服务的边界职责
大数据层取数统一实现入口(数据源的路由,ADB/CK/HBASE... 大数据操作层数据源的路由)
支持多实例、多库、多表的异构数据查询
通过 查询 语义分析+元信息解析,拆解 查询输入 中的异构数据源处理,所有异构数据处理采用异步 Callback 方式
解决的问题
多个数据来源写入到不同实例、不同库中,并且一个圈选可以支持圈多个实例(不同库)中的标签、事件数据
单表数据量过大,目前只能通过压缩保留时间解决,需要可以进行按时间段拆表分表查询数据
单实例配置上限问题,实例升级配置是有上限的成本也很高,支持多实例后就可以使用多实例中等配置无限扩展
无法支持场景
同一个圈选不支持跨不同类型数据库混用,类似一个圈选包含了ADB+CK两种类型数据库的配置
创建库表的时候,需要有原则:
不同实例的库、表名字如果完全一样,默认他们代表的业务语意也是一致的,如果不一致会出现问题
场景描述:

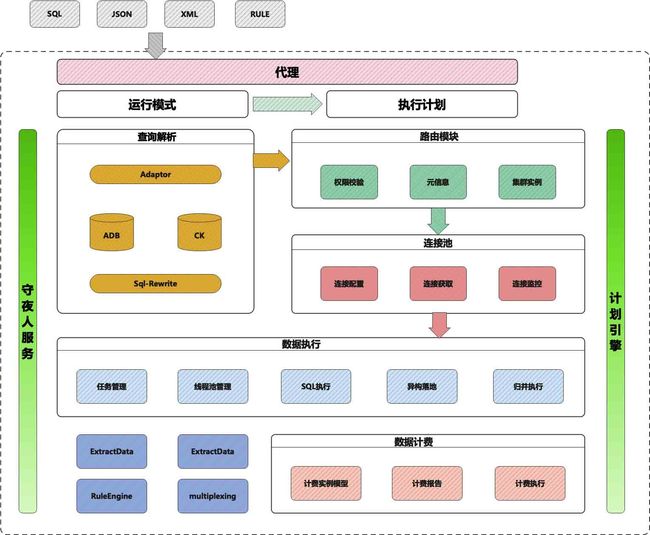
架构全景图
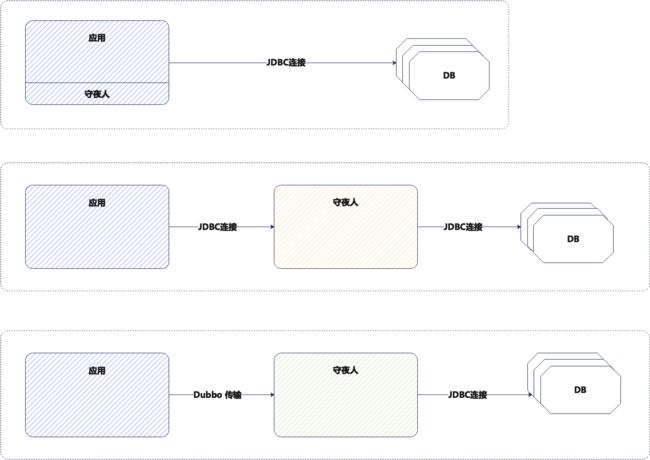
传统数据库中间件的几种模式:
种类 |
优势 |
缺点 |
JAR方式嵌入到应用端 |
|
|
中间件方式存在,伪装数据库代理层 |
|
|
中间件方式存在,不伪装数据库代理层 |
|
|
模块说明:
模块名 |
执行边界 |
输入描述 |
输出描述 |
代理模块 |
模型接入 |
请求模型 |
结果模型 |
运行模式模块 |
执行线程池处理 |
在线模式/离线模式 |
执行线程池 |
计划模块 |
离线模式和在线模式都需要创建入口执行计划和执行日志 离线异构取数场景,每一层内嵌取数都是单独计划和执行日志,完成后上推执行计划 计划存在父子计划任务 |
创建计划 查询可执行计划任务数据 更新计划状态 |
可执行的计划任务 |
解析模块 |
解析查询请求的参数,转换成 AST 语法树 |
查询语句,可以是 SQL,可以是 JSON 也可以是规则XML |
AST语法树对象、核心解析模型 |
权限校验模块 |
判断token是否有使用的实例、库、表权限 |
根据token,库,表查询到有权限的实例信息 |
是否有权限,以及有权限的实例信息 |
路由模块 |
获取有权限且最优的实例 |
请求来源的系统,请求来源的库,请求来源的表 |
符合权限校验的实例 ID+库信息 |
连接池管理模块 |
管理各种数据源的连接池 |
库元信息 |
连接池连接 |
数据执行模块 |
取数执行逻辑,根据改写后的SQL进行分实例分库分表查询,最终汇总到临时表,在进行完整原始SQL改写的执行 大数据量临时表通过生成SQL执行语句导入到OSS |
取数语句分析拆分后的执行语句 |
异构数据的话返回实例名+库名+表名 非异构数据返回数据结果集 |
计费模块 |
根据临时表数据量,跨库+跨表数量进行公式化计费 |
