一文教你如何处理高并发
目录
前言
一、为什么要解决高并发问题
二、性能评估
计算峰值流量方法
本章结论
三、性能测试
测试目的
找到系统最高承受压力的临界点
找出系统中的短板
测试工具
简单测试
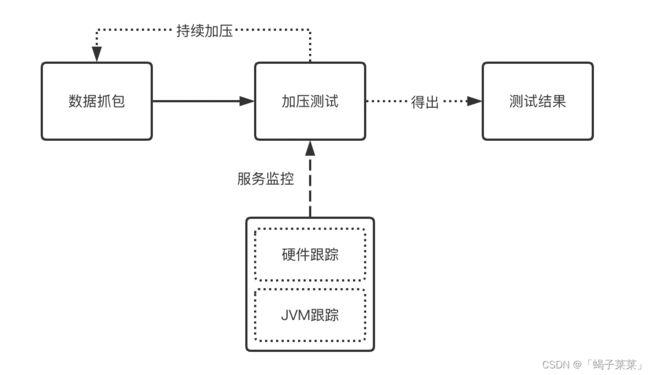
1.数据抓包
2.加压测试
3.硬件跟踪
4.JVM跟踪
5.其它组件测试
6.总括
全链路测试(待补充)
其它专项测试(待补充)
四、性能提升的思路
降低峰值带宽
减少客户端即时请求次数
默认数据+延迟更新
接口合并
异步处理+合并请求
负载均衡
缓存的使用
客户端缓存
服务器缓存
CDN缓存
服务端缓存(待补充)
性能提升评估
五、监控报警及扩容
监控报警(待补充)
扩容(待补充)
六、总结
前言
前言:面试的时候,面试官与你的聊天对话,是不是这样的:
第一种:
问:怎么解决高并发?
答:读写分离、分库分表、搜索引擎、分布式集群、消息队列、负载均衡......
问:技术方案呢?
答:SpringCloud、Dubbo、Redis Cluster、ES......
问:还有吗?
答:阿巴阿巴阿巴
问:怎么实施?
答:我......
问:那么用了你这套技术方案,并发量能到多少呢?
答:我.....
第二种:
问:怎么解决高并发?
答:分布式
问:用了分布式就能解决高并发?
答:阿巴阿巴阿巴
问:你说的分布式是不是就是加机器?
答:差不多是这样
问:比如让你做10w用户同时在线,那加多少呢?
答:我......
问:加了之后能满足吗?
答:我......
是不是跟你很像?那么带着这些问题,我们来看一看高并发应该如何处理。
一、为什么要解决高并发问题
1. 保障应用的正常运行
在任何情况下,都要保证用户正常使用。
2.保证资源的合理使用
公司是我们赖以生存的环境,合理爱护公司资源!!!
3.异常情况的应急处理
避免网络、内存、硬盘、CPU异常导致服务宕机;流量激增的情况下,防止服务垮掉。
二、性能评估
计算峰值流量方法
方法一:通过日PV计算
公式:峰值流量=(日PV*80%)/(60*60*24*20%),即每天80%的访问集中在20%的时间
方法二:通过项目经验给出基本判断
公式:峰值流量=用户在线数/(60*60*8)*N,N为预估倍数,一般为5到30倍
比如,我们项目有10w人用户同时在线,因为用户不可能平均分布在每天8个小时内(8个小时为工作时长),所以我们估算出同时在线人数。
方法三:接入第三方统计得出峰值流量和用户数据(推荐)
统计平台包括:友盟、极光、百度、Google Analytics、FireBase等,接过的同学一看就明白,没接过的自己去了解下吧,这里不多做赘述。
以下统计都以极光为例,数据很惨,哈哈哈。
用户增长趋势(极光统计)
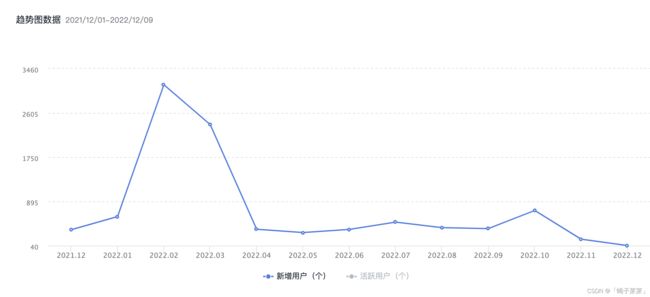 用户增长趋势图
用户增长趋势图
用户活跃统计(极光统计)
 用户活跃统计图
用户活跃统计图
用户访问路径统计(极光统计)
 用户访问页径统计图
用户访问页径统计图
