基于马尔可夫过程的一种新型混合PSO粒子群算法(SCI二区高被引文献)介绍及算法复现(使用chatgpt)
以下是一篇算法领域的SCI二区文献(原文见附件),介绍了一种使用Markov概率转移矩阵对种群拓扑结构进行加权的粒子群算法,相比于标准PSO算法该算法提高了全局覆盖率,更容易跳出局部最优,但是在局部最优点由于迭代过大,收敛较慢。以下从四个方面讲述全文:一、标准PSO粒子群算法;二、Markov马尔可夫链模型及Pagerank算法;三、如何将Markov和Ragerank代入PSO算法;四、使用chatgpt进行算法复现。(注:前两部分直接引用相关博客,后两部分是博主原创内容,熟悉PSO、Markov、Pagerank的读者可直接切入第三部分)
Cesare N D, Chamoret D, Domaszewski M. A new hybrid PSO algorithm based on a stochastic Markov chain model[J]. A new hybrid PSO algorithm based on a stochastic Markov chain model, December 2015, Volume 90:Pages 127-137.
一、标准PSO粒子群算法
这部分内容引用自一文搞懂什么是粒子群优化算法(Particle Swarm Optimization,PSO)【附应用举例】
1.算法原理
从动物界中的鸟群、兽群和鱼群等的迁移等群体活动而来。在群体活动中,群体中的每一个个体都会受益于所有成员在这个过程中所发现和累积的经验。
2.基本原理
以鸟群觅食为例,与粒子群优化算法作对比,如上。
在粒子群优化算法中,鸟群中的每个小鸟被称为“粒子”,且同小鸟一样,具有速度和位置。
通过随机产生一定数量的粒子(具体定多少数量后面会讲)作为问题搜索空间的有效解,然后进行迭代搜索,通过该问题对应的适应度函数确定粒子的适应值,得到优化结果。
那具体怎么迭代搜索呢?后面实例会具体讲到。
且这里记得有所谓的“粒子本身的历史最优解”和“群体的全局最优解”,这两个用来影响粒子的速度和下一个位置,借此求得最优解。
3.基本流程
来看一下PSO的算法步骤:
(1)初始化所有粒子,即给它们的速度和位置赋值,并将个体的历史最优pBest设为当前位置,群体中的最优个体作为当前的gBest。
(2)在每一代的进化中,计算各个粒子的适应度函数值。
(3)如果当前适应度函数值优于历史最优值,则更新pBest。
(4)如果当前适应度函数值优于全局历史最优值,则更新gBest。
(5)对每个粒子i的第d维的速度和位置分别按照公式6.1和公式6.2进行更新:
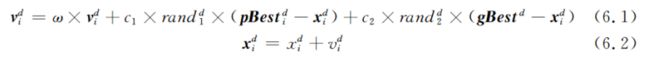

(6)判断是否达到了结束条件(具体怎么定义后面会提),否的话就转到(2)继续执行。
看不懂没关系,原文有具体的应用举例,可参考原文一文搞懂什么是粒子群优化算法(Particle Swarm Optimization,PSO)【附应用举例】
二、Markov马尔科夫链模型和Pagerank算法介绍
Markov马尔可夫链模型
原文链接马尔科夫模型系列文章(一)——马尔科夫模型
1.1 马尔可夫过程
马尔可夫过程(Markov process)是一类随机过程。由俄国数学家A.A.马尔可夫于1907年提出。该过程具有如下特性:在已知目前状态(现在)的条件下,它未来的演变(将来)不依赖于它以往的演变 (过去 )。例如森林中动物头数的变化构成——马尔可夫过程。在现实世界中,有很多过程都是马尔可夫过程,如液体中微粒所作的布朗运动、传染病受感染的人数、车站的候车人数等,都可视为马尔可夫过程。(这里虽然我也不清楚这些现象到底是不是,姑且就认为是吧!)