AST语法树对象、SQL |
最终成本费用 |
复用模块 |
数据复用的逻辑判断 |
执行语句,间隔时间 |
是否复用模型 |
熔断模块 |
对执行中的计划进行强制熔断,没有任何业务逻辑,只是提供熔断标示 |
计划ID |
是否熔断 |
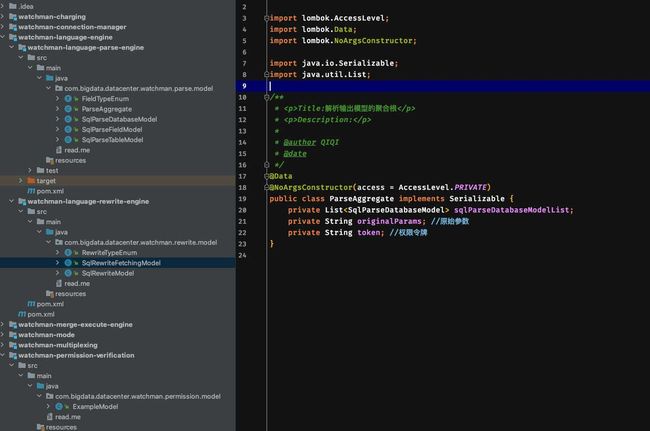
项目模块依赖描述:(开发分之:multiple-instances)(项目名:datacenter-night-watchman)
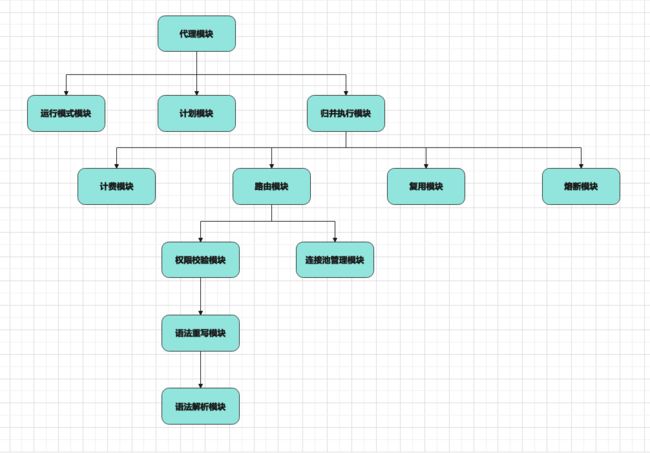
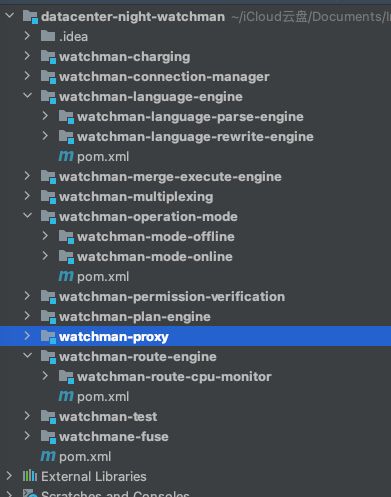
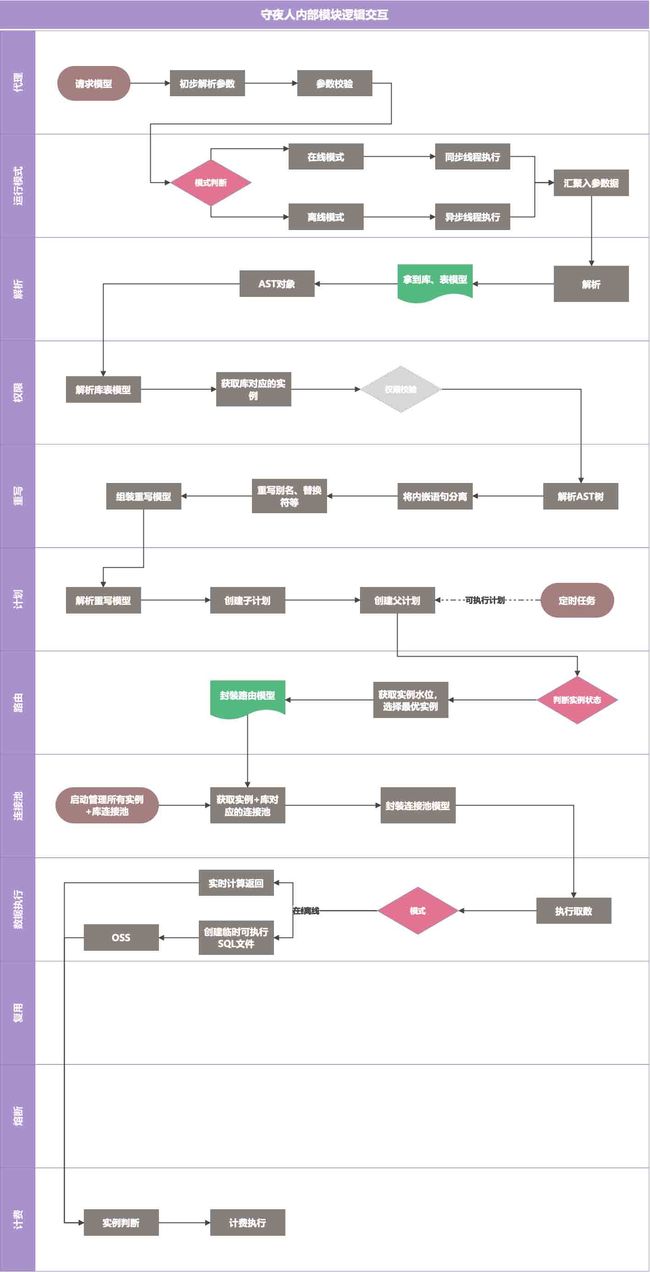
模块间逻辑交互
- 支持单实例多库查询
- 支持多实例多库查询
- 支持单实例单库查询
- 异构数据统一异步汇总临时表,非异构数据默认实时传输返回
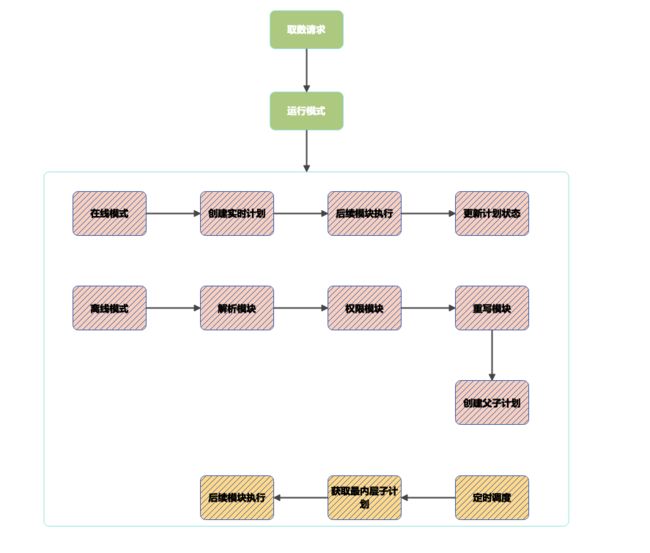
运行模式模块
- 在线模式(只支持非异构取数),先落地实时计划表,然后实时交互查询数据,返回数据
- 离线模式(支持异构和非异构取数),先实时创建父子计划,然后返回父计划ID,异步调度执行计划进行取数,接入方通过计划ID查询计划状态和异构存储表
- 每一个计划都对应一个取数任务
计划表结构:(Mysql-watchman库)

CREATE TABLE `extract_data_calculation_log` ( `id` bigint(32) NOT NULL, `exe_id` bigint(32) NOT NULL COMMENT '计划表主键ID', `last_exe_id` bigint(32) NOT NULL COMMENT '最大用户ID', `exe_state` tinyint(1) NOT NULL COMMENT '执行状态,1-执行中 2-执行成功 3-执行失败', `create_time` datetime(0) NOT NULL ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '记录创建时间', `updat_time` datetime(0) NULL ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '记录更新时间', `version` int(8) NOT NULL COMMENT '记录版本号', `exe_quantity` bigint(32) NULL COMMENT '数据冗余字段,执行的数据量', PRIMARY KEY (`id`), INDEX `exe`(`circle_exe_id`) ) COMMENT = '提取数据日志表';
