一文理解Hadoop分布式存储和计算框架入门基础
文章目录
- 概述
-
- 定义
- 发展历史
- 发行版本
- 优势
- 生态项目
- 架构
-
- 组成模块
- HDFS架构
- YARN架构
- 部署
-
- 部署规划
- 前置条件
- 部署步骤
-
- 下载文件(三台都执行)
- 创建目录(三台都执行)
- 配置环境变量(三台都执行)
- 安装和配置(hadoop1上执行)
- 启动和停止Hadoop
- HDFS环境测试
- 计算和资源环境测试
概述
定义
Hadoop 官网地址 https://hadoop.apache.org/
Hadoop GitHub地址 https://github.com/apache/hadoop
Hadoop 文档地址 https://hadoop.apache.org/docs/stable/
Apache Hadoop是一个由 Apache 基金会所开发的分布式存储和计算的基础框架,使用简单的编程模型跨计算机集群分布式处理海量数据,也即是主要解决海量数据的存储和海量数据的分析计算问题。
Apache Hadoop可从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储,实现存储和计算高可用性;而从广义上来说, Hadoop 通常是指一个更广泛的概念 —— Hadoop 生态圈。
发展历史
- Hadoop 创始人 Doug Cutting ,为了实现与 Google 类似的全文搜索功能,他在 Lucene 框架基础上进行优化升级,查询引擎和索引引擎。
- 2001 年年底 Lucene 成为 Apache 基金会的一个子项目。
- 对于海量数据的场景, Lucene 框架面对与 Google 同样的困难, 存储海量数据困难,检索海量速度慢 。
- 学习和模仿 Google 解决这些问题的办法 :微型版 Nutch 。
- 可以说 Google 是 Hadoop 的思想之源( Google 在大数据方面的三篇论文,GFS —>HDFS、Map-Reduce —>MR、BigTable —>HBase)。
- 2003-2004 年, Google 公开了部分 GFS 和 MapReduce 思想的细节,以此为基础 Doug Cutting 等人用了 2 年业余时间 实现了 DFS 和 MapReduce 机制,使 Nutch 性能飙升。
- 2005 年 Hadoop 作为 Lucene 的子项目 Nutch 的一部分正式引入 Apache 基金会。
- 2006 年 3 月份, Map-Reduce 和 Nutch Distributed File System ( NDFS )分别被纳入到 Hadoop 项目中, Hadoop 就此正式诞生,标志着大数据时代来临。
- 名字来源于 Doug Cutting 儿子的玩具大象。
发行版本
Hadoop 发行版除了Apache的开源版本之外,还有华为发行版、Intel发行版、Cloudera发行版(CDH)、Hortonworks发行版(HDP)、MapR等,所有这些发行版均是基于Apache Hadoop衍生出来的。
- Apache Hadoop 原生版本,其优点完全开源免费,社区活跃,文档、资料详实。缺点复杂版本管理,复杂的集群部署、安装、配置,复杂的集群运维,复杂的生态环境兼容性和冲突,因此仅适用于以学习原理部署方式。
- Cloudera Hadoop(CDH):cloudera研发了cloudera manger、cdh大数据分析集成平台、cloudera Support;也是最成型的发行版本,拥有最多的部署案例;提供强大的部署、管理和监控工具;Cloudera开发并贡献了可实时处理大数据的Impala项目。
- Hortonworks Hadoop(HDP)hortonworks研发了Ambari和hdp的大数据分析集成平台。
- CDP:在Cloudera和Hortonworks合并后,Cloudera公司推出了新一代的数据平台产品CDP Data Center(以下简称为CDP).