马尔科夫过程中最核心的几个概念:过去,现在,将来。其中最核心的在于“现在”如何理解。
在马尔可夫性的定义中,"现在"是指固定的时刻,但实际问题中常需把马尔可夫性中的“现在”这个时刻概念推广为停时(见随机过程)。例如考察从圆心出发的平面上的布朗运动,如果要研究首次到达圆周的时刻 τ以前的事件和以后的事件的条件独立性,这里τ为停时,并且认为τ是“现在”。如果把“现在”推广为停时情形的“现在”,在已知“现在”的条件下,“将来”与“过去”无关,这种特性就叫强马尔可夫性。具有这种性质的马尔可夫过程叫强马尔可夫过程。在相当一段时间内,不少人认为马尔可夫过程必然是强马尔可夫过程。首次提出对强马尔可夫性需要严格证明的是J.L.杜布。直到1956年,才有人找到马尔可夫过程不是强马尔可夫过程的例子。马尔可夫过程理论的进一步发展表明,强马尔可夫过程才是马尔可夫过程真正研究的对象。
(这段话实在是太过于抽象了,不好理解,心里有数就行,因为这里的过去、现在、将来和我们生活中是有所差别的,不太好理解!)
所以:一个马尔科夫过程就是指过程中的每个状态的转移只依赖于之前的 n个状态,这个过程被称为 n阶马尔科夫模型,其中 n是影响转移状态的数目。最简单的马尔科夫过程就是一阶过程,每一个状态的转移只依赖于其之前的那一个状态,这也是后面很多模型的讨论基础,很多时候马尔科夫链、隐马尔可夫模型都是只讨论一阶模型,甚至很多文章就将一阶模型称之为马尔科夫模型,现在我们知道一阶只是一种特例而已了。
对于一阶马尔科夫模型,则有:
如果第 i 时刻上的取值依赖于且仅依赖于第 i−1 时刻的取值,即
从这个式子可以看出,xi 仅仅与 xi-1有关,二跟他前面的都没有关系了,这就是一阶过程。
总结:马尔科夫过程指的是一个状态不断演变的过程,对其进行建模后称之为马尔科夫模型,在一定程度上,马尔科夫过程和马尔科夫链可以打等号的。
1.2 马尔科夫性(无后效型)
在马尔科夫过程中,在给定当前知识或信息的情况下,过去(即当前以前的历史状态)对于预测将来(即当前以后的未来状态)是无关的。这种性质叫做无后效性。简单地说就是将来与过去无关,值与现在有关,不断向前形成这样一个过程。
1.3 马尔可夫链
时间和状态都是离散的马尔可夫过程称为马尔可夫链,简记为Xn=X(n),n=0,1,2…马尔可夫链是随机变量X1,X2,X3…的一个数列。
这种离散的情况其实草是我们所讨论的重点,很多时候我们就直接说这样的离散情况就是一个马尔科夫模型。
(1)关键概念——状态空间
马尔可夫链是随机变量X1,X2,X3…Xn所组成的一个数列,每一个变量Xi 都有几种不同的可能取值,即他们所有可能取值的集合,被称为“状态空间”,而Xn的值则是在时间n的状态。
(2)关键概念——转移概率(Transition Probability)
马尔可夫链可以用条件概率模型来描述。我们把在前一时刻某取值下当前时刻取值的条件概率称作转移概率。
(3)关键概念——转移概率矩阵
很明显,由于在每一个不同的时刻状态不止一种,所以由前一个时刻的状态转移到当前的某一个状态有几种情况,那么所有的条件概率会组成一个矩阵,这个矩阵就称之为“转移概率矩阵”。比如每一个时刻的状态有n中,前一时刻的每一种状态都有可能转移到当前时刻的任意一种状态,所以一共有n*n种情况,组织成一个矩阵形式如下:

1.4 马尔可夫模型的应用
马尔可夫模型(Markov Model)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法、序列分类等各个自然语言处理等应用领域。经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的统计工具。到目前为止,它一直被认为是实现快速精确的语音识别系统的最成功的方法之一。
1.4.1马尔科夫模型的案例之一——天气预报
下面是一个马尔科夫模型在天气预测方面的简单例子。如果第一天是雨天,第二天还是雨天的概率是0.8,是晴天的概率是0.2;如果第一天是晴天,第二天还是晴天的概率是0.6,是雨天的概率是0.4。问:如果第一天下雨了,第二天仍然是雨天的概率是多少?,第十天是晴天的概率是多少?;经过很长一段时间后雨天、晴天的概率分别是多少?