CREATE TABLE `extract_data_execute` ( `id` bigint(32) NOT NULL, `storage_result` json NOT NULL COMMENT '{"type":"存储类型,1-adb 2-rmq 3-oss 4-ck","result":"adb/ck 代表表名,rmq代表topic,oss代表存储地址","example":"实例地址","database":"库地址"}', `create_time` timestamp(0) NOT NULL ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '记录创建时间', `updat_time` timestamp(0) NULL ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '记录更新时间', `plan_logic` tinyint(1) NOT NULL DEFAULT 1 COMMENT '计划逻辑,1-正常 2-暂不执行', `priority` int(8) NOT NULL DEFAULT 1 COMMENT '任务优先级,数字越小优先级越高', `data_type` tinyint(1) NOT NULL COMMENT '执行模式,1-立即执行 2-离线执行', `parent_id` bigint(0) NOT NULL DEFAULT 0 COMMENT '父级计划ID ', `rewrite_result` json NOT NULL COMMENT '改写模型', PRIMARY KEY (`id`) ) COMMENT = '数据取数计划表';
ALTER TABLE `extract_data_calculation_log` ADD CONSTRAINT `exe` FOREIGN KEY (`circle_exe_id`) REFERENCES `extract_data_execute` (`id`);
ALTER TABLE `extract_data_execute` ADD CONSTRAINT `config` FOREIGN KEY (`circle_config_id`) REFERENCES `circle_config` (`id`);
查询解析模块
- 解析模块使用shardingjdbc5内部的sql解析引擎,druid很久不更新了,很多新的语法支持不好
- 解析模块代码写到底层工具包,包含SQL、JSON解析

Sharding5 的解析引擎已经支持多种数据库包含各种数据库新增的函数语法解析,主要是Mysql、Pg、Sqlserver、Oracle
