STL标准库设计原理与使用
目录
简介
1.1 STL的版本
1.2 STL的组成
STL六大组件
内存分配
常用头文件
容器与数据结构
序列式容器
2.1 数组类容器
2.1.1 vector
2.1.2 array
2.1.3 string
2.2 链表类容器
2.2.1 list
2.2.2 forward_list
2.3 队列类容器
2.3.1 deque
2.3.2 stack
2.3.3 queue
2.4 堆容器 priority_queue
关联式容器
3.1 set
3.2 map
无序关联式容器
4.1 unordered_set
4.2 unordered_map
常用算法
5.1 非质变算法
5.2 质变算法
5.3 排序和查找算法
参考资料
-
简介
STL 是“Standard Template Library”的缩写,中文译为“标准模板库”。STL 是 C++ 标准库的一部分,不用单独安装,命名空间std。
C++ 对模板(Template)支持得很好,STL 就是借助模板把常用的数据结构及其算法都实现了一遍,并且做到了数据结构和算法的分离。
STL 是一些容器、算法和其他一些组件的集合,它位于各个 C++ 的头文件中,以源代码的形式提供。
1.1 STL的版本
STL是一个标准,只规定了STL的接口,内部实现没有要求。STL有许多实现版本:
SGI STL版本注释丰富,结构清晰,可读性较强,GNU STL是基于SGI版本开发的,所以是最流行的版本。
CLANG 中使用的是LLVM STL, mac os中用的就是LLVM STL。
1.2 STL的组成
STL六大组件
-
容器(containers) 一些封装数据结构的模板类,例如 vector 向量容器、list 列表容器等。
-
算法(algorithms)STL 提供的数据结构算法,被设计成一个个的模板函数,大部分算法都包含在头文件
中,少部分位于头文件 中。 -
迭代器(iterators)对容器中数据的读和写,是通过迭代器完成的,它扮演着容器和算法之间的胶合剂
-
仿函数(functors)一个类将 () 运算符重载为成员函数,这个类就称为函数对象类,这个类的对象就是函数对象(又称仿函数)。
-
配接器(adapters)使一个类的接口(模板的参数)适配成用户指定的形式,从而让原本不能在一起工作的两个类工作在一起。
-
配置器(allocators)又叫内存分配器,为容器类模板提供自定义的内存申请和释放功能,内存分配器对于一般用户来说,并不常用。

内存分配
为了减小内存碎片问题,SGI STL采用了两级配置器:
-
当分配的空间大小超过128 bytes时,会使用第一级空间配置器。第一级空间配置器直接使用malloc()、realloc()、free()函数进行内存空间的分配和释放。
-
当分配的空间小于128 Bytes时,将使用第二级空间配置器。第二级空间配置器采用了内存池技术,通过空闲链表来管理内存,初始配置一大块内存,并维护对应不同内存空间大小的的16个空闲链表,它们管理的内存块大小是8、16、24、...、128 bytes,如果有内存需求,直接在空闲链表中取,如果有内存释放,则归还到空闲链表中。

常用头文件
C++标准库定义的无扩展名的头文件
Mac上的源码路径:
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/include/c++/v1/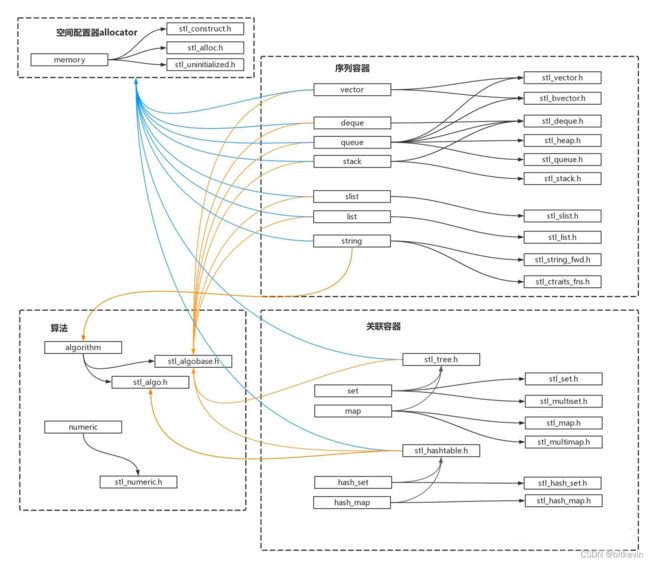
容器与数据结构
下图为常见数据结构,下面会结合数据结构讲解容器的实现原理。

-
-
-
序列式容器
序列式容器:以线性排列来存储某一指定类型的数据,对应于数据结构中的线性表。
2.1 数组类容器
2.1.1 vector
vector可以看做是支持模板的动态数组容器,它满足数组内存连续存储,O(1)遍历,O(n)插入删除的特性,并且可以动态扩缩容。
vector的实现
LLVM版本vector实现
templateclass __vector_base : protected __vector_base_common { public: typedef _Allocator allocator_type; typedef allocator_traits __alloc_traits; typedef typename __alloc_traits::size_type size_type; protected: typedef _Tp value_type; typedef value_type& reference; typedef const value_type& const_reference; typedef typename __alloc_traits::difference_type difference_type; typedef typename __alloc_traits::pointer pointer; typedef typename __alloc_traits::const_pointer const_pointer; typedef pointer iterator; typedef const_pointer const_iterator; pointer __begin_; pointer __end_; __compressed_pair 
vector的遍历