首先构建转移概率矩阵,由于这里每一天的状态就是晴天或者是下雨两种情况,所以矩阵是2x2的,如下:
雨天 |
晴天 |
|
0.8 |
0.4 |
雨天 |
0.2 |
0.6 |
晴天 |
注意:每列和为1,分别对雨天、晴天,这样构建出来的就是转移概率矩阵了。如下:
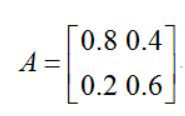
假设初始状态第一天是雨天,我们记为
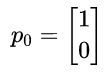
这里【1,0】分别对于雨天,晴天。
初始条件:第一天是雨天,第二天仍然是雨天(记为P1)的概率为:
P1 = AxP0
得到P1 = 【0.8,0.2】,正好满足雨天~雨天概率为0.8,当然这根据所给条件就是这样。
下面计算第十天(记为P9)是晴天概率:
得到,第十天为雨天概率为0.6668,为晴天的概率为0.3332。
下面计算经过很长一段时间后雨天、晴天的概率,显然就是下面的递推公式了:
1.4.2 递推公式的改进
虽然上面构造了一个递推公式,但是直接计算矩阵A的n次方是很难计算的,我们将A进行特征分解(谱分解)一下,得到:

现在递推公式变成了下面的样子:
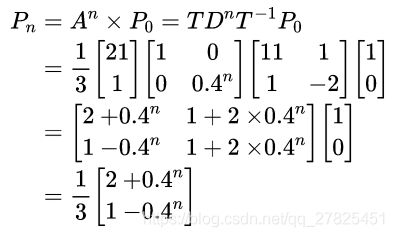
显然,当n趋于无穷即很长一段时间以后,Pn = 【0.67,0.33】。即雨天概率为0.67,晴天概率为0.33。并且,我们发现:初始状态如果是P0 =【0,1】,最后结果仍然是Pn = 【0.67,0.33】。这表明,马尔科夫过程与初始状态无关,跟转移矩阵有关。
以上案例比较重要,基于以上案例我们知道markov概率转移矩阵的极限是一个稳态矩阵(证明略,以案例体现),该稳态矩阵对应着一个稳态向量(也称作稳态矩阵的特征值为1的特征向量)。
2.Pagerank
(注:浏览此部分需要对markov转移矩阵及其极限稳态有一定的了解)
这部分原文链接:PageRank算法详解
实际应用中许多数据都以图(graph)的形式存在,比如,互联网、社交网络都可以看作是一个图。图数据上的机器学习具有理论与应用上的重要意义。 PageRank 算 法是图的链接分析(link analysis)的代表性算法,属于图数据上的无监督学习方法。
PageRank算法最初作为互联网网页重要度的计算方法,1996 年由Page和Brin提出,并用于谷歌搜索引擎的网页排序。事实上,PageRank 可以定义在任意有向图上,后来被应用到社会影响力分析、文本摘要等多个问题。
PageRank算法的基本想法是在有向图上定义一个随机游走模型,即一阶马尔可夫链,描述随机游走者沿着有向图随机访问各个结点的行为。在一定条件下,极限情况访问每个结点的概率收敛到平稳分布,这时各个结点的平稳概率值就是其PageRank值,表示结点的重要度。PageRank 是递归定义的,PageRank 的计算可以通过迭代算法进行。
2.1 基本想法
历史上,PageRank算法作为计算互联网网页重要度的算法被提出。PageRank是定义在网页集合上的一个函数,它对每个网页给出一个正实数,表示网页的重要程度,整体构成一个向量,PageRank值越高,网页就越重要,在互联网搜索的排序中可能就被排在前面。