org.apache.shardingsphere shardingsphere-sql-parser-engine org.apache.shardingsphere shardingsphere-sql-parser-mysql org.apache.shardingsphere shardingsphere-infra-federation-optimizer org.apache.calcite calcite-core
Clickhouse和ADB目前都是支持原生mysql协议的,那么进入的数据库解析方言使用mysql引擎即可
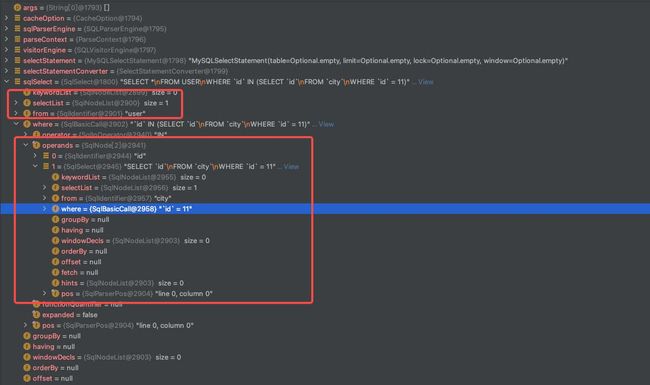
ShardingSphere解析引擎模块代码示例:
public static void main(String[] args) {
CacheOption cacheOption = new CacheOption( 128, 1024L, 4 ); SQLParserEngine sqlParserEngine = new SQLParserEngine( "MySQL", cacheOption, true );
ParseContext parseContext = sqlParserEngine.parse( "select * from user where id in (select id from city where id = 11);", true );
SQLVisitorEngine visitorEngine = new SQLVisitorEngine( "MySQL", "STATEMENT", new Properties() );
SelectStatement selectStatement = visitorEngine.visit( parseContext ); SelectStatementConverter selectStatementConverter = new SelectStatementConverter();
SqlSelect sqlSelect = (SqlSelect) selectStatementConverter.convertToSQLNode( selectStatement );
System.out.println( sqlSelect.getSelectList() );
System.out.println( sqlSelect.getFrom() );
System.out.println( sqlSelect.getWhere() );
}
输出结果: 查询字段:* 查询表:user 查询条件:`id` IN (SELECT `id` FROM `city` WHERE `id` = 11)
解析模块注意点:
- 解析引擎只做原始解析,然后封装到输出模型中
- 解析输出模型需要考虑嵌套SQL的模型存在以及同层级union的模型存在