#include#include #include using namespace std; int main() { vector values{1,2,3,4,5}; //1.下标遍历 for (int i = 0; i < values.size(); i++) { cout << values[i] << " "; } cout << endl; //2.迭代器遍历 for (vector ::iterator pos = values.begin(); pos != values.end(); ++pos) { cout << *pos << " "; } cout << endl; //3.range for (c++11) for (const auto& value : values) { cout << value << " "; } cout << endl; //4. for_each (c++11) for_each(values.begin(), values.end (), [&](int v){ cout < vector元素删除
#include#include #include using namespace std; int main() { std::vector demo{ 1,3,5,4,3,2,5,2,1 }; //1.使用迭代器删除3 for(auto iter = demo.begin(); iter != demo.end();) { if(*iter = 3){ iter = demo.erase(iter); }else{ iter++; } } for (const auto& value : demo) { cout << value << " "; } cout << endl; cout << "size is :" << demo.size() << endl; cout << "capacity is :" << demo.capacity() << endl; //2.使用remove函数交换要删除元素和最后一个元素的位置 auto iter = std::remove(demo.begin(), demo.end(), 3); cout << "size is :" << demo.size() << endl; cout << "capacity is :" << demo.capacity() << endl; //输出剩余的元素 for (auto first = demo.begin(); first != iter;++first) { cout << *first << " "; } return 0; } vector的初始化
初始化
std::vectorvalue1(5, 'c'); std::vector value2(value1); int array[]={1,2,3}; std::vector values(array, array+2);//values 将保存{1,2} std::vector value3{1,2,3,4,5}; std::vector value4(std::begin(value3),std::begin(value4)+3);//value3保存{1,2,3} 赋值
std::vector users; //预分配内存,防止频繁动态扩容造成性能损耗 //1.reserve users.reserve(1000); for (int i = 0; i < 1000; ++i) users.push_back(xxx); //2.resize std::vector newUsers(users.size()); for (int i = 0; i < newUsers.size(); ++i) newUsers[i] = xxx;高效push_back
数据类定义了一个noexcept的移动构造函数,原始数据将不用拷贝构造函数拷贝,而使用移动构造,大大提高效率。
#include#include class TestDemo { public: TestDemo(int num):num(num){ std::cout << "调用构造函数" <<"," << num << endl; } TestDemo(const TestDemo& other) :num(other.num) { std::cout << "调用拷贝构造函数" <<"," << num << endl; } TestDemo(TestDemo&& other) noexcept :num(other.num) { std::cout << "调用移动构造函数" <<"," << num << endl; } private: int num; }; int main() { std::vector demo{2,3}; TestDemo test{1}; demo.push_back(test); demo.emplace_back(4); //使用empalce_back直接在vector上构造变量避免拷贝 } 输出结果:
调用构造函数,2 调用构造函数,3 调用拷贝构造函数,2 调用拷贝构造函数,3 调用构造函数,1 调用拷贝构造函数,1 调用移动构造函数,3 调用移动构造函数,2 调用构造函数,4vector扩缩容
使用reserve(n) 扩容:如果n>capacity(),则将capacity扩大到n; 否则什么都不做。
使用resize(n) 扩缩容:如果n>size(),将size()扩大到n并且使用构造函数初始化扩出来的n-size()个对象;否则析构后size()-n个元素,将size()缩减到n。
使用shrink_to_fit() 缩容:如果capacity()>size(), 则将cpacity()缩小到size()。
2.1.2 array
c++11增加的数组容器,大小固定的,无法扩缩容,无法增加删除元素。相比原生数组,使用更加安全。

2.1.3 string