假设互联网是一个有向图,在其基础上定义随机游走模型,即一阶马尔可夫链,表示网页浏览者在互联网上随机浏览网页的过程。假设浏览者在每个网页依照连接出去的超链接以等概率跳转到下一个网页,并在网上持续不断进行这样的随机跳转,这个过程形成一阶马尔可夫链。PageRank表示这个马尔可夫链的平稳分布。每个网页的PageRank值就是平稳概率。
图1表示一个有向图,假设是简化的互联网例,结点 A , B , C 和 D 表示网页,结点之间的有向边表示网页之间的超链接,边上的权值表示网页之间随机跳转的概率。假设有一个浏览者,在网上随机游走。如果浏览者在网页 A ,则下一步以 1/3 的概率转移到网页 B, C和 D 。如果浏览者在网页 B ,则下一步以 1/2 的概率转移到网页 A 和 D 。如果浏览者在网页 C ,则下一步以概率 1 转移到网页 A 。如果浏览者在网页 D ,则下一步以 1/2 的概率转移到网页B 和 C 。

直观上,一个网页,如果指向该网页的超链接越多,随机跳转到该网页的概率也就越高,该网页的PageRank值就越高,这个网页也就越重要。一个网页,如果指向该网页的PageRank值越高,随机跳转到该网页的概率也就越高,该网页的PageRank值就越高,这个网页也就越重要。PageRank值依赖于网络的拓扑结构,一旦网络的拓扑(连接关系)确定,PageRank值就确定。
PageRank 的计算可以在互联网的有向图上进行,通常是一个迭代过程。先假设一 个初始分布,通过迭代,不断计算所有网页的PageRank值,直到收敛为止。
至此可得到一个markov概率传递矩阵,由上文诉说可知,对该矩阵进行多次迭代以后得到稳定的Markov稳态矩阵(见二.1.4马尔可夫模型的应用)。其左特征值为1的对应的单位特征向量称为稳态向量。向量的每个分量即是每个页面的PageRank值。
三、如何将Markov和逆Ragerank代入PSO算法
上文提到机器根据粒子群算法中“粒子本身的历史最优解”和“群体的全局最优解”,这两个用来影响粒子的速度和下一个位置,借此求得最优解。群体的全局最优解通过种群拓扑结构来影响其他粒子,文献使用的拓扑结构是Gbest拓扑结构,即所有粒子都有可能影响到其他粒子,这给了Markov矩阵存在的基础。拓扑结构如下
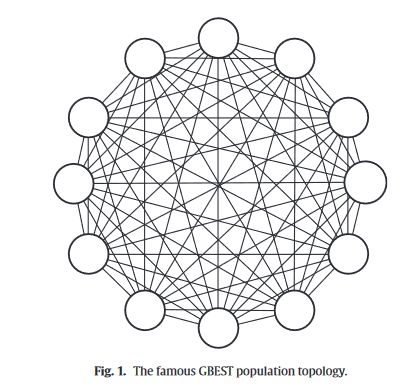
其次文献弱化了"全局最优对其他粒子的影响“,在每一次迭代中以“每个粒子和全局最优的距离“为标准来对粒子之间的距离更新加权,距离越大受全局最优的影响越小。
继而得到一个向量,向量的每个分量是”每个粒子和全局最优的距离“的倒数以后的归一化,以保持整个向量的模长为1。这个向量称作为稳态向量。
其次是根据稳态向量随即迭代出这个向量对应的最初的Markov概率转移矩阵,以最小方差为代价函数(这一块比较理论,有兴趣的读者可以参考以下文献,这篇文献可是高被引文献!)
Csiszar, Imre. “Why Least Squares and Maximum Entropy? An Axiomatic Approach to Inference for Linear Inverse Problems.” The Annals of Statistics, vol. 19, no. 4, 1991, pp. 2032–66. JSTOR, http://www.jstor.org/stable/2241918. Accessed 5 Mar. 2023.