- 解析输出模型聚合根已经调整好,缺失的字段或者模型在进行微调
权限校验模块:(此模块代码接口预留,逻辑暂不实现)
- 有了圈选解析模型,已经获取到使用的实例、库、表相关所有信息了
- 根据入参token判断实例和库的权限情况
- 表结构需要有,数据需要按照规范填入,后期做代码逻辑实现
- 暂时无实现,所以默认所有实例都可用,全部返回到模型
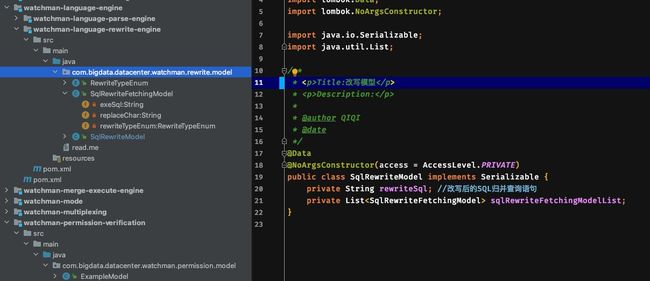
改写引擎
- 负责将可能涉及到多实例、多库、多表的联合查询拆分
- 拆分过程中需要考虑联合查询的where条件、group by 条件、order by 条件
- 如果解析模型传递过来的数据中,不存在跨库场景,那么改写引擎不进行任何操作逻辑
改写案例描述:
- 将复合嵌套的SQL平铺,按照库为单位,最内层开始为最小粒度
- 每一层都会同时存在4中类型改写语句
- 取数语句
- 替换符语句
- 聚合语句
- 建表语句

改写模型描述:
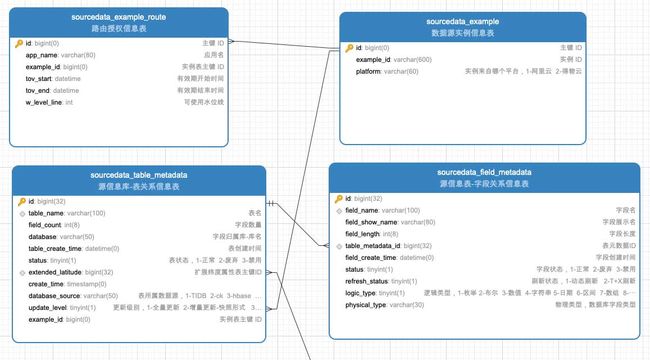
路由模块
- 通过权限模型中返回的有权限的实例,判断最优的CPU实例
- 根据实例+库名去连接池模块中获取相应的连接池信息
- 分库分表逻辑后续实现,暂不做设计
链接池模块
需要支持通配符方式的连接配置,案例:
# 同一个实例下不同库的通配连接 db.datasource.watchman.jdbcUrl=jdbc:mysql://A.mysql.rds.aliyuncs.com:3306/{db1,db2,db3}
db.datasource.watchman.username={A.db1:dw_datacenter_A,A.db2:dw_datacenter_B,A.db3:dw_datacenter_C} db.datasource.watchman.password= {A.db1:password_A,A.db2:password_B,A.db3:password_C}
# 不同实例下同库的通配连接 db.datasource.watchman.jdbcUrl=jdbc:mysql://{A,B}.mysql.rds.aliyuncs.com:3306/db1
db.datasource.watchman.username={A.db1:dw_datacenter_A,B.db1:dw_datacenter_B} db.datasource.watchman.password= {A.db1:password_A,B.db2:password_B}