- TDH:星环科技开发,是国内首个全面支持Spark的Hadoop发行版,也是国内落地案例最多的商业版本,是国内外领先的高性能平台。
- MapR:获取更好的性能和易用性而支持本地Unix文件系统而不是HDFS。
优势
- 高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
- 高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
- 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
- 高容错性:能够自动将失败的任务重新分配。
生态项目
- Ambari™:一个基于web的工具,用于配置、管理和监控Apache Hadoop集群,包括对Hadoop HDFS、Hadoop MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig和Sqoop的支持。Ambari还提供了一个仪表板,用于查看集群健康状况,如热图,以及可视化地查看MapReduce、Pig和Hive应用程序的能力,以及以用户友好的方式诊断它们的性能特征的功能。
- Avro™:数据序列化系统。
- Cassandra™:一个可扩展的多主数据库,没有单点故障。
- Chukwa™:用于管理大型分布式系统的数据收集系统。
- HBase™:一个可扩展的分布式数据库,支持对大型表的结构化数据存储。
- Hive™:一个数据仓库基础设施,提供数据汇总和特别查询。
- Mahout:一个可扩展的机器学习和数据挖掘库。
- Ozone™:一个可扩展的,冗余的,分布式的Hadoop对象存储。
- Pig™:用于并行计算的高级数据流语言和执行框架。
- Spark™:一个快速通用的Hadoop数据计算引擎。Spark提供了一个简单而富有表现力的编程模型,支持广泛的应用,包括ETL、机器学习、流处理和图计算。
- Submarine:一个统一的AI平台,可让工程师和数据科学家在分布式集群中运行机器学习和深度学习工作负载。
- Tez™:一个通用的数据流编程框架,建立在HadoopYARN之上,它提供了一个强大而灵活的引擎来执行任务的任意DAG,为批处理和交互用例处理数据。Tez正在被Hive™、Pig™和Hadoop生态系统中的其他框架以及其他商业软件(如ETL工具)所采用,以取代Hadoop™MapReduce作为底层执行引擎。
- ZooKeeper™:分布式应用的高性能协调服务。
架构
组成模块
- Hadoop Common:支持其他Hadoop模块的通用实用程序。
- Hadoop Distributed File System (HDFS™):提供对应用程序数据的高吞吐量访问的分布式文件系统。
- Hadoop YARN:一个用于任务调度和集群资源管理的框架。
- Hadoop MapReduce:基于yarn的大型数据集并行计算系统。
HDFS架构
Hadoop Distributed File System ,简称 HDFS ,是一个分布式文件系统;HDFS是一个主/从架构,HDFS集群由一个单一的NameNode组成,NameNode是一个主服务器,负责管理文件系统命名空间和规范客户端对文件的访问。此外,还有许多datanode,通常集群中的每个节点都有一个,它们管理连接到它们运行的节点上的存储。HDFS公开了一个文件系统命名空间,允许用户数据存储在文件中。在内部,一个文件被分割成一个或多个块,这些块存储在一组datanode中。NameNode执行文件系统命名空间操作,比如打开、关闭和重命名。简单的说就是NameNode就相当于一个目录一个索引,负责标记每一个DataNode的存放位置;而DataNode才是真正存放数据的。
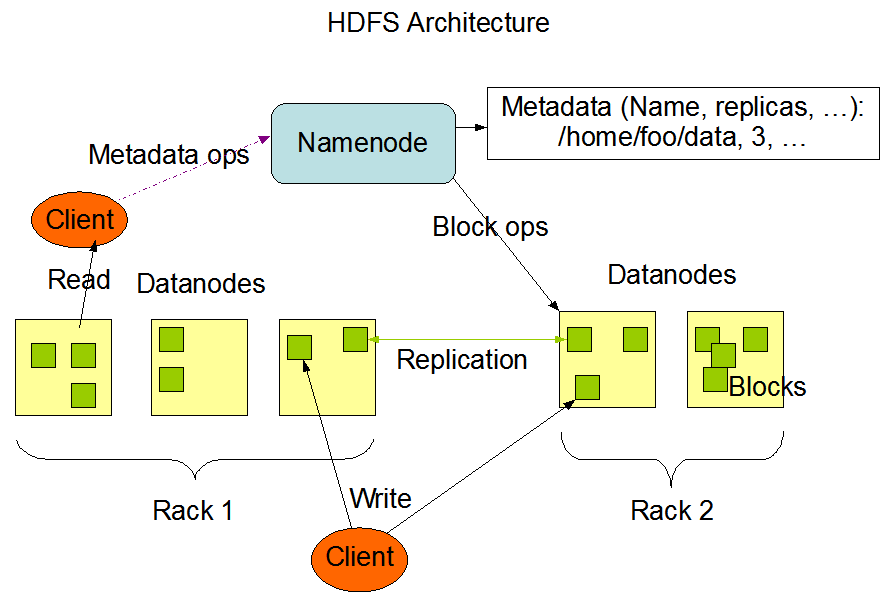
- 数据组织
- 数据块:HDFS设计成支持非常大的文件。兼容HDFS的应用程序是那些处理大型数据集的应用程序。这些应用程序只写入数据一次,但它们读取数据一次或多次,并且需要以流速度来满足这些读取。HDFS支持文件的write-once-read-many语义。HDFS使用的典型块大小是128 MB。因此一个HDFS文件被分割成128 MB的块,每个块将驻留在不同的DataNode上。