string的底层实现与vector相同,很多vector的成员函数string都可以直接使用。比如 auto length = s.length(); 等价于 auto length = s.size();
不同的是string中保存的是char字符,并且string增加了很多字符查找替换等功能。
2.2 链表类容器
2.2.1 list
list的llvm实现版本:
templatestruct __list_node_base { typedef __list_node_pointer_traits<_Tp, _VoidPtr> _NodeTraits; typedef typename _NodeTraits::__node_pointer __node_pointer; typedef typename _NodeTraits::__base_pointer __base_pointer; typedef typename _NodeTraits::__link_pointer __link_pointer; __link_pointer __prev_; //前驱指针 __link_pointer __next_; //后继指针 _LIBCPP_INLINE_VISIBILITY __list_node_base() : __prev_(_NodeTraits::__unsafe_link_pointer_cast(__self())), __next_(_NodeTraits::__unsafe_link_pointer_cast(__self())) {} _LIBCPP_INLINE_VISIBILITY __base_pointer __self() { return pointer_traits<__base_pointer>::pointer_to(*this); } _LIBCPP_INLINE_VISIBILITY __node_pointer __as_node() { return static_cast<__node_pointer>(__self()); } }; template struct __list_node : public __list_node_base<_Tp, _VoidPtr> { _Tp __value_; //链表节点值 typedef __list_node_base<_Tp, _VoidPtr> __base; typedef typename __base::__link_pointer __link_pointer; _LIBCPP_INLINE_VISIBILITY __link_pointer __as_link() { return static_cast<__link_pointer>(__base::__self()); } }; template class __list_imp { __list_imp(const __list_imp&); __list_imp& operator=(const __list_imp&); public: typedef _Alloc allocator_type; typedef allocator_traits __alloc_traits; typedef typename __alloc_traits::size_type size_type; protected: typedef _Tp value_type; typedef typename __alloc_traits::void_pointer __void_pointer; typedef __list_iterator 
stl list是一个双向链表,每个链表节点都有一个前驱指针一个后继指针,它的迭代器具有前移和后移的能力。事实上SGI 和LLVM的list的实现都是一个循环双向链表,这个链表只需要一个指针就可以表现一个完整链表。

list的设计保证了插入删除操作不会造成原有list迭代器的失效(被删除元素的迭代器除外)。
list符合链表数据结构的特点,内存不连续,知道插入删除位置的情况下插入删除时间复杂度O(1),遍历时间复杂度O(n),不支持随机访问节点,适合于插入删除比较频繁的场景。
list除了不支持随机访问外,其他操作和vector类似,这里不做详细介绍了。
2.2.2 forward_list

c++11增加的单向链表容器,单链表只有一个后继指针,没有前驱指针,因此只能向后遍历不能向前遍历。
forward_list的优势在于链表节点只用存储一个额外指针,耗费的内存空间更少,在插入删除比较频繁的场景效率也是很高。
2.3 队列类容器
2.3.1 deque
deque是stl中双向队列的实现,它是双向开口的连续线性空间,在队列头尾插入删除的时间复杂度都是O(1),而vector只有在vector尾部插入才能做到平均O(1)的时间复杂度。
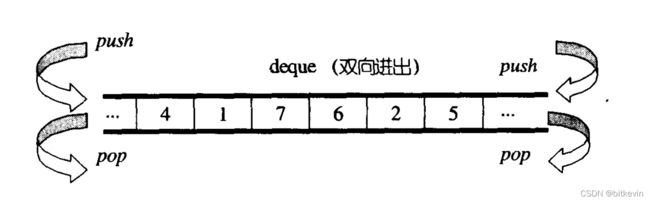
deque的实现
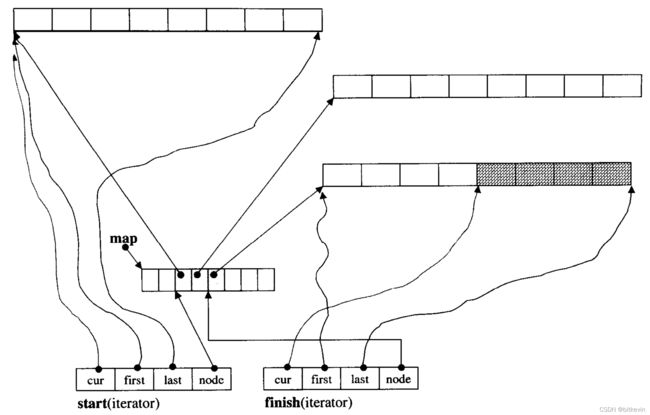
如上图所示,deque的实现是分段连续空间,通过迭代器实现整体连续的假象。通过迭代器的++/--可以实现访问队列元素的前驱和后继。
deque的使用
#include#include using namespace std; int main() { //初始化一个空deque容量 deque d; //向d容器中的尾部依次添加 1,2,3 d.push_back(1); //{1} d.push_back(2); //{1,2} d.push_back(3); //{1,2,3} //向d容器的头部添加 0 d.push_front(0); //{0,1,2,3} //调用 size() 成员函数输出该容器存储的字符个数。 printf("元素个数为:%d\n", d.size()); //使用迭代器遍历容器 for (auto itr = d.begin(); itr != d.end(); ++itr) { cout << *itr << " "; } cout << endl; return 0; } 2.3.2 stack
