安装:rpm -ivh elasticsearch-5.6.13.rpm
2、进入/etc/elasticsearch/目录下,编辑jvm.options配置文件,配置下面两项,表示使用内存情况,建议2g,根据服务器内存情况而定

3、编辑elasticsearch.yml配置文件
定义集群名,主机名,数据存储目录,日志存储目录,本机IP
下面discovery.zen.ping.unicast.hosts-->添加集群里面的所有主机IP
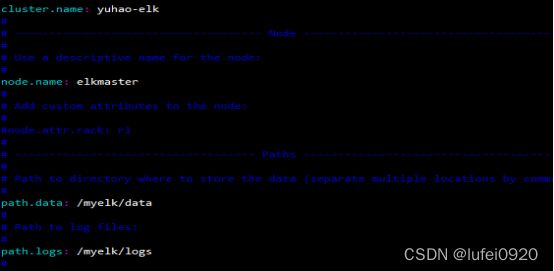
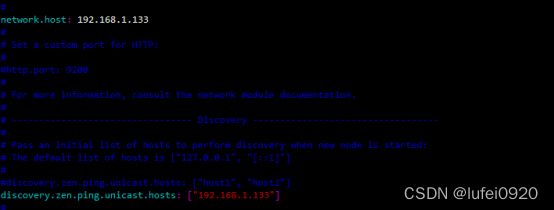
4、默认是没有/myelk/data和/myelk/logs目录的
手动创建/myelk/data和/myelk/logs,并把属主属组信息更改为elasticsearch
mkidr -p /myelk/{data,logs} 修改属主信息:chown -R elasticsearch.elasticsearch /myelk/*
5、启动elasticsearch并查看是否启动成功
systemctl start elasticsearch
systemctl status elasticsearch
curl -XGET http://192.168.1.133:9200/,出现以下信息则表示elasticsearch启动成功,至此elasticsearch配置成功
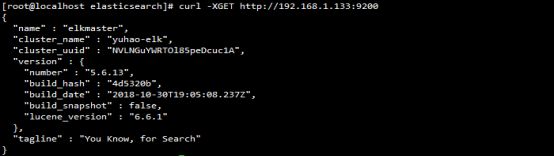
6、配置文件解释说明
01 masternode的elasticsearch.yml文件配置如下:
cluster.name: pancm
node.name: master
path.data: /home/elk/masternode/data
path.logs: /home/elk/masternode/logs
network.host: 0.0.0.0
network.publish_host: 192.169.0.23
transport.tcp.port: 9301 http.port: 9201 discovery.zen.ping.unicast.hosts: ["192.169.0.23:9301","192.169.0.24:9301","192.169.0.25:9301"] node.master: true node.data: false
node.ingest: false
index.number_of_shards: 5
index.number_of_replicas: 1 discovery.zen.minimum_master_nodes: 1 bootstrap.memory_lock: true
02 elasticsearch.yml文件参数配置说明:
cluster.name: 集群名称,同一集群的节点配置应该一致。es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
node.name: 该节点的名称。 path.data: 数据存放的路径。 path.logs: 日志存放的路径。
network.host: 设置ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
network.publish_host: 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
· transport.tcp.port:设置节点间交互的tcp端口,默认是9300。
· · http.port:设置对外服务的http端口,默认为9200。
· · discovery.zen.ping.unicast.hosts: 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
· · node.master: 指定该节点是否有资格被选举成为node,默认是true。 node.data: 指定该节点是否存储索引数据,默认为true。
· · node.ingest: 指定该节点是否使用管道,默认为true。
· · index.number_of_shards:设置默认索引分片个数,默认为5片。
· · index.number_of_replicas:设置默认索引副本个数,默认为1个副本。
· · discovery.zen.minimum_master_nodes: 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)。
· · bootstrap.memory_lock: 设置为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许elasticsearch的进程可以锁住内存,Linux下可以通过ulimit -l unlimited命令。 http.max_content_length: 设置内容的最大容量,默认100mb。 -...
03 这里在顺便说下ElasticSearch节点的属性。
node.master: true 并且 node.data: true
node.master: true 并且 node.data: true
这种组合表示这个节点即有成为主节点的资格,又存储数据。
如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。ElasticSearch默认每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,因为这样相当于主节点和数据节点的角色混合到一块了。
node.master: false 并且 node.data: true
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。 这个节点我们称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据,后期提供存储和查询服务
node.master: true 并且 node.data: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点,这个节点我们称为master节点。
node.master: false node.data: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,这个节点的意义是作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
node.ingest: true
node.ingest: true执行预处理管道,不负责数据和集群相关的事物。 它在索引之前预处理文档,拦截文档的bulk和index请求,然后加以转换。 将文档传回给bulk和index API,用户可以定义一个管道,指定一系列的预处理器。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/important-configuration-changes.html
04 数据节点配置:
datanode的elasticsearch.yml文件配置如下:
cluster.name: pancm
node.name: data1
path.data: /home/elk/datanode/data
path.logs: /home/elk/datanode/logs
network.host: 0.0.0.0
network.publish_host: 192.169.0.23
transport.tcp.port: 9300
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.169.0.23:9301","192.169.0.24:9301","192.169.0.25:9301"]
node.master: false
node.data: true
node.ingest: false
index.number_of_shards: 5
index.number_of_replicas: 1
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: true
http.max_content_length: 1024mb
七、kibana的安装及配置
1、kibana下载地址:https://artifacts.elastic.co/downloads/kibana/kibana-5.6.13-x86_64.rpm
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.6.13-x86_64.rpm
rpm -ivh kibana-5.6.13-x86_64.rpm
2、编辑配置文件/etc/kibana/kibana.yml配置文件
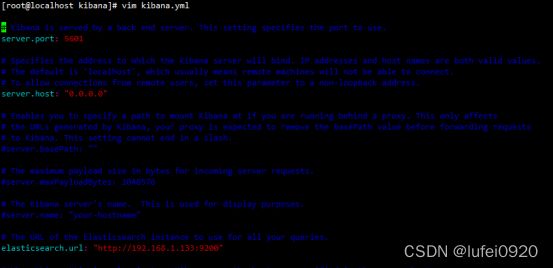
3、启动kibana服务,直接在浏览器访问该服务器的ip和端口即可成功
systemctl start kibana
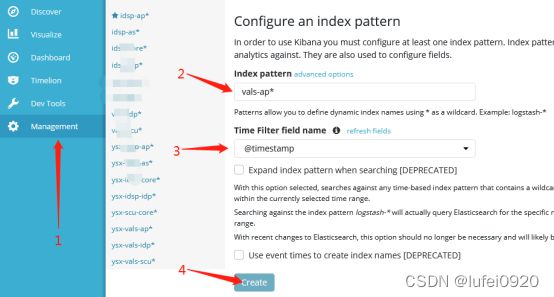
4、配置index pattern,
index就是刚刚在logstash中输出插件配置的index,我这里配置的是vals-ap,注意,有时候会不成功,这是因为你logstash还没有从kafka中读到数据传送给elasticsearch,只有你的日志在开启了logstash后有改变才会生效,可以自行添加测试数据到日志里面,然后去查看index是否生成,查看index可以通过如下方式
网址输入elasticsearch地址:192.168.1.133:9200/_cat/indices