- 复制管道:当客户端将数据写入一个复制因子为3的HDFS文件时,NameNode会使用复制目标选择算法检索一个datanode列表。该列表包含将承载该块副本的datanode。然后客户端写入第一个DataNode。第一个DataNode开始接收部分数据,将每个部分写入本地存储库,并将该部分传输到列表中的第二个DataNode。第二个DataNode依次开始接收数据块的每个部分,将该部分写入其存储库,然后刷新该部分。最后,第三个DataNode将数据写入它的本地存储库。因此,DataNode可以从管道中的前一个接收数据,同时将数据转发给管道中的下一个。因此,数据通过流水线从一个DataNode传输到下一个DataNode。
- NameNode HA高可用配置
- With QJM(Quorum Journal Manager)
- With NFS
YARN架构
YARN的基本思想是将资源管理和作业调度/监视的功能拆分为独立的守护进程。包含一个全局的ResourceManager (RM)和每个应用的ApplicationMaster (AM),应用程序要么是单个作业要么是多个作业的DAG。
- ResourceManager和NodeManager组成了数据计算框架。ResourceManager是对系统中所有应用程序之间的资源进行仲裁的最终权力机构。NodeManager是每台机器的框架代理,负责容器,监控它们的资源使用情况(cpu、内存、磁盘、网络),并向ResourceManager/Scheduler报告相同的情况。
- 每个应用程序的ApplicationMaster的任务是与ResourceManager协商资源,并与NodeManager一起执行和监控任务。
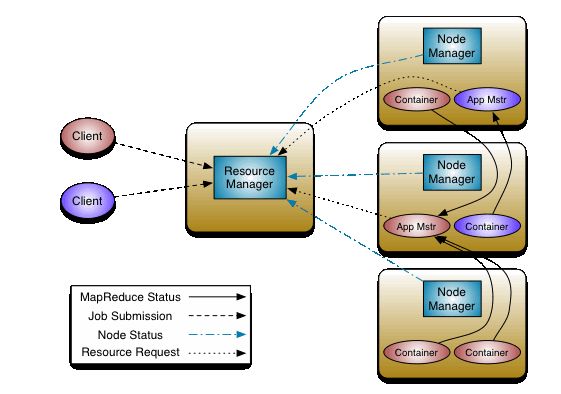
- 用户提交任务,任务给到ResourceManager。
- ResourceManager 会找一个节点NodeManager,开启一个Container ,把任务(App Mstr)放在Container。
- App Mstr会向 ResourceManager申请说自己需要多少资源 ResourceManager 看哪一个DataNode有资源,给他分配资源 。
- App Mstr 会在被分配的资源节点上开启计算任务(MapTask ),这个其实就是MapReduce 的map阶段,之后会返回一个Reduce到各自对应的节点。
部署
部署规划
本次使用Hadoop最新版本3.3.4部署3个节点的Hadoop分布式集群。
- DataNode:储存数据的节点,定时发送心跳包和数据块信息给NameNode。部署1个。
- NameNode:与DataNode交互信息进行监控和索引数据目录。一般是部署2个节点(主、备)。
- ZKFailoverController(ZKFC):主要是负责监控NameNode及选举。每个NameNode节点都会运行ZKFC服务。
- JournalNode:同步主备NameNode的数据。至少要部署3个节点,必须是奇数个(3、5、7、…),因为系统最多只能容忍 (n-1)/2 个JN节点失败而不影响正常运行。
- NodeManager:Yarn的节点状况监控服务。每台机都要部署。
- ResourceManager:Yarn管理集群资源调度的服务,与NodeManager交互信息进行调度管理。一般是部署2个节点(主、备,)。
前置条件
-
安装JDK8(本篇的服务器安装目录在/home/commons/jdk8)或者JDK11,目前新版本是支持JDK11
-
关闭主机防火墙
-
修改3个节点hosts表(/etc/hosts),配置三台服务器的IP对应的节点名称为hadoop1、hadoop2、hadoop3
-
配置SSH免密码通信,在三台上都执行如下操作,配置完成可以通过ssh命令任意一台无需输入密码则配置免密成功
- 输入命令 ssh-keygen -t rsa 然后连续按下三次回车然后输入命令
- ssh-copy-id hadoop1(master)按下回车后输入所对应的密码
- ssh-copy-id hadoop2(slave1)按下回车后输入所对应的密码
- ssh-copy-id hadoop3(slave2)按下回车后输入所对应的密码
-
安装Zookeeper集群(三台集群zk1、zk2、zk3,详细可查阅前面讲解Zookeeper文章)
部署步骤
下载文件(三台都执行)
# 在hadoop2上下载最新版的hadoop-3.3.4
cd /home/commons
# 其他两台可以使用scp命令拷贝hadoop-3.3.4.tar.gz如scp ./hadoop-3.3.4.tar.gz hadoop1:/home/commons/和scp ./hadoop-3.3.4.tar.gz hadoop3:/home/commons/
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