用户访问页面统计(极光统计)
按照用户访问页面,分析用户访问行为,如下图(示例):
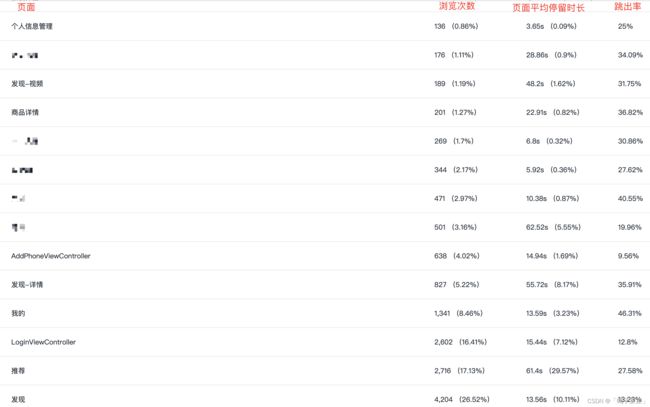 用户访问页面统计图
用户访问页面统计图
本章结论
1.我们可以通过以上的几种方法得出峰值的并发数。
2.如果接入统计,我们可以按用户在线人数、页面的访问路径、页面访问频次等做更加细粒度的规划,也就是在峰值流量期间,用户分布在什么功能点。
FAQ
1.为什么要定义并发数
为了更趋向于真实用户访问,我们需要给出准确的并发数,以便于后续并发测试、系统优化,这样得出的结论才会有说服力。
2.并发数评估方式的有哪些
你可以按自己的方式评估,也可以百度去搜,方法不限,但最终的目的都是模拟真实的用户访问。
3.为什么要接入第三方统计
接入第三方统计分析,可以很好的反映出在线人数、流量峰值、页面访问数等信息,对我们评估并发数有很好的帮助。
三、性能测试
测试目的
找到系统最高承受压力的临界点
测试系统能不能达到我们预期的并发数,并找到临界点。如果可以承载,那么多少的并发量,能把系统压崩;如果不能承载,那么系统可以最高可以承受多少的并发量。
找出系统中的短板
根据最短木板原理,找出系统性能最差的地方,对症下药,才能达到更好的效果。
测试工具
测试工具为前要条件,给大家简单介绍一下
- 任意抓包工具(重要),比如Charles、Burp Suite等
- 性能测试工具,比如Jmeter、LoadRunner等
- 数据库测试工具,比如MySQL测试可以使用sysbench
- 缓存测试工具,比如Redis测试可以使用redis-benchmark
- 各个厂商浏览器
- 各种厂商手机
简单测试
服务器硬件环境:硬盘60G,内存4G,带宽2M,CPU2个
使用主流品牌手机,在网络较好的情况下,打开今日某条
1.数据抓包
测试并记录步骤如下:
| 序号 | 步骤 | 接口数量 | 接口内容占用 | 总耗时 |
| 1 | 打开应用,进入引导页 | 2个 | 0.1k | 0.8s |
| 2 | 从引导页进入首页 | 4个 | 0.74k | 1.5s |
| 3 | 点击某一条新闻,进入详情页 | 1个 | 1.4k | 1.4s |
| 4 | 打开搜索框,进入搜索页 | 2个 | 0.3k | 1.2s |
| 5 | 输入内容,进行搜索 | 1个 | 0.8k | 1.3s |
注:数据为凭空捏造的,只是为了说明都需要干什么
名词解释
接口内容占用:指的是[请求体+返回体]内容占用的总字节数
总耗时:从用户点击到页面内容渲染完成的总耗时
2.加压测试
1.把上述所有接口,按照接口请求顺序,生成Jmeter脚本
2.Jmeter启动参数设置:线程数:20,循环次数:永久
3.此时会有20个线程在一直请求这些接口,即模拟20个用户同时在线。
4.此时我们再来使用APP,即:
| 序号 | 步骤 | 接口数量 | 接口内容占用 | 总耗时 |
| 1 | 打开应用,进入引导页 | 2个 | 0.1k | 1.7s |