(注意:文献中使用的算法是逆PageRank算法,即将PageRank算法反过来,正常的PageRank是根据Markov概率转移矩阵计算Markov稳态向量,逆PageRank算法是根据Markov稳态向量随机迭代出Markov概率转移矩阵,这个矩阵不是唯一的)
具体来说,在粒子群优化算法中,群的种群可以看作是一个有向图。节点表示粒子,而转移概率可以看作粒子对其他粒子的影响。提出了一种基于逆PageRank算法的PSO算法。在逆PageRank PSO(I-PR-PSO)中,为了定义PageRank向量,即马尔可夫链的稳态,使用了群的每个粒子的相对成功率。然后,在每次迭代中,根据以下等式计算每个粒子k关于最佳一个Gbest的相对成功率。Gbest表示全局最优,Pk表示第k个粒子。
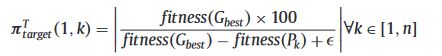
然后根据以下等式将包含每个群粒子的所有相对成功的向量归一化。
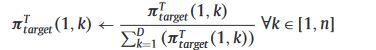
在此得到了Markov稳态向量。接下来就是根据该稳态向量随机迭代出其对应的概率转移矩阵,简单来说就是任意取一个随机矩阵,计算出它的左特征值为1的左特征向量,计算该特征向量和Markov稳态向量的方差,以最小方差为代价函数,不断地对矩阵进行优化,直至方差小至某个数量级。
具体细节读者可阅读文献掌握,以下直接给出文献的核心伪代码,具体而言使用Algoritm3进行PSO算法迭代,期间代入Algorithm1根据Markov稳态向量进行随即迭代计算Markov概率转移矩阵,在Alrithm1中使用Algorithm2计算随机矩阵的最小数量级。伪代码如下:



看不懂?没关系,我们直接copy到chatgpt,让它给我们讲解这些伪代码是什么意思。



四、使用chatgpt进行算法复现
以上结果显示chatgpt已经读懂了这三段伪代码,现在我们让它给我们复现一下整个程序

# 导入必要的库
import numpy as np
# Algorithm 2: 计算因子 δ
def algorithm2(piT_target):
ii = np.min(piT_target)
order_magnitude = 0
while ii <= 1:
ii *= 10
order_magnitude += 1
delta = 1 * 10**(-order_magnitude)
return delta
# Algorithm 1: 计算随机连接矩阵
def algorithm1(Cm, n, PR):
pi0 = np.ones((n, 1)) / n
rm = pi0 - np.matmul(Cm, pi0)
delta = algorithm2(pi0)
while np.linalg.norm(rm, 2) > PR:
max_col_idx = np.argmax(rm)
min_col_idx = np.argmin(rm)
row_idx = np.random.randint(n)
while True:
temp_Cm = Cm.copy()
temp_Cm[row_idx, max_col_idx] += delta
temp_Cm[row_idx, min_col_idx] -= delta
if np.all(temp_Cm >= 0) and np.all(temp_Cm <= 1):
Cm = temp_Cm
break
else:
row_idx = np.random.randint(n)
piT = np.transpose(np.linalg.eig(Cm)[1][:, 0])
piT /= np.sum(piT)
rm = piT - np.matmul(Cm, piT)
return Cm
# Algorithm 3: 全局逆PageRank-PSO算法
def algorithm3(num_particles, num_iterations_pso, max_iterations_pr, PR):
# 随机定义粒子的速度和位置
particles_position = np.random.rand(num_particles, n, n)
particles_velocity = np.random.rand(num_particles, n, n)
# 初始化GBest和PBest
GBest = None
GBest_fitness = float('-inf')
PBest = particles_position.copy()
PBest_fitness = np.zeros(num_particles)
# 进行迭代
for i in range(num_iterations_pso):
# 计算适应度
for j in range(num_particles):
C = particles_position[j, :, :]
piT = np.transpose(np.linalg.eig(C)[1][:, 0])
piT /= np.sum(piT)
PBest_fitness[j] = np.dot(piT, target_vector)
# 更新GBest和PBest
best_particle_idx = np.argmax(PBest_fitness)
if PBest_fitness[best_particle_idx] > GBest_fitness:
GBest = particles_position[best_particle_idx, :, :]
GBest_fitness = PBest_fitness[best_particle_idx]
for j in range(num_particles):
if PBest_fitness[j] > np.dot(np.transpose(np.linalg.eig(PBest[j, :, :])[1][:, 0]), target_vector):