# 解压文件
tar xvf hadoop-3.3.4.tar.gz
# 重命名
mv hadoop-3.3.4 hadoop
创建目录(三台都执行)
mkdir -p /home/commons/hadoop
cd /home/commons/hadoop
mkdir hdfs tmp
cd hdfs
mkdir name data journal
配置环境变量(三台都执行)
vim ~/.bashrc
export HADOOP_HOME=/home/commons/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=/home/commons/hadoop
export HADOOP_HDFS_HOME=/home/commons/hadoop
export HADOOP_MAPRED_HOME=/home/commons/hadoop
export HADOOP_CONF_DIR=/home/commons/hadoop/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_HOME=/home/commons/hadoop
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
更新环境变量
source ~/.bashrc
安装和配置(hadoop1上执行)
cd /home/commons/hadoop/etc/hadoop
编辑 vim hadoop-env.sh ,添加以下内容
export JAVA_HOME=/home/commons/jdk8
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
编辑 vim yarn-env.sh
export JAVA_HOME=/home/commons/jdk8
编辑vim core-site.xml
fs.defaultFS
hdfs://myns/
hadoop.tmp.dir
/home/commons/hadoop/tmp
io.file.buffer.size
131072
ha.zookeeper.quorum
zk1:2181,zk2:2181,zk3:2181
ha.zookeeper.session-timeout.ms
1000
编辑vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///home/commons/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///home/commons/hadoop/hdfs/datavalue>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.nameservicesname>
<value>mynsvalue>
property>
<property>
<name>dfs.ha.namenodes.mynsname>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.myns.nn1name>
<value>hadoop1:9000value>
property>
<property>
<name>dfs.namenode.rpc-address.myns.nn2name>
<value>hadoop2:9000value>
property>
<property>
<name>dfs.namenode.http-address.myns.nn1name>
<value>hadoop1:50070value>
property>
<property>
<name>dfs.namenode.http-address.myns.nn2name>
<value>hadoop2:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mynsvalue>
<description>
JournalNode的配置
格式是qjournal://host1:port1;host2:port2;host3:port3/journalID
默认端口号是8485,journalID建议使用nameservice的名称
description>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/home/commons/hadoop/hdfs/journalvalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