# 同一个实例下不同库的区间通配连接 db.datasource.watchman.jdbcUrl=jdbc:mysql://A.mysql.rds.aliyuncs.com:3306/{db[1~20]}
db.datasource.watchman.username={A.db1:dw_datacenter_A,A.db2:dw_datacenter_B,A.db3:dw_datacenter_C,A.db...} db.datasource.watchman.password= {A.db1:password_A,A.db2:password_B,A.db3:password_C,A.db...}
# 多数据源连接配置 db.datasource.watchman.jdbcUrl.ck=jdbc:mysql://A.mysql.rds.aliyuncs.com:3306/{db[1~20]}
db.datasource.watchman.username.ck={A.db1:dw_datacenter_A,A.db2:dw_datacenter_B,A.db3:dw_datacenter_C,A.db...} db.datasource.watchman.password.ck= {A.db1:password_A,A.db2:password_B,A.db3:password_C,A.db...} db.datasource.watchman.jdbcUrl.adb=jdbc:mysql://A.mysql.rds.aliyuncs.com:3306/{db[1~20]}
db.datasource.watchman.username.adb={A.db1:dw_datacenter_A,A.db2:dw_datacenter_B,A.db3:dw_datacenter_C,A.db...} db.datasource.watchman.password.adb= {A.db1:password_A,A.db2:password_B,A.db3:password_C,A.db...}
链接池内部使用druid框架,没有单独对数据源进行druid参数配置的话全部采用守夜人默认提供的运行参数,如果需要单独对不同数据源进行配置,那么原先druid的配置加上对应的后缀
db.datasource.watchman.jdbcUrl.adb=jdbc:mysql://A.mysql.rds.aliyuncs.com:3306/{db[1~20]}
db.datasource.watchman.username.adb={A.db1:dw_datacenter_A,A.db2:dw_datacenter_B,A.db3:dw_datacenter_C,A.db...} db.datasource.watchman.password.adb= {A.db1:password_A,A.db2:password_B,A.db3:password_C,A.db...}
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。