| 2 | 从引导页进入首页 | 4个 | 0.74k | 5.3s |
| 3 | 点击某一条新闻,进入详情页 | 1个 | 1.4k | 2.1s |
| 4 | 打开搜索框,进入搜索页 | 2个 | 0.3k | 2.5s |
| 5 | 输入内容,进行搜索 | 1个 | 0.8k | 2.2s |
我们可以看到总耗时对比之前有所增加。
我们可以持续增加线程数,一直压到接口无响应,即为临界点。
3.硬件跟踪
我们观测服务器硬件使用情况为(示例):
| CPU | 内存 | 硬盘 | 带宽 |
| 15% | 75% | 20% | 0.9M |
服务器硬件使用情况,可以借助第三方云厂商DashBoard进行查看,如下为阿里云:
4.JVM跟踪
跟踪JVM使用情况为(可以使用阿里的arthas查看,官网在这里:https://arthas.gitee.io/):
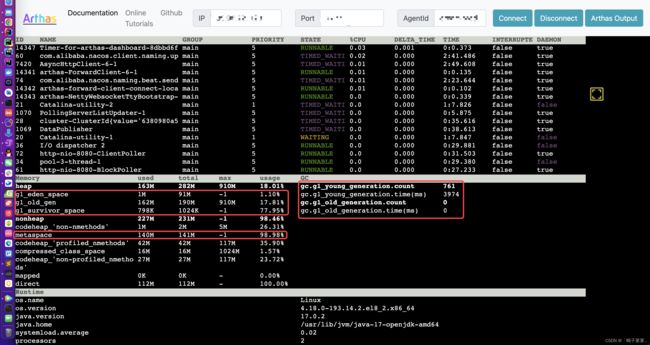
关于JVM的简单分析:
元空间:元空间包含:类的信息、方法数据、方法编码、常量池。如果元空间内存占用过大,需要看一下是不是有很多反射、代理等。
年老代:如果年老代内存占用过高,或者gc次数过多,就需要我们去调优,或增加硬件资源
年轻代:emmm,一般来说前面两个没问题,这个就不需要看,前面两个有问题,那就调前面两个。
5.其它组件测试
Web服务器测试:测试Nginx、Apache等Web服务器的吞吐量,可以使用Jemeter测试。
缓存测试:测试缓存的吞吐量,比如只读、只写、读写的情况下每秒可以处理的并发数。工具:redis-benchmark可以用来测试Redis
数据库测试:测试数据库的吞吐量,跟缓存的测试方法差不多。工具:sysbench可以用来测试mysql
服务端组件测试:其它组件像消息队列、搜索引擎、注册中心等都有自己的测试工具就不一一列举了,自己去百度搜吧。
6.总括
1.我们需要按照产品功能的使用步骤进行访问,并记录下访问过程中的各项数值。
2.递增式的对接口进行加压测试,直到接口无响应。
3.在测试期间,我们观察并记录硬件和GC的使用情况,并记录各项数值。
4.我们可以再把数据库、缓存、消息队列等也进行递增式的压力测试,得到各个组件的临界点。
5.最后我们得到了:
1)系统中所有接口的吞吐量
2)各项服务组件的吞吐量
然后,我们就可以根据我们性能评估的并发数,来测试我们的系统是否可以承载。
如果不能,则根据测试的数据报告,找出性能最弱的项,对其进行优化。
全链路测试(待补充)
其它专项测试(待补充)
白屏测试:用户从浏览器输入网址,到浏览器开始显示内容的时间。
首屏测试:用户从浏览器输入网址,到首屏内容渲染完成时间,此时整个网页不一定要全部渲染完成,但在当前视窗的内容需要
资源加载测试:统计页面中图片、js、字体等,从页面打开到资源加载完成时间。
RAIL指标:参照:03 RAIL 评估模型介绍 · 前端性能监控与体验优化实战 · 看云
FAQ
1.有人会问,我又不是测试工程师,为什么要我知道这些测试东西?