<description>HDFS的故障自动转移服务description>
property>
<property>
<name>dfs.client.failover.proxy.provider.mynsname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
<description>客户端(client)通过该类获取active NameNodedescription>
property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.msname>
<value>60000value>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
<description>隔离机制(fencing),防止主备切换时同时存在2个master的情况description>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>~/.ssh/id_rsavalue>
<description>隔离机制(fencing)使用的远程控制密钥description>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration>
编辑vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobtracker.http.addressname>
<value>hadoop2:50030value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop2:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop2:19888value>
property>
<property>
<name>mapred.job.trackername>
<value>http://hadoop2:9001value>
property>
configuration>
编辑vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>myynvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>hadoop1value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>hadoop2value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>hadoop1:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>hadoop2:8088value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>zk1:2181,zk2:2181,zk3:2181value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
<description>
ResourceManger会将应用的状态信息保存到yarn.resourcemanager.store.class配置的存储介质中,
重启后会加载这些信息,并且NodeManger会将还在运行的container信息同步到ResourceManager。
description>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>86400value>
property>
<property>
<name>yarn.application.classpathname>
<value>
/home/commons/hadoop/etc/hadoop,
/home/commons/hadoop/share/hadoop/common/*,
/home/commons/hadoop/share/hadoop/common/lib/*,
/home/commons/hadoop/share/hadoop/hdfs/*,
/home/commons/hadoop/share/hadoop/hdfs/lib/*,
/home/commons/hadoop/share/hadoop/yarn/*,
/home/commons/hadoop/share/hadoop/yarn/lib/*,