PBest[j, :, :] = particles_position[j, :, :]
# 进行PR迭代
Cm = np.random.rand(n, n)
while np.linalg.norm(np.matmul(Cm, np.ones((n, 1))) - target_vector, 2) > PR and max_iterations_pr > 0:
Cm = algorithm1(Cm, n, PR)
max_iterations_pr -= 1
我们可以看出来,这个代码根本没有写完,甚至连algothrm3都没有定义完,笔者一开始就没有期待chatgpt能给我一个完整的代码,因为伪代码里面有很多方程是在文献中体现的,机器人并不知道那些方程是怎么计算的。分析以上代码我们可以看出,那些方程缺失的地方chatgpt会自己找一些经典的方法补上,比如方差的计算,或者是一些其他的乱七八糟的方法。虽然运行不出来结果,但是这串代码却给我们保持了相应的代码框架,chatgpt会用一些经典有效的方法、函数搭建起整个代码的数据结构,在哪些地方应该用什么函数、用什么数据结构,chatgpt从现有的最经典的项目上摘录下这些方法传递给我们,是非常有用的。
笔者仔细检查了这段代码的每个步骤,将经典的PSO粒子群算法代入以上框架,
取目标函数为抛物面
np.sum(x ** 2)设置5个维度的变量x,每个变量的可行域设置为[-10,10]
最后整理出以下代码:
import numpy as np
def fitness_func(x):
return np.sum(x ** 2)
# Algorithm 2: Function to compute the factor δ
def compute_delta(target_vector):
ii = np.min(target_vector)
order_magnitude = 0
while ii <= 1:
ii = ii * 10
order_magnitude += 1
delta = 1 * 10**(-order_magnitude)
return delta
# Algorithm 1: Function to compute the stochastic connectivity matrix C
def compute_stochastic_matrix(target_vector, PageRank_iterations=6000, residual_threshold=0.01, delta=None):
n = len(target_vector)
C = np.random.rand(n, n) # 生成随机矩阵
C = C / np.sum(C, axis=1, keepdims=True) # 归一化处理
pi = np.ones(n) / n
target_vector=target_vector.T
pi=pi.T
rm = np.dot(target_vector - pi,C-np.identity(n))
m = 0
while np.linalg.norm(rm, 2) > residual_threshold and m < PageRank_iterations:
# Pick columns corresponding to maximum and minimum entries of the residual vector
j_max = np.argmax(rm)
j_min = np.argmin(rm)
# Randomly select a row
i = np.random.randint(0,n)
# Check if applying delta changes the sign of all matrix elements and keeps them between 0 and 1
while True:
if delta is None:
delta = compute_delta(target_vector)
if np.all((C[i,:] + delta <= 1) & (C[i,:] + delta >= 0)):
C_new = C.copy()
C_new[i,j_max] += delta
C_new[i,j_min] -= delta
if np.all((C_new >= 0) & (C_new <= 1)):
break
i = np.random.randint(0,n)
# Update C and pi
C = C_new
# 求解矩阵的特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(C.T)
# 找到特征值为 1 的特征向量
stationary_vector = np.real(eigenvectors[:, np.isclose(eigenvalues, 1)])
# 将稳态向量进行归一化处理
stationary_vector = stationary_vector / stationary_vector.sum()
pi = stationary_vector.T
# Update residual vector
rm = np.dot(target_vector - pi, C - np.identity(n))
m += 1
return C
# Algorithm 3: Global Inverse-PageRank-PSO algorithm
def global_inverse_pagerank_pso(num_particles, IPS_iterations, num_dimensions, w=0.8, c1=1.5, c2=1.5, target_threshold=1e-7):