1)测试是评估系统吞吐量最直观的方法,也是最重要的一环之一;
2)身为团队的Leader,我们也应该知道让测试给出什么样的结果
3)我们应该知道什么样的测试的方法是正确的,如果测试的同学达不到预期,我们可以指导并协助他做好测试工作。
四、性能提升的思路
降低峰值带宽
解释:减少单次请求的数据量,按需拿取数据。即:客户端从服务端获取数据时,先拿首屏展示的数据,再预加载后续的数据。这样分段式的请求会降低峰值带宽。
例[1]:[今日某条]的[推荐列表],每屏展示信息不超过4条,那就每次拿4条。
例[2]:[某宝]的[购物车列表],每屏展示信息不超过5条,那就每次拿5条。
假如:
每条数据为1KB
当前在线人数为1000人
每个用户平均每人看看30条信息
把之前每页10条的改成每页5条后,假设用户每屏信息看1秒,得到如下表格
| 改版前带宽 | 改版后带宽 | |
| 第一秒 | 1K*10条*1000=10M | 1K*5条*1000=5M |
| 第二秒 | 0 | 1K*5条*1000=5M |
| 第三秒 | 1K*10条*1000=10M | 1K*5条*1000=5M |
| 第四秒 | 0 | 1K*5条*1000=5M |
| 第五秒 | 1K*10条*1000=10M | 1K*5条*1000=5M |
| 第六秒 | 0 | 1K*5条*1000=5M |
思路:服务端拼装数据量变小,客户端渲染的更快,且峰值带宽占用减少,可以节省硬件成本。
FAQ
问:这样虽然峰值带宽降了,但是用户体验比以前差了呀
答:可以用其他策略来规避,方法不限,示例:
方法[1]:先加载首屏数据条数(比如5条),等数据渲染后,再加载后续数据
方法[2]:先加载首屏数据条数,根据用户手势滑动行为,预加载后面数据(参考今日头条)
方法[3]:首屏加载数据条数和预加载数据条数,根据产品差异化加载。比如:首次加载10条,后续按照滑动手势每次递增5条。
问:那每次拿几条是适合的呢?
答:如果你不确定,那你就先定一个默认值,后续跟踪用户行为进行调整,比如:用户每屏可以看到多少数据;点击了多少次下一页;每次手势滑动距离有多大,涵盖多少数据;平均每个用户看多少条数据等,毕竟合适才是最好的。
问:那么怎么跟踪用户行为和跟踪调整后的用户反馈呢?