/home/commons/hadoop/share/hadoop/mapreduce/*
value>
property>
configuration>
由于目前几台服务器配置较低,所以yarn调度默认配置不满足,死活起动不了job,提交后一直ACCEPTED。修改配置文件vim capacity-scheduler.xml
默认0.1修改的大些,我直接改到0.5,这一步不是必要,有资源问题可以修改
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percentname>
<value>0.5value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
description>
property>
配置vim workers
hadoop1
hadoop2
hadoop3
同步配置文件,拷贝到其它两台上
cd /home/commons/hadoop/etc/hadoop
scp * hadoop2:/home/commons/hadoop/etc/hadoop
scp * hadoop3:/home/commons/hadoop/etc/hadoop
启动和停止Hadoop
启动JournalNode
# 在hadoop1上启动
hdfs --workers --daemon start journalnode
格式化NameNode
hadoop namenode -format
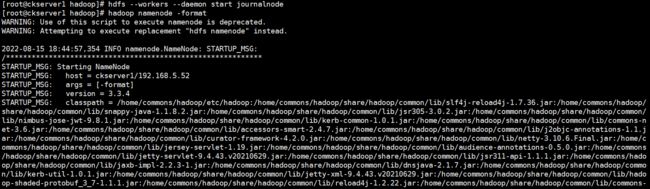
格式化后同步namenode的信息文件给hadoop2。因为有2个NameNode节点,hadoop1和hadoop2
scp -r /home/commons/hadoop/hdfs/name/current/ hadoop2:/home/commons/hadoop/hdfs/name/
格式化zkfc
zkfc = ZKFailoverController = ZooKeeper Failover Controller,zkfc用于监控NameNode状态信息,并进行自动切换。
启动HDFS和Yarn
# 下面这两步是最经常出现报错的,因此第一次先一步步单独启动
start-dfs.sh
start-yarn.sh
# 第1次部署时需要用上面的操作,后面启动可以直接用全部启动脚本
start-all.sh
hadoop1上查看进程
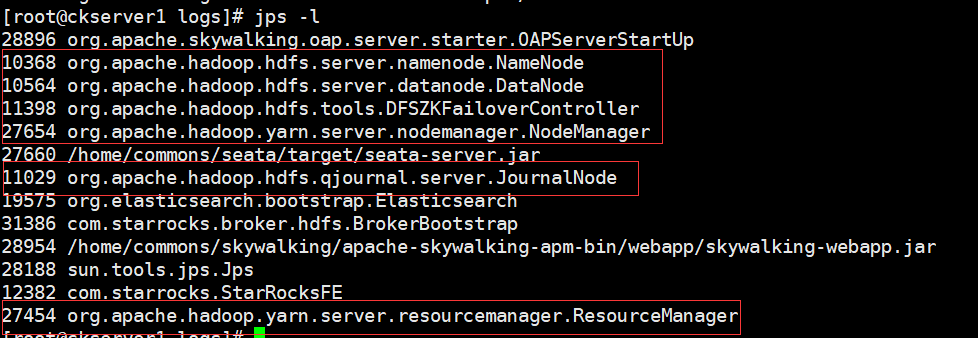
hadoop2上查看进程
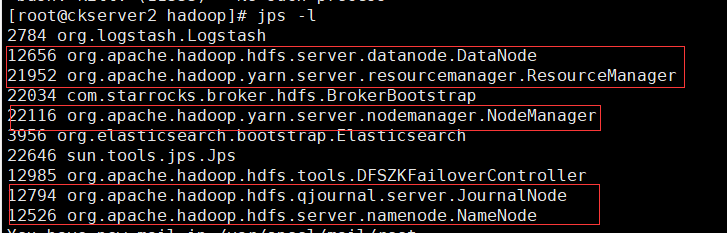
访问hadoop1 NameNode节点的HDFS的页面http://hadoop1:50070/
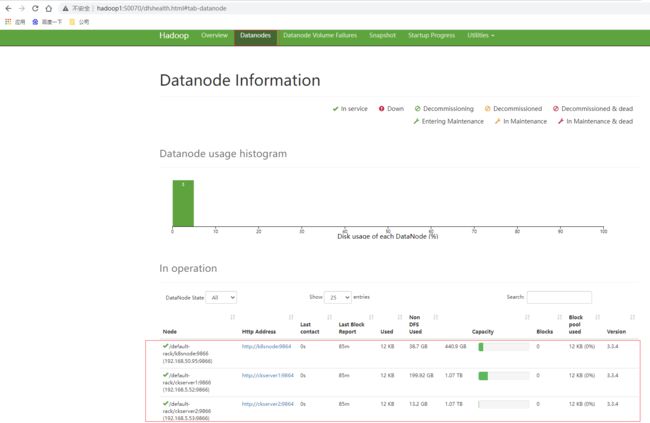
访问hadoop1 NameNode节点的HDFS的页面http://hadoop2:50070/
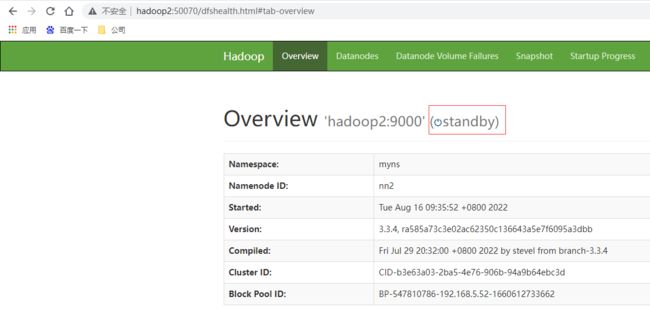
访问yarn的ResourceManager的管理页面http://hadoop2:8088/ ,访问http://hadoop1:8088/会跳转到hadoop2上
HDFS环境测试
# HDFS中创建文件
hadoop fs -mkdir /mytest
hadoop fs -ls /

查看页面浏览文件系统也可以看下创建的目录
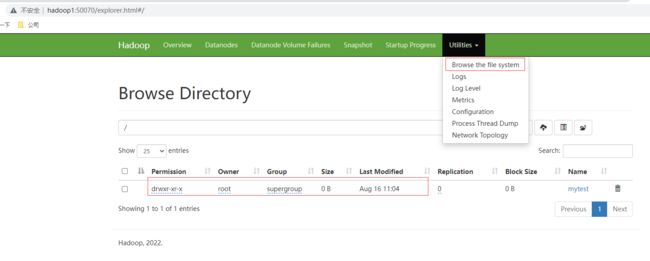
计算和资源环境测试
# 上传一个文件和创建输出目录
hadoop fs -put word.txt /mytest
hadoop fs -ls /mytest

# 执行wordcount计算
cd /home/commons/hadoop
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /mytest /output
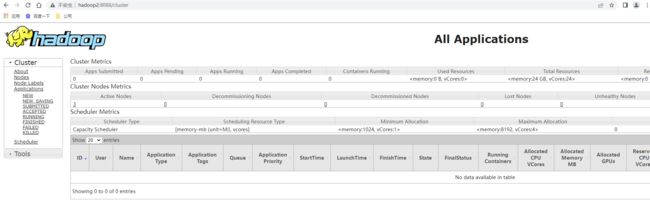
查看yarn的ResourceManager的管理页面http://hadoop2:8088/ ,可以看到提交任务已经跑完
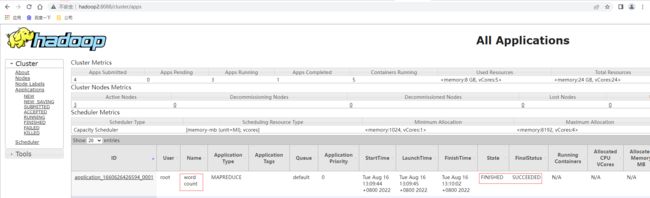
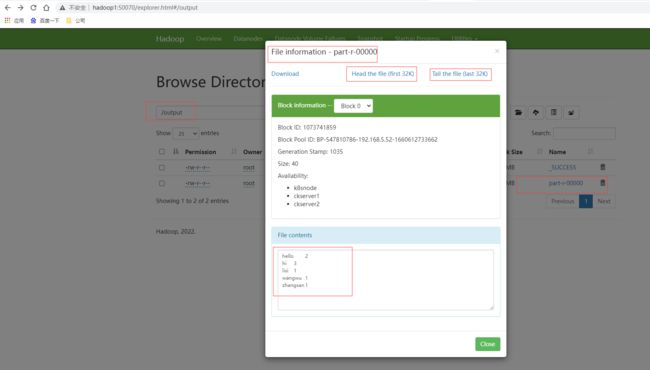
查看HDFS的页面http://hadoop2:50070/ ,查看到output目录有输出part-r-00000的文件,文件的内容为正确单词频次统计结果。
**本人博客网站 **IT小神 www.itxiaoshen.com