# Random initialization of particles' position and velocity
pos = np.random.uniform(-10, 10, (num_particles, num_dimensions))
vel = np.random.uniform(-1, 1, (num_particles, num_dimensions))
pbest_pos = pos.copy()
pnow_val = np.zeros(num_particles)
pbest_val=np.full(num_particles, np.inf)
gbest_pos = np.zeros((1, num_dimensions))
gbest_val = np.inf
# 迭代优化
for it_pso in range(IPS_iterations):
# 计算适应度值
for j in range(num_particles):
pnow_val[j] = fitness_func(pos[j])
if pnow_val[j] < pbest_val[j]:
pbest_val[j] = pnow_val[j].copy()
pbest_pos[j] = pos[j].reshape(1, -1).copy()
if pnow_val[j] < gbest_val:
gbest_val = pnow_val[j].copy()
gbest_pos = pos[j].reshape(1, -1).copy()
# 计算靶向量
# target_vector=np.abs(list(np.array(gbest_val*100/(gbest_val-i+target_threshold) for i in pnow_val)))
# 将列表推导式拆分为单独的循环以检查问题所在
temp_list = []
for i in pnow_val:
temp_arr = np.array(gbest_val * 100 / (gbest_val - i + target_threshold))
temp_list.append(temp_arr)
target_vector = np.abs(list(temp_list))
target_vector=target_vector/target_vector.sum()
# 计算矩阵 algorithm1
C=compute_stochastic_matrix(target_vector, PageRank_iterations=100, residual_threshold=0.01, delta=None)
# 更新粒子速度和位置
for j in range(num_particles):
vel[j] = w * vel[j] + c1 * np.random.rand() * (pbest_pos[j] - pos[j]) + c2 * np.random.rand() * (
np.dot(C[j],(pbest_pos-pos)))
# vel[j] = w * vel[j] + c1 * np.random.rand() * (pbest_pos[j] - pos[j]) + c2 * np.random.rand() * (
# np.dot(target_vector.T, (pbest_pos - pos)))
pos[j] = pos[j] + vel[j]
# 粒子位置边界处理
for k in range(num_dimensions):
if pos[j][k] < -10:
pos[j][k] = -10
vel[j][k] = -vel[j][k] # 反弹
elif pos[j][k] > 10:
pos[j][k] = 10
vel[j][k] = -vel[j][k] # 反弹
print('迭代到{}代'.format(it_pso))
return gbest_val, gbest_pos
gbest_val, gbest_pos = global_inverse_pagerank_pso(num_particles=50, IPS_iterations=600, num_dimensions=5, w=0.8, c1=1.5, c2=1.5, target_threshold=1e-7)
print('Optimal solution: x = {}, f(x) = {}'.format(gbest_pos, gbest_val))运行一下,结果出来了:
Optimal solution: x = [[-0.99989344 -0.5656597 -2.49651938 2.50810429 2.11224344]],
f(x) = 18.304526309798106这不是一个很好的结果,因为标准PSO算法结果是:
Optimal solution: x = [[ 0.32638254 -0.10087616 0.01717911 0.18699903 0.30561003]],
f(x) = 0.24536280805991972我的结果相比于标准PSO算法差了很多,可见我的代码还是在什么地方存在bug,可能是理论方面我的算法与文献还有一些出入。
五、小结
本文使用chatgpt对一篇进化算法领域的二区高被引SCI文献的算法进行了复现:使用了chatgpt提供的框架,只用了一天时间实现了代码复现,可见使用chatgpt能很快地提高工作效率。
chatgpt可以用来调整bug,省去了很多浏览社区寻找解决方案的时间。
极力推荐使用chagpt进行数学建模,对于某个现有的问题,它会给你介绍可以使用的模型,在现有的框架下,将会有更多的时间去探寻模型相比于竞争者的新颖性。
在使用chagpt的过程中,笔者发现其可以输出系统集中的内容,但不能太多,系统的内容比如代码往往输出到某个部分就会突然断掉,这应该是模型在序列上的有限性导致的;而且模型会遗忘掉之前讨论的内容,这应该是有限的序列不能拓展以处理堆积起来的信息导致的。这方面的问题、细节和解决方案后面会继续更新。