登入kibana主页:192.168.1.133:5601
进入kibana管理页面,点击左侧Management按钮,然后点击Index Patterns按钮,点击左上角的Create Index Pattern按钮,配置index的索引值为vals-ap*,添加时间过滤插件,点击create创建即可,其他类型日志操作步骤类似
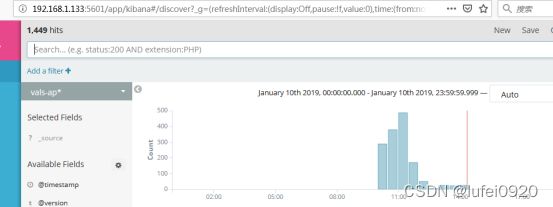
5、此时及可以在kibana网站界面上看到我们收集到的日志信息了
6、日志清理
由于日志文件每日的积累,最终 磁盘可能会撑满,所以我们这里做了个机制,日志只保留最近10天,我写了个删除前10天日志的脚本,根据elasticsearch上的index做删除操作

放到定时任务里面,每日凌晨1点执行
crontab -e
0 1 * * * /root/bin/rmelklog.sh > /dev/null 2>&1
更多参考资料请参看如下博客:
ELK+Filebeat+kafka+zookeeper日志分析平台: https://my.oschina.net/xuesong0204/blog/919760
使用logstash读取kafka中数据: https://blog.csdn.net/lvyuan1234/article/details/78653324
官网logstash详细文档:https://www.elastic.co/guide/en/logstash/current/index.html
官网filebeat详细文档:https://www.elastic.co/guide/en/beats/filebeat/current/index.html