template*/> class _LIBCPP_TEMPLATE_VIS stack { public: typedef _Container container_type; typedef typename container_type::value_type value_type; typedef typename container_type::reference reference; typedef typename container_type::const_reference const_reference; typedef typename container_type::size_type size_type; static_assert((is_same<_Tp, value_type>::value), "" ); protected: container_type c; public: bool empty() const {return c.empty();} _LIBCPP_INLINE_VISIBILITY size_type size() const {return c.size();} _LIBCPP_INLINE_VISIBILITY reference top() {return c.back();} _LIBCPP_INLINE_VISIBILITY const_reference top() const {return c.back();} _LIBCPP_INLINE_VISIBILITY void push(const value_type& __v) {c.push_back(__v);} #ifndef _LIBCPP_CXX03_LANG _LIBCPP_INLINE_VISIBILITY void push(value_type&& __v) {c.push_back(_VSTD::move(__v));} } stack 是stl中的栈的实现,具有先进后出的特点,底层实现默认使用deque实现,也可以使用list实现。
stack没有迭代器,只有栈顶的元素可以访问。
stack的使用:
#include#include #include -
using namespace std;
int main()
{
stack
st; //向st容器中依次添加 1,2,3 st.push(1); //{1} st.push(2); //{1,2} st.push(3); //{1,2,3} //栈的遍历 while(!st.empty()){ cout << st.top() << " "; st.pop(); } cout << endl; //list实现的stack statck 2.3.3 queue
queue 是stl中的队列的实现,具有先进先出的特点,底层实现默认使用deque实现,也可以使用list实现。
queue没有迭代器,只有队头的元素可以访问。
queue的使用:
#include#include #include -
using namespace std;
int main()
{
queue
que; //向que容器中依次添加 1,2,3 que.push(1); //{1} que.push(2); //{1,2} que.push(3); //{1,2,3} //栈的遍历 while(!que.empty()){ cout << que.front() << " "; que.pop(); } cout << endl; //list实现的queue queue 2.4 堆容器 priority_queue
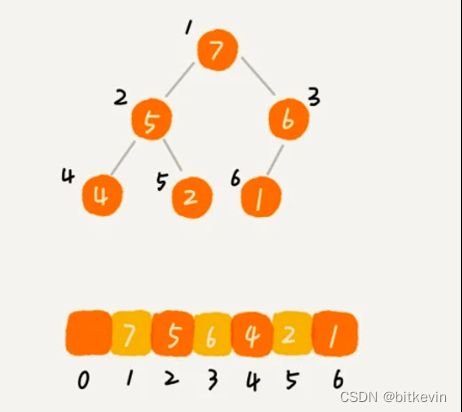
priority_queue 优先级队列,是stl中堆的实现,堆是一种完全二叉树,因此可以使用数组来存储。
stl中priority_queue默认使用vector实现,头文件
,它的对外接口和queue很像,但不是依赖于deque来实现的。 priority_queue的实现
template, class _Compare = less > class _LIBCPP_TEMPLATE_VIS priority_queue { public: typedef _Container container_type; typedef _Compare value_compare; typedef typename container_type::value_type value_type; typedef typename container_type::reference reference; typedef typename container_type::const_reference const_reference; typedef typename container_type::size_type size_type; static_assert((is_same<_Tp, value_type>::value), "" ); protected: container_type c; value_compare comp; public: _LIBCPP_NODISCARD_AFTER_CXX17 _LIBCPP_INLINE_VISIBILITY bool empty() const {return c.empty();} _LIBCPP_INLINE_VISIBILITY size_type size() const {return c.size();} _LIBCPP_INLINE_VISIBILITY const_reference top() const {return c.front();} _LIBCPP_INLINE_VISIBILITY void push(const value_type& __v); #ifndef _LIBCPP_CXX03_LANG _LIBCPP_INLINE_VISIBILITY void push(value_type&& __v); template _LIBCPP_INLINE_VISIBILITY void emplace(_Args&&... __args); #endif // _LIBCPP_CXX03_LANG _LIBCPP_INLINE_VISIBILITY void pop(); }; 堆中元素为堆序排列,堆顶元素是最大/最小元素,取堆顶时间复杂度O(n)。
stl默认实现是大顶堆,指定比较器可以成为小顶堆,自定义类型做堆元素需要实现比较器仿函数或者重载operator <
#include#include using namespace std; int main() { //大顶堆 priority_queue q; for( int i= 0; i< 10; ++i ) q.push(i); while( !q.empty() ){ cout< > q2; for( int i= 0; i< 10; ++i ) q2.push(i); while( !q2.empty() ){ cout << q2.top() << endl; q2.pop(); } } 应用场景:
•求Top K问题
•求中位数
•求tp99响应时间
•图的最短路径
-
关联式容器
以下关联式容器都是基于红黑树(RB-tree)实现。

红黑树是一种近似平衡的二叉搜索树,它有以下特点:
•红黑树的高度近似2log2n
•查找删除插入时间复杂度O(logn)
•插入删除性能高于AVL树
•查找、删除、插入性能都比较稳定
3.1 set
set的容器模板
template < class T, // 键 key 的类型 class Compare = less, // 指定 set 容器内部的排序规则 默认升序 class Alloc = allocator // 指定分配器对象的类型 > class set; set依赖红黑树实现,所有元素都会自动按键值排序,不可以通过迭代器修改键值,自定义类型做键值需要实现比较器。
set的使用:
#include#include #include using namespace std; int main() { //创建并初始化set容器 std::set 3.2 map
map与set的实现类似,都是依赖于红黑树实现底层处理,不同的是map中存储的元素是pair, 它同时具有键值(key)和实值(value)。map不可以修改key,但可以修改value。
其他容器:
multiset 允许键值重复的set
multimap 允许键值重复的map
-
无序关联式容器
无序关联式容器是C++11才引入的容器,底层通过哈希表实现,数据分布比较均匀时,使用哈希表插入、删除、查找等操作可以达到平均O(1)的时间复杂度。


基于底层实现采用了不同的数据结构,因此和关联式容器相比,无序关联式容器具有以下 2 个特点:
-
无序容器内部存储的键值对是无序的,各键值对的存储位置取决于该键值对中的键
-
无序容器擅长通过指定键查找对应的值(平均时间复杂度为 O(1));对于使用迭代器遍历容器中存储的元素,无序容器的执行效率则不如关联式容器。
4.1 unordered_set
unorderd_set的容器模板:
template < class Key, //容器中存储元素的类型 class Hash = hash, //确定元素存储位置所用的哈希函数 class Pred = equal_to , //判断各个元素是否相等所用的函数 class Alloc = allocator //指定分配器对象的类型 > class unordered_set; 自定义类型需要实现自己的哈希函数和判断相等函数
4.2 unordered_map
unordered_map的容器模板
template < class Key, //键值对中键的类型 class T, //键值对中值的类型 class Hash = hash, //容器内部存储键值对所用的哈希函数 class Pred = equal_to , //判断各个键值对键相同的规则 class Alloc = allocator< pair > // 指定分配器对象的类型 > class unordered_map; unordered_map的初始化和赋值
#include#include #include using namespace std; int main() { //创建空 umap 容器 unordered_map 小心迭代器失效
哈希表在插入删除过程中会发生rehash,从而可能导致原有的迭代器失效。
#include#include using namespace std; int main() { //创建 umap 容器 unordered_map 预分配大小防止多次rehash造成的性能损耗
如果预先知道要使用的unordered_map的大小或大致大小,可以预分配好大小,防止不断追加造成的多次rehash