答:接第三方统计可以跟踪用户行为,但是需要客户端的同学对用户操作行为进行埋点。跟踪用户反馈的话使用A/B Testing,不懂的自行百度。
减少客户端即时请求次数
解释:页面渲染数据时,即时请求的接口越少,渲染速度越快。
以[今日某条]为例:
进入首页时,需要渲染[频道/label]+[置顶]+[信息流]三个类目的数据。
一般来说我们会把三个类目的数据做成三个不同的接口。
下面给大家列举几种策略:
默认数据+延迟更新
以[今日某条]中的[频道]为例(label栏)
1.先把[频道]的数据给几个默认值,比如[推荐]、[热榜]、[发现]、[视频]、[问答]、[音乐]等
2.我们拿[频道]数据的时候,从缓存里拿。如果缓存没有,就创建子线程发起异步延迟请求
3.异步延迟请求从服务端获取最新数据后,写入缓存,再通知主线程
4.主线程从缓存中获取最新的[频道]数据,并进行渲染,或下次打开渲染
5.客户端做好更新策略,比如[定时更新],[按用户点击频道次数更新]等
6.另外,如果首页渲染完成之后,用户直接滑动[频道]栏,那么就[缓存]+[请求接口]进行渲染
接口合并
以[今日某条]中的[置顶]+[信息流]为例
1.现有[置顶]的[接口A],[信息流]的[接口B]
2.服务端再创建一个[接口C],且C=A+B
3.如果客户端请求第一页的数据,那么服务端会把[置顶]和[信息流]的数据一并返回
异步处理+合并请求
以[今日某条]中的[点赞]、[收藏]为例
1.用户在客户端对文章[点赞/收藏]时,先把[文章]的数据存储到本地,不发送网络请求
2.把用户当前的文章状态改为[已点赞/已收藏]
3.当用户查看[点赞/收藏]列表时,从本地加载数据
4.制订数据上报策略,比如[按时间间隔上报]、[按点赞次数上报]等
5.制订数据更新策略,即按时间间隔,从服务端拿数据
6.其它问题:
6.1.数据上报,信息有可能被篡改,需要做安全加密处理
6.2.数据更新,如果有多端登录,比如PC+手机,需要考虑多端同步问题
优势:
默认数据+延迟更新:在不影响主要业务的情况下,加快渲染速度
接口合并:减少网络开销
异步处理+合并请求:从缓存中获取数据,效率更高
FAQ
问:把点赞、收藏等这些数据存到本地,如果数据未上报就丢失了怎么办
答:
1.比如[应用卸载/换手机]这些操作肯定会导致数据丢失,但这些情况毕竟占少数。
2.站在用户的角度,用户只在乎自己是否点赞成功,可能不在乎别人是否收到了赞;
3.用户点击收藏之后,就能在收藏列表看到已收藏文章,至于有没有上传到服务器,用户是无感知的。
4.就算数据丢失,用户也不一定记得对哪个文章点过赞;或者记得对哪个文章点过赞,发现没点赞成功,可能是因为自己网不好。
5.如果这类数据的价值可以覆盖成本,那么就不要这么做了。把数据提交到服务端,服务端写入到缓存,然后再定时把数据同步到数据库。
负载均衡
把任务拆分到多个单元进行执行,共同完成工作任务。
例1:把商城系统分成订单、商品、库存、商铺等多个模块,如需扩容就把相应模块进行横向扩容,也就是大家经常说的分布式+微服务。
例2:把一些服务中间件(如消息队列、搜索引擎)的各个节点,根据所需进行横向扩容。
说白了,就是把服务拆分成多个子模块或子节点,便于精准扩容。
缓存的使用
客户端缓存
打开应用,把请求到的数据都缓存起来,下次进入相同的页面后尽量不请求接口。(前端我会的不多)
需要增量更新的数据可以异步更新,或者引导用户去刷新
服务器缓存
Web服务器可以缓存js、图片、静态网页等一系列信息。
值得一提的是对于静态文件,客户端多次发起请求时资源未改动,http状态码会返回304即页面无改动,表示客户端可以从本地缓存拿相应资源。
CDN缓存
图片、视频、静态资源、大文件等可以使用第三方的CDN服务,加快访问速度,节省服务器带宽
服务端缓存(待补充)
服务端缓存都是以服务器内容为主。以Redis为例,官方表示单线程Redis吞吐量达到10w/每秒。
如果使用得当,可以解决大部分中小公司的性能问题
间隔性数据更新
首次查询后,把数据从数据库放入放入缓存;数据更新时,计算要统计的各项数值,以数据驱动的方式写入缓存。
以考试报名统计为例
| 活动名称 | 姓名 | 活动开始时间 | 活动结束时间 | 所在城市 | 订单号 | 订单创建时间 | 订单状态 | .....等几十个字段 | |
相信有的朋友做过这种类型的报表吧,从多张表中获取数据,无论怎么优化,效率都特别低。
改进建议:
数据查询:只从缓存中拿数据,如果未获取到数据,则通知[数据更新任务]
数据更新任务:异步从数据库的各个表中拿数据,然后拼装,最后写入缓存
增量更新:如果数据有[新增/修改],去缓存中找到相应的key,进行增量更新操作
改进后缺点:数据更新可能会延迟,延迟取决于数据查询的速度
改进后优点:极快!!!
