Hudi 数据湖的插入,更新,查询,分析操作示例
Hudi 数据湖的插入,更新,查询,分析操作示例
作者:Grey
原文地址:
博客园:Hudi 数据湖的插入,更新,查询,分析操作示例
CSDN:Hudi 数据湖的插入,更新,查询,分析操作示例
前置工作
首先,需要先完成
Linux 下搭建 Kafka 环境
Linux 下搭建 Hadoop 环境
Linux 下搭建 HBase 环境
Linux 下搭建 Hive 环境
本文基于上述四个环境已经搭建完成的基础上进行 Hudi 数据湖的插入,更新,查询操作。
开发环境
Scala 2.11.8
JDK 1.8
需要熟悉 Maven 构建项目和 Scala 一些基础语法。
操作步骤
master 节点首先启动集群,执行:
stop-dfs.sh && start-dfs.sh
启动 yarn,执行:
stop-yarn.sh && start-yarn.sh
然后准备一个 Mave 项目,在 src/main/resources 目录下,将 Hadoop 的一些配置文件拷贝进来,分别是
$HADOOP_HOME/etc/hadoop/core-site.xml 文件
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop/tmpvalue>
property>
configuration>
注意,需要在你访问集群的机器上配置 host 文件,这样才可以识别 master 节点。
$HADOOP_HOME/etc/hadoop/hdfs-site.xml 文件
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>
$HADOOP_HOME/etc/hadoop/yarn-site.xml 文件,目前还没有任何配置
<configuration>
configuration>
然后,设计实体的数据结构,
package git.snippet.entity
case class MyEntity(uid: Int,
uname: String,
dt: String
)
插入数据代码如下
package git.snippet.test
import git.snippet.entity.MyEntity
import git.snippet.util.JsonUtil
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object DataInsertion {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("MyFirstDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
insertData(sparkSession)
}
def insertData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/mydata/data1")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = JsonUtil.getJsonData(item.getString(0))
MyEntity(jsonObject.getIntValue("uid"), jsonObject.getString("uname"), jsonObject.getString("dt"))
})
})
val result = df.withColumn("ts", lit(commitTime)) //添加ts 时间戳列
.withColumn("uuid", col("uid"))
.withColumn("hudipart", col("dt")) //增加hudi分区列
result.write.format("org.apache.hudi")
.option("hoodie.insert.shuffle.parallelism", 2)
.option("hoodie.upsert.shuffle.parallelism", 2)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交时间列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一标示列
.option("hoodie.table.name", "myDataTable")
.option("hoodie.datasource.write.partitionpath.field", "hudipart") //分区列
.mode(SaveMode.Overwrite)
.save("/snippet/data/hudi")
}
}
然后,在 master 节点先准备好数据
vi data1
输入如下数据
{'uid':1,'uname':'grey','dt':'2022/09'}
{'uid':2,'uname':'tony','dt':'2022/10'}
然后创建文件目录,
hdfs dfs -mkdir /mydata/
把 data1 放入目录下
hdfs dfs -put data1 /mydata/
访问:http://192.168.100.130:50070/explorer.html#/mydata
可以查到这个数据
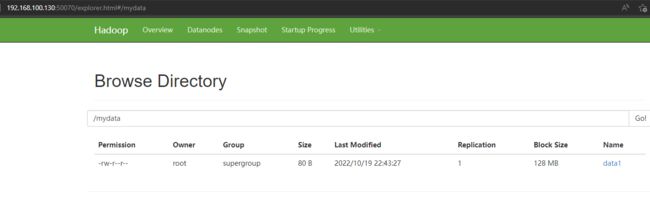
接下来执行插入数据的 scala 代码,执行完毕后,验证一下
访问:http://192.168.100.130:50070/explorer.html#/snippet/data/hudi/2022
可以查看到插入的数据

准备一个 data2 文件
cp data1 data2 && vi data2
data2 的数据更新为
{'uid':1,'uname':'grey1','dt':'2022/11'}
{'uid':2,'uname':'tony1','dt':'2022/12'}
然后执行
hdfs dfs -put data2 /mydata/
更新数据的代码,我们可以做如下调整,完整代码如下
package git.snippet.test
import git.snippet.entity.MyEntity
import git.snippet.util.JsonUtil
import org.apache.hudi.{DataSourceReadOptions, DataSourceWriteOptions}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object DataUpdate {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("MyFirstDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
updateData(sparkSession)
}
def updateData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/mydata/data2")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = JsonUtil.getJsonData(item.getString(0))
MyEntity(jsonObject.getIntValue("uid"), jsonObject.getString("uname"), jsonObject.getString("dt"))
})
})
val result = df.withColumn("ts", lit(commitTime)) //添加ts 时间戳列
.withColumn("uuid", col("uid")) //添加uuid 列
.withColumn("hudipart", col("dt")) //增加hudi分区列
result.write.format("org.apache.hudi")
// .option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
.option("hoodie.insert.shuffle.parallelism", 2)
.option("hoodie.upsert.shuffle.parallelism", 2)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交时间列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一标示列
.option("hoodie.table.name", "myDataTable")
.option("hoodie.datasource.write.partitionpath.field", "hudipart") //分区列
.mode(SaveMode.Append)
.save("/snippet/data/hudi")
}
}
执行更新数据的代码。
验证一下,访问:http://192.168.100.130:50070/explorer.html#/snippet/data/hudi/2022
可以查看到更新的数据情况

数据查询的代码也很简单,完整代码如下
package git.snippet.test
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object DataQuery {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("MyFirstDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
queryData(sparkSession)
}
def queryData(sparkSession: SparkSession) = {
val df = sparkSession.read.format("org.apache.hudi")
.load("/snippet/data/hudi/*/*")
df.show()
println(df.count())
}
}
执行,输出以下信息,验证成功。

数据查询也支持很多查询条件,比如增量查询,按时间段查询等。
接下来是 flink 实时数据分析的服务,首先需要在 master 上启动 kafka,并创建 一个名字为 mytopic 的 topic,详见Linux 下搭建 Kafka 环境
相关命令如下
创建topic
kafka-topics.sh --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --create --topic mytopic
生产者启动配置
kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic mytopic
消费者启动配置
kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic mytopic
然后运行如下代码
package git.snippet.analyzer;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class DataAnalyzer {
public static void main(String[] args) {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.100.130:9092");
properties.setProperty("group.id", "snippet");
//构建FlinkKafkaConsumer
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>("mytopic", new SimpleStringSchema(), properties);
//指定偏移量
myConsumer.setStartFromLatest();
final DataStream<String> stream = env.addSource(myConsumer);
env.enableCheckpointing(5000);
stream.print();
try {
env.execute("DataAnalyzer");
} catch (Exception e) {
e.printStackTrace();
}
}
}
其中
properties.setProperty("bootstrap.servers", "192.168.100.130:9092");
根据自己的配置调整,然后通过 kakfa 的生产者客户端输入一些数据,这边可以收到这个数据,验证完毕。
完整代码见
data-lake