#include#include using namespace std; int main() { unordered_map 其他容器:
unordered_multiset 允许键值重复的unordered_set
unordered_multimap 允许键值重复的unordered_map
-
-
常用算法
5.1 非质变算法
-
for_each
为指定序列区间应用函数fn
template
Function for_each (InputIterator first, InputIterator last, Function fn);
-
find
查找等于指定值的第一个元素位置
template
InputIterator find (InputIterator first, InputIterator last, const T& val);
-
find_if
查找满足条件的第一个元素位置
template
InputIterator find_if (InputIterator first, InputIterator last, UnaryPredicate pred);
-
find_first_of
在一个序列中查找等于第二个序列中任何一个元素的第一个元素的位置
template
ForwardIterator1 find_first_of (ForwardIterator1 first1, ForwardIterator1 last1, ForwardIterator2 first2, ForwardIterator2 last2); t
-
find_end
在序列1所涵盖的区间中查找序列2最后一次的出现点,如果不存在则返回
template
ForwardIterator1 find_end (ForwardIterator1 first1, ForwardIterator1 last1, ForwardIterator2 first2, ForwardIterator2 last2);;
-
count
返回与value相等的元素个数
template
count (InputIterator first, InputIterator last, const T& val);
-
count_if
返回满足指定操作的元素的个数 -
search
在序列1所涵盖的区间中查找序列2的首次出现点,如果不存在则返回
template
ForwardIterator1 search (ForwardIterator1 first1, ForwardIterator1 last1, ForwardIterator2 first2, ForwardIterator2 last2);
-
search_n
找出n个符合条件的元素形成的子序列
5.2 质变算法
-
transform
transform() 可以将函数应用到序列的元素上,并将这个函数返回的值保存到另一个序列中,它返回的迭代器指向输出序列所保存的最后一个元素的下一个位置。
template
OutputIterator transform (InputIterator first1, InputIterator last1, OutputIterator result, UnaryOperation op);
-
copy
-
copy_backward
-
swap
-
swap_ranges
互相交换元素 -
replace
用new_value代替old_value -
replace_if
替换满足条件的元素
-
fill
填充序列
-
fill_n
填充序列的前n个元素
-
remove
移除与value相等的元素,并不是真正删除 -
remove_if
移除被仿函数核定为true的元素,并不是真正删除 -
remove_copy
移除与value相等的元素,并不是真正删除,结果拷贝到另一处空间 -
remove_copy_if
移除被仿函数核定为true的元素,并不是真正删除,结果拷贝到另一处空间 -
unique
移除重复的元素,必须先排序 -
reverse
颠倒排序 -
rotate
把[first, middle) 和[middle, last) 的元素互换 -
random_shuffle
随机重排
5.3 排序和查找算法
-
sort
不稳定排序 -
stable_sort
稳定排序 -
partial_sort
分区排序
-
partial_sort_copy
分区排序并拷贝
-
nth_element
使第n小(大)元素排在合适位置
-
lower_bound
二分查找的下界 (从小到大序列中二分查找第一个大于等于目标数的位置)
upper_bound二分查找的上届 (从小到大序列中二分查找第一个大于目标数的位置)
-
equal_bound
二分查找的区间 [下界,上届)
-
binary_search
二分查找template
bool binary_search (ForwardIterator first, ForwardIterator last, const T& val);
-
merge
将两个有序集合s1和s2合并起来置于另一段空间,结果是有序序列 -
partition
不稳定分割 -
stable_partition
稳定分割
-
-
参考资料
书籍:
《STL源码剖析》
《C++ Primer(中文版第5版)》
《数据结构与算法分析:C++语言描述(第四版)》
教程:
STL教程:C++ STL快速入门(非常详细)
手册:
cplusplus.com - The C++ Resources Network
cppreference.com
最佳实践:
C++ Core Guidelines