后续我会专门写一篇[如果使用Redis做缓存]的博客主题
性能提升评估
当你真正去做的时候,你照着网上抄来的技术方案,给领导看或同事们看,他们有没有不认同你的方案,或对你的方案不屑一顾?那么问题的出在哪里呢?
其实很简单:
1.我们可先去做性能测试得到一份性能报告
2.根据性能报告找出系统的性能最差的地方,再制定相应的优化方案
3.制定优化方案后,再把提升的性能指标量化出来
当你拿出[性能报告+优化方案+提升结果]再去汇报的时候,想必成功率就很高了。
五、监控报警及扩容
上线后,我们要对服务进行监控,避免服务有异常情况发生。
监控报警(待补充)
一般来说,我们会对CPU,内存,硬盘、网络四个要素进行监控。
我们用的阿里云自带免费的报警,示例:

也可以使用脚本的方式,对报警的信息,发邮件处理。
扩容(待补充)
监控报警后,对于报警的相关项进行扩容。
六、总结
本文介绍了解决高并发的的通用的思路,包括性能评估、性能测试、性能优化、性能优化数据报告、监控以及扩容。这些都是我在项目里遇到的,我把这些总结了一下,分享给大家。以上是我对高并发的理解,望不足之处大家能够指正。
对我来讲,高并发的核心只有一个,就是你要明白问题出在哪?
比如说:
- 项目中哪里的效率低,要不要去优化(比如功能用的少不一定要去优化) ?影响项目的短板在哪里?
- 是应该优化还是应该加机器?优化的话需要优化哪里?是由前端负责还是由后端负责?加机器应该加多少?
- 在现有项目中,影响项目并发的哪个硬件是短板?CPU、内存、硬盘、带宽、GPU?
- 在现有项目中,多少量级的用户,需要多少的硬件来支撑?用户达到多长量级的时候需要扩容?
对于高并发来说,没有最好的方案,只有最合适的方案。
再回答一下开头的问题
1.怎么解决高并发
首先我们需要进行性能测试,然后逐步的找到性能瓶颈产生的地方,再对症下药。
2.高并发要用什么技术来解决
解决高并发跟技术和开发语言没关系,理论上来说:你机器的硬件越好,能承受的并发越高。比如说:一个要住500人的楼盘和要住3000人的楼盘,基建设施肯定会差很多的;往500人的楼盘塞3000人,无论怎么优化,效果可能都没那么好,所以合理的资源使用对我们有着至关重要的作用。
3.解决高并发的技术方案
其实也就是文章的主要内容:先性能评估,再性能测试,然后优化,最后给出优化后的结论。
4.分布式可以用来解决高并发吗
分布式可以用来解决高并发,思路就是把整个项目拆分成微服务,然后按需进行扩容。但是关键点是我们要知道:在什么时候应该扩容什么硬件。
4.SpringCloud、Dubbo、Redis Cluster、ES这些是怎么解决高并发的?
SpringCloud:把服务按模块拆分开,按照每个模块评估性能,按需扩容。
Dubbo:把服务按模块拆分开,按照每个模块评估性能,按需扩容。
Elastic Search:简单来说,就是把数据库的数据放到内存里,再建立索引,达到快速搜索的目的
Redis Cluster:
1.先说Redis,Redis使用内存当存储空间,在1CPU 1G的服务器上QPS大概在10w左右。
2.那如果超过10w怎么办?Redis Cluster给出了哈希槽的概念,简单理解就是Redis增加了Node(节点),Client写入的时候,会根据算法算出插入哪个Node,达到负载均衡的效果。一个Node的QPS是10w,最优的情况下10个节点QPS就是100w了。
自我评价
文章的前半部分写的还可以,有条理性,也比较直观一点。后半部分的话,我太想把我的想法和我对产品的看法表露出来,然后条理性变得很差,一堆一堆的字儿,搞的我自己都不太想去读。但是总体来说的话,我还是把我心中的那个高并发的认知给写出来了。后面有时间的话,肯定会把这篇文章重新梳理一下。